
پروتکلهای شبکه، به عنوان قوانین ارتباطی بین دستگاههای شبکه کامپیوتری، پایه و اساس عملکرد عادی شبکهها هستند. با این حال، مسائل امنیتی ناشی از نقصهای طراحی و آسیبپذیریهای پیادهسازی در پروتکلهای شبکه، خطرات قابل توجهی را برای عملیات و امنیت شبکه ایجاد میکنند. فازینگ پروتکل شبکه یک تکنیک مؤثر برای کشف و کاهش نقصهای امنیتی در پروتکلهای شبکه است. این تکنیک به لطف حداقل نیاز به دانش قبلی از هدف و پیچیدگی کم استقرار، مزایای بینظیری را در مقایسه با سایر تکنیکهای تحلیل امنیتی ارائه میدهد. با این وجود، تصادفی بودن در تولید موارد آزمایشی، پوشش غیرقابل کنترل آزمایش و کارایی ناپایدار آزمایش، چالشهایی را در تضمین کنترلپذیری فرآیند و نتایج آزمایش ایجاد میکند. به منظور بررسی جامع توسعه تکنیکهای فازینگ پروتکل شبکه و تجزیه و تحلیل مزایا و مسائل موجود آنها، در این مقاله، فازینگ پروتکل و تکنیکهای مرتبط با آن را بر اساس روشهای تولید موارد آزمایشی و شرایط آزمایش دستهبندی و خلاصه کردهایم. به طور خاص، مسیر توسعه و الگوهای این تکنیکها را در طول دو دهه گذشته به ترتیب زمانی بررسی کردهایم. بر اساس این تحلیل، ما مسیرهای آینده تکنیکهای فازینگ را بیشتر پیشبینی میکنیم.
کلمات کلیدی: کشف آسیبپذیری؛ پروتکل شبکه؛ فازینگ؛ امنیت شبکه؛ امنیت پروتکل شبکه
1. مقدمه
پروتکلهای شبکه پایه و اساس شبکههای کامپیوتری هستند. آنها قالب، معنا، ترتیب و اقدامات تبادل پیام بین موجودیتهای ارتباطی را تعریف میکنند. با توسعه برنامههای کاربردی شبکه، آسیبپذیریها در پروتکلهای شبکه به عنوان یک عامل حیاتی تهدیدکننده امنیت شبکهها ظهور کردهاند.
کرم “Code Red” در سال 2001، از آسیبپذیریهای پیادهسازی پروتکل HTTP سوءاستفاده کرد و سطح دسترسی ابرکاربر (superuser) را در سرورهای وب مایکروسافت IIS به دست آورد. این کرم تقریباً 360،000 سرور و 1 میلیون کامپیوتر را در سراسر جهان آلوده کرد و منجر به خسارت جهانی حدود 2.6 میلیارد دلار شد. در سال 2014، آسیبپذیری “Heartbleed” در OpenSSL به طور عمومی افشا و مورد بهرهبرداری قرار گرفت [1]. این حادثه حدود 500،000 سرور اینترنتی را تحت تأثیر قرار داد. در سال 2021، مجموعهای از آسیبپذیریها به نام “WRECK” [2] افشا شد که مربوط به پیادهسازی پروتکلهای DNS بود و میتوانست منجر به انکار سرویس یا اجرای کد از راه دور شود. بیش از 180،000 دستگاه تنها در ایالات متحده تحت تأثیر قرار گرفتند.
مفهوم فازینگ در رابطه با کشف آسیبپذیریهای سیستم، توسط پروفسور بارتون میلر در دانشگاه ویسکانسین در سال 1988 پیشنهاد شد [3]. این مفهوم به تدریج به یک تکنیک مؤثر، سریع و کاربردی تبدیل شده است [4-7]. ایده اصلی، توسعه یک ابزار فازینگ، معروف به فازر [8] است که قادر به تولید دادههای نیمه معتبر (موارد آزمایشی) و ارسال آنها به سیستم تحت آزمایش (SUT) برای یافتن هرگونه مشکل امنیتی است.
دادههای نیمهمعتبر یا ناهنجار به دادههایی اشاره دارد که میتوانند به درستی توسط سیستم هدف دریافت و پردازش شوند، و در عین حال آسیبپذیریهای عمیق و ریشهداری را آشکار میسازند که تشخیص آنها از طریق روشهای مرسوم دشوار است [۹–۱۲]. گردش کار فازینگ در شکل ۱ نشان داده شده است، که در آن اطلاعات اولیه نیز به عنوان بذر (Seed) شناخته میشود.
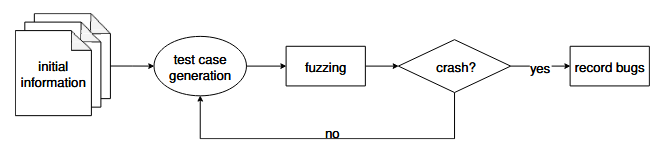
فازینگ به عنوان یک تکنیک تشخیص آسیبپذیری که به طور گسترده پذیرفته شده است، کاربرد گستردهای در زمینه آزمایش امنیت پروتکل پیدا کرده است. در حال حاضر، تکنیکهای فازینگ پروتکل در درجه اول بر آزمایش پیادهسازی پروتکلها تمرکز دارند. به عنوان مثال، در آسیبپذیری CVE-2019-16519، در طول فرآیند ارتباط پروتکل BGP، ارسال یک ارتباط نزدیک با طول پیام به اندازه کافی طولانی میتواند باعث خطای سرریز بافر در دیمن مسیر شود. در فازینگ پروتکل، اگر یک فازینگ یک بسته ارتباط نزدیک تولید و ارسال کند که معیارهای طول را برآورده کند، ممکن است این آسیبپذیری را ایجاد کند. یک تفاوت کلیدی با تکنیکهای فازینگ سنتی این است که بسیاری از پروتکلها دارای وضعیت هستند و نیاز به پیادهسازی دارند تا مجموعهای از درخواستهای پیام را دریافت کرده و پاسخهای مناسب را بر اساس وضعیت فعلی ارسال کنند. در مقابل، ابزارهای فازینگ سنتی اطلاعات وضعیت نرمافزار یا ساختار و ترتیب پیامهای ارسالی را در نظر نمیگیرند. در دو تا سه سال گذشته، هیچ بررسی سیستماتیکی که به طور خاص بر تکنیکهای فازینگ پروتکل شبکه متمرکز باشد، انجام نشده است.
اگر چند سال به عقب برگردیم، بررسیهای موجود در مورد فازینگ پروتکل و فازینگ سنتی وجود دارد که به کاربرد تکنیکهای فازینگ در پروتکلهای شبکه اشاره میکند. لیانگ و همکاران [7] به چالشهای کلیدی که تکنیکهای فازینگ سنتی در هر مرحله با آن مواجه هستند، پرداختند و مروری بر تحقیقات انجام شده برای رسیدگی به این چالشها ارائه دادند. این مقاله سناریوهای کاربردی مختلف برای تکنیکهای فازینگ را مورد بحث قرار میدهد و به طور خلاصه دو فازینگ پروتکل شبکه را شرح میدهد.
لی و همکاران [13] به طور خاص بر تکنیکهای فازینگ سنتی مبتنی بر پوشش تأکید کردند و فناوریهای یکپارچه در فازینگ را مورد بحث قرار دادند. آنها همچنین به تکنیکهای فازینگ پروتکل شبکه در سناریوهای کاربردی مختلف اشاره کردند و تنها چهار فازینگ مختلف را برجسته کردند.
مانس و همکاران [14] فرآیند کلی فازینگ را به چندین مرحله تقسیم کردند و گزینههای طراحی هر مرحله را با استفاده از تکنیکهای مربوطه توضیح دادند. در مرحله تولید ورودی، آنها اشاره کردند که برخی از تکنیکهای فازینگ پروتکل، مدلهای از پیش تعریف شده و روشهای مبتنی بر استنتاج را برای تولید موارد آزمایشی اتخاذ میکنند، بدون اینکه مقدمه خاصی برای این فازینگها ارائه دهند. مونئا و همکاران [15] تکنیکهای فازینگ پروتکل را از پنج دیدگاه مختلف طبقهبندی و مقایسه کرد، اما این بررسی فقط شامل پنج فازینگ خاص است. هو و پن [16] خلاصهای از تکنیکهای فازینگ پروتکل را به ترتیب زمانی ارائه دادند و تکنیکهای یادگیری ماشینی اعمال شده بر فازینگ پروتکل شبکه را معرفی کردند. با این حال، مطالعه آنها از نظر جامعیت تکنیکهای مرتبط جمعآوری شده و تجزیه و تحلیل انجام شده دارای محدودیتهایی است.
این مقاله با انجام یک بررسی در حوزه فازینگ پروتکل، قصد دارد شکاف موجود را پر کند. ما توسط رویکردی زمانی، تقریباً پنجاه فازینگ پروتکل و تکنیکهای تحقیقاتی مرتبط را بر اساس روشهای تولید موارد آزمایش و شرایط آزمایش، دستهبندی و خلاصه کردیم. این امر امکان مرور کلی مسیر توسعه و الگوهای مراحل مختلف از زمان آغاز این تکنیک را فراهم میکند. بر اساس تجزیه و تحلیل، ما مسیرهای آینده تکنیکهای فازینگ پروتکل را بیشتر پیشبینی میکنیم.
ساختار ادامه مقاله به این شرح است: در بخش 2، روششناسی جستجوی ادبیات پژوهش را شرح خواهیم داد. در بخش ۳، دانش بنیادی و روشهای طبقهبندی رایج مربوط به تکنیکهای فازینگ پروتکل شبکه را معرفی خواهیم کرد. در بخش ۴، به طور جامع توسعه و پیشرفتهای تکنیکهای فازینگ پروتکل شبکه را در دو دهه گذشته بررسی خواهیم کرد و آنها را به مراحل مختلف تقسیم خواهیم کرد.
بخش ۵ تکنیکهای مربوط به تکنیکهای فازینگ پروتکل شبکه را بررسی و تجزیه و تحلیل کرده و سهم آنها را در این زمینه ارزیابی خواهیم کرد. در بخش ۶، به مسائل کلیدی در فازینگ پروتکل خواهیم پرداخت و مزایا و معایب تکنیکهای پیشرفته فعلی را ارزیابی خواهیم کرد. در بخش ۷، تجزیه و تحلیل جامعی از تنگناهای موجود در تکنیکهای فازینگ پروتکل ارائه خواهیم داد و بینشهایی در مورد روندهای آینده این تکنیک ارائه خواهیم داد. در نهایت، این موضوع را در بخش ۸ به پایان خواهیم رساند.
۲. روش بررسی
به منظور انجام یک بررسی جامع در مورد فازینگ پروتکل شبکه، در بخشهای بعدی، روشهای تحقیق و دادههای جمعآوریشده خود را به تفصیل معرفی خواهیم کرد.
۲.۱ سوالات تحقیق
این بررسی عمدتاً با هدف پاسخ به سوالات تحقیقاتی زیر در مورد فازینگ پروتکل شبکه انجام شده است.
۱. سوال اول: مشکلات کلیدی و تکنیکهای مربوطه در تحقیقات فازینگ پروتکل چیست؟
۲. سوال دوم: تکنیکهای پیشرفته و مزایا و معایب آنها چیست؟
۳. سوال سوم: مسیرهای آینده فازینگ پروتکل و تکنیکهای مرتبط چیست؟
سوال اول، که در بخش ۶ به آن پاسخ داده شده است، به ما این امکان را میدهد که نگاهی عمیق به فازینگ پروتکل بیندازیم. سوال دوم، که در بخش ۶ به آن پاسخ داده شده است، برای ارائه بینشی در مورد مقایسهها و سناریوهای مناسب تکنیکهای موجود پیشنهاد شده است. در نهایت، بر اساس پاسخ به سوالات قبلی، انتظار داریم مشکلات حل نشده و فرصتهای آینده فازینگ پروتکل و تکنیکهای مرتبط را در پاسخ به RQ3 شناسایی کنیم که در بخش 7 به آن پاسخ داده شده است.
2.2 استراتژی جستجو
به منظور ارائه یک بررسی کامل که تا حد امکان مقالات مرتبط را پوشش دهد، ما جستجویی برای تکنیکهای مرتبط در سه مرحله انجام دادیم. ابتدا، برخی از مخازن آنلاین اصلی مانند IEEE XPlore، کتابخانه دیجیتال ACM، USENIX، کتابخانه آنلاین Springer و غیره را جستجو کردیم و یک جستجوی ادبی برای جمعآوری مقالاتی که از اصطلاحات “آزمایش فاز”، “فازینگ” یا “فازکننده” در رابطه با “پروتکل” استفاده میکنند، و همچنین مقالاتی که شامل “ماشین حالت پروتکل”، “FSM ” یا “مدلسازی پروتکل” در عناوین، چکیدهها یا کلمات کلیدی خود هستند، انجام دادیم. دوم، ما از چکیده مقالات جمعآوری شده برای حذف برخی از آنها بر اساس معیارهای انتخاب زیر استفاده کردیم:
- مرتبط با فیلد پروتکل شبکه نیست؛
- به زبان انگلیسی نوشته نشده است؛
- از طریق وب قابل دسترسی نیست.
سوم، ما منابع مقاله جمعآوریشده را بررسی کردیم تا مشخص کنیم که آیا تکنیکهای نادیده گرفتهشدهای وجود دارد یا خیر. جدول ۱ تعداد تکنیکهای مرتبط بازیابیشده از هر منبع را نشان میدهد. شایان ذکر است که دسته «سایر» شامل بسیاری از تکنیکهای مهم است که ممکن است در مقالات تحقیقاتی منتشر نشده باشند، مانند Peach و AFL هنوز هم ممکن است جستجوی ما تمام مقالات مرتبط را بهطور کامل پوشش ندهد، اما ما مطمئن هستیم که روندهای کلی در این مقاله دقیق هستند و تصویر منصفانهای از تکنیکهای پیشرفته ارائه میدهند.

۳. طبقهبندی تکنیکهای فازینگ پروتکل شبکه
۳.۱ طبقهبندی مبتنی بر روشهای تولید نمونههای آزمایشی
در تکنیکهای فازینگ پروتکل شبکه، نمونههای آزمایشی در درجه اول به بستههای داده پروتکل اشاره دارند که به درستی قالببندی شدهاند اما حاوی محتوای نادرست هستند. تکنیکهای مختلف فازینگ پروتکل شبکه از روشهای مختلفی برای تولید نمونههای آزمایشی استفاده میکنند و سپس نمونههای آزمایشی با استفاده از مکانیسمهایی مانند سوکتها برای شناسایی آسیبپذیریها به پیادهسازی پروتکل تحت آزمایش ارسال میشوند. در میان معیارهای طبقهبندی برای تکنیکهای فازینگ پروتکل شبکه، روش تولید نمونههای آزمایشی یکی از مهمترین عوامل است. روشهای تولید نمونههای آزمایشی را میتوان به طور کلی به رویکردهای مبتنی بر جهش و مبتنی بر تولید طبقهبندی کرد، همانطور که در زیر شرح داده شده است:
۱. رویکرد مبتنی بر جهش: در این رویکرد، فازر در ابتدا برخی از دادههای معتبر را با قالببندی و محتوای مناسب به دست میآورد. سپس این دادهها را با استفاده از روشهای مختلف اصلاح میکند تا دادههای نیمه معتبر مربوطه را ایجاد کند. فرآیند جهش عموماً شامل چهار روش است: وارونه کردن بیت، جهش حسابی، جهش مبتنی بر بلوک و جهش مبتنی بر فرهنگ لغت [14]:
- وارونه کردن بیت شامل وارونه کردن بیتهای خاص در بسته داده، تغییر 0 ثانیه به 1 ثانیه و 1 ثانیه به 0 ثانیه است.
- جهش حسابی یک دنباله بایت را انتخاب میکند، آن را به عنوان یک عدد صحیح در نظر میگیرد، عملیات حسابی را انجام میدهد و یک مقدار عدد صحیح جدید تولید میکند که سپس دوباره به دنباله بایت اصلی وارد میشود.
- جهش مبتنی بر بلوک، طول مشخصی از دنباله بایت را به عنوان یک بلوک در نظر میگیرد که واحد اساسی بسته داده در نظر گرفته میشود. عملیاتی مانند اضافه کردن، حذف، جایگزینی و تنظیم اولویت بلوکها انجام میشود.
