
فازینگ شامل تعداد زیادی تصمیمگیری است که برای به حداکثر رساندن کارایی، به پارامترهای دقیق و از پیشتنظیم شده نیاز دارند. این موضوع به ویژه در فازینگ هستهٔ سیستمعامل اهمیت بیشتری دارد، زیرا (۱) هستههای سیستم عامل بسیار بزرگ و پیچیدهاند، (۲) رابط فراخوانی سیستمی (syscall) خاصی دارند که نیازمند مدیریت ویژه است (مثلاً کدگذاری وابستگیهای صریح بین syscallها)، و (۳) رفتار ورودیها (یعنی تستکیسها) به دلیل ماهیت حالتمند هستهها اغلب قابل بازتولید نیست. بنابراین، ابزار Syzkaller که پیشرفتهترین فازر جعبه خاکستری برای هسته محسوب میشود، شامل رویهها، نقاط تصمیمگیری و پارامترهای ثابت فراوانی است که توسط متخصصان این حوزه بهصورت دستی طراحی شدهاند. با این حال، راهبردهای ثابت نمیتوانند خود را با شرایطی مانند محیطها یا اهداف مختلف فازینگ و همچنین تغییر پویای کارایی وظایف یا بذرها (seed) تطبیق دهند و در نتیجه اثربخشی کلی فازر محدود میشود.
در این مقاله، ما SYZVEGAS را معرفی میکنیم؛ یک فازر که دو نقطهٔ تصمیمگیری بسیار مهم در Syzkaller یعنی انتخاب وظیفه (task) و انتخاب بذر (seed) را بهصورت پویا و خودکار تطبیق میدهد تا میزان پوشش کد در واحد زمان بهطور چشمگیری افزایش یابد. سازوکار تطبیق SYZVEGAS از الگوریتمهای باندیت چنداهرمی (Multi-Armed Bandit یا MAB) به همراه یک مدل جدید ارزیابی پاداش استفاده میکند. ارزیابیهای گسترده روی آخرین نسخهٔ هستهٔ لینوکس و زیرسیستمهای آن نشان میدهد که SYZVEGAS (۱) تا ۳۸٫۷٪ پوشش بیشتری نسبت به Syzkaller پیشفرض به دست میآورد، (۲) باگها و کرشهای بیشتری را کشف میکند (۸ کرش منحصربهفرد بیشتر)، و (۳) تنها ۲٫۱٪ سربار عملکردی ایجاد میکند. نتایج این پژوهش به تیم Syzkaller در گوگل گزارش شده و پژوهشگران در حال همکاری برای افزودن این تغییرات به نسخهٔ اصلی پروژه هستند.
1. مقدمه
فازینگ جعبه خاکستری (Gray-box fuzzing) یا فازینگ هدایت شده با پوشش (coverage-guided fuzzing) در سالهای اخیر توجه زیادی را به خود جلب کرده است. فازینگ اغلب نوعی «هنر» تلقی میشود، زیرا فازرها شامل مجموعهای از روشهای ابتکاری هستند که معمولاً نقاط تصمیمگیری و پارامترهای فراوانی دارند (برای مثال انتخاب اینکه کدام بذر (seed) جهش داده شود) و در مجموع میزان کارایی آنها را تعیین میکنند.
انتخابهای طراحی در فازرها معمولاً نهتنها به شهود قوی و تخصص حوزه وابستهاند، بلکه به آزمایشها و تنظیمات تجربی گسترده نیز نیاز دارند. در بسیاری از موارد، این انتخابها میتوانند باعث تخصص بیش از حد برای مجموعهای خاص از پایگاههای کد هدف مورد استفاده در طول فرآیند تنظیم شوند.
اگرچه تلاشهایی برای تنظیم خودکار تصمیمهای مختلف در فازینگ، از جمله انتخاب بذر [26،33،35] و عملگرهای جهش (mutation operators) [8،9،17،22] انجام شده است، اما کارهای پیشین عمدتاً راهحلهایی موردی بودهاند و هیچکدام بهطور خاص برای فازینگ کرنل سیستم عامل (Operating System Kernel) طراحی نشدهاند. فازینگ هسته به دلایل زیر بهطور ویژهای چالشبرانگیز است: (1) هستههای مدرن سیستمعامل دارای پایگاه کدی بسیار بزرگ و وابستگیهای گسترده میان مؤلفهها هستند؛ (2) ورودی هستهٔ سیستمعامل از طریق رابط فراخوانی سیستمی (system call interface) انجام میشود که نیازمند مدیریت و پردازش خاصی است؛ و (3) هستهٔ سیستمعامل فضای حالت بسیار بزرگی را نگه میدارد، بهطوریکه ممکن است یک ورودی واحد (یعنی یک test case) قابل بازتولید نباشد.
برای نمونه، فازر پیشرفتهٔ هسته یعنی Syzkaller [14] بیش از ۶۲٬۰۰۰ خط کد دارد و شامل پارامترهای قابل تنظیم متعددی برای بهبود کارایی است. با توجه به این فضای بزرگ و پیچیده و همچنین راهبردهای موردی مورد استفاده برای تنظیم پارامترها، ما معتقدیم فرصتهای قابلتوجهی برای بهبود فازینگ هسته وجود دارد.
برای مقابله با چالشهای فوق، Syzkaller از ترکیبی از تولید ورودیها[13] و جهش ورودیها[5] استفاده میکند. بهطور مشخص، برای تولید ورودیها (دنبالهای از system callها) از ابتدا، Syzkaller به مدلهای ورودی دستی ساخته شده به نام «templates» یا قالبها نیاز دارد. همچنین از ورودیهای قبلاً معتبر (یا همان corpus seed) که پیشتر پوشش کد جدیدی کشف کردهاند استفاده میکند و آنها را جهش (Mutation) میدهد تا ورودیهای جدید تولید شوند. در نهایت، Syzkaller هر ورودی را بررسی و بهینهسازی میکند تا مطمئن شود کمترین ورودی ممکن بتواند همان پوشش بهدستآمده را بازتولید کند، پیش از آنکه به یک seed تبدیل شود. Syzkaller از یک استراتژی ثابت برای زمانبندی انواع مختلف وظایف فازینگ و یک استراتژی ثابت و هاردکد و از پیشتنظیم شده برای انتخاب بذرهایی (seed) که باید جهش داده شوند، استفاده میکند.
ما در این مقاله، SYZVEGAS را معرفی میکنیم؛ یک فازر مبتنی بر Syzkaller که قادر است استراتژیهای خود را بهصورت پویا و خودکار تطبیق دهد تا پوشش کد را بهبود بخشد. بهطور مشخص، تمرکز ما بر حل دو فرایند تصمیمگیری اولویتدار است:
- انتخاب (زمانبندی) پربازدهترین وظایف فازینگ (مانند تولید ورودی، جهش ورودی و بررسی/بهینهسازی)
- انتخاب مؤثرترین بذرها (seed) برای جهش.
هر دوی این تصمیمها در SYZVEGAS بهصورت پویا و با استفاده از یک مدل واحد ارزیابی پاداش انجام میشوند تا شانس کشف پوشش کد جدید و پیدا کردن آسیبپذیریهای تازه بهطور چشمگیری افزایش یابد. مهمترین دستاوردهای ما عبارتاند از:
- شناسایی فرصتهای بهینهسازی: ما یک تحلیل سیستماتیک از سیاستهای انتخاب وظیفه و seed ثابت Syzkaller انجام دادیم و چندین فرصت برای افزایش کارایی فازینگ آن شناسایی کردیم.
- پیادهسازی فازینگ پویا: SYZVEGAS از یک الگوریتم سبک MAB تهاجمی استفاده میکند تا سیاستهای انتخاب وظیفه و بذر (seed) را بهصورت پویا تنظیم کند. این روش شامل یک رویکرد نوآورانه برای مدلسازی پاداش وظایف فازینگ است که هم کشف پوشش جدید و هم هزینه زمانی صرفشده را در نظر میگیرد. این رویکرد همچنین وابستگی بین انواع مختلف وظایف را در نظر میگیرد، قادر است سریعاً در مراحل مختلف فازینگ تطبیق یابد و سربار بسیار کمی دارد. تا جایی که ما میدانیم،SYZVEGAS اولین فازری است که (۱) از مدل MAB متخاصم برای انتخاب وظیفه استفاده میکند و توابع پاداش مناسب برای آن طراحی میکند و (۲) مفهوم زمان صرف شده برای کشف پوشش جدید را در تابع پاداش وارد میکند.
