
کامپایلر (Compiler) یکی از بنیادیترین مؤلفههای زیرساخت نرمافزارهای مدرن است و نقشی محوری در تبدیل ایدههای انتزاعی برنامهنویسان به دستورالعملهای قابل اجرای سختافزار ایفا میکند. هر برنامهی کامپیوتری، صرفنظر از میزان پیچیدگی یا سادگی آن، پیش از اجرا باید از مرحلهای عبور کند که در آن توصیف سطح بالای رفتار برنامه به شکلی قابل فهم برای ماشین تبدیل شود. این وظیفه بر عهدهی کامپایلر است؛ ابزاری که به عنوان واسطی ضروری میان زبان انسانمحور برنامهنویسی و زبان ماشین عمل میکند.
اهمیت کامپایلرها زمانی روشنتر میشود که به محدودیتهای ذاتی سختافزار توجه کنیم. پردازندهها تنها قادر به اجرای دستوراتی بسیار ساده و دقیق هستند که در قالب زبان ماشین بیان میشوند، در حالی که زبانهای برنامهنویسی سطح بالا برای بیان مفاهیم پیچیده، ساختارهای انتزاعی و منطقهای سطح انسانی طراحی شدهاند. فاصلهی عمیق میان این دو دنیا باعث میشود که وجود یک سامانهی ترجمهی خودکار، دقیق و قابل اعتماد نهتنها مفید، بلکه اجتنابناپذیر باشد. بدون چنین سامانهای، توسعهی نرمافزارهای بزرگ، قابل نگهداری و قابل توسعه عملاً غیرممکن میشد و برنامهنویسان ناچار بودند مستقیماً با جزئیات پیچیده و خطاپذیر زبان ماشین یا اسمبلی کار کنند.
با این حال، کامپایلر صرفاً یک مترجم سادهی متنی نیست. فرآیند کامپایل شامل تحلیل دقیق ساختار و معنای برنامه، تشخیص و گزارش خطاها، و در بسیاری موارد بهینهسازی کد برای دستیابی به کارایی بالاتر است. تصمیمهایی که در مراحل مختلف کامپایل گرفته میشوند، میتوانند تأثیر مستقیمی بر سرعت اجرا، مصرف حافظه، و حتی قابلیت اطمینان برنامهی نهایی داشته باشند. از این رو، کامپایلرها نه تنها بر نحوهی اجرای برنامهها، بلکه بر شیوهی طراحی زبانهای برنامهنویسی و معماری سیستمهای نرمافزاری نیز اثرگذار بودهاند.
مطالعهی ساختار درونی کامپایلرها فراتر از یک موضوع تخصصی برای طراحان زبان یا مهندسان سیستم است. درک این ساختار به برنامهنویس کمک میکند تا بداند کد او چگونه تفسیر و پردازش میشود، خطاها در چه مراحلی تشخیص داده میشوند، و چرا برخی الگوهای کدنویسی کارآمدتر یا ایمنتر از دیگران هستند. بسیاری از مفاهیم کلیدی در حوزههایی مانند تحلیل ایستای کد، بهینهسازی برنامه، امنیت نرمافزار و حتی پردازش زبان طبیعی، ریشه در اصول طراحی کامپایلرها دارند.
1. زبانهای برنامهنویسی و ضرورت ترجمه
زبانهای برنامهنویسی ساختارهایی نمادین برای توصیف محاسبات هستند که بهگونهای طراحی شدهاند تا هم برای انسان قابل فهم باشند و هم بتوانند رفتار مورد نظر را در قالبی دقیق و صوری بیان کنند. تمام نرمافزارهایی که امروزه روی سامانههای کامپیوتری اجرا میشوند، از سادهترین برنامههای کاربردی تا پیچیدهترین سیستمعاملها و سامانههای توزیعشده، در نهایت در یکی از این زبانها نوشته شدهاند. با این حال، صرفِ نوشتن برنامه به یک زبان برنامهنویسی برای اجرا شدن آن کافی نیست؛ پیش از اجرا، برنامه باید به شکلی بازنمایی شود که سختافزار کامپیوتر قادر به درک و اجرای آن باشد.
نکتهی اساسی در اینجا تفاوت بنیادین میان زبانهای برنامهنویسی سطح بالا و زبان ماشین است. زبانهای سطح بالا با هدف افزایش خوانایی، قابلیت نگهداری و بیان مفاهیم انتزاعی طراحی شدهاند، در حالی که پردازندهها تنها میتوانند دنبالهای از دستورهای بسیار ساده را اجرا کنند که در قالب زبان ماشین و معمولاً به صورت صفر و یک نمایش داده میشوند. این شکاف مفهومی و ساختاری میان زبان انسانمحور و زبان ماشین، ضرورت وجود یک فرآیند ترجمهی ساختارمند و دقیق را ایجاد میکند.
سیستمهای نرمافزاری که وظیفهی انجام این ترجمه را بر عهده دارند، کامپایلرها نامیده میشوند. کامپایلر کد منبع نوشتهشده توسط برنامهنویس را دریافت میکند و آن را به شکلی معادل، اما قابل اجرا برای ماشین، تبدیل مینماید. این فرآیند صرفاً یک جایگزینی مکانیکی نمادها نیست، بلکه شامل تحلیل ساختار برنامه، بررسی صحت آن از نظر قواعد زبان، تشخیص خطاها و در بسیاری موارد بهینهسازی کد برای دستیابی به عملکرد بهتر است. به همین دلیل، ترجمهی برنامه یک فعالیت پیچیده و چندمرحلهای محسوب میشود که نقش مستقیمی در کیفیت و کارایی نرمافزار نهایی دارد.
بدون وجود چنین فرآیند ترجمهای، اجرای برنامههای پیچیدهی امروزی عملاً غیرممکن میبود. برنامهنویسان مجبور میشدند مستقیماً با زبان ماشین یا اسمبلی کار کنند، امری که نهتنها توسعهی نرمافزار را بسیار کند و پرخطا میکرد، بلکه نگهداری و گسترش سیستمها را نیز به شدت دشوار میساخت. در این معنا، کامپایلرها بهعنوان پلی میان ذهن برنامهنویس و سختافزار کامپیوتر عمل میکنند و امکان میدهند که مفاهیم سطح بالا و انتزاعی به شکلی کارآمد و قابل اعتماد به اجرا درآیند.
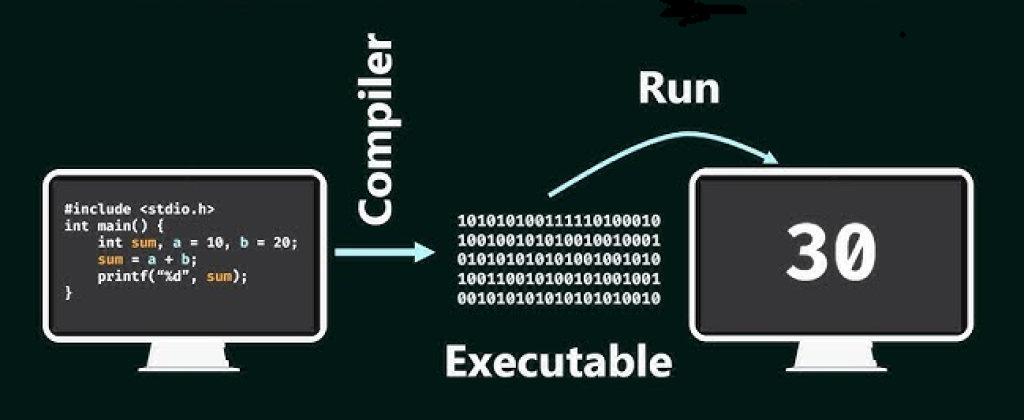
2. تعریف دقیق کامپایلر و جایگاه آن در سیستمهای نرمافزاری
بهطور دقیق، کامپایلر یک برنامهی نرمافزاری است که وظیفه دارد یک برنامه را که در یک زبان مشخص، موسوم به زبان منبع، نوشته شده است دریافت کند و آن را به برنامهای معادل در زبانی دیگر، موسوم به زبان هدف، ترجمه نماید. معادل بودن در اینجا به این معناست که رفتار برنامهی ترجمهشده از نظر معنایی با رفتار برنامهی اولیه یکسان باشد، حتی اگر ساختار، نمایش و سطح انتزاع دو زبان کاملاً متفاوت باشد. یکی از نقشهای اساسی کامپایلر در این فرآیند، تشخیص و گزارش خطاهایی است که در برنامهی منبع وجود دارند و مانع از ترجمهی صحیح یا اجرای درست برنامه میشوند. این خطاها میتوانند از نقض قواعد نحوی زبان گرفته تا ناسازگاریهای معنایی و منطقی را شامل شوند.