- جهش مبتنی بر فرهنگ لغت بر روی عبارات معنایی خاصی که حاوی فیلدهای وزندار هستند تمرکز میکند. این عمل وزنها یا سایر فیلدهای مرتبط را با اعداد یا رشتههای از پیش تعریف شده جایگزین میکند
۲. رویکرد مبتنی بر تولید: در این رویکرد، فازر دادههای نیمه معتبر را بر اساس مشخصات یا الگوهای شناخته شده تولید میکند. این الگوها میتوانند توسط خود پرسنل آزمایش تعریف شوند یا در فازر از پیش تعریف شده باشند.
مقایسه مزایا و معایب این دو روش در زمینه فازینگ پروتکل شبکه به شرح زیر است:
۱. رویکرد مبتنی بر جهش با چالشهایی روبرو است زیرا بستههای داده پروتکل شبکه اغلب حاوی انواع داده متعددی هستند و پروتکلها یا انواع مختلف بستهها مشخصات متفاوتی دارند. یافتن یک استراتژی جهش مناسب برای تولید موارد آزمایشی که میتوانند به درستی در مرحله تولید موارد آزمایشی دریافت شوند، دشوار میشود. اگر یک استراتژی جهش تصادفی اتخاذ شود، تلاشهای قابل توجهی برای تأیید اینکه این موارد آزمایشی میتوانند به درستی دریافت شوند، مورد نیاز است.
۲. از سوی دیگر، رویکرد مبتنی بر تولید چالشهای خود را دارد. یکی از مسائل، هزینه مربوط به دستیابی به مشخصات پروتکل شبکه در مرحله کسب اولیه است. ممکن است به منابع و تلاشهای قابل توجهی برای به دست آوردن مشخصات دقیق پروتکل شبکه نیاز باشد. علاوه بر این، اگر انحرافاتی در درک پرسنل آزمایش از پروتکل وجود داشته باشد، کیفیت بذر (Seed) به دست آمده میتواند به خطر بیفتد. درک نادرست یا ناقص از پروتکل میتواند منجر به تولید موارد آزمایشی ناقص یا ناکارآمد شود و در نتیجه مانع اثربخشی فرآیند فازینگ شود.
3.2 طبقهبندی مبتنی بر شرایط آزمایش
بر اساس سطح درک از پیادهسازی پروتکل (که به فرآیندهای برنامه/نرمافزار یا سختافزاری که پروتکلهای شبکه را پیادهسازی میکنند و ارسال یا دریافت پیامهای پروتکل را مدیریت میکنند اشاره دارد)، فازینگ پروتکل شبکه را میتوان به سه دسته طبقهبندی کرد: فازینگ جعبه سیاه، جعبه سفید و جعبه خاکستری.
- جعبه سیاه: فازینگ جعبه سیاه، که به عنوان آزمایش تصادفی نیز شناخته میشود، شامل ابزار فازینگی است که هیچ دانشی از عملکرد داخلی SUT ندارد. این ابزار فقط میتواند ورودیها و خروجیهای سیستم را برای استنباط رفتار آن مشاهده کند. در نتیجه، فازینگ جعبه سیاه در مقایسه با سایر رویکردها، پوشش کد کمتری دارد.
- جعبه سفید: فازینگ جعبه سفید نیاز به درک منطق داخلی برنامه هدف دارد [17]. ابزار فازینگ، اطلاعات مربوط به عملکرد داخلی سیستم را برای تولید موارد آزمایشی جمعآوری و تجزیه و تحلیل میکند. در زمینه فازینگ پروتکل شبکه، این امر مستلزم درک کد خاص و اطلاعات زمان اجرای پیادهسازی پروتکل است. این رویکرد در ابتدا توسط Godefroid و همکارانش در سال 2008 برای رفع محدودیتهای فازینگ جعبه سیاه از نظر آزمایش کور و تصادفی پیشنهاد شد [18،19]. در تئوری، فازینگ جعبه سفید میتواند تمام مسیرهای کد را در SUT پوشش دهد. با این حال، دستیابی به پوشش کد 100٪ هنوز چالش برانگیز است، به خصوص برای پیادهسازیهای پروتکل در مقیاس بزرگ.
- جعبه خاکستری: فازینگ جعبه خاکستری بین فازینگ جعبه سیاه و جعبه سفید قرار میگیرد. این روش، روش تولید مورد آزمون را بر اساس اطلاعات پویای بهدستآمده از سیستم تحت آزمون، مانند پوشش کد، شرایط انشعاب و حالتهای حافظه تنظیم میکند. هدف آن تولید موارد آزمونی است که مسیرهای اجرایی بیشتری را پوشش دهند یا خطاها را کارآمدتر کشف کنند، بدون آنکه به دانش خاصی از پیادهسازی کد نیاز داشته باشد.
در زمینه فازینگ پروتکل شبکه، اغلب برای پرسنل آزمایش، دسترسی به کد منبع پیادهسازی پروتکل چالش برانگیز است. بنابراین، تکنیکهای فازینگ جعبه سیاه و جعبه خاکستری بیشتر مورد استفاده قرار میگیرند، در حالی که روشهای فازینگ جعبه سفید نسبتاً محدود هستند. در مقایسه با فازینگ جعبه سیاه، فازینگ جعبه خاکستری این مزیت را دارد که جهت آزمایش را بر اساس اطلاعات پیادهسازی پروتکل به دست آمده تنظیم میکند و در نتیجه به مسائل آزمایش کور و تصادفی که در فازینگ جعبه سیاه با آن مواجه میشویم، میپردازد.
4. جدول زمانی توسعه تکنیکهای فازینگ پروتکل شبکه
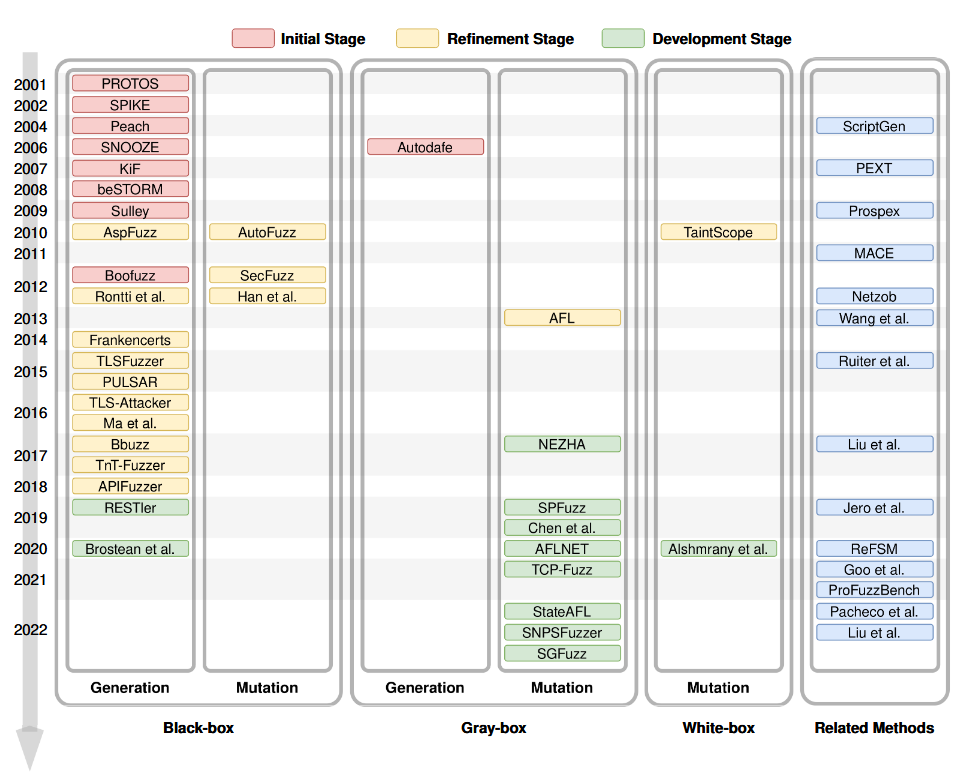
از زمان کاربرد تکنیکهای فازینگ در زمینه آزمایش امنیت پروتکل شبکه در سال 2001، توسعه تکنیکهای فازینگ پروتکل شبکه تقریباً 20 سال طول کشیده است. در این بخش، بر اساس یک جدول زمانی و شرایط آزمایش، ما توسعه تکنیکهای فازینگ پروتکل شبکه را از جنبههای روشهای تولید موارد آزمایشی و شرایط آزمایش بررسی و تجزیه و تحلیل میکنیم. هدف، ترسیم مسیر توسعه و روندهای آینده این تکنیک است. تجزیه و تحلیل خاص کارهای مرتبط در شکل 2 نشان داده شده است.
از شکل 2 میتوان مشاهده کرد که قبل از سال 2017، اکثر تکنیکهای فازینگ پروتکل شبکه از روشهای فازینگ جعبه سیاه مبتنی بر تولید استفاده میکردند. با این حال، در پنج سال گذشته، تکنیکهای فازینگ جعبه خاکستری توسعه سریعی را تجربه کردهاند.
علاوه بر این، با توجه به عواملی مانند سطح اتوماسیون مراحل تولید موارد آزمایشی و هدف فازر، توسعه تکنیکهای فازینگ پروتکل شبکه را میتوان به سه مرحله طبقهبندی کرد: مرحله اولیه (2001-2009)، مرحله پالایش (2009-2017) و مرحله توسعه (2017 تاکنون).
4.1 مرحله اولیه
مرحله اولیه تکنیکهای فازینگ پروتکل شبکه با ظهور این تکنیکها در سال ۲۰۰۱ آغاز شد و تا حدود سال ۲۰۰۹ ادامه یافت. در طول این مرحله، ابزارهای تست عمدتاً چارچوبهای فازینگ پروتکل عمومی بودند و از تکنیکهای فازینگ جعبه سیاه استفاده میکردند. این چارچوبهای فازینگ یا به ساخت دستی موارد تست توسط پرسنل تست متکی بودند یا از رویکردهای مبتنی بر تولید که توسط مشخصات پروتکل هدایت میشدند برای تولید موارد تست استفاده میکردند.
۴.۱.۱ مقدمه کار
۱. جعبه سیاه (Black-box)
یک پروژه تحقیقاتی در سال ۲۰۰۱، مجموعه تست پروتکل به نام PROTOS [20] توسط دانشگاه اولو، کاربرد تکنیکهای فازینگ را در تست امنیتی پروتکلهای شبکه معرفی کرد. هدف آن کشف آسیبپذیریهایی مانند سرریز بافر و خطاهای قالب رشته است. این رویکرد مفهوم مجموعههای تست را معرفی میکند که شامل ساخت دستی پیامهای تست است. این پیامها بر اساس تجزیه و تحلیل مشخصات پروتکل، با در نظر گرفتن ساختارهای داده پشتیبانی شده و محدوده مقادیر قابل قبول برای هر فیلد هستند. با این حال، PROTOS محدودیتهایی دارد زیرا API برای ساخت فازینگ سفارشی ارائه نمیدهد و اجازه تغییرات در موارد تست را بدون تغییر خود سینتکس پروتکل نمیدهد.
در سال ۲۰۰۲، چارچوب SPIKE [21]، یک چارچوب فازینگ پروتکل همه منظوره مبتنی بر زبان C، معرفی شد. این چارچوب یک پایگاه داده فازینگ شامل کاراکترهای ناقص مختلف مانند رشتههای طولانی، رشتههای با مشخصههای قالب، اعداد صحیح بزرگ و اعداد منفی ارائه میدهد. SPIKE همچنین مجموعهای غنی از APIها را ارائه میدهد و مفهوم فازینگ پروتکل مبتنی بر بلوک را معرفی میکند. پرسنل تست با استفاده از SPIKE میتوانند فازینگ را مستقیماً با استفاده از اسکریپتهای کاربردی ارائه شده انجام دهند یا با استفاده از کپسولهسازی سبک APIهای ارائه شده توسط چارچوب، فازینگهای خود را ایجاد کنند.
با این حال، SPIKE هنوز هم برای ساخت موارد تست به دانش قبلی پروتکل نیاز دارد و به تنظیم دستی متکی است. علاوه بر این، انتزاع بلوک ارائه شده نسبتاً سطح پایین است. این امر مدلسازی آسان پروتکلهای دارای وضعیت و پیامهای پیچیده را دشوار میکند. در سال 2004، Deja vu Security چارچوب فازینگ چند پلتفرمی به نام Peach [22] را منتشر کرد. این شامل اجزایی مانند Datamodel شامل انواع داده و رابطهای تغییردهنده Statemodel،شامل رابطهای Datamodel، حالتها و اقدامات،پروکسیها، یک موتور تست و غیره است. فازرها با نوشتن دستی فایلهای پیکربندی Peach Pit ایجاد میشوند. نسخه اولیه Peach در پایتون توسعه داده شد و نسخههای دوم و سوم متعاقباً در سالهای 2007 و 2013 منتشر شدند.
نسخه سوم در #C دوباره توسعه داده شد و از فازینگ فرمتهای فایل، ActiveX، پروتکلهای شبکه، APIها و موارد دیگر پشتیبانی میکرد. در سال 2006، گرگ بنکس و همکارانش یک ابزار فازینگ پروتکل شبکه به نام SNOOZE [23] توسعه دادند. این ابزار یک رویکرد فازینگ مبتنی بر سناریو را معرفی میکند که به پرسنل تست اجازه میدهد عملیات دارای وضعیت را در پروتکل توصیف کرده و سناریوهایی متشکل از پیامهای تولید شده در هر حالت ایجاد کنند. این ابزار بر اساس سناریوهای فازینگ، موارد آزمایشی مربوطه را تولید میکند و در نتیجه، آزمایش پروتکل حالتمند را امکانپذیر میسازد.
SNOOZE همچنین فازینگ اولیه را با هدف حملات خاص ارائه میدهد و به پرسنل آزمایش اجازه میدهد تا بر روی انواع خاصی از آسیبپذیریها تمرکز کنند. این ابزار میتواند آسیبپذیریهایی مانند سرریز بافر، سرریز عدد صحیح و تزریق SQL را کشف کند. با این حال، یک محدودیت این است که حالتهای مشاهده شده در فازر با حالتهای SUT هماهنگ نیستند. این امر نیاز به تجزیه و تحلیل بیشتر توسط پرسنل آزمایش دارد.
در سال 2007، H. J. Abdelnur و همکارانش ابزار KiF [24] را توسعه دادند که اولین فازر SIP بود که صرفاً دادههای تصادفی تولید نمیکرد. KiF موارد آزمایشی را بر اساس سناریوها و مشخصات پروتکل برای SIP تولید میکند. این ابزار قادر به حملات خودکار از طریق خود بهبودی و ردیابی وضعیت دستگاه هدف است. پیادهسازی KiF به یک الگوریتم یادگیری متکی است که یک ماشین حمله را با استفاده از ردیابیهای شبکه واقعی آموزش میدهد. این ماشین حمله میتواند در طول مرحله فازینگ تکامل یافته و بهروزرسانی شود. در سال 2008، شرکت Beyond Security ابزار فازینگ تجاری beSTORM [25] را منتشر کرد. این ابزار BNF مورد استفاده در اسناد RFC را به یک زبان حمله تبدیل میکند و مشخصات پروتکل را به یک مجموعه تست خودکار تبدیل میکند. معماری beSTORM از دو بخش تشکیل شده است: سمت کلاینت و سمت مانیتور. سمت کلاینت بستههای نیمه معتبر را به SUT ارسال میکند، در حالی که سمت مانیتور وضعیت SUT را رصد میکند، هرگونه استثنا را ثبت میکند و آنها را به سمت کلاینت ارسال میکند.