- افزایش پوشش کد: ما ارزیابیهای گستردهای از SYZVEGAS روی آخرین نسخهٔ هسته لینوکس انجام دادیم و نشان دادیم که این فازر بهطور مستمر ۳۸٫۷٪ پوشش بیشتری نسبت به Syzkaller پیشفرض بهدست میآورد و کرشهای منحصربهفرد بیشتری کشف میکند. در مجموع، ما ۱۳ کرش بیشتر (۸ کرش منحصربهفرد) نسبت به Syzkaller در همان بازه زمانی یافتیم. برای هستههای OS مانند لینوکس، چنین بهبودی بسیار مهم است، زیرا هر نسخهٔ هسته بهطور مداوم فاز و تست میشود (مثلاً توسط گوگل [15]).
- قابلیت اجرا در فضای کاربر: ما همچنین نشان دادیم که ماژول انتخاب بذر SYZVEGAS میتواند در فضای کاربر (user-space) نیز اعمال شود و عملکرد آن در مقایسه با یک فازر پیشرفته مبتنی بر یادگیری تقویتی، یعنی EcoFuzz [34]، رضایتبخش و رقابتی است.
2. پیشزمینه و انگیزه
2.1 Syzkaller
Syzkaller هستهٔ سیستم عامل را با اجرای مجموعهای از برنامههای آزمایشی، یعنی یک دنباله از system callها، بررسی میکند. برای ساخت چنین برنامههایی، Syzkaller دو گزینه دارد: تولید یک برنامهٔ جدید از صفر یا جهش دادن یک برنامهٔ موجود. در طول فرایند فازینگ، سه نوع وظیفه اجرا میشود: تولید (Generation)، جهش (Mutation) و تریاژ (Triage) (جزئیات بیشتر در بخش ۸.۱).
- تولید برنامه آزمایشی (Generation): Syzkaller یک برنامهٔ آزمایشی کاملاً جدید میسازد که با استفاده از قالبها ایجاد میشود. این قالبها توسط متخصصان حوزه (مثلاً توسعهدهندگان هسته) بهصورت دستی تهیه شده و شامل اطلاعاتی درباره نوع آرگومان هر system call و وابستگیها میان system callها هستند (مثلاً مقدار بازگشتی open بعداً در read قابل استفاده است). این روش به Syzkaller اجازه میدهد دنبالههای معنی دار از system callها و آرگومانها تولید کند و احتمال کاوش کد عمیقتر هسته را افزایش دهد.
- جهش (Mutation): در این مرحله، Syzkaller به طور تصادفی یک برنامهٔ از میان مجموعه نمونهها (corpus) انتخاب میکند که شامل برنامههایی است که قبلاً پوشش جدیدی ایجاد کردهاند و به آنها بذر (Seed) گفته میشود. سپس مجموعهای از جهشهای تصادفی روی برنامه اعمال میکند، مانند اضافه یا حذف یک system call جدید یا تغییر آرگومان یک system call موجود با استفاده از قالبهای داخلی، و در نهایت برنامهٔ جهشیافته اجرا میشود تا اثر تغییرات و احتمال کشف پوشش جدید بررسی شود.
- بررسی، تأیید و اولویتبندی (Triage): Syzkaller برنامهای که تازه تولید یا جهش داده شده و پوشش جدیدی ایجاد کرده است را برای تریاژ دریافت میکند، یعنی آن را بررسی، تأیید و اولویتبندی میکند. ابتدا عملیات تایید انجام میشود تا اطمینان حاصل شود پوشش جدید قابل تکرار است و تحت تأثیر ماهیت حالتمند هسته، غیرقطعی بودن اجرا و همزمانی بین فرآیندها قرار نمیگیرد. در صورت موفقیت، برنامه حداقل سازی میشود (حذف برخی فراخوانیهای سیستمی (system callها) و/یا کوتاه کردن آرگومانها در حالی که پوشش پایدار حفظ میشود) و به بذر مجموعه نمونه (corpus seed) اضافه میگردد تا جهشهای بعدی روی آن انجام شود. در طول حداقل سازی، ممکن است کشف شود که یک برنامهٔ تا حدی حداقل سازی شده پوشش جدید ایجاد میکند؛ این برنامهها برای تریاژ بعدی علامتگذاری میشوند.
بهطور پیشفرض، Syzkaller سه نوع کار فازینگ ذکر شده را طبق اولویتهای هاردکد شده زیر انتخاب میکند:
۱. تریاژ (Triage) نسبت به تولید (Generation) و جهش (Mutation) اولویت دارد.
۲. زمانی که هیچ وظیفهٔ تریاژ موجود نباشد، بالاترین اولویت به جهش برنامههایی داده میشود که تازه به بذر مجموعه نمونه (corpus seed) اضافه شدهاند. هر بذر جدید برای تعداد ثابتی (۱۰۰) جهش داده میشود. این جهشها رفتار ویژهای دارند و در Syzkaller به آنها Smash گفته میشود.
۳. اگر هیچ وظیفهٔ تریاژ یا Smash موجود نباشد، Syzkaller کارهای تولید و جهش معمولی را با نسبت ثابت ۱:۹۹ اجرا میکند (یک کار تولید برای هر ۹۹ کار جهش).
در عمل، وقتی Syzkaller از صفر شروع میکند، ابتدا یک کار تولید (Generation) انجام میدهد و بخشی از کد کرنل پوشش داده میشود. این برنامهٔ اولیه سپس وارد تریاژ میشود، که بذر اولیه (seed) را تولید میکند و احتمالاً برنامههای بیشتری برای تریاژ در طول حداقل سازی ایجاد میکند. سپس Syzkaller روی تریاژ این برنامههای اضافی (اگر در حداقل سازی ایجاد شده باشند) و Smash کردن بذرهای جدید تمرکز میکند، که به نوبهٔ خود بذرهای بیشتری برای Smash و برنامههایی برای تریاژ ایجاد میکند. پیش رفتن به این روش معمولاً یک واکنش زنجیرهای عظیم ایجاد میکند. در نتیجه، تعداد واقعی کارهای تولید که Syzkaller انجام میدهد، بسیار کمتر از آن چیزی است که توضیح سیاست ممکن است نشان دهد.
وقتی به جهش میرسیم، Syzkaller انتخاب میکند کدام بذر را جهش دهد طبق اصول زیر: اول، همانطور که قبلاً توضیح داده شد، یک بذر تازه ایجاد شده از ۱۰۰ جهش با اولویت بالا بهرهمند میشود (Smash). دوم، به هر بذر یک وزن اختصاص داده میشود که برابر با تعداد پوشش لبههای جدید و پایدار است که آن بذر ایجاد میکند. این عدد ثابت است و در طول زمان تغییر نمیکند. وقتی Syzkaller نیاز دارد یک بذر از میام مجموعه بذرها انتخاب کند، آن را بر اساس این وزن و از میان تمام بذرها انتخاب میکند.
زمانبندی بین وظایف مختلف در Syzkaller منحصر به فرد است، زیرا فازرهای فضای کاربر معمولاً (۱) قالبهای مشخصی برای انجام تولید ندارند و (۲) نیازی هم به تریاژ ندارند، چرا که تحت تأثیر حالتمندی، عدمقطعیت یا همزمانی در کرنلهای OS قرار نمیگیرند. بنابراین، بهینهسازیهایی که برای فازرهای فضای کاربر انجام میشوند، اغلب نمیتوانند بهطور مستقیم روی Syzkaller اعمال شوند.
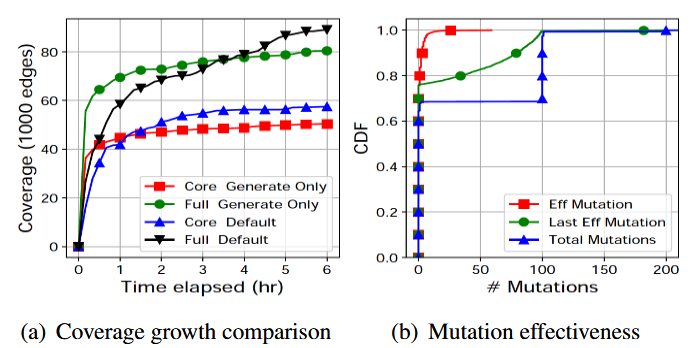
۲.۲ مشاهدات
در این بخش، استفاده از رویکرد مبتنی بر یادگیری برای بهبود پوشش Syzkaller را توجیه میکنیم. ما Syzkaller پیشفرض را در کنار نسخهٔ تعدیلشدهای که فقط کارهای تولید انجام میدهد، روی یک ماشین مجازی فازر با پردازندهٔ دو هستهای به مدت ۶ ساعت اجرا کردیم. شاخصهایی مانند رشد پوشش و اثربخشی وظایف را جمعآوری کردیم تا بینشی نسبت به عملکرد نسخهٔ پیشفرض به دست آوریم. آزمایشهای ما روی پردازنده Intel(R) Xeon(R) E5-2680 v4 با فرکانس ۲.۴۰ گیگاهرتز انجام شد. مشاهدات حاصل به شرح زیر است: بهترین استراتژی در طول زمان تغییر میکند. بر اساس سیاست انتخاب وظایف که پیشتر بحث شد، Syzkaller به تولید اولویت کمی میدهد. با این حال، با استفاده از قالب مناسب و دقیق، تولید میتواند قدرتمند باشد، بهویژه در مراحل اولیهٔ فازینگ که بیشتر کد کرنل هنوز کشف نشده است.