در حالتی که زبان هدف، زبان ماشین یک معماری خاص باشد، خروجی کامپایلر یک برنامهی قابل اجرا تولید میکند. این برنامهی اجرایی میتواند مستقیماً توسط کاربر یا سیستمعامل فراخوانی شود، ورودیها را دریافت کند، محاسبات لازم را انجام دهد و خروجیهای مورد انتظار را تولید نماید. در این سناریو، کامپایلر نقشی کلیدی در تبدیل توصیف انتزاعی یک مسئله به دنبالهای از دستورهای دقیق و سطح پایین ایفا میکند که پردازنده قادر به اجرای آنهاست.
کامپایلرها جایگاهی مرکزی و بنیادین در سیستمهای نرمافزاری دارند. آنها بهعنوان واسطهای ضروری میان برنامهنویس و سختافزار عمل میکنند و امکان میدهند که انسانها با زبانهایی سطح بالا، خوانا و ساختیافته برنامهنویسی کنند، در حالی که اجرای واقعی برنامه بر عهدهی ماشین است. بدون وجود کامپایلرها، توسعهی نرمافزارهای پیچیده و مقیاسپذیر عملاً غیرممکن میبود، زیرا برنامهنویسان ناچار میشدند مستقیماً به زبان ماشین یا در بهترین حالت اسمبلی برنامه بنویسند. چنین کاری نهتنها زمانبر و مستعد خطا است، بلکه نگهداری، توسعه و تحلیل سیستمهای نرمافزاری بزرگ را به شدت دشوار میسازد.
نقش کامپایلر صرفاً به ترجمهی کد محدود نمیشود. کامپایلرها با تشخیص خطاها در مراحل اولیهی توسعه، از گسترش خطاها به مراحل بعدی جلوگیری میکنند و در نتیجه کیفیت کلی نرمافزار را افزایش میدهند. افزون بر این، آنها با اعمال انواع بهینهسازیها، مانند کاهش مصرف حافظه، بهبود زمان اجرا یا استفادهی مؤثرتر از منابع سختافزاری، عملکرد برنامهی نهایی را بهطور قابل توجهی ارتقا میبخشند. این بهینهسازیها اغلب بهگونهای انجام میشوند که برای برنامهنویس شفاف هستند، اما تأثیر مستقیمی بر کارایی سیستم دارند.
در اکوسیستم ابزارهای توسعهی نرمافزار، کامپایلر تنها یکی از اجزای یک زنجیرهی کامل است. در یک فرآیند متداول ساخت برنامه، کامپایلر کد منبع را به کد میانی، کد اسمبلی یا مستقیماً به کد ماشین تبدیل میکند. سپس ابزارهایی مانند اسمبلر، لینککننده و لودر وارد عمل میشوند تا اجزای مختلف برنامه و کتابخانهها را به یکدیگر متصل کرده و برنامهی نهایی را برای اجرا آماده سازند. کامپایلرها همچنین با ابزارهایی نظیر ویرایشگرهای کد، دیباگرها، سیستمهای ساخت و سیستمهای کنترل نسخه یکپارچه میشوند و بدین ترتیب چرخهی کامل توسعهی نرمافزار را پشتیبانی میکنند.
فراتر از کاربرد مستقیم در ترجمهی زبانهای برنامهنویسی، اصول و تکنیکهای طراحی کامپایلرها در حوزههای دیگر سیستمهای نرمافزاری نیز به کار گرفته میشوند. برای مثال، تحلیل نحوی و معنایی که از مراحل اصلی کامپایل است، در پردازش زبان طبیعی، تفسیر زبانهای اسکریپتی، و حتی در ابزارهای امنیتی برای تحلیل و شناسایی کدهای مخرب مورد استفاده قرار میگیرد. همچنین در حوزههایی مانند سیستمهای جاسازیشده، ابررایانش و هوش مصنوعی، وجود کامپایلرهایی که بتوانند کد را بهصورت بهینه برای سختافزارهای خاص ترجمه کنند، امری حیاتی به شمار میآید.
در مجموع، کامپایلر را نمیتوان صرفاً یک ابزار ترجمه دانست. کامپایلر یک جزء بنیادی در معماری سیستمهای نرمافزاری است که امکان توسعه، تحلیل، بهینهسازی، نگهداری و اجرای نرمافزارهای مدرن را فراهم میکند. بدون آن، فاصلهی عمیق میان زبانهای سطح بالا و زبان ماشین پر نمیشد و پیشرفت کنونی نرمافزار و سیستمهای محاسباتی قابل تصور نبود.
3. پردازشگرهای زبان (Language Processors)
پردازشگرهای زبان ابزارهایی هستند که برای ترجمه یا اجرای برنامههای نوشتهشده در زبانهای برنامهنویسی استفاده میشوند. آنها نقش حیاتی در تبدیل کد منبع به فرمی قابل اجرا توسط کامپیوتر ایفا میکنند. پردازشگرهای زبان به عنوان سیستمهایی معرفی میشوند که برنامه را از یک زبان به زبان دیگر ترجمه میکنند یا مستقیماً اجرا میکنند. این پردازشگرها شامل کامپایلرها، مفسرها و سیستمهای هیبریدی هستند که ترکیبی از این دو را ارائه میدهند. هدف اصلی آنها تضمین اجرای صحیح برنامه، تشخیص خطاها و بهینهسازی عملکرد است. بدون پردازشگرهای زبان، برنامهنویسان مجبور بودند مستقیماً با زبان ماشین کار کنند، که فرآیندی پیچیده و پرخطا است. در ادامه، هر کدام از این پردازشگرها را با جزئیات بررسی میکنیم :
3.1 Compiler
بهطور ساده، کامپایلر یک برنامه است که میتواند یک برنامه را در یک زبان – زبان منبع – بخواند و آن را به یک برنامه معادل در زبان دیگری – زبان هدف – ترجمه کند؛ نقش مهم کامپایلر این است که هر خطایی در برنامه منبع که در فرآیند ترجمه تشخیص میدهد، گزارش کند.
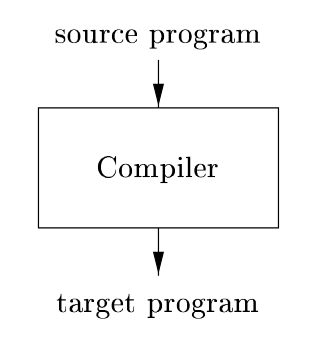
اگر برنامه هدف یک برنامه زبان ماشین قابل اجرا باشد، آنگاه کاربر میتواند آن را فراخوانی نماید تا ورودیها را پردازش و خروجیها را تولید کند.

کامپایلرها معمولاً برنامه منبع را به کد ماشین یا کد اسمبلی تبدیل میکنند که مستقیماً روی سختافزار اجرا میشود. این فرآیند شامل مراحل مختلفی مانند تحلیل لغوی، نحوی، معنایی و تولید کد است. مزیت اصلی کامپایلرها سرعت بالای اجرای برنامه هدف است، زیرا ترجمه یکبار انجام میشود و برنامه اجرایی میتواند چندین بار بدون نیاز به ترجمه مجدد اجرا شود. با این حال، کامپایلرها ممکن است تشخیص خطاهای دقیقتری نسبت به مفسرها ارائه ندهند، زیرا کل برنامه را یکجا ترجمه میکنند.
کامپایلرها نه تنها ترجمه میکنند، بلکه با اعمال بهینهسازیها، کارایی برنامه را افزایش میدهند. برای مثال، کامپایلر میتواند عملیاتهایی مانند تبدیل نوع دادهها را در زمان کامپایل انجام دهد تا اجرای برنامه سریعتر شود.
3.2 Interpreter
مفسر یک نوع رایج دیگر از پردازشگر زبان است. به جای تولید یک برنامه هدف به عنوان ترجمه، مفسر به نظر میرسد که مستقیماً عملیات مشخصشده در برنامه منبع را روی ورودیهای ارائهشده توسط کاربر اجرا میکند.