در سال 2009، چارچوب فازینگ Sulley در پلتفرم GitHub [26] منتشر شد. این چارچوب از یک فازر قابل تنظیم و چندین مؤلفه قابل توسعه تشکیل شده است. مزایای آن شامل سادهسازی فرآیندهای انتقال داده، نمایش و نظارت بر هدف است. ویژگیهای خاص سالی عبارتند از: (1) نظارت بر ارتباطات شبکه و نگهداری سوابق مربوطه، (2) تشخیص و نظارت بر وضعیت اجرای هدف، با قابلیت بازیابی به عملکرد عادی با استفاده از روشهای مختلف، (3) تشخیص، ردیابی و دستهبندی خرابیها، (4) انجام فازینگ به صورت موازی، و (5) تعیین خودکار توالی موارد آزمایشی که باعث خطا میشوند. سالی، فازینگ را با تجزیه درخواستهای پروتکل برای فازینگ به بلوکها و سپس پیوند دادن درخواستهای تجزیهشده به یک جلسه و اتصال پروکسیهای نظارتی موجود قبل از انجام آزمایش، پیادهسازی میکند. سالی دیگر به طور فعال نگهداری نمیشود و Boofuzz [27] که در سال ۲۰۱۲ منتشر شد، شاخهای و ادامهای از چارچوب Sulley است. Boofuzz مشکلات موجود در Sulley را برطرف کرد و مقیاسپذیری آن را بهبود بخشید.
۲. جعبه خاکستری (Gray-box)
در سال ۲۰۰۶، Vuagnoux، Autodafe [28] را معرفی کرد، ابزاری برای فازینگ که برای کشف آسیبپذیریهای سرریز بافر طراحی شده است. Autodafe نحوه استفاده از متغیرهای کنترلشده توسط کاربر توسط SUT را تجزیه و تحلیل میکند و آزمایش را با استفاده از متغیرهایی که به عنوان پارامتر به توابع حساس به امنیت منتقل میشوند، در اولویت قرار میدهد. مزیت Autodafe توانایی آن در تولید خودکار توضیحات پروتکل و انجام آزمایش با استفاده از یک پایگاه داده فازینگ است.
۴.۱.۲ خلاصه
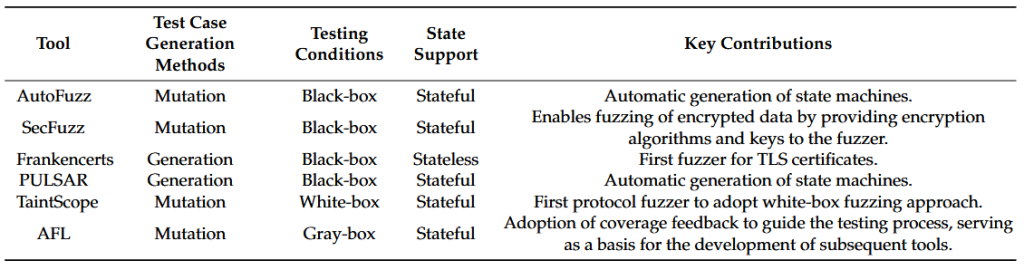
جدول ۲ مروری بر تکنیکهای نماینده ارائه میدهد. میتوان مشاهده کرد که با پیشرفت این تکنیک، تکنیکهای اولیه محدود به آزمایش پروتکلهای بدون وضعیت بودند، در حالی که تکنیکهای بعدی از آزمایش پروتکلهای دارای وضعیت پشتیبانی میکردند. در این مرحله، تکنیکهای فازینگ به شدت به مداخله دستی در فرآیند ساخت موارد آزمون متکی هستند و محدودیتهای خاصی در انعطافپذیری آزمون دارند. با این حال، ابزارهای فازینگ مانند Peach، Sulley و Boofuzz هنوز هم به طور گسترده مورد استفاده قرار میگیرند.

۴.۲ مرحله تکمیلی
۴.۲.۱ معرفی کارها
۱. جعبه سیاه (Black-box)
گوربونوف و روزنبلوم در سال ۲۰۱۰، یک چارچوب متنباز توسعهپذیر به نام AutoFuzz [29] را برای آزمایش پیادهسازیهای پروتکل شبکه پیشنهاد دادند. این چارچوب، ارتباط بین کلاینت و سرور را برای ساخت یک ماشین حالت متناهی که پیادهسازی پروتکل را یاد میگیرد، ثبت میکند. با استفاده از دانش بیوانفورماتیک، AutoFuzz نحو پیامهای پروتکل منفرد، از جمله فیلدهای پیام و انواع ممکن را یاد میگیرد. این چارچوب با استفاده از ماشین حالت متناهی به عنوان راهنما، به طور هوشمندانه جلسه ارتباط بین کلاینت و سرور را برای انجام آزمایش تغییر میدهد. در طول این فرآیند، AutoFuzz تمام اقدامات را برای بررسی و تأیید توسط پرسنل آزمایش ثبت میکند.
با این حال، AutoFuzz فاقد تجزیه و تحلیل و مقایسه بین بازخورد واقعی از پیادهسازیهای پروتکل و بازخورد ایدهآل از دستگاه حالت پروتکل برای تعیین اینکه آیا انواع خاصی از رفتار غیرمنتظره رخ میدهد یا خیر، است. در همان سال، کیتاگاوا و همکارانش، AspFuzz [30] را پیشنهاد کردند، یک ماشین فازر آگاه از حالت بر اساس مشخصات پروتکل لایه کاربرد. فازرهای سطح پیام قبلی فقط تغییرات درون پیامهای منفرد را در نظر میگرفتند، بدون اینکه ترتیب انتقال پیام را تغییر دهند. فازرهای مبتنی بر سناریو مانند SNOOZE و KiF میتوانند ترتیب انتقال پیام را بر اساس سناریوها تعیین کنند تا از مشکلاتی که فازرهای سطح پیام با آن مواجه میشوند، جلوگیری کنند، اما فرآیند ایجاد سناریو پیچیده است.
AspFuzz از یک رویکرد آگاه از وضعیت استفاده میکند که امکان انتخاب ترتیب انتقال موارد آزمایشی را پس از تولید موارد آزمایشی فراهم میکند. موارد آزمایشی میتوانند به ترتیب صحیح یا به ترتیب نادرست منتقل شوند. با این حال، AspFuzz به تعریف دستی پروتکل آزمایش شده و تعیین دستی حملات موفق در طول فرآیند آزمایش متکی است. در سال 2012، تسانکوف و همکارانش ابزار SecFuzz [31] را برای رسیدگی به مسئله محتوای رمزگذاری شده در پیامهای پروتکل پیادهسازیهای خاص پروتکل معرفی کردند. SecFuzz کلیدهای لازم و الگوریتمهای رمزگذاری را برای فازر فراهم میکند تا پیامهای رمزگذاری شده را بر اساس فازینگ پروتکل شبکه به درستی تغییر دهد. SecFuzz با عمل به عنوان واسطه بین کلاینت و سرور برای رهگیری پیامها، ورودیهای معتبر را دریافت کرده و آنها را بر اساس سه عملگر فاز سفارشی قبل از جهش و ارسال به SUT طبقهبندی میکند.
در همان سال، رونتی و همکارانش فازر شبکه نسل بعدی (NGN) [32] را مطالعه کردند که با استفاده از مشخصات پروتکل، موارد آزمایشی ایجاد میکند. شبکه NGN به شبکهای اشاره دارد که انواع خدمات و رسانهها را ادغام میکند. این ابزار، توصیف پروتکل را با استفاده از قوانین گرامری مشتق شده از مشخصات پروتکل بهبود میبخشد و سطح مناسب ناهنجاریها را از یک کتابخانه ناهنجاری موجود برای تولید موارد آزمایشی مربوطه انتخاب میکند. نتایج تجربی نشان میدهد که فازر در کشف آسیبپذیریهایی که میتوانند در حملات DoS یا DDoS مورد سوءاستفاده قرار گیرند، مؤثر است. هان و همکارانش یک روش تست فاز مبتنی بر مدل تجزیه و تحلیل روابط و علامتگذاری موارد آزمایشی RATM برای مجموعه دادههای فازینگ چند دامنهای پیشنهاد کردند [33]. با تجزیه و تحلیل روابط بین دامنهها در پروتکل، این روش میتواند مستقیماً بستههای داده مربوطه را که ممکن است باعث آسیبپذیری شوند، تغییر دهد. همچنین میتواند نتایج آزمایش را تجزیه و تحلیل کرده و پارامترهای RATM را برای بهبود کیفیت موارد آزمایشی تغییر دهد. این روش برای فازینگ پروتکلهای مبتنی بر لایه MAC بسیار مؤثر است.
در سال ۲۰۱۴، بروبیکر و همکاران اولین ابزار آزمایشی در مقیاس بزرگ به نام Frankencerts [۳۴] را طراحی، پیادهسازی و بهکار گرفتند که بهطور خاص منطق تأیید گواهی در پیادهسازیهای پروتکل SSL/TLS را هدف قرار میداد. این ابزار به دو مسئله اصلی میپردازد: تولید موارد آزمون با کیفیت بالا و بررسی معقول بودن پذیرش/رد گواهیها. در مورد تولید موارد آزمون، Frankencerts یک پیکرهای شامل تعداد عظیمی از گواهیها ایجاد میکند.
در فرآیند تولید مورد آزمون (test case)، این ابزار بخشهای دستساز گواهیها را با بخشهای ترکیبشده تصادفی از گواهیهای واقعی تلفیق میکرد و اطمینان میداد که موارد آزمون تولیدشده دارای ساختار نحوی (syntax) صحیحی باشند که توسط پروتکل قابل پردازش است. این موارد آزمون همچنین محدودیتها و وابستگیهایی را نقض میکنند که گواهیهای معتبر باید از آنها تبعیت کنند و در نتیجه احتمال آشکارسازی آسیبپذیریهای پروتکل را افزایش میدهند. در مورد بررسی معقولبودن نتایج گواهیها، ابزار از آزمون افتراقی (differential) بهره میگیرد و با استفاده از چندین پیادهسازی مستقل، تأیید مشترک را انجام میدهد تا از صحت دلایل پذیرش یا رد گواهیها اطمینان حاصل کند. چنانچه نتایج حاصل از اکثر پیادهسازیها ناهمگون باشد، نشاندهنده نادرست بودن آن نتیجه است.
مشابهاً با تمرکز بر اعتبارسنجی پیادهسازی پروتکل TLS، در سال ۲۰۱۵ ابزار فازینگ TLSFuzzer [35] برای پروتکل TLS در گیتهاب منتشر شد. برخلاف فازرهای معمولی که تنها بررسی میکنند آیا سیستم تحت آزمون دچار سقوط میشود یا خیر، TLSFuzzer همچنین تأیید میکند که آیا سیستم پیامهای خطای صحیح را بازمیگرداند یا نه. این ابزار رفتار سرورها را در پروتکل TLS اعتبارسنجی میکند و بررسی میکند که آیا امضای پیامهای TLS با اطلاعات گواهی (certificate) ارسالشده توسط سرور مطابقت دارد یا نه، بدون آنکه هیچ گونه بررسیای بر روی گواهیهای پروتکل انجام دهد. در همان سال، گاسکون و همکاران…
در همان سال، گاسکون و همکارانش PULSAR [36] را معرفی کردند، یک ابزار فازینگ جعبه سیاه حالتمند برای پروتکلهای شبکه اختصاصی. این ابزار در سناریوهایی که هیچ کد پیادهسازی پروتکل و مشخصات پروتکل در دسترس نیست، قابل استفاده است. PULSAR تکنیکهای فازینگ و مهندسی معکوس خودکار پروتکل را برای استنتاج خودکار مدل پروتکل شبکه بر اساس مجموعهای از بستههای داده شبکه تولید شده توسط برنامه، ادغام میکند. مدل پروتکل شبکه آموخته شده، فرآیند فازینگ را هدایت میکند. اشکال PULSAR این است که مدل آموخته شده از پیامهای شبکه ممکن است به طور طبیعی فاقد برخی از قابلیتها باشد، که ممکن است بر فرآیند آزمایش پروتکل تأثیر بگذارد.
در سال 2016، ساموروفسکی و همکارانش یک چارچوب منبع باز به نام TLS-Attacker [37] برای ارزیابی امنیت کتابخانههای TLS توسعه دادند. این چارچوب با استفاده از ابزار مدیریت پروژه Maven پیادهسازی شد. نویسندگان با تکیه بر TLS-Attacker، یک روش فازینگ دو مرحلهای را برای ارزیابی رفتار سرور TLS پیشنهاد دادند که به طور خودکار آسیبپذیریهای غیرمعمول اوراکل پدینگ (padding oracle) و سرریزها (overflows)/خواندنهای بیش از حد (over-reads) را تشخیص میداد. آنها همچنین یک مجموعه آزمایشی مربوط به پروتکل TLS ایجاد کردند. در همان سال، Ma و همکارانش روشی را برای تولید دادههای فازینگ با استفاده از ماشینهای حالت مبتنی بر قانون و درختهای قانون حالتمند [38] ارائه کردند.
این روش از ماشینهای حالتمند به عنوان توصیفهای رسمی از حالتهای پروتکل شبکه استفاده میکند، ماشین حالتمند را با حذف مسیرهای امن شناخته شده با استفاده از قوانین پروتکل ساده میکند و روابط بین حالتها و پیامها را با استفاده از درختهای قانون حالتمند توصیف میکند. الگوریتمهای تولید مختلفی برای جهش منظم بذرهای (seed) اولیه با استفاده از الگوریتمهای تولید داده به کار گرفته میشوند و امکان تولید دادههای فازینگ را فراهم میکنند. در سال 2017، Blumbergs و همکارانش ابزار Bbuzz را برای تجزیه و تحلیل پروتکلهای شبکه [39] معرفی کردند که به طور خاص در یک زمینه نظامی به کار گرفته شد. این ابزار در سطح بیت عمل میکند و دادههای بسته مورد نیاز را در فایلها فیلتر و ذخیره میکند. این ابزار با محاسبه آنتروپی شانون، به شناسایی ویژگیهای فیلد کمک میکند و امکان تجزیه و تحلیل بخشهایی که میتوانند جهش داده شوند را فراهم میکند. در نتیجه، نتایج مهندسی معکوس پروتکلهای دودویی دقیقتر شد.
برای APIهای انتقال حالت نمایشی (REST)، دو ابزار فازینگ در سالهای 2017 و 2018 در GitHub منتشر شدند: TnT-Fuzzer [40] و APIFuzzer [41]. هر دو ابزار با پایتون نوشته شدهاند و از مشخصات Swagger برای تجزیه درخواستهای HTTP استفاده میکنند و فرآیند فازینگ را هدایت میکنند.
2. جعبه خاکستری (Gray-box)
در سال 2013، زالوسکی و همکارانش یک ابزار فازینگ عمومی مبتنی بر جهش به نام American Fuzzy Lop (AFL) [42] پیشنهاد کردند. این ابزار، فازینگ هدایتشده با پوشش کد را با استفاده از ابزار کامپایل کد منبع و حالت QEMU معرفی میکند. با این حال، AFL برای آزمایش پروژههای بدون وضعیت، مانند آزمایش فایلها، مناسبتر است و فاقد دانش در مورد اطلاعات وضعیت پیادهسازی پروتکلها و ساختار یا ترتیب پیامهایی است که هنگام آزمایش پروتکلهای شبکه ارسال میشوند. فرآیند جهش پیام تصادفی است، در نتیجه منجر به راندمان آزمایش پایینتری میشود.
3. جعبه سفید (White-box)
در سال 2010، وانگ و همکارانش TaintScope [43] را ارائه کردند، یک ابزار فازینگ که از مجموع کنترلی و اعتبارسنجی عبور میکند. این ابزار از تجزیه و تحلیل دقیق اثرات مخرب برای شناسایی ورودیهایی که به فراخوانیهای سیستمی حیاتی یا فراخوانیهای API وارد میشوند، استفاده میکند. همچنین یک تکنیک فازینگ آگاه از مجموع کنترلی را معرفی میکند که دستورالعملهای آزمایش مجموع کنترلی را از طریق تجزیه و تحلیل اثرات مخرب شناسایی میکند و SUT را برای دور زدن اعتبارسنجی مجموع کنترلی اصلاح میکند.
اگر SUT اصلاح شده از کار بیفتد، TaintScope فیلد مجموع کنترلی را با استفاده از اجرای نمادین ترکیبی بیشتر تعمیر میکند و آزمایش را روی SUT اصلی انجام میدهد. علاوه بر این، TaintScope نحوه دسترسی و استفاده SUT از دادههای ورودی را رصد میکند و اطلاعات حساس را به صورت جهتدار تغییر میدهد. با این حال، TaintScope در مدیریت طرحهای بررسی یکپارچگی مرتبط با امنیت، مانند امضاهای دیجیتال، محدودیتهایی دارد و هنگام برخورد با دادههای رمزگذاری شده، کارایی کمتری از خود نشان میدهد. علاوه بر این، بسته به قالبهای ورودی خوشفرم و بدفرم، به ورودیهای با کیفیت بالا نیاز دارد.