بهترین استراتژی در طول زمان تغییر میکند. بر اساس سیاست انتخاب وظایف که پیشتر توضیح داده شد، Syzkaller به تولید اولویت کمی میدهد. با این حال، با استفاده از یک قالب دقیق و خوب نوشتهشده، تولید میتواند بسیار مؤثر باشد، بهویژه در مراحل اولیهٔ فازینگ که بیشتر کد کرنل هنوز کشف نشده است.
شکل ۱ (a) مقایسهٔ رشد پوشش بین دو نسخهٔ Syzkaller را نشان میدهد، زمانی که روی (۱) کل کرنل لینوکس و (۲) هستهٔ اصلی کرنل بدون زیرسیستمهایی مانند فایلسیستم و درایورها فازینگ انجام میشود. در مورد کل کرنل، در اولین ساعت فازینگ، نسخهٔ تولید (Generation) بهطور قابل توجهی بهتر از نسخهٔ پیشفرض عمل میکند. با این حال، بعد از ۴ ساعت، نسخهٔ تولید از نسخهٔ پیشفرض عقب میماند. هنگام فازینگ هستهٔ اصلی کرنل، تنها پس از ۱ ساعت نسخهٔ پیشفرض Syzkaller نسخهٔ تولید را پشت سر میگذارد. این نتایج نشان میدهد که استراتژی بهینه پویا است و باید در طول زمان سازگار شود، که استفاده از رویکرد مبتنی بر یادگیری را توجیه میکند.
تصمیمات سلیقهای میتوانند مضر باشند. Syzkaller به جهش (mutation) بذرهای (Seed) تازه کشف شده اولویت میدهد و ۱۰۰ جهش اجباری را اعمال میکند تا سریعاً پوشش زیادی به دست آورد. علاوه بر این، منطق «زمانبندی وظایف» Syzkaller از ساختارهای LIFO استفاده میکند تا جدیدترین بذرها ابتدا بررسی شوند. بدون شک، کارشناسان حوزه پشت Syzkaller این استراتژی را با آزمایشهای گسترده به دقت انتخاب کردهاند. با این حال، این تصمیم ایستا و سلیقهای محدودیتهایی دارد.
شکل ۱ (b) اثربخشی جهش Syzkaller را در فازینگ کل کرنل لینوکس به مدت ۶ ساعت نشان میدهد. میتوان سه فرصت برای بهبود را مشاهده کرد: (۱) بسیاری از بذرها دچار جهش نمیشوند زیرا Syzkaller بیش از حد مشغول اجرای تعداد اجباری جهشها و تریاژ است. (۲) ما واکنشهای زنجیرهای مشاهده میکنیم که در آن ۱۰۰ جهش جدید «smash» یک برنامه، پوشش جدیدی کشف میکنند و بلافاصله ۱۰۰ جهش «smash» جدید دیگر برای هر کدام برنامهریزی میشود، که باعث تمرکز بیش از حد روی بذرهای یک ریشهٔ خاص میشود؛ و (۳) بسیاری از بذرهای جهش یافته اجباری، شایستهٔ جهش ۱۰۰ باره نیستند.
این رفتارها به نظر میرسد پیامد ناخواستهٔ تصمیم سلیقهای (اما شاید از نظر تجربی قابل قبول) برای اعمال ۱۰۰ جهش روی هر بذر جدید باشد. ما تلاش کردیم برخی تنظیمات ایستا ساده (مثلاً کاهش تعداد جهشهای smash، اجبار به انجام چند تولید در ابتدا) را اعمال کنیم، اما هیچکدام بهبود پوشش مطلوب یا سازگاری در سناریوهای مختلف (مثل نسخهٔ کرنل یا بذرهای اولیه) ایجاد نکردند. بنابراین، استفاده از یک تکنیک مبتنی بر یادگیری بهترین رویکرد برای غلبه بر این مشکلات و افزایش اثربخشی فازینگ است.
بینش کلی: مشاهدات ما نشان میدهند که فرصتهای زیادی برای تنظیم پارامترهای سختکد شده مختلف (مثل تعداد جهشها، نسبت تولید به جهش) و اولویتها وجود دارد. همچنین نشان میدهند که استراتژی مناسب و بذر مناسب به صورت پویا در طول زمان تغییر میکنند. آنچه نیاز است، روشی خودکار برای شناسایی «مناسبترین» وظیفه در زمان مشخص و، در صورت لزوم، «بهترین بذر» برای اجرای آن وظیفه است. برای شناسایی این موارد، یک طرح مبتنی بر یادگیری تقویتی طبیعیترین انتخاب است، که در آن مدلی برای حداکثر کردن پاداش پوشش نسبت به هزینهٔ زمانی اجرای آن قابل استفاده است.
2.3 مسئله باندیت چند اهرمـی (Multi-armed Bandit Problem)
مسئله باندیت چنداهرمـی (MAB) برای مدلسازی تصمیمهای مختلف Syzkaller بسیار مناسب است. در این مسأله، یک قمارباز (gambler) باید چندین اهرمی دستگاههای بازی (انتخابها) را بازی کند تا سود مورد انتظار خود را بیشینه کند. ویژگیهای هر اهرم در ابتدا فقط تا حدی شناخته شدهاند و با بازی بیشتر اهرم، شناخت از آن بهتر میشود. مسأله MAB نمونه کلاسیک تعادل بین کاوش (exploration) و بهرهبرداری (exploitation) است.
جدول 1: نمادهایی که برای توصیف SYZVEGAS استفاده شده است

یکی از قویترین تعمیمهای مسئله MAB، نسخه MAB متخاصم است که در سال ۱۹۹۵ معرفی شد [6]. در این حالت، پاداش هر اهرم میتواند در هر بار بازی بهطور دلخواه تغییر کند. حل این مسأله نیازمند واکنش سریع به تغییرات پاداش هر اهرم است، که بهخوبی با فرآیند فازینگ مطابقت دارد، جایی که هر تصمیم میتواند در طول زمان پاداش متفاوتی دریافت کند.
Auer و همکاران الگوریتم Exp3 یا وزننمایی شده برای کاوش و بهرهبرداری (Exponential-weight algorithm for Exploration and Exploitation) را برای مسأله باندیت متخاصم پیشنهاد دادند [7]. ایده اصلی این است که وزن یک اهرم خوب (یعنی احتمال انتخاب آن) به صورت نمایی افزایش یابد تا اهرمهای مفید سریع شناسایی و بهرهبرداری شوند. برخی از نسخههای مهم الگوریتم Exp3 شامل موارد زیر هستند:
- Exp3.1 [7]: بازنشانی دورهای دارد و با گذشت زمان عملکرد بهتری نشان میدهد.
- Exp4 [7]: امکان ورودی یک بردار برای توصیههای بیشتر را فراهم میکند.
- Exp3M.B [36]: اجازه میدهد چند اهرم همزمان با بودجه محدود اجرا شوند.
- Exp3-IX [23]: از کاوش ضمنی (implicit exploration) استفاده میکند.
مدلهای دیگر یادگیری تقویتی هم وجود دارند، که هر کدام تمرکز و نقاط قوت متفاوتی دارند. ما باندیت چند اهرمی (MAB) را انتخاب کردیم چون به نظر میرسد بهطور طبیعی با مسئله ما سازگار است، چرا که تصمیماتش گسسته هستند و سربار کمی دارد. از آنجا که پاداش گزینههای فاز فازینگ میتواند با زمان تغییر کند (مثلاً تولید برنامهها از صفر فقط در مراحل اولیه مفید است و برنامههای seed با هر بار تغییر، کارایی کمتری دارند)، ما معتقدیم که MAB متخاصم برای مسئله فاز فازینگ بسیار مناسب است (همانطور که در تحقیقات قبلی مانند EcoFuzz بررسی شده است).