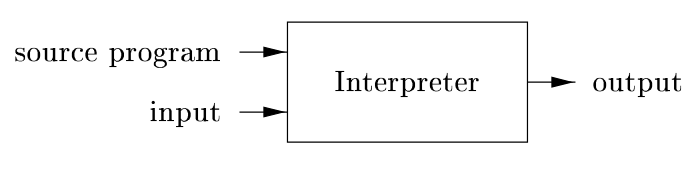
برنامه هدف زبان ماشین تولیدشده توسط کامپایلر معمولاً خیلی سریعتر از مفسر در نگاشت ورودیها به خروجیها عمل میکند. با این حال، مفسر معمولاً میتواند تشخیص خطاهای بهتری نسبت به کامپایلر ارائه دهد، زیرا برنامه منبع را دستور به دستور اجرا میکند.
مفسرها کد منبع را خط به خط یا دستور به دستور تفسیر و اجرا میکنند، بدون اینکه یک فایل اجرایی جداگانه تولید کنند. این رویکرد اجازه میدهد تا خطاها بلافاصله در زمان اجرا تشخیص داده شوند، که برای دیباگینگ مفید است. با این حال، اجرای مفسرها کندتر است زیرا هر بار که برنامه اجرا میشود، ترجمه مجدد انجام میگیرد. مفسرها برای زبانهای اسکریپتی مانند Python یا JavaScript مناسب هستند.
در مقایسه با کامپایلرها، مفسرها انعطافپذیری بیشتری در محیطهای توسعه ارائه میدهند، زیرا تغییرات کد میتواند بلافاصله تست شود بدون نیاز به کامپایل مجدد.
3.3 Hybrid Systems (مثال Java و JIT)
پردازشگرهای زبان جاوا ترکیبی از کامپایل و تفسیر را ترکیب میکنند. یک برنامه منبع جاوا ممکن است ابتدا به یک فرم میانی به نام بایتکد کامپایل شود. بایتکدها سپس توسط یک ماشین مجازی تفسیر میشوند. مزیت این ترتیب این است که بایتکدهای کامپایلشده روی یک ماشین میتوانند روی ماشین دیگری تفسیر شوند، شاید از طریق یک شبکه.
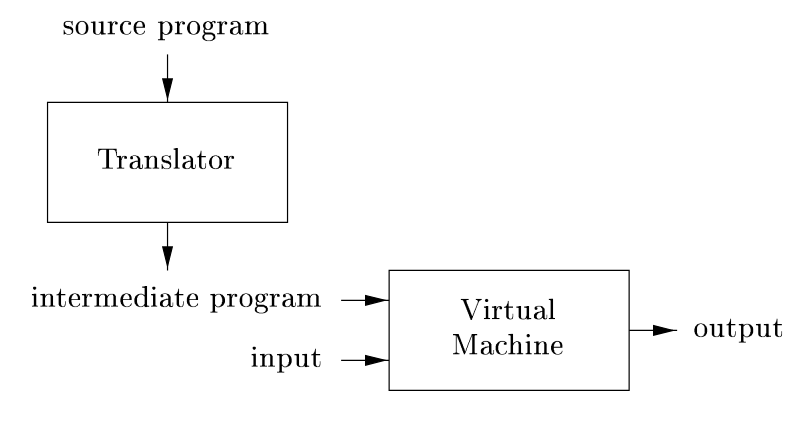
برای دستیابی به پردازش سریعتر ورودیها به خروجیها، برخی کامپایلرهای جاوا، که کامپایلرهای just-in-time نامیده میشوند، بایتکدها را به زبان ماشین بلافاصله قبل از اجرای برنامه میانی برای پردازش ورودی ترجمه میکنند.
سیستمهای هیبریدی ترکیبی از مزایای کامپایلر و مفسر را ارائه میدهند. در جاوا، کد منبع به بایتکد کامپایل میشود که مستقل از پلتفرم است، و سپس توسط JVM (ماشین مجازی جاوا) تفسیر یا کامپایل میشود. JIT (Just-In-Time) بخشی از این سیستم است که بخشهای پرکاربرد کد را در زمان اجرا به کد ماشین native کامپایل میکند تا سرعت افزایش یابد. این رویکرد اجازه میدهد تا برنامهها قابل حمل باشند (write once, run anywhere) در حالی که عملکرد نزدیک به کامپایلرهای سنتی را ارائه دهند.
این سیستمها به عنوان مثالهایی از تکامل پردازشگرهای زبان معرفی میشوند که برای حل مشکلات قابلیت حمل و عملکرد طراحی شدهاند. سیستمهای هیبریدی در زبانهایی مانند C# (.NET) نیز استفاده میشوند، جایی که کد به IL (Intermediate Language) کامپایل میشود و سپس توسط CLR اجرا میگردد.
در کل، پردازشگرهای زبان ابزارهای اساسی برای اجرای برنامهها هستند و انتخاب بین کامپایلر، مفسر یا هیبریدی بستگی به نیازهای عملکرد، قابلیت حمل و سهولت توسعه دارد. درک این پردازشگرها پایهای برای طراحی کامپایلرهای پیشرفته است.
4. زنجیره تولید برنامه اجرایی
علاوه بر کامپایلر، چندین برنامه دیگر ممکن است برای ایجاد یک برنامه هدف اجرایی لازم باشد. یک برنامه منبع ممکن است به ماژولهایی تقسیم شود که در فایلهای جداگانه ذخیره شوند. وظیفه جمعآوری برنامه منبع گاهی به یک برنامه جداگانه، به نام پیشپردازنده، سپرده میشود. پیشپردازنده همچنین ممکن است اختصارات، به نام ماکروها، را به دستورات زبان منبع گسترش دهد.
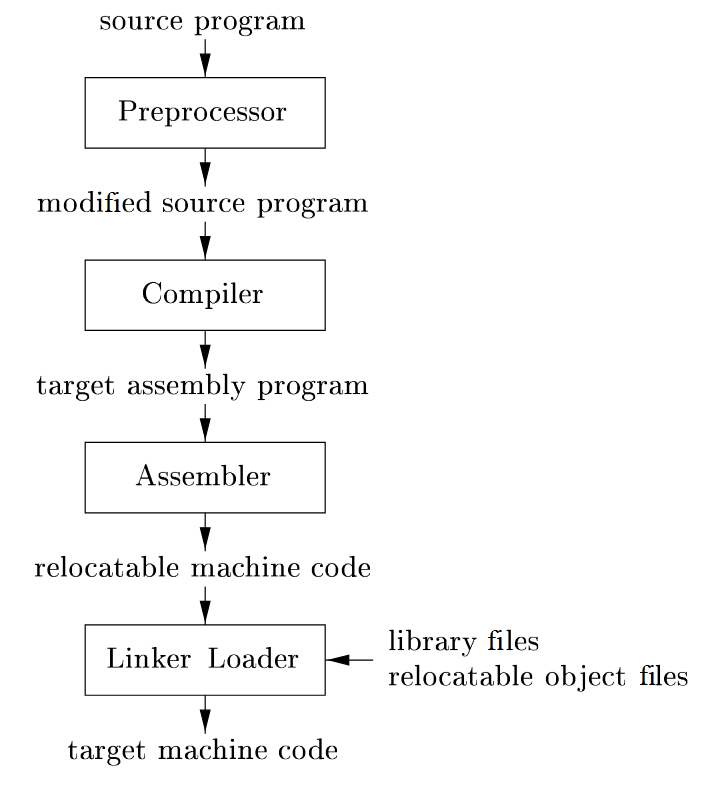
برنامه منبع تغییر یافته سپس به کامپایلر تغذیه میشود. کامپایلر ممکن است یک برنامه زبان اسمبلی به عنوان خروجی تولید کند، زیرا زبان اسمبلی آسانتر برای تولید به عنوان خروجی است و آسانتر برای دیباگ است. زبان اسمبلی سپس توسط برنامهای به نام اسمبلر پردازش میشود که کد ماشین قابل جابجایی تولید میکند به عنوان خروجی.