4.2.2 خلاصه
جدول ۳ خلاصهای از تکنیکهای شاخص در مرحله تکمیلی را ارائه میدهد. از جدول مشاهده میشود که در مرحله تکمیلی، تکنیکهای فازینگ مهمترین مسئله موجود در مرحله اولیه، یعنی وابستگی بیش از حد به مداخله دستی را برطرف کردهاند. بهعنوان مثال، Autofuzz و PULSAR توانستند با تحلیل بستههای داده ارتباطی پروتکل، ماشینهای حالت پروتکل را بهطور خودکار تولید کنند. علاوه بر این، در مرحله تکمیلی، ابزارهای فازینگ بهتدریج تمرکز خود را از پروتکلهای عمومی به خانوادههای پروتکل خاص معطوف کردهاند. این ابزارها همچنین قادر به پرداختن به سناریوهای خاص در طول آزمون هستند. برای مثال، ابزارهایی مانند Frankencerts و TLSFuzzer بر پیادهسازیهای پروتکل SSL/TLS متمرکزند، SecFuzz بر آزمون محتوای رمزگذاریشده تمرکز دارد و TaintScope فرآیند آزمون یکپارچگی سیستم تحت آزمون را دور میزند.
از سوی دیگر، در این دوره، AFL بهعنوان یک ابزار فازینگ عمومی منتشر شد. اگرچه AFL در فازینگ پروتکل عملکرد مطلوبی ندارد، اما رویکرد جدیدی را برای فازینگ پروتکل ارائه میدهد: استفاده از فازینگ جعبهخاکستری برای جمعآوری اطلاعات هدایتشده با پوشش و بهبود کارایی فازینگ پروتکل شبکه.
۴.۳ مرحله توسعه
مرحله توسعه، که از سال ۲۰۱۷ تا به امروز را در بر میگیرد، با غلبه تکنیکهای فازینگ جعبه خاکستری مشخص میشود که از پوشش کد برای بهبود کارایی فازینگ استفاده میکنند.
۴.۳.۱ مقدمه کار
۱. جعبه سیاه (Black-box)
در سال ۲۰۱۹، آتلیداکیس و همکارانش اولین فازینگ حالتمند را برای APIهای REST به نام RESTler [44] توسعه دادند. این ابزار مشخصات OpenAPI سرویسهای ابری را برای استخراج نحو REST تجزیه و تحلیل میکند و وابستگیهای بین انواع مختلف درخواستها را استنباط میکند. RESTler از سه استراتژی جستجوی مختلف بر اساس بازخورد پویا از پاسخهای سرویس برای کمک به تولید موارد آزمایشی استفاده میکند.
علاوه بر این، RESTler طرحهای سطلبندی را برای خوشهبندی آسیبپذیریهای مشابه و کمک به کاربران در تجزیه و تحلیل آسیبپذیری معرفی میکند. در سال 2020، برای پروتکل امنیت لایه انتقال داده DTLS، بروستیان و همکارانش چارچوب TLS-Attacker را گسترش دادند و یک چارچوب فازینگ حالتمند برای سرورهای DTLS ساختند [45]. این ابزار از یادگیری مدل با الگوریتم TTT برای استنتاج ماشینهای Mealy استفاده کرد و فازینگ حالت پروتکل جامعی را روی DTLS انجام داد. این آزمایشها مدلهای ماشین حالت Mealy از 13 پیادهسازی DTLS را تجزیه و تحلیل کردند و 4 آسیبپذیری امنیتی شدید را آشکار کردند.
2. جعبه خاکستری (Gray-box)
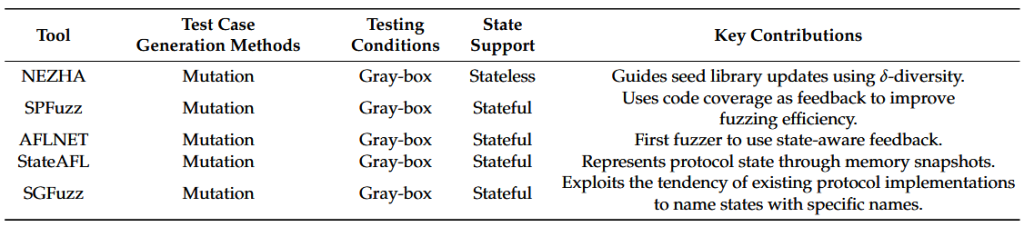
در سال 2017، پتسیوس و همکارانش چارچوب LibFuzzer [46] را اصلاح کردند و یک ابزار تست دیفرانسیل (differential testin) کارآمد به نام NEZHA [47] پیشنهاد دادند. NEZHA مفهوم δ-diversity را برای ثبت ناسازگاریهای رفتاری بین چندین SUT معرفی میکند. NEZHA شامل اجزای زمان اجرا و یک موتور اصلی است: اجزای زمان اجرا تمام اطلاعات لازم برای هدایت تنوع δ را جمعآوری و به موتور اصلی منتقل میکنند، که ورودیهای جدیدی را از طریق جهش ایجاد میکند تا تفاوتهای بین SUTها را کشف کند و پیکره اولیه را با هدایت تنوع δ بهروزرسانی کند. در طول آزمایش، NEZHA بر اساس اینکه آیا SUT از ابزار دقیق یا بازنویسی دودویی پشتیبانی میکند، تعیین میکند که آیا از روشهای جعبه سیاه یا جعبه خاکستری استفاده کند یا خیر.
در سال 2019، سونگ و همکارانش SPFuzz [48] را پیشنهاد کردند، یک چارچوب فازینگ پروتکل حالتمند که هدف آن ایجاد یک رویکرد انعطافپذیر و هدایتشده توسط پوشش است. SPFuzz مشخصات زبان را از Boofuzz ترکیب میکند تا مشخصات پروتکل، انتقال حالتها و وابستگیها را برای تولید موارد آزمایشی ارزشمند توصیف کند. این سیستم پیامهای صحیح را در حالت نشست (session) حفظ میکند و با بهروزرسانی به موقع دادههای پیام، وابستگیهای پروتکل را مدیریت میکند.
SPFuzz از یک استراتژی جهش سه سطحی (هدرها، محتوا و توالیها) استفاده میکند و تخصیص تصادفی پیامها و وزنها را برای استراتژیهای جهش در نظر میگیرد تا مسیرهای بیشتری را در طول فرآیند فازینگ پوشش دهد. یکی از محدودیتهای SPFuzz این است که به کد منبع و مشخصات پروتکل نیاز دارد و مشخصات پروتکل به ساخت دستی متکی است. در همان سال، به منظور دستیابی به پوشش کد بالاتر در آزمایش پروتکلهای ارتباطی شبکه، چن و همکارانش یک استراتژی فازینگ پروتکل حالتمند طراحی کردند و محدودیتهای فازینگهای جعبه خاکستری بدون حالت را در آزمایش پروتکل نشان دادند [49]. استراتژی فازینگ حالتمند شامل یک موتور انتقال حالت و یک سرور چند حالته است.
این استراتژی با استفاده از یک الگوریتم جستجوی عمق-اول، جستجو در حالتهای مختلف فازینگ را انجام میدهد و پیشرفت و رگرسیون حالتها را به صورت انعطافپذیر از طریق برنامهریزی انرژی تعیین میکند. این استراتژی امکان فازینگ انعطافپذیر حالتهای مختلف را در برنامههای پروتکل فراهم میکند.
در سال ۲۰۲۰، فام و همکاران، AFLNET [50] را توسعه دادند که از کدهای پاسخ به عنوان حالتهای برنامههای پروتکل شبکه استفاده میکند. AFLNET بهطور دقیق حالتهای واقعی برنامههای پروتکل شبکه را فاز میکند و از بازخورد حالت برای هدایت فرآیند فازینگ بهره میبرد. AFLNET از یک رویکرد مبتنی بر جهش استفاده کرده و توالی تبادل پیام بین کلاینتها و سرورها را به عنوان بذرهای اولیه (Seed) به کار میگیرد.
در طول آزمایش، AFLNET به عنوان یک کلاینت عمل میکند و انواع توالیهای پیام درخواست را دوباره پخش میکند. همچنین از تکنیکهای هدایتشده با پوشش برای حفظ انواعی استفاده میکند که به طور موثر پوشش کد یا حالت را بهبود میبخشند. AFLNET در مقایسه با ابزارهای تست بدون حالت هدایتشده با پوشش مانند AFLnwe نسخهای با قابلیت شبکه از AFL و ابزار تست مبتنی بر تولید Boofuzz، پیشرفتهای قابل توجهی را نشان میدهد. با این حال، AFLNET برای پروتکلهای بدون کدهای حالت مناسب نیست و استخراج اطلاعات حالت به مشخصات پروتکل نوشتهشده دستی متکی است.
در سال 2021، زو و همکاران. TCP-Fuzz [51] را طراحی کردند، یک چارچوب فازینگ جدید برای آزمایش مؤثر پشتههای (stack) TCP و تشخیص خطا در آنها. TCP-Fuzz با در نظر گرفتن وابستگیهای بین فراخوانیهای سیستم و بستهها برای تولید توالی فراخوانیهای سیستم، یک استراتژی مبتنی بر وابستگی را برای تولید موارد آزمایش مؤثر اتخاذ میکند. برای دستیابی به پوشش کارآمد انتقال حالت، TCP-Fuzz از یک روش فازینگ هدایتشده با انتقال استفاده میکند که از یک معیار کد جدید به نام انتقال شاخه به عنوان بازخورد برنامه به جای پوشش کد استفاده میکند. انتقال شاخه به عنوان برداری نمایش داده میشود که پوشش شاخه ورودی فعلی (بسته یا فراخوانی سیستم) و تغییرات در پوشش شاخه بین ورودیهای فعلی را ذخیره میکند.
ورودی و ورودیهای قبلی. این رویکرد نه تنها حالتها را توصیف میکند، بلکه انتقال حالتها بین ورودیهای مجاور را نیز ثبت میکند. در نهایت، برای تشخیص خطاهای معنایی، TCP-Fuzz از یک بررسیکننده تفاضلی استفاده میکند که خروجیهای چندین پشته TCP را با ورودی یکسان مقایسه میکند. از آنجایی که پشتههای TCP مختلف باید از بسیاری از قوانین معنایی یکسان (که اکثر آنها در اسناد RFC تعریف شدهاند) پیروی کنند، ناسازگاری در خروجی نشاندهنده خطاهای معنایی احتمالی در برخی از پشتههای TCP است.
در سال 2022، ناتلا StateAFL [52]، یک فازر جعبه خاکستری برای سرورهای شبکه، را توسعه داد. به طور کلی، در این مرحله، تمرکز بر فازینگ پروتکلهای حالتمند است و هدف اصلی این ابزارهای فازینگ، کشف آسیبپذیریها در حالتهای عمیقتر پروتکل است.
StateAFL ابزار زمان کامپایل را برای شناسایی سرور هدف و درج پروبها برای تخصیص حافظه و عملیات ورودی/خروجی شبکه انجام میدهد. در زمان اجرا، فازر عکسهای فوری از مناطق حافظه با عمر طولانی را ثبت میکند و یک الگوریتم هشینگ حساس به محل را برای نگاشت محتوای حافظه به شناسههای حالت منحصر به فرد اعمال میکند. این به StateAFL اجازه میدهد تا وضعیت پروتکل فعلی SUT را استنباط کند و به تدریج یک ماشین وضعیت پروتکل برای هدایت فرآیند فازینگ بسازد.
تجزیه و تحلیل کیفی نشان میدهد که استنباط وضعیتها از حافظه، بازتاب بهتری از رفتار سرور نسبت به تکیه صرف بر کدهای پاسخ ارائه میدهد. در همان سال، لی و همکارانش فازر جعبه خاکستری سریع دیگری به نام SNPSFuzzer [53] را پیشنهاد کردند که از اسنپشاتها (snapshot) نیز استفاده میکند. SNPSFuzzer بر اساس AFLNET ساخته شده و سه جزء اصلی را معرفی میکند: یک مولد نمونه مبتنی بر اسنپشات، یک اسنپشاتر (snapshotter) و یک تحلیلگر زنجیره پیام. هنگامی که برنامه پروتکل شبکه به یک وضعیت خاص میرسد، اطلاعات زمینهای ذخیره میشود و در صورت نیاز میتوان آن را بازیابی کرد.
علاوه بر این، لی و همکارانش یک الگوریتم تجزیه و تحلیل زنجیره پیام طراحی کردند که زنجیره پیام را با استفاده از دو متغیر برای تجزیه و تحلیل به اطلاعات پیشوند، میانوند و پسوند تقسیم میکند. این رویکرد، وضعیتهای عمیقتر پروتکل شبکه را بررسی میکند. در مقایسه با AFLNET، SNPSFuzzer در فازیسازی پروتکل شبکه در عرض 24 ساعت به بهبود سرعت 112.0٪ تا 168.9٪ دست یافت و پوشش مسیر را 21.4٪ تا 27.5٪ افزایش داد. علاوه بر این، در سال 2022، na و همکارانش SGFuzz [54] را توسعه دادند، ابزاری که به طور خودکار حالتهای پروتکل را تجزیه و تحلیل میکند و با استفاده از نظم بین نام متغیرها در پیادهسازیهای پروتکل، آزمایش حالت را انجام میدهد.
SGFuzz از تطبیق الگو برای شناسایی متغیرهای حالت با استفاده از enumها استفاده میکند. هنگامی که به یک متغیر حالت مقدار جدیدی اختصاص داده میشود، ابزار یک اعلان مربوطه ارسال میکند و حالت جدید را به درخت انتقال حالت ساخته شده STT اضافه میکند. SGFuzz همچنین ورودیهای تولید شده را برای آموزش STT به کتابخانه بذر (Seed) اضافه میکند و بر گرههایی تمرکز میکند که به ندرت بازدید میشوند و فرزندانی دارند که احتمال بیشتری دارد از مسیرهای مختلف عبور کنند و در نتیجه پوشش فضای حالت را بهبود میبخشد. SGFuzz در غیاب مشخصات صریح پروتکل یا حاشیهنویسیهای دستی، پیشرفتهای قابل توجهی در تولید توالیهای حالت، دستیابی به پوشش شاخهای یکسان و کشف خطاهای حالتدار به دست میآورد. با این حال، SGFuzz برای تجزیه و تحلیل حالتهای پروتکل در طول فرآیند آزمایش به کد منبع پیادهسازی پروتکل نیاز دارد و تجزیه و تحلیل آسیبپذیریهای ایجاد شده توسط حالتهای پنهان هنوز به تجزیه و تحلیل دستی نیاز دارد.
3. جعبه سفید (White-box)
در سال 2020، آلشمانی و همکارانش یک روش تأیید ارائه دادند که فازینگ را با تکنیکهای اجرای نمادین ترکیب میکند [55]. این رویکرد مبتنی بر AFL است و از فازینگ برای کاوش اولیه پروتکلهای شبکه استفاده میکند. به طور همزمان، اجرای نمادین برای کاوش مسیرهای برنامه و حالتهای پروتکل به کار گرفته میشود. با ترکیب این تکنیکها، بستههای داده مورد آزمایش با پوشش بالا میتوانند به طور خودکار برای پیادهسازیهای پروتکل شبکه تولید شوند. اجرای نمادین با استفاده از هر دو روش کاوش مسیر و بررسی مدل محدود BMC پیادهسازی میشود.
4.3.2 خلاصه
جدول ۴ تکنیکهای شاخص در مرحله توسعه را خلاصه میکند. در این مرحله، چندین تکنیک فازینگ جعبهخاکستری بر پایه AFL توسعه یافتند که فازینگ بدون حالت AFL را به فازینگ دارای حالت مناسب برای پروتکلها تطبیق دادند.