مشارکت ما، پیشنهاد استفاده از یادگیری تقویتی در فاز فازینگ کرنل است، نه الگوریتم یادگیری خاص. بررسی و به کارگیری دیگر استراتژیهای یادگیری را به کارهای آینده واگذار کردهایم.
۳. طراحی و پیادهسازی
ما SYZVEGAS را بهعنوان یک رویکرد فازینگ پویا پیشنهاد میکنیم که وظیفهٔ انتخاب میان سه نوع وظیفه (Task) موجود در Syzkaller را بر عهده دارد. اهداف اصلی طراحی SYZVEGAS به شرح زیر است:
- پوششدهی بهینه (Optimal Coverage): SYZVEGAS باید وظایف را زمانبندی کرده یا برنامههای بذر (Seed Programs) مناسب برای جهش (Mutation) را بهگونهای انتخاب کند که بیشترین میزان پوشش (Coverage) در Syzkaller حاصل شود، در حالی که هزینهٔ زمانی تحمیل شده نیز به حداقل برسد.
- تنظیم تطبیقی (Adaptive Adjustment): SYZVEGAS باید در هر مرحله از فرایند فازینگ تشخیص دهد کدام نوع وظیفه بهترین انتخاب است و راهبرد خود را بهصورت پویا با شرایط موجود تطبیق دهد. همچنین هنگام انجام جهشها، SYZVEGAS باید کیفیت (یا میزان تغییر مؤثر) بذر جهشیافته را ارزیابی کرده و اولویت آن را در مجموعهٔ بذرها (Seed Corpus) متناسب با این ارزیابی تنظیم کند.
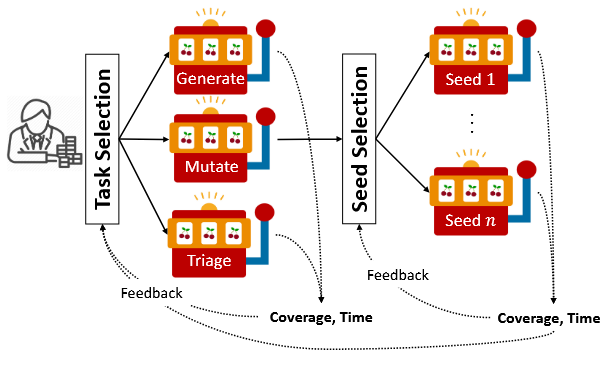
به منظور دستیابی به این اهداف، SYZVEGAS مسئلهٔ انتخاب وظیفه/بذر (Task/Seed Selection) را همانگونه که در شکل ۲ نشان داده شده است به صورت یک مسئلهٔ باندیت چند اهرمی متخاصم (Adversarial Multi-Armed Bandit یا MAB) مدلسازی میکند. در این مدل، وظیفههای تولید (Generation)، جهش (Mutation) و تریاژ (Triage) به عنوان سه اهرم (Arm) اصلی در نظر گرفته میشوند.
هنگامی که عملیات جهش اجرا میشود، SYZVEGAS انتخاب بذر را به عنوان یک لایهٔ دیگر از مسئلهٔ MAB در نظر میگیرد؛ به این معنا که هر بذر (Seed) به صورت یک اهرم مستقل مدل میشود. SYZVEGAS پس از هر بار اجرا، میزان پوشش حاصل شده (Coverage) و هزینهٔ زمانی صرف شده را جمعآوری کرده و بر اساس آن، بازخورد لازم را برای فرایند تصمیمگیری MAB محاسبه میکند. این محاسبه با استفاده از الگوریتمی مشابه روشهایی مانند Exp3-IX [23] (برای جزئیات بیشتر به بخش ۸.۲ مراجعه کنید) و Exp3.1 [7] انجام میشود.
با تکرار این فرایند، SYZVEGAS به صورت پیوسته بهروزرسانی میکند که کدام اهرمها باید انتخاب شوند تا میزان پوشش به دست آمده در واحد زمان بیشینه شود. برای آن که SYZVEGAS بتواند انتخاب وظیفه و بذر را بهصورت پویا و مؤثر انجام دهد، دو چالش کلیدی وجود دارد:
- ارزیابی ارزش وظیفه انتخاب شده یا بذر جهش یافته
- انتخاب وظیفه یا بذری که بیشترین پتانسیل را دارد
در ادامه توضیح میدهیم که SYZVEGAS چگونه بر این چالشها غلبه میکند. جدول ۱ نیز نمادهای استفاده شده در بخشهای بعدی را برای ارجاع معرفی میکند.
۳.۱ ارزیابی پاداش (Reward Assessment)
هر زمان که یکی از وظیفههای تولید (Generation)، جهش (Mutation) یا تریاژ (Triage) اجرای خود را به پایان برساند، لازم است یک مقدار پاداش (Reward) به آن اختصاص داده شود تا در مدل باندیت چند اهرمی متخاصم (Adversarial MAB) مورد استفادهٔ SYZVEGAS به کار رود. الزامات و چالشهای اصلی در محاسبهٔ این پاداش به شرح زیر هستند:
- درنظر گرفتن سود و هزینه (Gain and Cost Considerations). هدف SYZVEGAS بیشینهسازی سود یعنی تعداد یالهای پوشش داده شده (Covered Edges) در کنار کمینهسازی هزینه یعنی زمان صرف شده برای اجرا است. بنابراین مدل باید این معیارها را که دارای واحدهای متفاوت هستند، در قالب یک معیار واحد برای سنجش میزان اثربخشی یا مطلوبیت (Utility) هر وظیفه یکپارچه کند.
- وابستگی میان وظیفهها (Dependencies Between Tasks). برخلاف فرض رایج در مسئلهٔ کلاسیک MAB که اهرمها مستقل از یکدیگر هستند، در بستر Syzkaller چنین استقلالی وجود ندارد. همانطور که در شکل ۱۰ نشان داده شده است، میان وظیفههای تریاژ و جهش وابستگی و ارتباط قوی وجود دارد. بنابراین SYZVEGAS هنگام تخصیص پاداش به هر اهرم باید این وابستگی را بهدرستی مدلسازی و لحاظ کند.
- نرمالسازی (Normalization). مقدار مطلوبیت مشاهده شده در سیستمهای مختلف میتواند متفاوت باشد. برای مثال، زمان اجرای یک برنامه در اندروید (Android) معمولاً بسیار بیشتر از اجرای همان برنامه روی یک سرور قدرتمند است. علاوه بر این، الگوریتمهایی که برای حل مسائل باندیت متخاصم استفاده میشوند اغلب نیاز دارند مقدار پاداش نرمالسازی شده باشد. بنابراین لازم است مقادیر پاداش پیش از ورود به فرایند تصمیمگیری استانداردسازی شوند.
برای مواجهه با چالشهای مطرحشده، مدل ارزیابی پاداش خود را با درنظرگرفتن هر یک از وظیفههای موردنظر بهصورت زیر طراحی میکنیم.
تولید (Generation). وظیفه تولید بهطور مستقیم با وظیفههای جهش (Mutation) یا تریاژ (Triage) درهمتنیده نیست؛ بنابراین پاداش آن بهصورت مستقل ارزیابی میشود. فرض کنیدc میزان پوشش جدید (Coverage) به دستآمده از طریق تولید یک برنامه باشد که با تعداد یالهای پوشش داده شده اندازهگیری میشود. همچنینt هزینهٔ زمانی اجرای این برنامه است. مقدار C نشاندهندهٔ کل پوشش به دستآمده تاکنون (صرفنظر از اینکه توسط کدام وظیفه ایجاد شده) وT بیانگر کل زمان سپری شده از آغاز اجرای فازر است. با توجه به این مقادیر، زمان مورد انتظار برای دستیابی به پوشش جدید c با فرض عملکرد میانگین فازر تا زمان T میتواند بهصورت زیر «برآورد» شود:
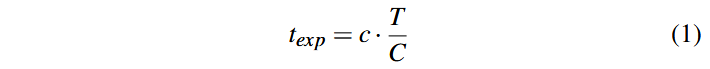
پاداش مربوط به وظیفه تولید (Generation) را میتوان بهصورت اختلاف میان هزینهٔ زمانی مورد انتظار و هزینهٔ زمانی واقعی اجرا یعنی t مدلسازی کرد:
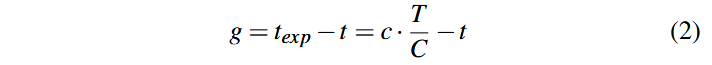
توجه داشته باشید که مقدار g در واقع نرخ کشف پوشش (Coverage Discovery Rate) در وظیفه تولید فعلی (c/t) را با نرخ تاریخی کشف پوشش (C/T) مقایسه میکند. اگر این وظیفه دارای نرخ کشف پوششی بهتر از میانگین تاریخی باشد، همواره پاداشی مثبت دریافت خواهد کرد؛ در مقابل، اگر نرخ کشف پوشش آن پایینتر از عملکرد تاریخی باشد، مقدار پاداش منفی خواهد شد.