برنامههای بزرگ اغلب به قطعات کامپایل میشوند، بنابراین کد ماشین قابل جابجایی ممکن است نیاز به لینک شدن با دیگر فایلهای شیء قابل جابجایی و فایلهای کتابخانه داشته باشد تا کدی که واقعاً روی ماشین اجرا میشود. لینککننده آدرسهای حافظه خارجی را حل میکند، جایی که کد در یک فایل ممکن است به مکانی در فایل دیگری اشاره کند. لودر سپس تمام فایلهای شیء اجرایی را در حافظه برای اجرا قرار میدهد.
زنجیره تولید برنامه اجرایی فرآیندی گامبهگام است که کد منبع نوشتهشده توسط برنامهنویس را به یک برنامه قابل اجرا تبدیل میکند. این زنجیره شامل ابزارهایی است که هر کدام نقش خاصی در تبدیل، بهینهسازی و آمادهسازی کد برای اجرا روی سختافزار دارند. این زنجیره به عنوان بخشی از اکوسیستم توسعه نرمافزار توصیف میشود که کامپایلر تنها یکی از اجزای آن است. بدون این زنجیره، مدیریت برنامههای بزرگ و پیچیده غیرممکن بود، زیرا برنامهنویسان باید همه چیز را دستی مدیریت میکردند. این فرآیند تضمین میکند که برنامه نهایی کارآمد، قابل حمل و بدون خطاهای لینک باشد. در ادامه، هر مرحله از این زنجیره را با جزئیات بررسی میکنیم:
4.1 Preprocessor
پیشپردازنده (Preprocessor) اولین مرحله در زنجیره تولید برنامه اجرایی است. وظیفه اصلی آن جمعآوری و آمادهسازی کد منبع قبل از ورود به کامپایلر است. برنامه منبع ممکن است به ماژولهایی تقسیم شود که در فایلهای جداگانه ذخیره شوند. وظیفه جمعآوری برنامه منبع گاهی به یک برنامه جداگانه، به نام پیشپردازنده، سپرده میشود. پیشپردازنده همچنین ممکن است اختصارات، به نام ماکروها، را به دستورات زبان منبع گسترش دهد.
برای مثال، در زبانهایی مانند C یا C++، پیشپردازنده دستوراتی مانند #include را پردازش میکند تا فایلهای هدر را وارد کد منبع کند، یا ماکروها را گسترش دهد تا کد تکراری را کاهش دهد. این مرحله کد منبع را به یک جریان واحد تبدیل میکند که آماده تحلیل توسط کامپایلر است. پیشپردازنده بخشی از فرآیند کامپایل نیست، بلکه یک ابزار کمکی است که کد را برای کامپایلر آماده میکند. بدون پیشپردازنده، مدیریت وابستگیها و ماکروها دستی و پرخطا میشد.
پیشپردازنده همچنین میتواند تعریفهای شرطی را مدیریت کند، مانند #ifdef، که اجازه میدهد بخشهایی از کد بر اساس شرایط کامپایل شوند. این ویژگی برای نوشتن کد قابل حمل بین پلتفرمهای مختلف مفید است. در نهایت، خروجی پیشپردازنده یک فایل منبع تغییر یافته است که مستقیماً به کامپایلر ارسال میشود.
4.2 Compiler
کامپایلر (Compiler) هسته اصلی زنجیره تولید برنامه اجرایی است. برنامه منبع تغییر یافته سپس به کامپایلر تغذیه میشود. کامپایلر ممکن است یک برنامه زبان اسمبلی به عنوان خروجی تولید کند، زیرا زبان اسمبلی آسانتر برای تولید به عنوان خروجی است و آسانتر برای دیباگ است.
کامپایلر کد منبع سطح بالا را به کد اسمبلی یا کد ماشین تبدیل میکند. این فرآیند شامل مراحل مختلفی مانند تحلیل لغوی، نحوی، معنایی، تولید کد میانی، بهینهسازی و تولید کد نهایی است که در بخشهای بعدی گزارش به تفصیل بحث خواهد شد. کامپایلر ترجمهگر اصلی است که نه تنها ترجمه میکند، بلکه خطاها را تشخیص میدهد و بهینهسازی اعمال میکند.
برای برنامههای بزرگ، کامپایلر ممکن است کد را به قطعات کامپایل کند، که این قطعات بعداً توسط مراحل بعدی ترکیب میشوند. مزیت تولید کد اسمبلی به عنوان خروجی این است که دیباگ آسانتر میشود، زیرا اسمبلی خواناتر از کد ماشین است. کامپایلر همچنین اطلاعات نمادها را مدیریت میکند تا مراحل بعدی بتوانند آدرسها را حل کنند.
4.3 Assembler
اسمبلر (Assembler) مرحله بعدی پس از کامپایلر است. زبان اسمبلی سپس توسط برنامهای به نام اسمبلر پردازش میشود که کد ماشین قابل جابجایی تولید میکند به عنوان خروجی.
اسمبلر کد اسمبلی را به کد ماشین باینری تبدیل میکند. کد اسمبلی شامل دستورات mnemonic است که مستقیماً به عملیات ماشین نگاشت میشوند، اما هنوز خوانا برای انسان هستند. اسمبلر این دستورات را به دنبالههای صفر و یک ترجمه میکند و فایلهای شیء (object files) تولید میکند که شامل کد ماشین قابل جابجایی است.
اسمبلر برای تولید خروجی آسانتر است و اجازه میدهد تا کامپایلر روی بهینهسازی تمرکز کند. فایلهای شیء تولید شده توسط اسمبلر شامل بخشهایی مانند کد، دادهها و نمادها هستند که برای لینک شدن آماده میشوند. بدون اسمبلر، کامپایلر باید مستقیماً کد ماشین تولید کند، که پیچیدهتر است.
4.5 Linker
لینککننده (Linker) مرحله ترکیب قطعات کد است. برنامههای بزرگ اغلب به قطعات کامپایل میشوند، بنابراین کد ماشین قابل جابجایی ممکن است نیاز به لینک شدن با دیگر فایلهای شیء قابل جابجایی و فایلهای کتابخانه داشته باشد تا کدی که واقعاً روی ماشین اجرا میشود.
لینک کننده آدرسهای حافظه خارجی را حل میکند، جایی که کد در یک فایل ممکن است به مکانی در فایل دیگری اشاره کند. برای مثال، اگر یک تابع در یک فایل شیء تعریف شده باشد و در فایل دیگری فراخوانی شود، لینککننده آدرس واقعی را قرار میدهد. لینککننده همچنین فایلهای کتابخانه را وارد میکند، مانند کتابخانههای استاندارد زبان.
لینککننده را حلکننده وابستگیها توصیف میکنند که برنامه نهایی اجرایی را تولید میکند. انواع لینک شامل لینک استاتیک (که همه چیز را در یک فایل ترکیب میکند) و لینک دینامیک (که کتابخانهها را در زمان اجرا بارگذاری میکند) است. این مرحله خطاهای لینک مانند نمادهای تعریفنشده را تشخیص میدهد.
4.6 Loader
لودر (Loader) آخرین مرحله در زنجیره است. لودر سپس تمام فایلهای شیء اجرایی را در حافظه برای اجرا قرار میدهد.
لودر برنامه اجرایی را در حافظه بارگذاری میکند، آدرسهای نهایی را تنظیم میکند و اجرای برنامه را شروع میکند. در سیستمهای عملیاتی مدرن، لودر بخشی از سیستم عامل است که مدیریت حافظه را انجام میدهد، مانند تخصیص فضای مجازی.
لودر را اغلب به عنوان پلی بین فایل اجرایی و اجرای واقعی معرفی میکنند. در لینک دینامیک، لودر ممکن است کتابخانههای اشتراکی را بارگذاری کند. این مرحله تضمین میکند که برنامه به درستی در محیط اجرا قرار گیرد.
در کل، زنجیره تولید برنامه اجرایی یک فرآیند یکپارچه است که از پیشپردازنده شروع میشود و با لودر پایان مییابد. درک این زنجیره برای طراحی کامپایلرهای کارآمد ضروری است، زیرا هر مرحله بر مراحل بعدی تأثیر میگذارد. این زنجیره اجازه میدهد تا برنامههای پیچیده به طور ماژولار توسعه یابند و نگهداری شوند.