AFLNET، StateAFL، SNPSFuzzer و SGFuzz همگی از بازخورد حالت برای هدایت فرآیند فازینگ استفاده میکنند. آنها این کار را با ضبط کدهای پاسخ پیام، گرفتن عکسهای فوری از حافظه، ذخیره اطلاعات زمینهای و تجزیه و تحلیل کد منبع پروتکل برای شناسایی انواع دادههای خاص و تعیین حالتهای پروتکل انجام میدهند. الشمرانی و همکاران [55] از تکنیکهای اجرای نمادین برای تجزیه و تحلیل مسیرهای برنامه و بررسی حالتهای پروتکل استفاده کردند.
۵. روشهای مرتبط با تکنیکهای فازینگ پروتکل شبکه
علاوه بر ابزارها/چارچوبهای فازینگ پروتکل شبکه که در بالا ذکر شد، ابزارها و روشهای مرتبط دیگری نیز وجود دارند که به اتوماسیون و ارزیابی فازینگ پروتکل شبکه کمک میکنند.
۵.۱ تکنیکهای تولید خودکار ماشینهای حالت پروتکل
ماشینهای حالت محدود FSM اغلب در زمینه تحقیقات پروتکل شبکه برای مدلسازی فرآیند تبادل پیام پروتکلهای شبکه به منظور توصیف انتقال حالتهای موجودیتهای پروتکل استفاده میشوند. برای ساخت موارد آزمون فازی برای پروتکلهای ناشناخته، لازم است از مشخصات پروتکل استخراج شده از طریق مهندسی معکوس پروتکل استفاده شود. برای پروتکلهای بدون حالت، موارد آزمون را میتوان بر اساس قالب پروتکل تولید کرد تا اطمینان حاصل شود که هر فیلد از تأیید برنامه هدف عبور میکند. با این حال، برای پروتکلهای حالتدار، لازم است توالیهای پیام آزمون که میتوانند توسط ماشین حالت پروتکل به صورت هدفمند پذیرفته شوند، ارسال شوند تا از تعداد زیادی از موارد آزمون نامعتبر به دلیل عدم تطابق حالتها جلوگیری شود و عمق و کارایی آزمایش تضمین شود. تست فازی سنتی شامل اطلاعات زمینه و تمام حالتهای موجود در توالی پیام نمیشود، بنابراین دادههای تست تولید شده برای هر حالت گسسته هستند و ممکن است کل مسیر حالت را پوشش ندهند. بنابراین، آسیبپذیریها در انتقال حالت ممکن است شناسایی نشوند و ممکن است مقدار زیادی از دادههای تست اضافی وجود داشته باشد. دادههای تست به صورت تصادفی تولید میشوند و فاقد قوانین هستند. علاوه بر این، تکنیکهای فازی پروتکل مبتنی بر تولید میتوانند از ماشینهای حالت پروتکل برای ساخت قالبهای پروتکل استفاده کنند. بنابراین، ترکیب فناوری تولید ماشین حالت محدود میتواند تست فازی پروتکل را هدفمندتر و کارآمدتر کند و پوشش تست بهتری را ارائه دهد.
در ادامه، تاریخچه توسعه فناوری تولید خودکار ماشین حالت پروتکل را معرفی خواهیم کرد.
5.1.1 رویکردهای مبتنی بر استنتاج غیرفعال
استنتاج غیرفعال به فرآیند استنتاج ماشین حالت از مجموعهای از نمونههای محدود بدون تکیه بر راهنمایی موجودیت پروتکل اشاره دارد. این امر در درجه اول شامل دو مرحله است: برچسبگذاری حالت و سادهسازی ماشین حالت. در مرحله برچسبگذاری وضعیت، برچسبهای طبقهبندی میتوانند بر اساس ویژگیهایی مانند انواع پیام، طول و موقعیتها در دادههای نمونه تعیین شوند که منجر به وضعیتهای مختلف میشود. در مرحله سادهسازی ماشین وضعیت، وضعیتهای برچسبگذاری شده میتوانند بیشتر سادهسازی شوند تا یک ماشین وضعیت مختصر برای تجزیه و تحلیل و کاربردهای بعدی ایجاد شود. در سال 2004، اولین ابزار تجزیه و تحلیل طراحی شده برای استنباط ماشینهای وضعیت پروتکل از جریانهای داده شبکه، به نام ScriptGen [56]، پیشنهاد شد.
این ابزار از الگوریتم همترازی توالی Needleman-Wunsch مشابه پروژه PI و همچنین خوشهبندی خرد و خوشهبندی کلان ترافیک شبکه ضبط شده برای ساخت ماشینهای وضعیت پروتکل استفاده میکند. با این حال، این ابزار محدودیتهای خاصی دارد، مانند عدم توانایی در مدیریت جلسات پیام مختلف با همبستگیهای سببی و اتکای آن به شناسههای بسته TCP مانند ACK، SYN، FIN ،این ابزار فقط میتواند چند پروتکل خاص را تجزیه و تحلیل کند و یک راه حل قوی و قابل اجرا برای استنباط حالتهای پروتکل نیست.
در سال 2007، شورتالوف و همکارانش در ابتدا راه حلی به نام PEXT [57] را پیشنهاد کردند که مبتنی بر خوشهبندی بسته برای استنتاج خودکار دستگاه حالت پروتکل است. این راه حل اندازه فاصله D(a,b) بین بستههای a و b را بر اساس طول طولانیترین زیردنباله مشترک آنها محاسبه میکند. سپس بستهها را بر اساس D(a,b) خوشهبندی میکند و بستههایی را که آدرسهای مبدا و مقصد یکسانی دارند، به عنوان توالیهای اولیه انتقال حالت، حاشیهنویسی میکند. سپس جفتهای حالت را با پیشوندهای مشترک و بدون گرههای خواهر و برادر ادغام میکند تا ماشینهای حالت را برای کل مجموعه نمونه به دست آورد. با این حال، PEXT دو محدودیت دارد: (1) نقش فیلدهای کلمات کلیدی در انتقال ماشین حالت را به طور کامل در نظر نمیگیرد که منجر به برچسبگذاری حالت با دقت کمتر و دقیقتر میشود، و (2) فرآیند ادغام بسیار ساده است که منجر به ماشینهای حالت استنباطی با دقت کمتر میشود.
در سال 2009، Comparetti و همکارانش Prospex [58] را پیشنهاد کردند، راهحلی که حالتهای پروتکل را بر اساس کد اجرایی دودویی استنباط میکند. این ابزار، کار قبلی آنها [59] در مورد استخراج قالب پیام مبتنی بر رفتار را بهبود میبخشد. این ابزار ساختارهای پیام و تأثیر پیامها بر رفتار سرور را معرفی میکند. در طول مرحله تحلیل جلسه، Prospex از تحلیل پویای رنگ برای ردیابی تمام عملیات مربوط به خواندن دادهها از پیامهای پروتکل استفاده میکند. این روش، جلسه را به پیامها تقسیم میکند و اولین بایت ورودی دریافت شده توسط سرور را به عنوان شروع یک پیام در نظر میگیرد و تمام ورودیهای بعدی را به عنوان بخشی از آن پیام در نظر میگیرد تا زمانی که سرور پاسخی ارسال کند. این فرآیند تا زمانی که تمام بستههای داده ردیابی شده به پیامها تقسیم شوند، تکرار میشود. این رویکرد دقیقتر از پردازش تک تک بستهها است.
به عنوان یک پیام، به ویژه برای پروتکلهای مبتنی بر تعامل که در آن یک پیام ممکن است چندین بسته داده را در بر بگیرد. سپس ویژگیها را از بستههای نمونه استخراج میکند، آنها را خوشهبندی میکند تا مجموعهای از انواع پیام M را بدست آورد، نمونههای جلسه S را به عنوان توالیهای نوع پیام MTS نشان میدهد و با استفاده از S، پذیرنده درخت پیشوندی افزوده APTA را میسازد. در APTA، گرهها حالتها را نشان میدهند و لبهها ورودیهای ai ∈ M را نشان میدهند که باعث انتقال حالت میشوند. انواع پیشینی Pi برای هر نوع mi ∈ M نیز استنباط میشوند. در نهایت، از الگوریتم Ex-bar برای ادغام حالتهای یکسان و استخراج یک ماشین متناهی قطعی حداقلی (DFA) استفاده میشود. با این حال، طبق تحقیقات [60]، استنباط یک ماشین حالت حداقلی دقیق صرفاً بر اساس نمونههای مثبت گرفته شده از شبکه دشوار است.
5.1.2 رویکردهای مبتنی بر استنتاج فعال
الگوریتمهای استنتاج غیرفعال به کامل بودن مجموعه نمونه متکی هستند. برای رفع این محدودیت، تحقیقات در مورد استنتاج فعال با معرفی الگوریتم *L توسط آنگلوین و همکارانش [61] آغاز شد. در استنتاج فعال، هدف گسترش مجموعه نمونه اصلی با استفاده از یک سیستم یادگیری دستی برای استنتاج تکراری ماشین حالت است. الگوریتم *L نمونههای ورودی-خروجی را به دو مجموعه تقسیم میکند: نمونههای مثبت و نمونههای منفی. نمونههای مثبت توالیهای ورودی هستند که ماشین میتواند به درستی آنها را مدیریت کند، در حالی که نمونههای منفی توالیهای ورودی هستند که ماشین نمیتواند به درستی آنها را مدیریت کند. الگوریتم *L وجود یک اوراکل را فرض میکند که میتواند پاسخهای دقیقی ارائه دهد. دو نوع پرسوجو وجود دارد: پرسوجوی عضو و پرسوجوی همارزی.
این الگوریتم از این مثالها برای ساخت یک مجموعه فرضیه OT استفاده میکند و تمام ماشینهای حالت کاندید M را تولید میکند. با پیشرفت الگوریتم، M در برابر ماشین حالت واقعی با استفاده از پرسوجوهای همارزی ارزیابی میشود تا به تدریج مجموعه فرضیه را محدود کرده و ماشین حالت کمینهشده را پیدا کند. الگوریتم *L تضمین میکند که یک ماشین حالت حداقل کامل میتواند در زمان چندجملهای استنتاج شود، اما چالش اصلی این است که چگونه به طور دقیق به پرسشها پاسخ داده شود.
Cho و همکارانشدر سال 2011، ابزار MACE را بر اساس الگوریتم *L پیشنهاد دادند [62] MACE برای کشف پیامهای پروتکل به اجرای نمادین پویا متکی است و از یک جزء فیلترینگ ویژه برای انتخاب پیامها برای مدلهای یادگیری استفاده میکند. این جزء جستجوی بیشتر را با استفاده از مدل یادگیری هدایت میکند و هنگامی که پیامهای جدید کشف میشوند، آن را اصلاح میکند. این سه جزء تا زمانی که فرآیند همگرا شود، به طور متناوب تغییر میکنند و به طور خودکار ماشین حالت پروتکل را استنتاج کرده و فضای حالت برنامه را کاوش میکنند. MACE میتواند مدلهای پروتکل را استنتاج و فضای جستجوی برنامهها را کاوش کند و به طور خودکار آزمایشهایی را ایجاد نماید. در یک تحلیل تجربی روی چهار برنامه، MACE هفت آسیبپذیری را کشف کرد و به نتایج خوبی دست یافت.
در سال ۲۰۱۲، بوسرت و همکارانش، پروژه متنباز Netzob [63] را معرفی کردند که از سه ماژول تشکیل شده بود: ماژول استنباط لغوی (lexical inference module)، ماژول استنباط نحوی (syntactic inference module) و ماژول شبیهسازی (simulation module). ماژول استنباط لغوی، الگوریتم همترازی توالی چندگانه را از PI PI [64] اقتباس کرده و بر اساس الگوریتم *L بهبود بخشیده است. این ماژول از اطلاعات ویژگی در قالبهای پیام برای استنتاج ماشینهای Mealy استفاده میکند. سپس مشخصات واژگانی و نحوی استنتاج شده در ماژول شبیهسازی برای شبیهسازی ارتباط بین موجودیتهای پروتکل استفاده میشوند و فازینگ هوشمند را برای پروتکلهای ناشناخته امکانپذیر میکنند.
در سال 2013، وانگ و همکارانش سیستم Veritas [65] را پیشنهاد داده و طراحی کردند. Veritas با استفاده از مجموعهای از اطلاعات وضعیت پروتکل که از طریق تحلیل خوشهای (cluster analysis) به دست آمده است، یک ماشین وضعیت پروتکل احتمالی میسازد. برای هر اطلاعات وضعیت پروتکل، Veritas فراوانی وقوع آن و احتمال انتقال بین آن و سایر اطلاعات وضعیت پروتکل را اندازهگیری میکند. سپس Veritas یک گراف جهتدار برچسبگذاری شده برای نمایش ماشین حالت پروتکل با استفاده از این نتایج آماری میسازد، که در آن انتقال حالت و مقادیر احتمال انتقال به عنوان برچسبهایی روی لبههای جهتدار نمایش داده میشوند. در نهایت، Veritas گراف جهتدار را به یک ماشین حالت پروتکل احتمالی تبدیل میکند.
برای کاهش پیچیدگی ماشین حالت پروتکل، Veritas از الگوریتم Hopcroft-Karp برای انجام عملیات کمینهسازی روی ماشین حالت پروتکل استفاده میکند. الگوریتم Hopcroft-Karp حالتهای معادل در ماشین حالت پروتکل را در یک حالت واحد ادغام میکند و تعداد حالتها را کاهش میدهد و کارایی و خوانایی ماشین حالت پروتکل را بهبود میبخشد. در سال 2015، De Ruiter و همکارانش روشی را برای توصیف پروتکلها با استفاده از ماشینهای حالت پیشنهاد کردند [66]. آنها از یک نسخه بهبود یافته از الگوریتم یادگیری مدل *L برای استنباط ماشین حالت از طریق LearnLib استفاده کردند که یک لیست پیام ورودی انتزاعی (همچنین به عنوان الفبای ورودی شناخته میشود) ارائه میدهد.
De Ruiter و همکارانش از یک ابزار آزمایش برای تبدیل لیست پیامهای ورودی به پیامهای ملموس ارسال شده به SUT استفاده کرد و پاسخهایی دریافت کرد که سپس به انواع پیامهای انتزاعی تبدیل شدند. LearnLib انواع پیامهای برگشتی را تجزیه و تحلیل کرد و فرضیههایی در مورد ماشین حالت پروتکل ارائه داد. تجزیه و تحلیل اشکال مختلف TLS lementations ماشینهای حالت منحصر به فرد و متمایزی تولید میکند که نشان میدهد این تکنیک میتواند برای انگشتنگاری TLS نیز استفاده شود.
مشکل این رویکرد این است که پس از به دست آوردن ماشین حالت پروتکل، De Ruiter و همکارانش به جای استفاده از یک روش خودکار برای آزمایش موجودیتهای پروتکل، ماشین حالت را به صورت دستی تجزیه و تحلیل کردند تا آسیبپذیریهای منطقی را در پیادهسازیهای خاص پیدا کنند و سپس کد منبع پیادهسازی را برای شناسایی مسائل مربوطه تجزیه و تحلیل کردند.
در سال 2017، Liu و همکارانش تکنیکی را برای رسیدگی به مشکل تعمیم بیش از حد ماشینهای حالت ناشی از خطاها در ادغام حالتهای برچسبگذاری شده هنگام ساخت درخت APTA پیشنهاد کردند [67]. آنها از یک تکنیک تجزیه و تحلیل پویای آلودگی با تکیه بر DECAF برای تجزیه و تحلیل برنامههای شبکه و ساخت درخت APTA استفاده کردند. با استفاده از اطلاعات معنایی برای تمایز حالتها و ادغام حالتهای مشابه، دقت برچسبگذاری حالتها در درخت APTA را بهبود بخشیدند.
این روش با TCP و پروتکل کنترل Agobot آزمایش شد و به نتایج مطلوبی دست یافت.
در سال ۲۰۱۹، Pacheco و همکاران، یادگیری خودکار قواعد پروتکل از مشخصات متنی (مانند RFC) را مطالعه کردند و قواعد استخراجشده خودکار را روی یک فازر برای ارزیابی قواعد یادگرفتهشده اعمال کردند [۶۸].
ارزیابی نشان داد که این رویکرد میتواند همان حملات سیستمهای مشخصشده دستی را با موارد آزمایش کمتر کشف کند. در سال 2022، پاچکو و همکارانش روش جامعتری را پیشنهاد کردند [69].