این نمایش همچنین تضمین میکند که اگر دو وظیفه A و B هر دو مقدار پوشش یکسانی c تولید کنند اما زمانهای متفاوتی مصرف کنند بهطوریکه tA>tB آنگاه همیشه خواهیم داشت: gA < gB، که از نظر شهودی منطقی است؛ زیرا وظیفهای که پوشش را سریعتر کشف میکند باید پاداش بیشتری دریافت کند.
همچنین توجه کنید که در این مدل، زمان به جای «نرخ» به عنوان واحد پاداش استفاده شده است. این انتخاب تضمین میکند که اگر هر دو وظیفه A و B هیچ پوشش جدیدی تولید نکنند، وضعیتی که در مراحل پایانی فازینگ بسیار رایج است همواره رابطهٔ زیر برقرار باشد: gA < gB < 0. به بیان دیگر، وظیفهای که زمان بیشتری را بدون دستاورد مصرف میکند، نسبت به وظیفهای که زمان کمتری هدر داده است، جریمهٔ بیشتری دریافت خواهد کرد.
جهش و اولویتبندی (Mutation and Triage). وظایف جهش به شدت به اولویتبندی (تریاژ) وابسته هستند زیرا: (1) بذری که باعث جهش میشود فقط از طریق اولویتبندی به دست میآید و (2) اولویتبندی سعی میکند بذر را به حداقل برساند، در نتیجه هزینههای جهشهای آینده را کاهش میدهد. بنابراین، پاداش جهش و اولویتبندی باید به صورت ترکیبی مدلسازی شوند. یک برنامه بذر p را در نظر بگیرید، که در آن هزینه زمانی وظیفه اولویتبندی که p را تأیید و به حداقل رسانده است، ttrip است. همانطور که در بخش 2 بحث شد، اولویتبندی شامل دو مرحله است: تأیید و کمینهسازی، که به ترتیب tverp و tminp هزینه دارند، tverp + tminp = ttrip.
در کمینهسازی، تریاژ ابتدا یک برنامه تولید/جهش یافته p‘ که هزینه اجرای tp’ را دارد دریافت میکند و با حذف فراخوانیهای سیستمی و/یا کوتاه کردن آرگومانها، آن را به p که هزینه tp را دارد «کمینه» میکند. بنابراین، زمان صرفهجویی شده از کمینهسازی برابر با Δtp + tp’ = tp است. در نهایت، کمینهسازی همچنین ممکن است پوشش جدیدی به میزان cminp کشف کند. مرحله تأیید نیز ممکن است پوشش جدیدی را از اجرای مجدد برنامه اصلی ایجاد کند.
با این حال، از آنجایی که این پوشش جدید در اجرای قبلی همان برنامه مشاهده نشده است، برنامه ورودی در این شکل طبق تعریف ناپایدار است (پوشش قابل تکرار نیست). در نتیجه، Syzkaller تلاشی برای پردازش چنین احتمالات پوشش جدیدی نمیکند. ما در این مورد از طرح Syzkaller پیروی میکنیم، یعنی احتمالات پوشش جدید حاصل از تأیید را نادیده میگیریم.
سپس برنامهٔ بذر p، به تعداد m بار دچار جهش (Mutation) میشود. میزان پوشش یالهای مشاهده شده در هر یک از این جهشها به ترتیب برابر با c1p, c2p, … cmp است؛ همچنین هزینهٔ زمانی مرتبط با هر یک از این جهشها نیز به ترتیب برابر با t1p, t2p , …, tmp خواهد بود. برای سادگی، مقادیر فوق را بهصورت زیر نمایش میدهیم:
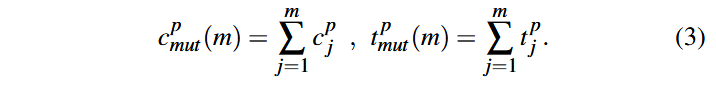
توجه کنید که Syzkaller بدون فاز کمینهسازی (Minimization)، فقط میتواند از برنامهٔ p′ جهش ایجاد کند، نه از p. در این حالت، بهطور میانگین، هر جهش باید به اندازهٔ Δtp زمان بیشتری صرف کند. بنابراین، کمینهسازی منجر به صرفهجویی کل زمانی برابر با m. Δtp در طول m وظیفه جهش میشود.
اگر یک بار وظیفه تریاژ و m وظیفه جهش را بهعنوان یک وظیفه واحد در نظر بگیریم، زمان مورد انتظار برای کشف پوشش جدید(m) cmut بدون کمینهسازی میتواند با استفاده از فرمول زیر محاسبه شود:
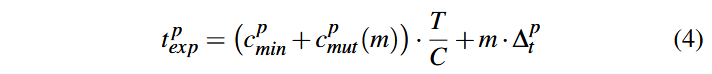
قسمت اول سمت راست معادله، زمان مورد انتظار کل برای کشف پوشش جدید cminp + cmutp (m) با جهش دادن از برنامهٔ p را برآورد میکند؛ قسمت دوم نیز زمان صرفهجویی شده حاصل از بهینهسازی و کمینهسازی (Minimization) را نشان میدهد. بنابراین، پاداش کل حاصل از تریاژ و جهش برنامهٔ بذر p، اختلاف بین «مطلوبیت زمان مورد انتظار» و «مطلوبیت زمان واقعی» است و به صورت زیر بیان میشود:
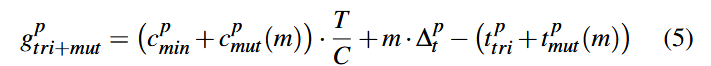
تاکید میکنیم که از آنجا که سهم اصلی فاز کمینهسازی (Minimization) در صرفهجویی زمان برای جهشهای آینده است، بخش صرفهجویی زمان در معادلهٔ ۵ باید بهطور کامل به کمینهسازی نسبت داده شود. علاوه بر این، کمینهسازی ممکن است پوشش جدید cmin را نیز از اجرای برنامههای بهینه شده کشف کند. با ترکیب این دو اثر (صرفهجویی در زمان و کشف پوشش جدید) میتوان پاداش نسبت داده شده به کمینهسازی را بهصورت زیر برآورد کرد:
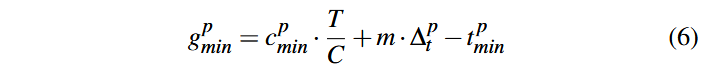
برای ایجاد بذر p، تأیید (Verification) ضروری است؛ زیرا بدون آن، جهشها هیچ بذر قابل جهشی نخواهند داشت. بنابراین، تأیید و جهش باید پاداش مربوط به کشف پوشش جدید را بهصورت نسبتی با هزینههایشان تقسیم کنند. از این رو، پاداش نسبت داده شده به تایید (Verification) و جهش (Mutation) به صورت زیر است:
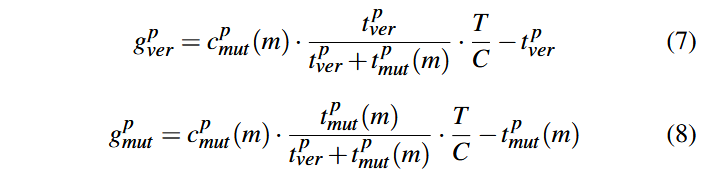
با جمع معادلههای ۶ و ۷، میتوان پاداش کل نسبت داده شده به وظیفه تریاژ را بهصورت زیر به دست آورد:
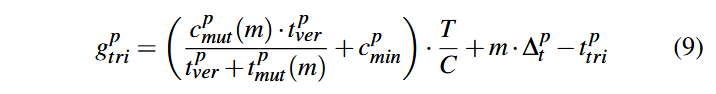
توجه داشته باشید که معادلههای ۸ و ۹ تنها برآورد تقریبی پاداشها برای جهش و تریاژ هستند. در عمل، پیشبینی اینکه یک برنامهٔ بذر p چند بار جهش خواهد یافت، دشوار و تقریباً غیرممکن است. علاوه بر این، محاسبهٔ پاداش بعد از اتمام همهٔ جهشها عملی نیست. بنابراین، هر بار که یک برنامهٔ بذر p جهش مییابد، باید وزن اهرمهای تریاژ و جهش بهروزرسانی شود. برای تحقق این هدف، ابتدا پاداش برای تریاژ و جهش وقتی که بذر p از طریق تریاژ به مجموعهٔ بذرها اضافه میشود، به صورت زیر محاسبه میکنیم:
gtrip (0) = cminp . T/C – ttrip
سپس، هر بار که p جهش مییابد، پوشش جدید مشاهدهشده و هزینههای زمانی مربوط به آن را پیگیری میکنیم تا پاداش اهرمها بهصورت پویا بهروزرسانی شود.