5. نمای درونی کامپایلر: Analysis و Synthesis
تا حالا، ما کامپایلر را به عنوان یک جعبه واحد تعریف کردیم که یک برنامه منبع را به یک برنامه هدف معادل معنایی نگاشت میکند. اگر این جعبه را کمی باز کنیم، میبینیم که دو بخش برای این نگاشت وجود دارد:
- تحلیل (Analysis)
- سنتز (Synthesis)
بخش تحلیل (Analysis) برنامه منبع را به قطعات تشکیلدهنده تقسیم میکند و یک ساختار دستوری روی آنها اعمال میکند. سپس از این ساختار برای ایجاد یک نمای میانی از برنامه منبع استفاده میکند. اگر بخش تحلیل تشخیص دهد که برنامه منبع از نظر نحوی بدشکل یا معنایی ناسالم است، باید پیامهای اطلاعرسان ارائه دهد تا کاربر بتواند اقدام اصلاحی انجام دهد. بخش تحلیل همچنین اطلاعات درباره برنامه منبع را جمعآوری میکند و آن را در یک ساختار داده به نام جدول نمادها ذخیره میکند، که همراه با نمای میانی به بخش سنتز منتقل میشود.
بخش سنتز (Synthesis) برنامه هدف مورد نظر را از نمای میانی و اطلاعات در جدول نمادها میسازد. بخش تحلیل اغلب front end کامپایلر و بخش سنتز back end کامپایلر نامیده میشود.
اگر فرآیند کامپایل را با جزئیات بیشتری بررسی کنیم، میبینیم که به عنوان یک توالی از فازها عمل میکند که هر کدام یک نمای برنامه منبع را به دیگری تبدیل میکند. در عمل، چندین فاز ممکن است با هم گروهبندی شوند، و نمایهای میانی بین فازهای گروهبندیشده نیاز به ساخت صریح ندارند. جدول نمادها، که اطلاعات درباره کل برنامه منبع را ذخیره میکند، توسط تمام فازهای کامپایلر استفاده میشود.
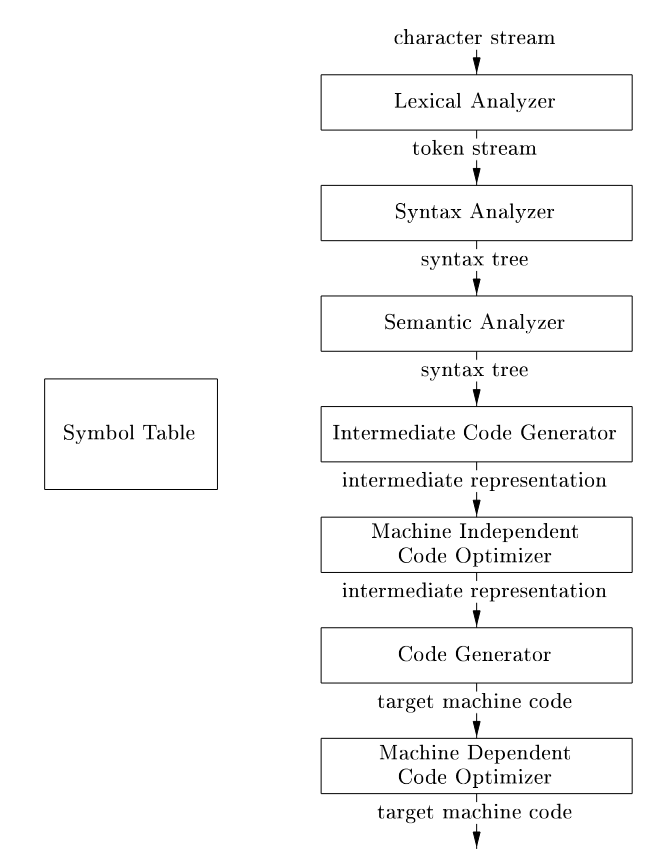
برخی کامپایلرها یک فاز بهینهسازی مستقل از ماشین بین front end و back end دارند. هدف این فاز بهینهسازی انجام تحولات روی نمای میانی است، تا back end بتواند برنامه هدف بهتری تولید کند نسبت به آنچه بدون نمای میانی بهینهنشده تولید میکرد.
این تقسیمبندی به عنوان پایهای برای درک ساختار کامپایلر معرفی میشود. تحلیل (Analysis) یا front end مسئول پردازش ورودی منبع و تولید نمای میانی است، در حالی که سنتز (Synthesis) یا back end این نمای میانی را به کد هدف تبدیل میکند. این ساختار اجازه میدهد تا کامپایلرها ماژولار باشند، به طوری که front end میتواند برای زبانهای مختلف و back end برای ماشینهای مختلف سفارشی شود.
front end شامل فازهایی مانند تحلیل لغوی، نحوی، معنایی و تولید کد میانی است که وابسته به زبان منبع هستند اما مستقل از ماشین هدف. این بخش کد منبع را تجزیه و تحلیل میکند و خطاهای نحوی یا معنایی را گزارش میدهد. در مقابل، back end شامل بهینهسازی، تولید کد و وابستگیهای ماشین است که کد میانی را به کد ماشین خاص پلتفرم تبدیل میکند. این تقسیمبندی در کامپایلرهایی مانند GCC یا LLVM مشهود است، جایی که front end زبانهایی مانند C++ را مدیریت میکند و back end کد را برای معماریهایی مانند x86 یا ARM تولید میکند.
front end syntax و semantics کد منبع را بررسی میکند، در حالی که back end تحلیل را به کد هدف سنتز میکند، و اغلب یک middle end برای بهینهسازیهای مستقل وجود دارد. این ساختار در طراحی کامپایلرهای مدرن مانند Clang، که بخشی از LLVM است، استفاده میشود، جایی که front end کد را به IR (Intermediate Representation) تبدیل میکند و back end نیز IR را بهینهسازی و تولید کد میکند.
حال با توجه موارد گفته که نمایی کلی این مفهوم رو باز میکند هر بخش را به صورت جداگانه باز میکنیم :
5.1 Lexical Analyzer (تحلیلگر لغوی یا Scanner)
اولین فاز کامپایلر، تحلیل لغوی یا اسکنینگ نامیده میشود. تحلیلگر لغوی جریان کاراکترهای تشکیلدهنده برنامه منبع را میخواند و آنها را به توالیهای معنادار به نام lexeme گروهبندی میکند. برای هر lexeme، تحلیلگر لغوی یک توکن به شکل <token-name, attribute-value> تولید میکند که به فاز بعدی (تحلیل نحوی) ارسال میشود.
توکن اول (token-name) یک نماد انتزاعی است که در تحلیل نحوی استفاده میشود و جزء دوم (attribute-value) به ورودی جدول نمادها اشاره دارد. اطلاعات جدول نمادها برای تحلیل معنایی و تولید کد لازم است.
این فاز سادهترین مرحله است اما بسیار مهم؛ زیرا ورودی خام (کاراکترها) را به واحدهای معنادار تبدیل میکند و فضاهای خالی، کامنتها و غیره را حذف میکند.
5.2 Syntax Analyzer (تحلیلگر نحوی یا Parser)
دومین فاز، تحلیل نحوی یا parsing نامیده میشود. پارسر از اجزای اول توکنهای تولیدشده توسط تحلیلگر لغوی استفاده میکند تا یک نمای درختیمانند میانی بسازد که ساختار دستوری جریان توکنها را نشان دهد. نمای رایج، درخت نحوی (syntax tree) است که در آن هر گره داخلی یک عملیات را نشان میدهد و فرزندان آن گره، آرگومانهای عملیات هستند.
این درخت ترتیب انجام عملیات را مشخص میکند و بر اساس قوانین اولویت عملگرها ساخته میشود. خروجی این فاز معمولاً یک درخت نحوی انتزاعی (abstract syntax tree یا AST) است که پایه تحلیلهای بعدی میشود.
5.3 Semantic Analyzer (تحلیلگر معنایی)
تحلیلگر معنایی از درخت نحوی و اطلاعات جدول نمادها استفاده میکند تا برنامه منبع را از نظر سازگاری معنایی با تعریف زبان بررسی کند. این فاز همچنین اطلاعات نوع (type information) را جمعآوری و در درخت نحوی یا جدول نمادها ذخیره میکند تا در تولید کد میانی استفاده شود.