این روش شامل سه مرحله کلیدی بود: (1) یادگیری نمایش کلمه در مقیاس بزرگ از زبانهای فنی، (2) نگاشت یادگیری zero-shot متن پروتکل به یک زبان میانی، و (3) نگاشت مبتنی بر قانون از زبان میانی به ماشینهای حالت محدود پروتکل خاص. آنها ماشینهای حالت پروتکل را از مشخصات پروتکل TCP، DCCP، BGPv4 و سایر پروتکلها استخراج کردند و به نتایج خوبی دست یافتند.
در سال 2020، LI و همکارانش یک روش استنتاج حالت پروتکل به نام ReFSM [70] پیشنهاد کردند که با در نظر گرفتن موارد زیر، روشهای استنتاج حالت پروتکل موجود را بهبود بخشید:
ویژگی ضبط بسته در زمان واقعی. این روش مبتنی بر ماشین حالت محدود توسعهیافته EFSM است و شامل سه مرحله است: (1) شناسایی نوع پیام، که از تحلیل کلمات کلیدی پیشین برای استخراج کلمات کلیدی پروتکل و الگوریتم K-means برای گروهبندی پیامها برای تعیین تعداد خوشهها استفاده میکند، و هر گروه به عنوان یک نوع پیام متفاوت در نظر گرفته میشود. (2) ساخت EFSM و استنتاج معنایی، که درختی از اتوماتای انتقال پروتکل PTA میسازد که تمام جلسات پروتکل را میپذیرد و از الگوریتم ادغام K-tail برای سادهسازی ماشین حالت پروتکل استفاده میکند. (3) استخراج مجموعه زیرداده، که مجموعههای زیرداده حاوی مقادیر فیلد پیام مشاهده شده در پیامها را برای تجزیه و تحلیل بیشتر برای جستجوی همبستگی بین فیلدها در پیامها استخراج میکند. دقت فیلدهای مرتبط با حالت استخراج شده با ترکیب روش فیلد مرتبط با حالت با روش خوشهبندی تا حد زیادی بهبود یافته است. سپس، اطلاعات این فیلدهای مرتبط با حالت برای مقایسه هر انتقال در EFSM استفاده میشود و عملیات ادغام ماشین حالت با تعیین اینکه آیا درختهای A و B تولید شده ساختار یکسانی دارند یا خیر، تکمیل میشود.
اگرچه روش ReFSM در استخراج فیلدهای مرتبط با حالت به پیشرفتهایی دست یافته است، اما هنوز مشکل انفجار حالت وجود دارد که به دلیل تعداد زیاد حالتها در ماشین حالت پروتکل، بر کارایی و دقت استنتاج ماشین حالت تأثیر میگذارد. در سال 2021، گو و همکارانش با تکیه بر تحقیقات قبلی روی الگوریتم L+M برای استنتاج ماشینهای Mealy، یک الگوریتم جدید و یک راه حل جدید برای استنتاج حالتهای پروتکل ارائه دادند [71]. آنها ماشین Mealy پروتکلهای نوع کلاینت-سرور را از طریق پرسوجوهای ورودی و همارزی روی توالی کاراکتر ورودی مدلسازی کردند. در آزمایشهای امکانسنجی، این ابزار روی پروتکلهای Modbus و MQTT آزمایش شد و نتایج خوبی به دست آورد.
5.1.3 خلاصه
به طور خلاصه، ماشینهای حالت پروتکل میتوانند به طور سیستماتیک رفتار و انتقال حالت یک سیستم یا پروتکل شبکه را توصیف کنند، دستورالعملهای تست واضحی را برای تست فاز ارائه دهند و تست فاز را هدفمندتر و کارآمدتر کنند. با استفاده از ماشینهای حالت پروتکل، موارد تست فاز طراحی شده میتوانند تمام حالتها و انتقالهای سیستم یا پروتکل شبکه تست شده را از نظر ساختار پوشش دهند و در نتیجه پوشش تست را بهبود بخشند.
در حال حاضر، اساسیترین و مهمترین جهت تحقیقاتی در این زمینه، استخراج خودکار ماشینهای حالت پروتکل از پیادهسازیهای پروتکل یا ترافیک شبکه یا نگاشت مستقیم رفتار پروتکل به ماشینهای حالت با حالتها و انتقالهای حالت تعریف شده است. یکی از جهتهای مهم توسعه مبتنی بر استنتاج فعال است که از سیستمهای یادگیری مصنوعی برای گسترش مداوم مجموعه نمونه اصلی و استنتاج مکرر ماشینهای حالت استفاده میکند و در نتیجه وابستگی به کامل بودن مجموعه نمونه را کاهش داده و دقت و کارایی استنتاج ماشین حالت را بهبود میبخشد.
5.2 ارزیابی تکنیکهای فازینگ پروتکل شبکه
تعداد ابزارهای فازینگ پروتکل شبکه در حال افزایش است و هر ابزار بر اهداف تست و دامنههای مختلف مسئله تمرکز دارد. بنابراین، برای تعیین اینکه کدام ابزار آزمون بهترین نتایج را ارائه میدهد، ارزیابی تکنیکهای فازینگ پروتکل شبکه ضروری است.
در سال 2021، ناتلا و همکارانش یک مجموعه تست معیار برای فازینگ پروتکل شبکه حالتمند به نام ProFuzzBench [72] معرفی کردند. این مجموعه تست معیار شامل مجموعهای از سرورهای شبکه منبع باز نماینده برای پروتکلهای محبوب و ابزارهای آزمایشی خودکار مانند AFLNET و StateAFL است. این مجموعه تست با استفاده از Docker برای دستیابی به آزمایشهای تکرارپذیر پیادهسازی شده و از تجزیه و تحلیل مقایسهای تکنیکهای مختلف فازینگ در شرایط کنترلشده پشتیبانی میکند.
از آنجایی که همه حالتها در یک پروتکل حالتمند به یک اندازه مهم نیستند و تکنیکهای فازینگ دارای محدودیتهای زمانی هستند، یک الگوریتم انتخاب حالت مؤثر برای فیلتر کردن حالتهای خوب با اولویت بالاتر مورد نیاز است. در سال 2022، لیو و همکارانش مجموعهای از الگوریتمهای انتخاب حالت را با استفاده از ابزار AFLNET در مجموعه تست معیار ProFuzzBench ارزیابی کردند و یک الگوریتم انتخاب حالت بهبود یافته به نام AFLNETLegion [73] پیشنهاد دادند.
5.3 خلاصه
در نتیجه، هنگام انتخاب ابزارهای فازینگ که نیاز به ساخت دستی مشخصات پروتکل دارند، مانند Peach و SNOOZE، میتوان ابزارهای خودکار را بر اساس اطلاعات موجود مربوط به پروتکل انتخاب کرد تا ماشینهای حالت پروتکل را تولید کرده و تلاش دستی را کاهش دهند. از سوی دیگر، هنگامی که پرسنل آزمایش باید بفهمند کدام روشها و ابزارهای فازینگ در سناریوهای خاص مؤثرتر هستند، ProFuzzBench از آزمایش ابزارهای نماینده پشتیبانی میکند و تجزیه و تحلیل مقایسهای تکنیکهای مختلف فازینگ را در شرایط کنترل شده امکانپذیر میسازد.
6. تکنیکهای پیشرفته
با توجه به فرآیند کلی فازینگ پروتکل و تفاوت بین فازینگ سنتی و فازینگ پروتکل که در بخش 1 توضیح داده شده است و روشهای مرتبط با تکنیکهای فازینگ پروتکل که در بخش 5 معرفی شدهاند،
سوالات زیر باید در نظر گرفته شوند:
- نحوه تولید یا انتخاب موارد آزمون؛
- نحوه اعتبارسنجی ورودیها در برابر مشخصات SUT (سیستم تحت آزمون)؛
- نحوه هدایت SUT برای انجام آزمایشها برای حالتهای عمیقتر پروتکل؛
- نحوه بهبود سطح اتوماسیون فازینگ پروتکل.
در این بخش، با خلاصهسازی و مقایسه سهم اصلی در مسائل فوق فازینگ پروتکل در تکنیکهای پایه و پیشرفته امروزی، به RQ1 و RQ2 میپردازیم.
6.1 تولید و انتخاب موارد آزمایشی
در مرحله تولید موارد آزمایشی، دو رویکرد اصلی قابل تشخیص است: روشهای مبتنی بر تولید که توسط Peach و Boofuzz ارائه میشوند، و روشهای مبتنی بر جهش که توسط AFLNet ارائه میشوند.
در رویکرد مبتنی بر تولید، مانند Peach و Boofuzz، یک الگوی پروتکل مورد نیاز است که قالب بسته مورد نظر را برای پروتکل تعریف میکند. برای به دست آوردن الگوی پروتکل، که ساختار و رفتار مورد انتظار بستههای داده پروتکل را مشخص میکند، تلاش دستی لازم است. سپس موارد آزمایشی بر اساس این الگو تولید میشوند و تغییرات و جهشها را برای بررسی سناریوهای ورودی مختلف در نظر میگیرند. از سوی دیگر، روشهای مبتنی بر جهش، مانند AFLNet، StateAFL، SNPSFuzzer و SGFuzz، برای تولید موارد آزمایشی به ترافیک شبکه واقعی متکی هستند. با گرفتن و تجزیه و تحلیل بستههای شبکه واقعی، تکنیکهای از پیش تعریف شده برای جهش بستههای گرفته شده و تولید موارد آزمایشی مورد نظر اعمال میشوند.
این رویکرد از ترافیک شبکه موجود برای بررسی آسیبپذیریهای بالقوه و آزمایش استحکام پیادهسازی پروتکل استفاده میکند. همانطور که در بخش 3 بحث شد، یکی از چالشهای اصلی روشهای مبتنی بر تولید، اتکا به پرسنل آزمایش دارای دانش قبلی از پروتکل است. این روش نیاز به تلاش دستی برای جمعآوری اطلاعات در مورد مشخصات پروتکل، از جمله حالتها و شرایط گذار دارد. این رویکرد میتواند منجر به هزینههای تحقیقاتی قابل توجه و الزامات تخصصی شود. در مورد روشهای مبتنی بر جهش، یک چالش قابل توجه این است که استراتژیهای تولید موارد آزمایشی فعلی میتوانند کاملاً تصادفی باشند، که در آن بسیاری از موارد آزمایشی تولید شده از طریق جهش ممکن است نتوانند اعتبارسنجی پروتکل را پشت سر بگذارند، که منجر به تأثیر قابل توجهی بر کارایی تکنیکهای فازینگ مبتنی بر جهش میشود.
6.2 اعتبارسنجی ورودی
توانایی تولید خودکار موارد آزمایشی متعدد برای ایجاد رفتارهای غیرمنتظره SUT، یک مزیت قابل توجه فازینگ است. با این حال، اگر SUT دارای مکانیسم اعتبارسنجی ورودی باشد، این موارد آزمایشی به احتمال زیاد در مرحله اولیه اجرا رد میشوند. در زمینه فازینگ پروتکل، تکنیکهای مجموع کنترلی و رمزگذاری معمولاً برای اطمینان از یکپارچگی و محرمانگی بستههای داده ورودی استفاده میشوند. TaintScope ابتدا از تحلیل پویای آلودگی و قوانین از پیش تعریفشده برای شناسایی نقاط احتمالی checksum استفاده میکند و سپس بایتها را برای ایجاد موارد آزمایشی جدید تغییر میدهد و checksum را تغییر میدهد.
نقاط را تغییر میدهد تا همه موارد آزمایشی ایجاد شده اعتبارسنجی یکپارچگی را پشت سر بگذارند. هنگامی که برخی از موارد آزمایشی میتوانند باعث خرابی SUT شوند، از اجرای نمادین و حل محدودیت برای رفع مقدار checksum این موارد آزمایشی استفاده میکند. یکی از چالشهای اصلی TaintScope این است که به اطلاعات گستردهای در مورد ورودیها، از جمله ورودیهای خوشفرم و بدفرم، نیاز دارد.
کیفیت ورودیها به طور قابل توجهی بر شناسایی نقاط بازرسی تأثیر میگذارد. بنابراین، ارائه طیف متنوع و جامعی از ورودیها، از جمله قالبها و شرایط خطای مختلف، برای اطمینان از آزمایش کامل و شناسایی دقیق نقاط بازرسی توسط TaintScope بسیار مهم است.
SecFuzz ابتدا به مسئله محتوای رمزگذاری شده در پیامهای پروتکل میپردازد. این فازر کلیدهای لازم و الگوریتمهای رمزگذاری را در اختیار فازر قرار میدهد و با عمل به عنوان واسطه بین کلاینت و سرور، پیامهای رمزگذاری شده را تغییر میدهد. در حال حاضر، SecFuzz قادر به رسیدگی به فقط برخی از مسائل رمزگذاری متقارن است و از تغییر برای همه فیلدها پشتیبانی نمیکند.
6.3 فازینگ پروتکل با وضعیت
در زمینه پیادهسازی پروتکل در حالت سرور-کلاینت، یک سرور با وضعیت و مبتنی بر پیام است. این سرور دنبالهای از پیامها را از کلاینت دریافت میکند، پیامها را مدیریت میکند و پاسخهای مناسب را ارسال میکند و پاسخ سرور به پیام فعلی و وضعیت فعلی سرور داخلی بستگی دارد که توسط پیامهای قبلی کنترل میشود.
در فازینگ پروتکل با وضعیت، روشهای مبتنی بر تولید و مبتنی بر جهش از رویکردهای متفاوتی استفاده میکنند.
در روشهای مبتنی بر تولید، الگوی پروتکل حاوی اطلاعات مرتبط با وضعیت پروتکل است. فازر نه تنها موارد آزمایشی تولید میکند، بلکه ماشینهای وضعیت مربوطه را نیز میسازد. در Peach، ماشین وضعیت پروتکل با استفاده از قالب StateModel نمایش داده میشود، در حالی که در Boofuzz، با استفاده از sessionها نمایش داده میشود. یک چالش قابل توجه این است که تلاش دستی برای به دست آوردن الگوی پروتکل در هر دو Peach و Boofuzz لازم است. در روشهای مبتنی بر جهش، AFLNET پیشگام فازینگ جعبه خاکستری مبتنی بر پوشش وضعیتمحور بود که دادههای وضعیت خودکار را ادغام میکرد.
استنتاج مدل و فازینگ هدایتشده توسط پوشش. متعاقباً، StateAFL، SNPSFuzzer و SGFuzz فازینگ پروتکل مبتنی بر بازخورد حالت را بیشتر بررسی کردهاند. AFLNET با استفاده از بازخورد کد وضعیت، ماشین حالت پروتکل را میسازد. در طول تولید بذر (Seed)، اگر یک توالی تست تولید شده باعث انتقال حالت جدید شود، به مجموعه بذر (Seed) اضافه میشود و حالت جدید در ماشین حالت گنجانده میشود.
AFLNET با محدودیتهایی مواجه است وقتی پروتکلها کدهای وضعیت ارائه نمیدهند و آن را بیاثر میکنند. StateAFL و SNPSFuzzer با گرفتن عکسهای فوری از سرور هدف، حالت پروتکل را استنباط میکنند و به تدریج ماشین حالت پروتکل را برای هدایت فرآیند فازینگ میسازند. آنها بذرها (Seed) و حالتهای جالب را بر اساس معیارهای بازخورد مانند پوشش حالت حفظ میکنند.
با این حال، دانهبندی آنها در سطح فرآیند است که ممکن است منجر به اختلاف ماشین حالت با حالت واقعی پروتکل شود. SGFuzz به طور خودکار متغیرهای حالت را در کد برنامه شناسایی میکند و با ساخت یک درخت انتقال حالت، تغییرات حالت پروتکل را ثبت میکند. این رویکرد به کد منبع پروتکل متکی است و برای آزمایش امنیتی پروتکلهای متنباز یا اختصاصی مناسب نیست.
6.4 آزمایش خودکار
در بخش ۶.۱ اشاره شده است که تکنیکهای فازینگ پروتکل مبتنی بر تولید، که توسط Peach و Boofuzz نمایندگی میشوند، نیازمند کمک دستی برای بهدستآوردن قالبهای پروتکل هستند و سطح خودکارسازی آنها نسبتاً پایین است. بنابراین، میتوان از تکنیکهای پردازش زبان طبیعی برای کمک به استخراج ماشینهای حالت پروتکل در مرحله استخراج قالبهای پروتکل استفاده کرد.