بهروزرسانی پاداشها. برای جهش kام، پاداش کل (k) gtrip و (k) gmutp را با استفاده از معادلههای ۹ و ۸ برآورد میکنیم. سپس، اختلاف نسبت به پاداش کل برآوردشده در مرحلهٔ جهش (k−1)ام محاسبه میشود:
Δ(gtrip,k) = gtrip (k) – gtrip (k-1) و Δ(gmutp,k) = gmutp (k) – gmutp (k-1) .

سپس، مقادیر Δ(gtrip,k) و Δ(gmutp,k) به عنوان پاداش وظیفههای تریاژ و جهش در جهش kام استفاده میشوند؛ این مقادیر بعداً در الگوریتم انتخاب وظیفه (بخش 3.2) مورد استفاده قرار میگیرند.
نرمالسازی (Normalization). مقادیر پاداش g برای وظیفههای تولید، جهش و تریاژ میتوانند در بازهٔ (∞,∞-) قرار گیرند. با این حال، الگوریتمهای تکعاملی مانند Exp3، Exp3.1 و Exp3-IX نیاز دارند که پاداشها به بازهٔ [0,1] نرمال شوند.
برای الگوریتمهای با محدودیت بودجه، مانند Exp3-M.B. [36]، هر دو مقدار سود (Gain) و هزینه (Cost) به بازهٔ [0,1] نرمال میشوند و اختلاف آنها (Gain−Cost) ∈ [1,1-] خواهد بود.
تابع لجستیک به شکل (1 + e-y)/1 معمولاً برای نرمالسازی از بازهٔ (∞,∞-) به (0,1) استفاده میشود [32]. ما این تابع را از (0,1) به (1,1-) بصورت (1 + e-y) / (1 – e-y) بازمقیاس میکنیم که اطمینان میدهد پاداش صفر همیشه به ۰ نرمال میشود.
برای در نظر گرفتن تغییرات و پراکندگی مقادیر پاداشها، از z‘ = g/σg استفاده میکنیم؛ این نسخهٔ تغییر داده شدهٔ Z-score استاندارد است که به جای y در تابع لجستیک قرار میگیرد. همچنین، Z-score استاندارد با میانگین z = (g – g–) /σg را به Z-score با میانگین صفر تغییر میدهیم تا اطمینان حاصل شود که پاداش مثبت g همیشه به پاداش نرمال مثبتx تبدیل میشود. در نهایت، معادلهٔ نرمالسازی نهایی به شکل زیر خواهد بود:
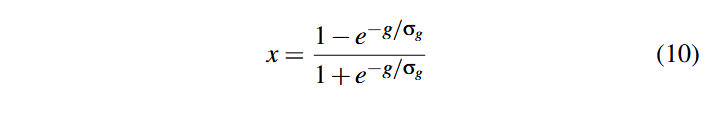
۳.۲ انتخاب وظیفه (Task Selection)
اکنون که توابع پاداش خود را تعریف کردهایم، از الگوریتمهای Exp3.1 [7] و Exp3-IX [23] استفاده میکنیم تا مشخص کنیم در هر مرحله از فازینگ، کدام وظیفه از Syzkaller باید اجرا شود. ما از رشد وزن نمایی و اکتشاف ضمنی (implicit exploration) الگوریتم Exp3-IX بهره میبریم تا تضمین شود اهرمهای خوب به طور کافی بهرهبرداری (exploitation) شوند و الگوریتم به سرعت به تغییرات پاداشها بین اهرمهای مختلف واکنش نشان دهد.
همچنین این رویکرد با Exp3.1 ترکیب میشود تا بهصورت دورهای وزن هر اهرم ریست شود و ضریب اکتشاف و رشد (exploration and growth factors) تنظیم گردد، که پایداری الگوریتم را در طولانیمدت (حتی دورهٔ نامتناهی) تضمین میکند. در نهایت، این مکانیزم با مدل نوین ارزیابی پاداش ما (بخش ۳.۱) ترکیب میشود تا وابستگی میان وظایف جهش و تریاژ بهدرستی لحاظ شود. الگوریتم انتخاب وظیفه SYZVEGAS به صورت الگوریتم 1 نمایش داده شده است.
مشابه Exp3.1، این الگوریتم خط زمانی فازینگ (fuzzing timeline) را به دورهها (epochs) تقسیم میکند که توسط الگوریتم 1 به طور خودکار تعیین میشوند و با شاخص r مشخص میشوند. این دورهها مشخص میکنند چه زمانی وزن اهرمها ریست شود، چیزی که در Exp3.1 الزامی است. الگوریتم ما برای هر دوره، یک پاداش هدف Gthreshold^ برآورد میکند و ضریبهای اکتشاف و رشد (γ و η) را مطابق با Exp3.1 تنظیم میکند.
در طول هر دوره، الگوریتم انتخاب اهرم و به روزرسانی پاداشها را مشابه Exp3-IX انجام میدهد. پس از هر بهروزرسانی، الگوریتم بررسی میکند که آیا سود برآورد شده Gi^ از آستانه Gi^s فراتر رفته است یا خیر. اگر بله، انتقال به دورهٔ بعدی انجام میشود و مقادیر سودهای مشاهده شده Gi^ به صفر ریست میشوند و Gthreshold^ برای دورهٔ بعدی، ۴ برابر افزایش مییابد.
یکی از تفاوتهای اصلی بین یک راه حل سنتی MAB و SYZVEGAS، تقسیم پاداش بین وظیفههای تریاژ و جهش است. الگوریتمهای Exp3 فرض میکنند که اهرمها مستقل هستند و بنابراین، هنگامی که یک اهرم انتخاب میشود، تنها وزن همان اهرم تحت تأثیر قرار میگیرد. اما در SYZVEGAS (بخش ۳.۱)، هنگامی که اهرمی جهش (Mutation) انتخاب میشود، وزن هر دو اهرمی جهش و تریاژ بهروزرسانی میشوند.
دومین تفاوت با الگوریتمهای شبیه Exp3 این است که در SYZVEGAS، پاداشهای نرمال شده xi∈(−1,1) هستند، در حالی که در الگوریتمهای مشابه Exp3 معمولاً پاداشها به بازهٔ [0,1] نرمال میشوند.
همانطور که در بخش ۳.۱ بحث شد، این انتخاب طراحی بر اساس دو دلیل شهودی صورت گرفته است:
- نمیخواهیم اهرمها (وظیفهها) که هیچ پوششی تولید نمیکنند، وزن یا سودی دریافت کنند،
- وقتی دو وظیفه هیچ پوششی تولید نمیکنند، میخواهیم وظیفههایی که هزینهٔ بیشتری مصرف میکنند، شدیدتر جریمه شوند، که نرمالسازی [0,1] قادر به اعمال آن نیست.
۳.۳ انتخاب بذر (Seed Selection)
علاوه بر انتخاب وظیفه مناسب، لازم است که هر وظیفه جهش با یک بذر مناسب مرتبط شود. برای این منظور، دوباره از یک الگوریتم مشابه Exp3-IX استفاده میکنیم که در الگوریتم 2 نمایش داده شده است.

اگرچه الگوریتم انتخاب بذر شباهتهایی با الگوریتم انتخاب وظیفه دارد (شامل مدل ارزیابی پاداش، نرمالسازی پاداش و فرایند بهروزرسانی وزنها) اما تفاوتهای کلیدی نیز وجود دارد. مدل ارزیابی پاداش تنها وظیفههای جهش را در نظر میگیرد.
هنگامی که یک وظیفه جهش کامل میشود، از مدل سود/زیان بخش ۳.۱ برای محاسبهٔ پاداش جهش بذر جاری استفاده میکنیم. از آنجا که تمرکز ما اکنون تنها بر وظیفههای جهش است، دیگر پاداشها با تریاژ تقسیم نمیشوند (برخلاف انتخاب وظیفه). در عوض، پاداش همانند معادلههای ۱ و ۲ محاسبه میشود و دیگر پاداشهای تولید و تریاژ در نرمالسازی لحاظ نمیشوند.