یکی از وظایف اصلی، type checking است؛ یعنی بررسی اینکه هر عملگر عملوندهای سازگار دارد یا نه. زبان ممکن است برخی تبدیلهای نوع (coercions) را اجازه دهد، مانند تبدیل عدد صحیح به اعشاری. اگر خطایی وجود داشته باشد (مثلاً استفاده از عدد اعشاری به عنوان اندیس آرایه)، گزارش میشود.
5.4 Intermediate Code Generator (تولیدکننده کد میانی)
پس از تحلیل نحوی و معنایی، بسیاری از کامپایلرها یک نمای میانی صریح و سطح پایین یا ماشینمانند تولید میکنند که میتوان آن را برنامهای برای یک ماشین انتزاعی دانست. این نمای میانی باید دو ویژگی مهم داشته باشد: آسان برای تولید باشد و آسان برای ترجمه به ماشین هدف.
یک فرم رایج به نام three-address code معرفی میشود که شامل دستوراتی شبیه اسمبلی با حداکثر سه عملوند است. این کد ترتیب عملیات را ثابت میکند، از نامهای موقت (temporaries) استفاده میکند و برخی دستورات ممکن است کمتر از سه عملوند داشته باشند.

5.5 Machine-Independent Code Optimizer (بهینهساز کد مستقل از ماشین)
این فاز اختیاری، کد میانی را بهبود میبخشد تا کد هدف بهتری تولید شود. معمولاً “بهتر” به معنای سریعتر است، اما ممکن است کوتاهتر بودن کد یا مصرف کمتر انرژی هم مدنظر باشد.
بهینهساز میتواند عملیات غیرضروری را حذف کند، ثابتها را محاسبه کند (constant folding)، یا ساختارهای تکراری را ساده کند. این فاز مستقل از ماشین هدف است و روی نمای میانی کار میکند.
5.6 Code Generator (تولیدکننده کد هدف)
تولیدکننده کد، نمای میانی را به زبان هدف (معمولاً کد ماشین) نگاشت میکند. اگر هدف کد ماشین باشد، برای هر متغیر رجیستر یا مکان حافظه انتخاب میشود. سپس دستورات میانی به توالی دستورات ماشین ترجمه میشوند.
انتخاب هوشمندانه رجیسترها یکی از جنبههای کلیدی است. این فاز وابسته به ماشین هدف است و شامل تخصیص رجیستر، مدیریت حافظه و تولید کد نهایی میشود.
5.7 Machine-Dependent Code Optimizer (بهینهساز کد وابسته به ماشین، اختیاری)
این فاز نهایی، کد هدف را با توجه به ویژگیهای خاص ماشین (مانند تعداد رجیسترها، دستورات خاص، pipeline و غیره) بهینه میکند. این مرحله نیز اختیاری است و در کامپایلرهای پیشرفتهتر دیده میشود.
جدول نمادها (Symbol Table) در تمام فازها نقش مرکزی دارد و اطلاعات متغیرها، توابع، انواع و دامنهها را ذخیره میکند تا دسترسی سریع امکانپذیر باشد.
در کامپایلرهای مدرن (مانند GCC، Clang/LLVM)، این فازها اغلب به سه بخش تقسیم میشوند:
- Front End: تحلیل لغوی، نحوی، معنایی و تولید کد میانی (زبانمحور)
- Middle End: بهینهسازیهای مستقل از ماشین (روی IR مانند LLVM IR)
- Back End: بهینهسازی وابسته به ماشین و تولید کد نهایی (ماشینمحور)
این ساختار اجازه میدهد کامپایلر برای زبانهای مختلف (front end متفاوت) و معماریهای مختلف (back end متفاوت) بازاستفاده شود. گروهبندی فازها به پاسها (passes) بستگی دارد؛ گاهی چندین فاز در یک پاس ترکیب میشوند تا کارایی افزایش یابد.
این توالی فازها پایه طراحی تقریباً تمام کامپایلرهای امروزی است.
6. مدیریت جدول نمادها (Symbol Table)
یک عملکرد اساسی کامپایلر این است که نام متغیرهای استفادهشده در برنامه منبع را ثبت کند و اطلاعات مختلفی درباره ویژگیهای (attributes) هر نام جمعآوری کند. این ویژگیها ممکن است اطلاعاتی درباره فضای ذخیرهسازی تخصیصیافته برای یک نام، نوع آن، دامنه (scope) آن (یعنی جایی در برنامه که مقدار آن قابل استفاده است) و در مورد نام توابع، مواردی مانند تعداد و انواع آرگومانها، روش ارسال هر آرگومان (مثلاً by value یا by reference) و نوع بازگشتی فراهم کنند.
جدول نمادها (Symbol Table) یک ساختار داده است که برای هر نام متغیر، یک رکورد (record) دارد و فیلدهایی برای ویژگیهای آن نام. این ساختار داده باید به گونهای طراحی شود که کامپایلر بتواند رکورد مربوط به هر نام را سریع پیدا کند و دادهها را از آن رکورد ذخیره یا بازیابی کند.
جدول نمادها توسط تقریباً تمام فازهای کامپایلر استفاده میشود و اطلاعات جمعآوریشده در مراحل تحلیل را به مراحل بعدی منتقل میکند. بدون جدول نمادها، مدیریت شناسهها (identifiers)، بررسی دامنه، type checking، تخصیص حافظه و تولید کد نهایی غیرممکن یا بسیار ناکارآمد میشد.
6.1 نقش جدول نمادها در فازهای مختلف کامپایلر
جدول نمادها در طول فرآیند کامپایل به صورت پویا ساخته و بهروزرسانی میشود:
- تحلیل لغوی (Lexical Analysis): وقتی یک شناسه (identifier) شناسایی میشود، برای اولین بار در جدول نمادها وارد میشود. اغلب، تحلیلگر لغوی lexeme را به جدول ارسال میکند تا بررسی شود آیا قبلاً وجود دارد یا خیر، و در صورت لزوم رکورد جدیدی ایجاد شود.
- تحلیل نحوی (Syntax Analysis): اطلاعات ساختاری مانند نوع، آرایه بودن، ابعاد آرایه، و خطوط ارجاع اضافه میشود. همچنین، ساختارهای بلوکی (blocks) و دامنهها مدیریت میشوند.
- تحلیل معنایی (Semantic Analysis): مهمترین استفاده اینجا است؛ type checking انجام میشود، تبدیلهای نوع (coercions) اعمال میگردد، و خطاهای معنایی مانند استفاده از متغیر تعریفنشده یا ناسازگاری نوع گزارش میشود. همچنین، اطلاعات درباره scope resolution و visibility تعیین میشود.
- تولید کد میانی و بهینهسازی: از جدول برای دسترسی به نوع دادهها، مکان حافظه، و اطلاعات لازم برای تولید کد استفاده میشود.
- تولید کد هدف: برای تخصیص رجیسترها، آدرسدهی حافظه، و مدیریت لینک خارجی (external references) به جدول نمادها نیاز است.
6.2 ساختار جدول نمادها
جدول نمادها معمولاً به صورت زیر سازماندهی میشود:
- جدول جهانی (Global Symbol Table): برای نمادهایی که در کل برنامه قابل دسترسی هستند (مانند توابع اصلی، متغیرهای جهانی).
- جدولهای دامنهای (Scoped Symbol Tables): برای هر بلوک، تابع یا namespace یک جدول جداگانه ایجاد میشود. این جدولها اغلب به صورت سلسلهمراتبی (hierarchical) یا زنجیرهای (chained) سازماندهی میشوند تا جستجو در دامنههای بیرونی (outer scopes) امکانپذیر باشد.
6.3 روشهای پیادهسازی رایج
Hash Table: سریعترین روش برای insert و lookup (o(1) متوسط). کلید معمولاً نام (lexeme) است و مقدار یک ساختار شامل ویژگیها.
درخت جستجوی باینری (BST) یا Trie: برای مدیریت ترتیب یا جستجوی پیشوندی مفید است (کمتر رایج).
لیست خطی با hashing: برای سادگی در کامپایلرهای کوچک.
هر رکورد در جدول نمادها معمولاً شامل فیلدهای زیر است:
- نام (name) یا اشارهگر به lexeme ذخیرهشده
- نوع (type): int, float, array, pointer, struct و غیره
- دسته (category): variable, function, constant, parameter, label و غیره
- دامنه (scope) یا سطح (level)
- مکان حافظه (memory location) یا offset
- اندازه (size) برای آرایهها یا structها
- آرگومانها (برای توابع): لیست پارامترها، نوع بازگشت
- خط تعریف (line number) برای گزارش خطا
- پرچمهای اضافی (flags): مانند const, static, volatile, initialized و غیره.