در مرحله استخراج ماشین حالت پروتکل، دو نوع رویکرد وجود دارد: استنباط غیرفعال و استنباط فعال. استنباط غیرفعال که نماینده آن PEXT است، مبتنی بر خوشهبندی پیامها برای استنباط ماشین حالت پروتکل عمل میکند. تحقیق در زمینه استنباط فعال عمدتاً بر اساس الگوریتم *L (الگوریتم یادگیری) انجام شده است، مانند ابزارهایی همچون LearnLib، Netzob، MACE و غیره، که فرض میکنند یک اوراکل وجود دارد که میتواند پاسخهای دقیقی به پرسشهای عضویت و پرسشهای همارزی ارائه دهد.
فرآیند به این صورت است: ابتدا یک جدول مشاهده بسته و پیوسته بر اساس پرسشهای عضویت ساخته میشود، سپس ماشین حالت کاندید M مربوطه تولید میگردد. پس از آن، از پرسشهای همارزی برای تعیین اینکه آیا M با ماشین حالت واقعی سازگار است یا خیر استفاده میشود. اگر پاسخ مثبت باشد، استنباط پایان مییابد؛ در غیر این صورت، یک مثال متقابل تولید شده و استنباط مجدداً انجام میگیرد.
یکی از چالشهای اصلی رویکرد مبتنی بر تولید این است که کارایی آن به تعداد پرسشهای تولیدشده و سرعت پاسخ اوراکل به پرسشها وابسته است. استنباط فعال مبتنی بر الگوریتم *L نیازمند تولید حجم زیادی پرسش است که منجر به کارایی پایین میشود.
در سالهای اخیر، تحقیقات در زمینه استنباط حالت پروتکل بر روی روشهای مبتنی بر یادگیری عمیق و تکنیکهای یادگیری ماشین نیز متمرکز شده است [۷۰، ۷۴]. با این حال، این روشها همچنان دارای محدودیتها و کاستیهایی هستند؛ برای مثال، برای آموزش مدل به حجم زیادی از دادههای آموزشی نیاز است و برای برخی پروتکلها ممکن است دستیابی به دادههای آموزشی کافی دشوار باشد، در نتیجه این روشها فقط برای پروتکلهای ساده مناسب هستند.
۷. زمینه توسعه تکنیک و مسیرهای آینده
در این بخش، با بحث در مورد برخی از مسیرهای احتمالی آینده فازینگ پروتکل و تکنیکهای مرتبط، به سوال سوم پاسخ میدهیم. اگرچه نمیتوانیم مسیرهای آیندهای را که مطالعه فازینگ پروتکل دنبال خواهد کرد، به طور دقیق پیشبینی کنیم، اما میتوانیم بر اساس مقالات بررسی شده، برخی از روندها را شناسایی و خلاصه کنیم.
۷.۱ زمینه توسعه
همانطور که قبلاً ذکر شد، AFL از زمان انتشارش در سال ۲۰۱۳، آسیبپذیریهای روز صفر متعددی را در نرمافزارهای متنباز اصلی کشف کرده است و به طور گسترده برای آزمایش اهداف مختلف استفاده و گسترش یافته است. موفقیت آن، ارزش تکنیکهای هدایتشده با پوشش کد را در فازینگ عملی نشان داده و نقش مهمی در توسعه تکنیکهای فازینگ ایفا میکند. با تجزیه و تحلیل روندهای توسعه، میتوانیم مشاهده کنیم که AFL تأثیر قابل توجهی بر تمرکز تحقیقاتی تکنیکهای فازینگ پروتکل شبکه داشته است.
با اشاره به شکل ۳، میتوانیم ببینیم که قبل از انتشار AFL، تمرکز تحقیقاتی پرسنل آزمایش بر روی تکنیکهای فازینگ جعبه سیاه بوده است. با این حال، پس از انتشار AFL، تکنیکهای فازینگ جعبه خاکستری به تدریج مورد توجه قرار گرفتند. بر اساس این یافتهها، میتوانیم در مورد روندهای توسعه زیر برای تکنیکهای فازینگ پروتکل شبکه گمانهزنی کنیم:
- با گذشت زمان، پرسنل تست، اطلاعات مربوط به پیادهسازی پروتکل را آسانتر به دست میآورند و بر اساس بازخوردهایی مانند پوشش وضعیت و پوشش کد، کارایی تست را بهبود میبخشند. در نتیجه، تعداد ابزارهای فازینگ جعبه سیاه که به تازگی منتشر شدهاند، احتمالاً به تدریج کاهش مییابد، در حالی که تعداد ابزارهای فازینگ جعبه خاکستری افزایش مییابد و بر چشمانداز فازینگ پروتکل شبکه تسلط پیدا میکنند.
- تعداد ابزارهای فازینگ جعبه سفید ممکن است افزایش یابد زیرا با بالغتر شدن تکنیکهای فازینگ پروتکل شبکه عمومی، الزامات خاصی برای فازینگ پروتکل شبکه نیز پدیدار میشود. به عنوان مثال، تکنیکهای فازینگ که کلیدهای رمزگذاری یا بررسیهای یکپارچگی را دور میزنند. دستیابی به این الزامات خاص تست، نیاز به درک جامعتری از اطلاعات مربوط به پیادهسازی پروتکل دارد، از این رو نیاز به تکنیکهای فازینگ جعبه سفید وجود دارد.
۷.۲ جهتگیریهای آینده
۷.۲.۱ اتوماسیون در تکنیکهای فازینگ مبتنی بر تولید
همانطور که قبلاً ذکر شد، تجزیه و تحلیل قالبهای پروتکل در فازینگ پروتکل شبکه نیازمند تلاش قابل توجهی است که آن را از سایر رویکردهای فازینگ متمایز میکند. تجزیه و تحلیل دستی قالبهای پروتکل شبکه تا حدودی اثربخشی موارد آزمایشی را بهبود میبخشد، اما هزینههای تحقیقاتی قابل توجهی را متحمل میشود. علاوه بر این، تجزیه و تحلیل باید دوباره برای پروتکلهای مختلف انجام شود که منجر به تلاش دستی بالا میشود. در نتیجه، ارزش عملی دسترسی دستی به قالبهای پروتکل شبکه تا حد زیادی کاهش مییابد. راهحلهای ممکن برای این مشکل عبارتند از:
۱. استفاده از NLP و سایر تکنیکهای هوش مصنوعی برای تجزیه و تحلیل خودکار اسناد مشخصات پروتکل و ردیابیهای شبکه، در نتیجه افزایش سطح اتوماسیون تجزیه و تحلیل قالب پروتکل و اتوماسیون کلی فازینگ. با این حال، پیادهسازی فعلی این رویکرد هنوز بهینه نیست و هنوز مسائل حل نشده زیادی وجود دارد. به عنوان مثال، قبل از تجزیه و تحلیل خودکار با استفاده از تکنیکهای هوش مصنوعی، حاشیهنویسی دستی اسناد پروتکل برای کمک به تولید ماشین حالت پروتکل مورد نیاز است.
۲. مدلهای زبان بزرگ LLM در حال حاضر یک حوزه پرطرفدار در تحقیقات هوش مصنوعی هستند، زیرا میتوانند متن با کیفیت بالا را بهتر درک و تولید کنند. در زمینه فازینگ پروتکل شبکه، آموزش LLM های اختصاصی برای تولید بستههای پروتکل ناقص ارزشمند است. این رویکرد میتواند به غلبه بر تلاش دستی قابل توجه در تکنیکهای فازینگ مبتنی بر تولید موجود کمک کند.
۷.۲.۲ بهبود کارایی در تکنیکهای فازینگ
در فازینگ پروتکل شبکه، اثربخشی موارد آزمایشی برای کشف آسیبپذیریهای ناشناخته بسیار مهم است. موارد آزمایشی کارآمد، نرخ جهش، نرخ پذیرش و پوشش کد بالایی را نشان میدهند. بهینهسازی استراتژیهای انتخاب موارد آزمایشی و اطمینان از استفاده از حداقل مجموعههای مورد آزمایشی برای کشف هرچه بیشتر آسیبپذیریهای بالقوه، موضوعات داغی در تحقیقات آینده در مورد فازینگ پروتکل شبکه هستند. راهحلهای ممکن برای بررسی عبارتند از:
- با تغییر استراتژی جهش، تکنیک فازینگ پروتکل مبتنی بر جهش میتواند موارد آزمایشی ایجاد کند که با ویژگیهای بستههای داده پروتکل مطابقت بهتری داشته باشند و در نتیجه میزان موفقیت اعتبارسنجی را افزایش دهند. استراتژیهای جهش شامل رویکردهای مختلفی مانند استراتژی جهش سه سطحی به کار رفته در SPFuzz، استراتژیهای جهش ساختاریافته آگاه از متن و غیره میشود.
- ترکیب مدلهای شبکه عصبی با تکنیکهای فازینگ پروتکل شبکه برای استخراج قوانین و دانش از دادههای انبوه. مدل شبکه عصبی میتواند به طور خودکار موارد تست نامعتبر را فیلتر کند و در نتیجه کارایی فازینگ را بهبود بخشد.
- اعمال اصول فازینگ جهتدار و اعمال محدودیتهای خاص در طول مرحله تولید موارد تست برای تولید موارد تستی که کد/وضعیت هدف را پوشش میدهند. این بخشهای کد/وضعیت هدف به احتمال زیاد باعث ایجاد رویدادهای امنیتی در پروتکل میشوند. آزمایش این بخشهای کد/وضعیت میتواند منجر به کارایی بالاتر آزمایش شود.
7.2.3 تنوع اهداف تست در فازینگ پروتکل شبکه
در تکنیکهای فازینگ پروتکل شبکه فعلی، اهداف تست عمدتاً به معماری کلاینت/سرور پایبند هستند. کل فرآیند آزمایش شامل ارتباط بین فازر و پیادهسازی پروتکل است، به طوری که فازر موارد آزمایش را به پیادهسازی پروتکل ارسال میکند. پشتیبانی محدودی برای پروتکلهای چندطرفه یا پروتکلهایی که کاربران موقعیتهای نسبتاً برابری دارند، وجود دارد. علاوه بر این، از نظر سلسله مراتب شبکه، تمرکز بیشتری بر آزمایش یک پروتکل ساده لایه کاربرد مانند پروتکل انتقال فایل FTP و تأکید کمتری بر پروتکلهای سطح پایینتر و پیچیدهتر وجود دارد. برای پروتکلهای سطح پایینتر، پیادهسازیهای پروتکل مربوطه ممکن است وجود نداشته باشند. برای فازر، مشاهده رفتارهای غیرعادی مانند خرابیها در پیادهسازی پروتکل برای تعیین کشف آسیبپذیریهای جدید، چالش برانگیز است.
با این حال، برای پروتکلهای مختلف، میتوان رویدادهای امنیتی خاصی را تعریف کرد و موفقیت آزمایش را میتوان به طور غیرمستقیم از طریق سایر معیارهای شبکه ارزیابی کرد. به عنوان مثال، تغییرات در توان عملیاتی یا تغییرات در جدول مسیریابی را میتوان مشاهده کرد تا مشخص شود که آیا فازر آسیبپذیریهایی را کشف کرده است یا خیر.
7.2.4 تکنیکهای مرتبط با فازینگ پروتکل شبکه
روش یادگیری فعال مبتنی بر الگوریتم *L در حال حاضر به طور گسترده برای استنتاج ماشین حالت پروتکل به کار میرود، اما هنوز با چالشهای متعددی روبرو است. یکی از مسائل اصلی، پرسوجوهای عضویت بیش از حد است که ممکن است منجر به مجموعه نمونههای ناقص مثال نقض شود و به طور بالقوه بر دقت ماشین حالت پروتکل استنتاج شده تأثیر بگذارد. علاوه بر این، این روش ممکن است هنگام برخورد با پروتکلهای پیچیده از مشکلات تعمیم رنج ببرد، به این معنی که ممکن است نتواند رفتارهای خاصی از ماشین حالت پروتکل را به درستی استنباط کند. برای پرداختن به این چالشها، تحقیقات آینده میتواند زمینههای زیر را برای گسترش و بهبود بررسی کند.
اول، گنجاندن دنباله روابط محدودیت بین پیامها در استنتاج ماشین حالت پروتکل میتواند رفتار واقعی پروتکل را بهتر منعکس کند، زیرا پیامها در یک پروتکل اغلب درجه خاصی از ترتیب زمانی دارند. دوم، بررسی همبستگیهای ساختاری بین مثالهای نقض و مثالهای مثبت ممکن است به تولید مؤثرتر مثالهای نقض و کاهش تعداد پرسوجوهای عضویت کمک کند. علاوه بر این، بهینهسازی فرآیند تولید پرسوجوها و مثالهای نقض میتواند عملکرد روش را بهبود بخشد، مانند استفاده از الگوریتمها یا استراتژیهای کارآمدتر برای تولید پرسوجوها و مثالهای نقض.
در نهایت، ترکیب روش یادگیری فعال با سایر روشهای رسمی میتواند دقت و قابلیت اطمینان استنتاج ماشین حالت پروتکل را بهبود بخشد. به عنوان مثال، استفاده از بررسی مدل برای تأیید صحت ماشین حالت پروتکل استنتاج شده یا ترکیب روش یادگیری فعال با سایر تکنیکهای یادگیری ماشین برای بهبود کارایی و دقت استنتاج. برای ارزیابی تکنیکهای فازینگ پروتکل، Profuzzbench در حال حاضر فقط از پوشش کد به عنوان معیاری برای مقایسه پشتیبانی میکند و فازرهای موجود شامل تکنیکهای فازینگ مبتنی بر تولید نمیشوند. در مجموعههای تست معیار آینده، توصیه میشود که مجموعههای تستی که شامل تکنیکهای فازینگ مبتنی بر تولید هستند، گنجانده شوند و تکنیکهای فازینگ پروتکل بر اساس معیارهای متعدد، از جمله تعداد اشکالات کشف شده، زمان مورد نیاز برای آزمایش همان اشکال، پوشش وضعیت و سایر شاخصهای مرتبط، ارزیابی شوند.
8. نتیجهگیری
تکنیکهای کشف آسیبپذیری پروتکل شبکه برای تضمین ارتباطات امن شبکه ضروری هستند. در میان تکنیکهای مختلف کشف آسیبپذیری، فازینگ به لطف پیچیدگی کم استقرار و حداقل الزامات دانش قبلی در مورد SUT، توجه گستردهای را به خود جلب میکند.
این مقاله، تولید، توسعه و کاربرد فازینگ پروتکل شبکه و تکنیکهای مرتبط مختلف را بر اساس یک جدول زمانی بررسی و خلاصه میکند. با شروع از مقدمه، تجزیه و تحلیل اصول کار و روشهای طبقهبندی تکنیکهای فازینگ پروتکل شبکه، مروری بر پیشرفت تحقیقات در این زمینه از دیدگاه تکنیکهای فازینگ جعبه سفید، جعبه خاکستری و جعبه سیاه ارائه میدهیم. هر یک از این دیدگاهها شامل معرفی ابزارها و روشهای معمول است. بر اساس تجزیه و تحلیل تقریباً پنجاه مقاله مرتبط در طول دو دهه گذشته، این مقاله الگوهای توسعه و مسائل موجود در تکنیکهای فازینگ پروتکل شبکه را خلاصه میکند و تکنیکهای NLP را که میتوانند با تکنیکهای فازینگ پروتکل ترکیب شوند، معرفی میکند. علاوه بر این، این مقاله چشماندازهایی را برای جهتگیریهای تحقیقاتی آینده در این زمینه ارائه میدهد و هدف آن کمک به توسعه کارآمد کارهای تحقیقاتی در این حوزه است.
9. منابع
CVE-2014-0160. Available online: https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2014-0160(accessed on 6 March 2023).
NAME: WRECK DNS Vulnerabilities Affect over 100 Million Devices. Available online: https://www.bleepingcomputer.com/news/security/name-wreck-dns-vulnerabilities-affect-over-100-million-devices/(accessed on 6 March 2023).