فرض کنید Cmut و Tmut به ترتیب کل پوشش به دست آمده و کل زمان سپری شده برای همهٔ وظیفههای جهش باشند. ci و ti پوشش و زمان به دست آمده برای جهش یک بذرi باشند. در این صورت، سود مشاهده شده از جهش این بذر میتواند به شکل زیر محاسبه شود:
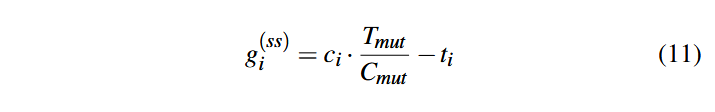
فرض کنید σmut(ss) انحراف معیار سودهای مشاهده شده در تمام وظیفههای جهش باشد. در این صورت، پاداش نهایی جهش بذر i به فرمول زیر محاسبه میشود:
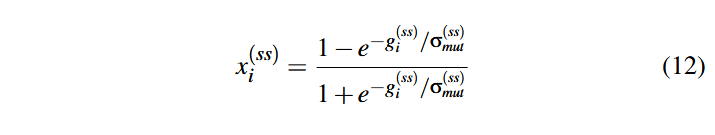
تعداد فزاینده اهرمها. Syzkaller با هیچ بذری (seed) در مجموعهٔ بذرها (Corpus) شروع میکند و این مجموعه تنها با ایجاد و اجرای برنامههای جدید پر میشود. بنابراین، اگر مسئلهٔ انتخاب بذر را بهصورت یک مسئلهٔ MAB در نظر بگیریم، ممکن است تعداد اهرمها (Arms) همیشه در حال افزایش باشد. این وضعیت در مسائل کلاسیک MAB معمولی نیست، اما میتوان با تعدیلات مناسب آن را با مسئلهٔ خود تطبیق داد. وقتی بذر جدید i به مجموعهٔ بذرها اضافه میشود، با یک پاداش برآورد شدهٔ خنثی شروع میکند Gi(ss) = 0. در نتیجه، وزن اولیهٔ این بذر مطابق باالگوریتم 2 برابر است با wi(ss) = 1.
احتمال انتخاب این بذر در ابتدا بستگی به پاداشهای تجمعی سایر بذرهای موجود در Corpus دارد، مثلاً Gj(ss) . پس از آنکه بذر i جهش داده شد، احتمال انتخاب آن با توجه به این که سود حاصل از پوشش به دست آمده از هزینهٔ زمانی بیشتر است یا خیر تعیین میشود. همچنین، با افزایش تعداد بذرها، ضریبهای اکتشاف و رشد الگوریتم کاهش مییابند تا از تسلط یک بذر خاص بر احتمال انتخاب جلوگیری شود (چون با افزایش تعداد بذرها، احتمال انتخاب هر بذر کاهش مییابد).
عدم نیاز به Reset. از آنجا که فرایند جهش تصادفی است، هر چه یک بذر بیشتر جهش داده شود، احتمال اینکه جهشهای بعدی آن منجر به کشف پوشش جدید شود کمتر خواهد بود. بنابراین، هر اهرم در MAB انتخاب بذر دارای پاداش کاهش یابنده (diminishing reward) است. در نتیجه، استفاده از مکانیزم Reset مشابه Exp3.1 برای الگوریتم انتخاب بذر ضرورتی ندارد (زیرا بذرها به مرور “از دور خارج” میشوند). الگوریتم انتخاب بذر ما به سادگی از الگوریتم Exp3-IX پیروی میکند، با این تفاوت که اهرمهای جدید زمانی ایجاد میشوند که یک بذر جدید به Corpus اضافه شود.
۳.۴ پیادهسازی
پیادهسازی SYZVEGAS شامل مدلهای ارزیابی پاداش و گسترشهای مطرح شده از الگوریتم Exp3.1 بر روی Syzkaller است (بر اساس commit 1128418 در ۲۴/۰۵/۲۰۲۰ [14]). پیادهسازی ما حدود ۱۸۰۰ خط کد دارد. در ادامه، برخی از نکات ظریف که در پیادهسازی در نظر گرفتهایم را توضیح میدهیم.
محاسبه انحراف معیار (Standard Deviation Computation). در فرایند نرمالسازی، لازم است انحراف معیار تمام پاداشهای مشاهده شده قبلی همانند معادلههای ۱۰ و ۱۲ محاسبه شود. نگهداری تمام مقادیر پاداش عملی نیست، زیرا Syzkaller ممکن است میلیونها برنامه اجرا کند. همچنین این مقادیر باید با ماشین میزبان همگامسازی (sync) شوند و در صورت خرابی یا قطع اتصال VM/Device فازر بازگردانده شوند. خوشبختانه، تنها لازم است که سه مقدار زیر را نگه داریم:
- تعداد کل مشاهدات n
- مجموع مقادیر پاداش ∑g
- مجموع مربعات پاداشها ∑g2
سپس میتوان انحراف معیار را به صورت زیر محاسبه کرد:
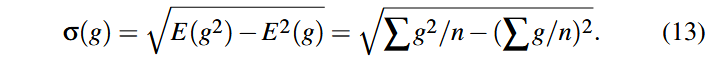
مدیریت مقادیر پرت (Outlier Handling). برنامهها در VM یا دستگاه فازر میتوانند زمان اجرای متفاوتی داشته باشند. در برخی موارد، یک برنامه ممکن است چندین ثانیه طول بکشد. اگرچه این موارد نادر هستند، اما حتی چند مورد بسیار افراطی میتواند برآورد زمان و انحراف معیار را بهشدت مختل کند و الگوریتمهای انتخاب وظیفه و انتخاب بذر ما را تحت تأثیر منفی قرار دهد. بنابراین، تشخیص این مقادیر پرت و جلوگیری از آسیب آنها به الگوریتمها ضروری است.
اندازهگیریها نشان میدهد که تریاژ پرهزینهترین وظیفه است و زمان اجرای آن میتواند بسیار متفاوت باشد. اگر از روش “ربع سوم + بازه بین ربعها” (3rd quartile + IQR) برای تشخیص مقادیر پرت استفاده کنیم، آستانه تقریباً ۰.۳۲ ثانیه خواهد بود. برای دادن کمی انعطاف بدون خدشه به صحت آزمایش، آستانه تشخیص پرت را یک ثانیه قرار دادیم. هر وظیفهای که بیش از یک ثانیه طول بکشد، به عنوان یک ثانیه در نظر گرفته میشود و ادامهٔ فرایند به حالت عادی انجام میشود. در عمل، کمتر از ۱٪ از تمام وظیفهها نیاز به تعدیل زمان دارند.
۴. ارزیابی
ما ارزیابیهای گستردهای از SYZVEGAS با پیکربندیهای مختلف انجام دادیم و به طور پیش فرض، آن را با Syzkaller به عنوان baseline مقایسه کردیم. مگر اینکه خلاف آن ذکر شود، هر پیکربندی ۱۰ بار اجرا میشود، یک VM فازر با ۲ هسته و ۲ گیگابایت حافظه استفاده میشود، سرور میزبان دارای پردازندههای Intel Xeon Gold 6248 با فرکانس 2.50GHz است و برای انتخاب بذر، θ = 0.1 برای تمام آزمایشها در نظر گرفته شد
آزمایشهای کلیدی انجام شده عبارتند از:
- آزمایش ۲۴ ساعته روی یک کرنل لینوکس از ابتدا، همراه با تحلیل جامع نتایج.
- آزمایش ۲۴ ساعته روی کرنل لینوکس با یک مجموعهٔ بذر اولیه، برای مطالعهٔ اثر آن بر رشد پوشش.
- آزمایش ۲۴ ساعته روی چند نسخهٔ کرنل لینوکس، برای بررسی اینکه SYZVEGAS چگونه به صورت خودکار با کرنلهای مختلف سازگار میشود.
- آزمایش ۷ روزه، برای بررسی اثرات بلند مدت و وقوع کرشها.
- آزمایشهای ۲۴ ساعته برای مقایسه SYZVEGAS با فازرهای پیشرفته (state-of-the-art) HFL [18] و EcoFuzz [34].
۴.۱ فازینگ کرنل لینوکس به مدت ۲۴ ساعت
ابتدا، یک آزمایش فازینگ ۲۴ ساعته روی کرنل لینوکس نسخه ۵.۶.۱۳ انجام دادیم تا ارزیابی سیستماتیک و عمیقی از SYZVEGAS داشته باشیم.