6.4 عملیات اصلی روی جدول نمادها
عملیات کلیدی که باید سریع و کارآمد باشند عبارتند از:
- Insert(name, attributes): افزودن یک شناسه جدید با ویژگیهایش. اغلب در تحلیل نحوی و معنایی استفاده میشود. اگر شناسه قبلاً در دامنه فعلی وجود داشته باشد، خطای redeclaration گزارش میشود.
- Lookup (name): جستجوی یک شناسه و بازگشت رکورد مربوطه. جستجو از دامنه فعلی شروع میشود و در صورت عدم یافتن، به دامنههای بیرونی میرود (scope chaining). اگر پیدا نشود، خطای undefined identifier گزارش میشود.
- Delete یا Pop scope: وقتی از یک بلوک یا تابع خارج میشویم، جدول دامنه مربوطه حذف یا غیرفعال میشود (برای مدیریت scope محلی).
- Update attributes: تغییر ویژگیها مانند تخصیص آدرس یا نوع پس از تحلیل بیشتر.
- Enter scope / Exit scope: ایجاد جدول جدید برای بلوک جدید یا بازگشت به جدول قبلی.
7. مدیریت دامنه (Scope Management)
در زبانهایی با lexical scoping (مانند C، Java، Rust)، جدول نمادها باید دامنه را پشتیبانی کند. روش رایج:
- Stack of Symbol Tables: یک پشته از جدولها؛ هر بلوک جدید یک جدول جدید روی پشته push میشود. Lookup از بالای پشته شروع میشود و پایین میرود.
- Chained Hash Tables: هر جدول به جدول والد اشاره دارد.
- Nested Environments: در کامپایلرهای پیشرفته مانند GCC یا LLVM، محیطهای تو در تو (nested environments) استفاده میشود.
7.1 مثال ساده
فرض کنید کد زیر:
int position;
float initial, rate;
void main(){
position = initial + rate * 60;
}
- در تحلیل لغوی: شناسههای `position`, `initial`, `rate` وارد جدول میشوند.
- در تحلیل معنایی: نوعها (int برای position، float برای initial و rate) ذخیره میشوند.
- برای `60`: ممکن است به عنوان constant integer وارد شود.
- در تولید کد: از جدول برای دانستن نوع و مکان این متغیرها استفاده میشود (مثلاً offset در stack یا register).
در کامپایلرهای مدرن (مانند Clang/LLVM)، جدول نمادها بخشی از AST و metadata است و با IR ترکیب میشود تا بهینهسازیها و کدجنریشن دقیق انجام شود.
7.2 اهمیت و چالشها
- کارایی: lookup باید بسیار سریع باشد (میلیونها بار در برنامههای بزرگ).
- مدیریت حافظه: جدول نمادها میتواند بزرگ شود؛ باید garbage collection یا آزادسازی مناسب داشته باشد.
- چندزبانه / چندپلتفرمی: در کامپایلرهای cross-platform، جدول باید اطلاعات وابسته به پلتفرم (مانند alignment) را مدیریت کند.
جدول نمادها قلب اطلاعاتی کامپایلر است و مدیریت صحیح آن تضمینکننده صحت، کارایی و قابلیت نگهداری برنامه نهایی است. درک عمیق آن برای پیادهسازی کامپایلر یا حتی ابزارهای تحلیل کد ضروری است.
8. تحلیل ایستا
این بخش بهمنظور تکمیل بحثهای پیشین درباره کامپایلر و فازهای مختلف آن، به معرفی و تبیین مفهوم تحلیل ایستای برنامه میپردازد. تحلیل ایستا شاخهای بنیادی از علوم کامپیوتر و طراحی کامپایلر است که هدف آن استخراج اطلاعات معنادار درباره رفتار یک برنامه، بدون اجرای واقعی آن، میباشد. در این رویکرد، برنامه بهعنوان یک شیء صوری مورد بررسی قرار میگیرد و تلاش میشود خواصی مانند امکان وقوع خطا، محدوده مقادیر متغیرها، وابستگیهای دادهای و کنترلی، و رفتار حافظه پیش از زمان اجرا استنتاج شود.
اهمیت این حوزه از آنجا ناشی میشود که بسیاری از خطاهای نرمافزاری، مشکلات امنیتی و ناکارآمدیهای عملکردی را میتوان پیش از اجرای برنامه و حتی پیش از تحویل نرمافزار شناسایی کرد. با این حال، تحلیل ایستا همواره با یک محدودیت نظری بنیادین مواجه است: از آنجا که پیشبینی دقیق تمام رفتارهای اجرایی یک برنامه غیر بدیهی غیرقابل پیش بینی است، هر تحلیل عملی ناچار به استفاده از تقریب و سادهسازی است. این تنش میان دقت تحلیل و امکانپذیری محاسباتی، محور اصلی طراحی تمام تحلیلهای ایستا را تشکیل میدهد.
8.1 کلیات و مفاهیم محوری
هدف اصلی هر تحلیل ایستا، استخراج اطلاعاتی «ایمن» درباره برنامه است؛ به این معنا که نتایج تحلیل نباید رفتاری را رد کنند که ممکن است در زمان اجرا رخ دهد. به همین دلیل، بسیاری از تحلیلها محافظهکارانه هستند و به جای دقت کامل، تضمین صحت را در اولویت قرار میدهند. در این چارچوب، مفهوم انتزاع اهمیت مرکزی دارد. فضای حالات اجرایی واقعی یک برنامه بسیار بزرگ، و اغلب نامتناهی است؛ بنابراین تحلیلگر مجبور است این فضا را به یک دامنه انتزاعی کوچکتر نگاشت کند. انتخاب این دامنه انتزاعی، میزان دقت و هزینه محاسباتی تحلیل را تعیین میکند. همچنین نمای برنامه، مانند گراف جریان کنترل یا نمایش میانی کامپایلر، نقش تعیینکنندهای در قابلیت بیان و قدرت تحلیل دارد. تحلیل ایستا عملاً بر روی این نمایشها عمل میکند، نه بر روی متن خام برنامه.
8.2 زبان نمونه و مدلسازی
برای تشریح مفاهیم تحلیل ایستا، معمولاً از یک زبان نمونه ساده اما گویا استفاده میشود. این زبان شامل عناصر پایهای مانند متغیرهای عددی، اشارهگرها، ساختارهای کنترلی، توابع و حافظه هیپ (heap) است. هدف از این سادهسازی، حذف جزئیات غیرضروری و تمرکز بر هسته مفهومی تحلیل است، نه بازسازی کامل پیچیدگی زبانهای صنعتی. در این مرحله، برنامه منبع اغلب به شکلی نرمالسازیشده بازنویسی میشود؛ برای مثال، نام متغیرها یکتا میشوند، عبارات پیچیده به توالیای از دستورات سادهتر تبدیل میگردند، و ساختار برنامه بهصورت گراف جریان کنترل استخراج میشود. این مدلسازی، پایهای است که تمام تحلیلهای بعدی بر آن استوار میشوند.
8.3 تحلیل نوع (Type Analysis)
تحلیل نوع یکی از ابتداییترین و در عین حال حیاتیترین انواع تحلیل ایستا است. هدف آن اطمینان از سازگاری عملیات برنامه با انواع دادههاست. در این تحلیل، برای هر متغیر و عبارت، نوعی استنتاج میشود و بررسی میگردد که آیا استفاده از آن با قواعد زبان سازگار است یا خیر. این تحلیل معمولاً مبتنی بر قواعد صوری و استنتاج منطقی است و میتوان برای آن اثبات صحت ارائه داد؛ بدین معنا که اگر تحلیل نوع برنامهای را معتبر تشخیص دهد، اجرای آن از نظر خطاهای نوعی ایمن خواهد بود. تحلیل نوع نمونهای روشن از تحلیلی است که دقت بالا و تضمین نظری قوی دارد، اما دامنه خطاهایی که پوشش میدهد محدود به مسائل نوعی است.