Miller, B.P.; Fredriksen, L.; So, B. An empirical study of the reliability of UNIX utilities. ACM1990, 33, 32–44. [Google Scholar] [CrossRef]
Miller, B.P.; Koski, D.; Lee, C.P.; Maganty, V.; Murthy, R.; Natarajan, A.; Steidl, J. Fuzz Revisited: A Re-Examination of the Reliability of UNIX Utilities and Services; Technical Report; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 1995. [Google Scholar]
Forrester, J.E.; Miller, B.P. An Empirical Study of the Robustness of Windows NT Applications Using Random Testing. In Proceedings of the 4th Conference on USENIX Windows Systems Symposium—Volume 4, Seattle, WA, USA, 3 August 2000; WSS’00. p. 6. [Google Scholar]
Miller, B.P.; Cooksey, G.; Moore, F. An empirical study of the robustness of macos applications using random testing. In Proceedings of the 1st International Workshop on Random Testing, Portland, ME, USA, 17 July 2006; pp. 46–54. [Google Scholar]
Liang, H.; Pei, X.; Jia, X.; Shen, W.; Zhang, J. Fuzzing: State of the art. IEEE Trans. Reliab.2018, 67, 1199–1218. [Google Scholar] [CrossRef]
Oehlert, P. Violating assumptions with fuzzing. IEEE Secur. Priv.2005, 3, 58–62. [Google Scholar] [CrossRef]
Viide, J.; Helin, A.; Laakso, M.; Pietikäinen, P.; Seppänen, M.; Halunen, K.; Puuperä, R.; Röning, J. Experiences with Model Inference Assisted Fuzzing. WOOT2008, 2, 1–2. [Google Scholar]
Yang, H.; Zhang, Y.; Hu, Y.P.; Liu, Q.X. IKE vulnerability discovery based on fuzzing. Commun. Netw.2013, 6, 889–901. [Google Scholar] [CrossRef]
Yan, J.; Zhang, Y.; Yang, D. Structurized grammar-based fuzz testing for programs with highly structured inputs. Commun. Netw.2013, 6, 1319–1330. [Google Scholar] [CrossRef]
Palsetia, N.; Deepa, G.; Khan, F.A.; Thilagam, P.S.; Pais, A.R. Securing native XML database-driven web applications from XQuery injection vulnerabilities. Syst. Softw.2016, 122, 93–109. [Google Scholar] [CrossRef]
Li, J.; Zhao, B.; Zhang, C. Fuzzing: A survey. Cybersecurity2018, 1, 1–13. [Google Scholar] [CrossRef]
Manès, V.J.; Han, H.; Han, C.; Cha, S.K.; Egele, M.; Schwartz, E.J.; Woo, M. The art, science, and engineering of fuzzing: A survey. IEEE Trans. Softw. Eng.2019, 47, 2312–2331. [Google Scholar] [CrossRef]
Munea, T.L.; Lim, H.; Shon, T. Network protocol fuzz testing for information systems and applications: A survey and taxonomy. Tools Appl.2016, 75, 14745–14757. [Google Scholar] [CrossRef]
Hu, Z.; Pan, Z. A systematic review of network protocol fuzzing techniques. In Proceedings of the 2021 IEEE 4th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 18–20 June 2021; Volume 4, pp. 1000–1005. [Google Scholar]
DeMott, J. The evolving art of fuzzing. In Proceedings of the DEF CON 14, Las Vegas, NV, USA, 4–6 August 2006; pp. 1–25. [Google Scholar]
Godefroid, P.; Levin, M.Y.; Molnar, D.A. Automated whitebox fuzz testing. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2008, San Diego, CA, USA, 8 February 2008; Volume 8, pp. 151–166. [Google Scholar]
Godefroid, P.; Levin, M.Y.; Molnar, D. SAGE: Whitebox fuzzing for security testing. ACM2012, 55, 40–44. [Google Scholar] [CrossRef]
Kaksonen, R.; Laakso, M.; Takanen, A. Software security assessment through specification mutations and fault injection. In Proceedings of the Communications and Multimedia Security Issues of the New Century: IFIP TC6/TC11 Fifth Joint Working Conference on Communications and Multimedia Security (CMS’01), Darmstadt, Germany, 21–22 May 2001; pp. 173–183. [Google Scholar]
Aitel, D. The Advantages of Block-Based Protocol Analysis for Security Testing; Immunity Inc.: Miami Beach, FL, USA, 2002; Volume 105, p. 106. [Google Scholar]
Peach Fuzzer. Available online: https://peachtech.gitlab.io/peach-fuzzer-community/(accessed on 2 March 2023).
Banks, G.; Cova, M.; Felmetsger, V.; Almeroth, K.; Kemmerer, R.; Vigna, G. SNOOZE: Toward a Stateful NetwOrk prOtocol fuzZEr. In Proceedings of the Information Security 9th International Conference, ISC 2006, Samos Island, Greece, 30 August–2 September 2006; Volume 4176, pp. 343–358. [Google Scholar]
Abdelnur, H.J.; State, R.; Festor, O. KiF: A stateful SIP fuzzer. In Proceedings of the 1st International Conference on Principles, Systems and Applications of IP Telecommunications, New York, NY, USA, 19 July 2007; pp. 47–56. [Google Scholar]
Dynamic Application Security Testing Tool (DAST). BeSTORM. Available online: https://www.beyondsecurity.com/solutions/bestorm-dynamic-application-security-testing(accessed on 2 March 2023).
A Pure-Python Fully Automated and Unattended Fuzzing Framework. Available online: https://github.com/OpenRCE/sulley(accessed on 2 March 2023).
A Fork and Successor of the Sulley Fuzzing Framework. Available online: https://github.com/jtpereyda/boofuzz(accessed on 2 March 2023).
Vuagnoux, M. Autodafe: An act of software torture. In Proceedings of the 22th Chaos Communication Congress, Chaos Computer Club, Berlin, Germany, 26 August 2005; pp. 47–58. [Google Scholar]
Gorbunov, S.; Rosenbloom, A. Autofuzz: Automated network protocol fuzzing framework. Ijcsns2010, 10, 239. [Google Scholar]
Kitagawa, T.; Hanaoka, M.; Kono, K. Aspfuzz: A state-aware protocol fuzzer based on application-layer protocols. In Proceedings of the IEEE Symposium on Computers and Communications, Riccione, Italy, 22–25 June 2010; pp. 202–208. [Google Scholar]
Tsankov, P.; Dashti, M.T.; Basin, D. SECFUZZ: Fuzz-testing security protocols. In Proceedings of the 2012 7th International Workshop on Automation of Software Test (AST), Zurich, Switzerland, 2–3 June 2012; pp. 1–7. [Google Scholar]
Rontti, T.; Juuso, A.M.; Takanen, A. Preventing DoS attacks in NGN networks with proactive specification-based fuzzing. IEEE Commun. Mag.2012, 50, 164–170. [Google Scholar] [CrossRef]
Han, X.; Wen, Q.; Zhang, Z. A mutation-based fuzz testing approach for network protocol vulnerability detection. In Proceedings of the 2012 2nd International Conference on Computer Science and Network Technology, Changchun, China, 29–31 December 2012; pp. 1018–1022. [Google Scholar]
Brubaker, C.; Jana, S.; Ray, B.; Khurshid, S.; Shmatikov, V. Using frankencerts for automated adversarial testing of certificate validation in SSL/TLS implementations. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 114–129. [Google Scholar]
SSL and TLS Protocol Test Suite and Fuzzer. Available online: https://github.com/tlsfuzzer/tlsfuzzer(accessed on 2 March 2023).
Gascon, H.; Wressnegger, C.; Yamaguchi, F.; Arp, D.; Rieck, K. Pulsar: Stateful black-box fuzzing of proprietary network protocols. In Proceedings of the Security and Privacy in Communication Networks: 11th EAI International Conference, SecureComm 2015, Dallas, TX, USA, 26–29 October 2015; pp. 330–347. [Google Scholar]
Somorovsky, J. Systematic fuzzing and testing of TLS libraries. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1492–1504. [Google Scholar]
Ma, R.; Wang, D.; Hu, C.; Ji, W.; Xue, J. Test data generation for stateful network protocol fuzzing using a rule-based state machine. Tsinghua Sci. Technol.2016, 21, 352–360. [Google Scholar] [CrossRef]
Blumbergs, B.; Vaarandi, R. Bbuzz: A bit-aware fuzzing framework for network protocol systematic reverse engineering and analysis. In Proceedings of the MILCOM 2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; pp. 707–712. [Google Scholar]
OpenAPI 2.0 (Swagger) Fuzzer Written in Python. Available online: https://github.com/Teebytes/TnT-Fuzzer(accessed on 4 April 2023).
HTTP API Testing Framework. Available online: https://github.com/KissPeter/APIFuzzer(accessed on 4 April 2023).
American Fuzzy Lop. Available online: https://lcamtuf.coredump.cx/afl/(accessed on 2 March 2023).
Wang, T.; Wei, T.; Gu, G.; Zou, W. TaintScope: A checksum-aware directed fuzzing tool for automatic software vulnerability detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 16–19 May 2010; pp. 497–512. [Google Scholar]
Atlidakis, V.; Godefroid, P.; Polishchuk, M. Restler: Stateful rest api fuzzing. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 748–758. [Google Scholar]
Fiterau-Brostean, P.; Jonsson, B.; Merget, R.; De Ruiter, J.; Sagonas, K.; Somorovsky, J. Analysis of DTLS implementations using protocol state fuzzing. In Proceedings of the 29th USENIX Security Symposium, Online, 12–14 August 2020; pp. 2523–2540. [Google Scholar]
libFuzzer—A Library for Coverage-Guided Fuzz Testing. Available online: http://llvm.org/docs/LibFuzzer.html(accessed on 4 April 2023).
Petsios, T.; Tang, A.; Stolfo, S.; Keromytis, A.D.; Jana, S. Nezha: Efficient domain-independent differential testing. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 615–632. [Google Scholar]
Song, C.; Yu, B.; Zhou, X.; Yang, Q. SPFuzz: A hierarchical scheduling framework for stateful network protocol fuzzing. IEEE Access2019, 7, 18490–18499. [Google Scholar] [CrossRef]
Chen, Y.; Lan, T.; Venkataramani, G. Exploring effective fuzzing strategies to analyze communication protocols. In Proceedings of the 3rd ACM Workshop on Forming an Ecosystem Around Software Transformation, London, UK, 15 November 2019; pp. 17–23. [Google Scholar]
Pham, V.T.; Böhme, M.; Roychoudhury, A. AFLNet: A greybox fuzzer for network protocols. In Proceedings of the 2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST), Porto, Portugal, 24–28 October 2020; pp. 460–465. [Google Scholar]
Zou, Y.H.; Bai, J.J.; Zhou, J.; Tan, J.; Qin, C.; Hu, S.M. TCP-Fuzz: Detecting Memory and Semantic Bugs in TCP Stacks with Fuzzing. In Proceedings of the USENIX Annual Technical Conference, Virtual Event, 14–16 July 2021; pp. 489–502. [Google Scholar]
Natella, R. Stateafl: Greybox fuzzing for stateful network servers. Softw. Eng.2022, 27, 191. [Google Scholar] [CrossRef]
Li, J.; Li, S.; Sun, G.; Chen, T.; Yu, H. SNPSFuzzer: A Fast Greybox Fuzzer for Stateful Network Protocols using Snapshots. IEEE Trans. Inf. Forensics Secur.2022, 17, 2673–2687. [Google Scholar] [CrossRef]
Ba, J.; Böhme, M.; Mirzamomen, Z.; Roychoudhury, A. Stateful greybox fuzzing. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 3255–3272. [Google Scholar]
Alshmrany, K.; Cordeiro, L. Finding security vulnerabilities in network protocol implementations. arXiv2020, arXiv:2001.09592. [Google Scholar]
Leita, C.; Mermoud, K.; Dacier, M. Scriptgen: An automated script generation tool for honeyd. In Proceedings of the 21st Annual Computer Security Applications Conference (ACSAC’05), Tucson, AZ, USA, 5–9 December 2005; p. 12. [Google Scholar]
Shevertalov, M.; Mancoridis, S. A reverse engineering tool for extracting protocols of networked applications. In Proceedings of the 14th Working Conference on Reverse Engineering (WCRE 2007), Vancouver, BC, Canada, 28–31 October 2007; pp. 229–238. [Google Scholar]
Comparetti, P.M.; Wondracek, G.; Kruegel, C.; Kirda, E. Prospex: Protocol specification extraction. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Oakland, CA, USA, 17–20 May 2009; pp. 110–125. [Google Scholar]
Wondracek, G.; Comparetti, P.M.; Kruegel, C.; Kirda, E.; Anna, S.S.S. Automatic Network Protocol Analysis. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2008, San Diego, CA, USA, 8 February 2008; Volume 8, pp. 1–14. [Google Scholar]
Gold, E.M. Language identification in the limit. Control1967, 10, 447–474. [Google Scholar] [CrossRef]
Angluin, D. Learning regular sets from queries and counterexamples. Comput.1987, 75, 87–106. [Google Scholar] [CrossRef]
Cho, C.Y.; Babić, D.; Poosankam, P.; Chen, K.Z.; Wu, E.X.; Song, D. MACE: Model-Inference-Assisted Concolic Exploration for Protocol and Vulnerability Discovery. In Proceedings of the 20th USENIX Conference on Security, San Francisco, CA, USA, 8–12 August 2011; p. 10. [Google Scholar]
Protocol Reverse Engineering, Modeling and Fuzzing. Available online: https://github.com/netzob/netzob(accessed on 2 March 2023).
Beddoe, M.A. Network protocol analysis using bioinformatics algorithms. Toorcon2004, 26, 1095–1098. [Google Scholar]
Wang, Y.; Zhang, Z.; Yao, D.D.; Qu, B.; Guo, L. Inferring Protocol State Machine from Network Traces: A Probabilistic Approach. In Proceedings of the 9th International Conference on Applied Cryptography and Network Security, Nerja, Spain, 7–10 June 2011; pp. 1–18. [Google Scholar]
De Ruiter, J.; Poll, E. Protocol state fuzzing of {TLS} implementations. In Proceedings of the 24th {USENIX} Security Symposium ({USENIX} Security 15), Washington, DC, USA, 12–14 August 2015; pp. 193–206. [Google Scholar]
Liu, Y.; Xie, P.; Wang, Y.; Liu, M. Inference of protocol state machine using a semantic-related labeling method based on dynamic taint analysis. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 258–262. [Google Scholar]
Jero, S.; Pacheco, M.L.; Goldwasser, D.; Nita-Rotaru, C. Leveraging textual specifications for grammar-based fuzzing of network protocols. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, 27 January–1 February 2019; Volume 33, pp. 9478–9483. [Google Scholar]
Pacheco, M.L.; von Hippel, M.; Weintraub, B.; Goldwasser, D.; Nita-Rotaru, C. Automated attack synthesis by extracting finite state machines from protocol specification documents. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 27 July 2022; pp. 51–68. [Google Scholar]
Lin, Y.D.; Lai, Y.K.; Bui, Q.T.; Lai, Y.C. ReFSM: Reverse engineering from protocol packet traces to test generation by extended finite state machines. Netw. Comput. Appl.2020, 171, 102819. [Google Scholar] [CrossRef]
Goo, Y.H.; Shim, K.S.; Kim, M.S. Automatic Reverse Engineering Method for Extracting Well-trimmed Protocol Specification. In Proceedings of the 2nd International Conference on Telecommunications and Communication Engineering, Beijing, China, 28 November 2018; pp. 16–21. [Google Scholar]
Natella, R.; Pham, V.T. Profuzzbench: A benchmark for stateful protocol fuzzing. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, New York, NY, USA, 11 July 2021; pp. 662–665. [Google Scholar]
Liu, D.; Pham, V.T.; Ernst, G.; Murray, T.; Rubinstein, B.I. State Selection Algorithms and Their Impact on The Performance of Stateful Network Protocol Fuzzing. In Proceedings of the 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Honolulu, HI, USA, 15–18 March 2022; pp. 720–730. [Google Scholar]
Hagos, D.H.; Engelstad, P.E.; Yazidi, A.; Kure, Ø. General TCP state inference model from passive measurements using machine learning techniques. IEEE Access2018, 6, 28372–28387. [Google Scholar] [CrossRef]