8.4 چارچوب کلی تحلیل جریان داده
تحلیل جریان داده یک چارچوب عمومی برای بسیاری از تحلیلهای ایستا فراهم میکند. در این رویکرد، برنامه بهصورت گراف جریان کنترل مدل میشود و برای هر نقطه از برنامه، اطلاعاتی درباره وضعیت متغیرها محاسبه میگردد. این اطلاعات در یک دامنه مشخص تعریف میشوند و توسط توابع انتقال، از یک نقطه به نقطه دیگر منتقل میشوند.
از آنجا که برنامهها ممکن است دارای حلقه و مسیرهای تکرارشونده باشند، محاسبه این اطلاعات نیازمند یافتن یک نقطه ثابت است؛ یعنی وضعیتی که با اعمال مکرر توابع انتقال دیگر تغییری نکند. تحلیلها میتوانند پیشرو یا پسرو باشند و بسته به ماهیت مسئله، حساس یا غیرحساس به مسیر اجرا طراحی شوند.
8.5 تحلیل تعاریف در دسترس
تحلیل تعاریف در دسترس به بررسی این موضوع میپردازد که در هر نقطه از برنامه، کدام انتسابها ممکن است مقدار فعلی یک متغیر را تعیین کرده باشند. این تحلیل پیشرو است و برای هر دستور، مجموعهای از تعاریف تولید و مجموعهای حذف میشوند. نتیجه این تحلیل مشخص میکند که یک استفاده از متغیر به کدام انتسابهای قبلی وابسته است. این اطلاعات برای بهینهسازیهایی مانند حذف انتسابهای غیرضروری، تحلیل وابستگی داده و حتی دیباگ برنامه اهمیت زیادی دارد و اغلب بهعنوان زیربنای تحلیلهای پیشرفتهتر استفاده میشود.
8.6 تحلیل متغیرهای زنده
در تحلیل متغیرهای زنده، تمرکز بر آینده اجرای برنامه است. یک متغیر در یک نقطه زنده محسوب میشود اگر مقدار فعلی آن در آینده برنامه مورد استفاده قرار گیرد. این تحلیل پسرو است و با بررسی استفادهها و تعریفها انجام میشود.
کاربرد عملی این تحلیل بهویژه در تخصیص رجیستر و حذف کد مرده نمایان است. اگر متغیری در نقطهای زنده نباشد، میتوان از نگهداری مقدار آن صرفنظر کرد یا حتی برخی دستورات را حذف نمود، بدون آنکه رفتار برنامه تغییر کند.
8.7 تحلیل ثابتها
تحلیل ثابتها تلاش میکند تعیین کند که آیا مقدار یک متغیر در یک نقطه مشخص، مقدار ثابتی است یا خیر. این تحلیل معمولاً از دامنهای با حالات محدود استفاده میکند که نشان میدهد یک مقدار ثابت، نامشخص یا غیرقابلدسترس است.
با وجود سادگی ظاهری، این تحلیل بهسرعت با مشکل از دست رفتن دقت مواجه میشود، بهویژه زمانی که مسیرهای کنترلی مختلف به یک نقطه میرسند. با این حال، نتایج آن برای سادهسازی عبارات، حذف محاسبات زائد و بهبود کارایی برنامه بسیار ارزشمند است.
8.8 تحلیل بازهای
در تحلیل بازهای، به جای نگهداری یک مقدار دقیق، برای هر متغیر یک بازه ممکن از مقادیر ذخیره میشود. این رویکرد امکان بیان اطلاعات غنیتری نسبت به تحلیل ثابتها فراهم میکند و برای تشخیص خطاهایی مانند سرریز یا دسترسی خارج از محدوده مفید است.
مشکل اصلی این تحلیل، رشد نامحدود بازهها در حضور حلقههاست. برای حل این مسئله، از تکنیکهایی مانند widening برای تضمین همگرایی و narrowing برای بازیابی بخشی از دقت از دسترفته استفاده میشود.
8.9 تحلیل اشارهگرها و همنامی
تحلیل اشارهگرها یکی از پیچیدهترین انواع تحلیل ایستا است. هدف آن تعیین این است که یک اشارهگر ممکن است به کدام مکانهای حافظه اشاره کند. وجود همنامی باعث میشود که چند نام مختلف به یک مکان حافظه اشاره داشته باشند، که این امر تحلیلهای دیگر را بهشدت محافظهکار میکند. برای مدیریت این پیچیدگی، مکانهای حافظه بهصورت انتزاعی مدل میشوند و تخصیصهای مختلف ممکن است در یک نماد واحد ادغام شوند. دقت این تحلیل تأثیر مستقیمی بر کیفیت بسیاری از تحلیلها و بهینهسازیهای بعدی دارد.
9. نتیجهگیری
مسیر مفهومی مطرحشده در این بحث، به یک ایدهی محوری ختم میشود : تبدیل برنامه از یک متن اجرایی به یک موجودیت قابل تحلیل، استدلال و کنترل. در این نگاه، برنامه صرفاً مجموعهای از دستوراتی نیست که باید اجرا شوند، بلکه ساختاری صوری است که میتوان آن را مدلسازی کرد، روی آن استنتاج انجام داد و پیش از اجرا دربارهی رفتارهای ممکن آن قضاوت کرد. این تغییر زاویه دید، مبنای اصلی علوم کامپیوتر مدرن در حوزهی زبانهای برنامهنویسی و مهندسی نرمافزار است.
کامپایلر در این چارچوب نقش یک لایهی واسط ساده را بازی نمیکند، بلکه بهمثابهی یک سیستم تحلیلی عمل میکند که برنامه را مرحلهبهمرحله به نمایشهایی دقیقتر و قابل پردازشتر تبدیل میسازد. هر فاز، بخشی از ابهام برنامه را حذف کرده و آن را به شکلی ساختاریافته نزدیکتر میکند؛ شکلی که در آن معنا، جریان کنترل، وابستگی دادهها و محدودیتهای زبانی بهصورت صریح قابل مشاهدهاند. نتیجهی این فرآیند، فراهمشدن بستری است که در آن میتوان بهجای اجرای برنامه، دربارهی آن استدلال کرد.
در ادامهی این مسیر، تحلیل ایستا بهعنوان نقطهی تمرکز اصلی ظاهر میشود. هدف آن نه شبیهسازی دقیق اجرا، بلکه استخراج اطلاعات معنادار دربارهی مجموعهای از رفتارهای ممکن برنامه است. این اطلاعات به مهندس نرمافزار اجازه میدهد تا بدون وابستگی به ورودیهای خاص یا سناریوهای محدود، دیدی کلی و اصولی نسبت به صحت، ایمنی و کارایی برنامه به دست آورد. تحلیل ایستا بهطور بنیادین بر این فرض استوار است که بسیاری از خطاها، ناایمنیها و ناکارآمدیها را میتوان پیش از اجرا و تنها از روی ساختار برنامه تشخیص داد.
اهمیت این رویکرد زمانی آشکارتر میشود که برنامهها به سیستمهایی بزرگ، پیچیده و حساس تبدیل میشوند؛ جایی که خطا نهتنها یک باگ ساده، بلکه یک ریسک امنیتی، یک نقص پایداری یا یک شکست سیستمی محسوب میشود. در چنین شرایطی، تکیه بر تست و اجرای تجربی کافی نیست و نیاز به ابزارهایی وجود دارد که بتوانند بهصورت سیستماتیک همهی مسیرهای ممکن اجرا را در نظر بگیرند. تحلیل ایستا دقیقاً پاسخ به همین نیاز است و پلی میان نظریهی محاسبات و مهندسی عملی نرمافزار ایجاد میکند.
در نهایت، تمام این مفاهیم به شکلگیری یک توانمندی کلیدی منجر میشوند: طراحی و ساخت نرمافزارهایی که رفتار آنها پیش از اجرا قابل پیشبینی، قابل کنترل و قابل اعتماد باشد. این توانمندی پایهی ابزارهای پیشرفتهای مانند کشف خودکار خطا، تحلیل امنیتی، اثبات ویژگیهای برنامه و بهینهسازیهای هوشمند است. بنابراین، این مسیر صرفاً مقدمهای بر یک موضوع خاص نیست، بلکه چارچوب فکری لازم برای ورود به حوزههایی است که در آنها کیفیت، امنیت و درستی نرمافزار بهعنوان یک مسئلهی صوری و مهندسیشده مطرح میشود، نه نتیجهای تصادفی از آزمایش و اجرا.