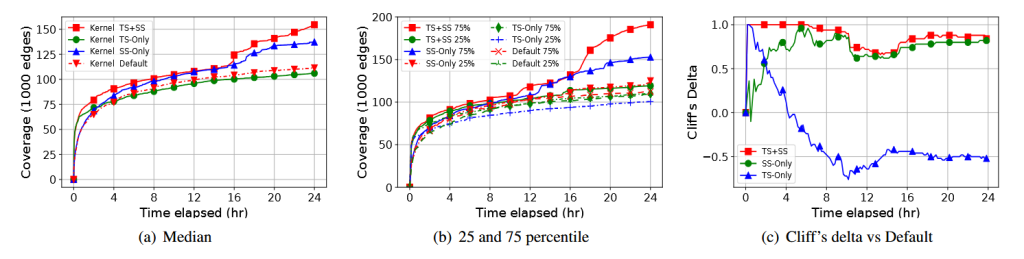
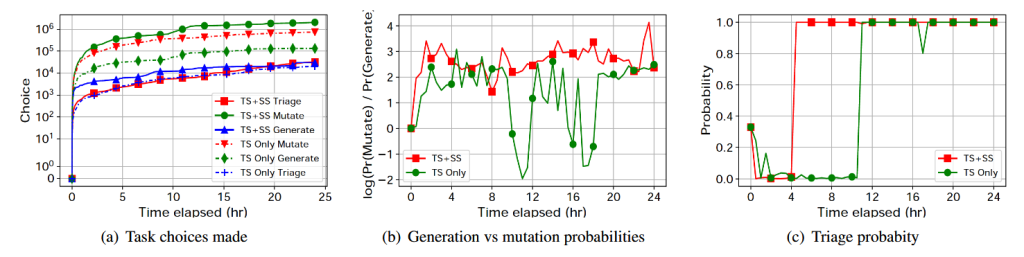
رشد پوشش (Coverage Growth). شکل ۳ (a) نشان دهندهٔ میانهٔ رشد پوشش پس از ۲۴ ساعت فازینگ کرنل است. شکل ۳ (b) چارکهای ۲۵ و ۷۵ درصد را نمایش میدهد. از این دو شکل، چند مشاهدهٔ جالب حاصل شد:
- انتخاب وظیفه با MAB در مراحل اولیه فازینگ بهترین عملکرد را دارد، اما این مزیت اولیه با پیشرفت فازینگ کاهش مییابد.
- انتخاب بذر با MAB در چند ساعت اول اثر چندانی ندارد، اما با طولانیتر شدن زمان اجرا، انتخاب بذر باعث افزایش رشد پوشش میشود و در میانه، در ۲۴ ساعت حدود ۲۵٬۸۳۰ یال (۲۳.۲٪) بهبود ایجاد میکند.
- ترکیب انتخاب وظیفه و بذر با MAB موجب بهبود قابل توجه رشد پوشش میشود، به طوری که میانهٔ پوشش در ۲۴ ساعت ≈ ۴۳٬۱۳۰ یال (۳۸.۷٪) افزایش مییابد. جالب است که انتخاب وظیفه به تنهایی در ۲۴ ساعت مزیتی ندارد، اما ترکیب آن با انتخاب بذر، پوشش اضافی ایجاد میکند.
- با استفاده از انتخاب بذر، پراکندگی پوشش بیشتر میشود. دلیل آن این است که SYZVEGAS بذرها را با وزن تصادفی انتخاب میکند، در حالی که درSyzkaller استاندارد، جهشهای smash تعیینکنندهٔ انتخاب بذر هستند (بخش ۲.۲).
از آنجا که شانس نقش مهمی در رشد پوشش فازینگ دارد، پژوهشگران پیشنهاد میکنند که روشهای آماری برای تعیین احتمال تفاوتهای مشاهدهشده در پوشش استفاده شود [19]. برای ارزیابی اینکه آیا مزیت پوشش SYZVEGAS در تمام اجراها ثابت است، ما دلتای کلیف (Cliff’s delta) [10] بین اجراهای با انتخاب وظیفه و/یا بذر با SYZVEGAS و Syzkaller پیشفرض را محاسبه کردیم.
دلتای کلیف در بازهٔ [−1,1] قرار دارد و نتیجهٔ مقایسهٔ جفتی بین دو اجرا را نشان میدهد (در اینجا بین تنظیمات ما و Syzkaller پیشفرض). دلتای کلیف بالاتر به این معناست که تنظیمات ما احتمال بیشتری دارد تا بهتر از Syzkaller پیشفرض عمل کند.
شکل ۳ (c) نشان میدهد که SYZVEGAS با SS-Only و TS+SS بهطور قابل اعتماد از Syzkaller پیشفرض بهتر عمل میکند و مشاهدات شکل ۳ (a) و ۳ (b) را با اعتماد بالا تأیید میکند.
یک مشاهدهٔ جالب دیگر این است که قدرت انتخاب بذر (Seed Selection) واقعاً از حدود ۱۲ تا ۱۴ ساعت فازینگ شروع به ظهور میکند. در ساعات اولیه، SYZVEGAS تنها مزیت کمی در پوشش نسبت به Syzkaller پیشفرض دارد. بررسی دقیقتر نشان میدهد که در ۱۲–۱۴ ساعت، اکثر بذرهای موجود قبلاً به شدت استفاده شدهاند و انتخاب بذر به آنها پاداش منفی اختصاص میدهد (یعنی اولویت بسیار پایین). در این شرایط، انتخاب بذر فوراً بذرهای جدید را ترجیح میدهد و اگر بذر جدید پوشش خوبی تولید کند، اولویت آن را تمدید میکند.
در مقابل، Syzkaller تحت تأثیر سیاست ۱۰۰ جهش برای هر بذر جدید قرار میگیرد. همانطور که در رابطه با شکل ۱ (b) بحث شد، این سیاست بار کاری عظیمی برای جهش بذرهای جدید ایجاد میکند، در حالی که این بذرهای جدید پتانسیل بیشتری نسبت به بذرهای قدیمی دارند. حتی بعد از اینکه بذرهای جدید ۱۰۰ جهش خود را دریافت کنند، آنها باید با بذرهای قدیمی فقط بر اساس پوشش اولیه رقابت کنند؛ یعنی پوششی که با جهشهای آنها به دست آمده، لحاظ نمیشود. بنابراین، SYZVEGAS بذرهای جدید را به شکل بهتری استفاده میکند و شانس “باز کردن” بلوکهای جدید کد کرنل را افزایش میدهد.
شکل ۴ (a) تعداد برنامههای اجراشده توسط انواع مختلف وظیفهها را نشان میدهد. همانطور که قابل پیشبینی است، تمام بهینهسازیهای ما باعث اجرای برنامههای بیشتر میشوند، زیرا یا به وظیفه تولید (Generation) اولویت بالاتری داده شده یا جهش اجباری smash حذف شده است. یک مشاهدهٔ جالب این است که انتخاب بذر مبتنی بر MAB، موجب مبشود SYZVEGAS در کل برنامههای بیشتری نسبت به Syzkaller پیشفرض اجرا کند.
دلیل اصلی این امر، ترجیح جهش بذرهایی با زمان اجرای کم است، یعنی SYZVEGAS میتواند جهشهای بیشتری انجام دهد. این دقیقاً بازتاب هدف طراحی SYZVEGAS برای بهینهسازی کارایی پوشش به ازای زمان (coverage-time efficiency) است.
شکل ۴ (b) پوشش به دست آمده را بر اساس انواع وظیفهها تفکیک میکند. بر اساس مشاهدات ما، انتخاب وظیفه مبتنی بر MAB بهطور قابل توجهی بار کاری را از جهش به تولید منتقل میکند و باعث میشود وظیفه تولید تا ۲۰ برابر پوشش بیشتری نسبت به حالت قبل تولید کند. البته این با یک فداکاری همراه است: پوشش تولیدشده توسط جهشها حدود ۵۰٪ کاهش مییابد. خوشبختانه، انتخاب بذر این کاهش را جبران میکند و قدرت جهشها را به سطح اولیه بازمیگرداند.
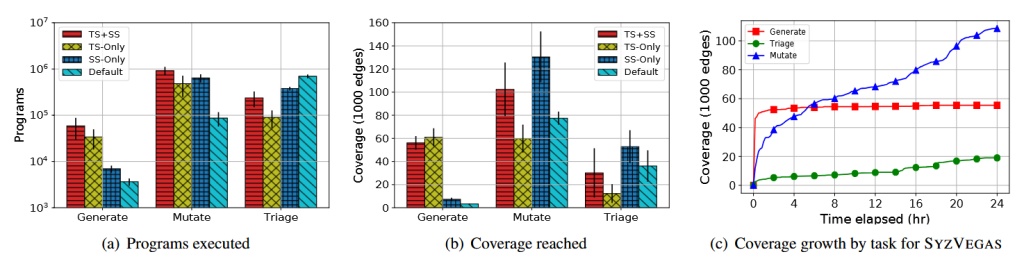
جالب است که مشاهده کردیم وقتی انتخاب وظیفه مبتنی بر MAB فعال است، وظیفه تولید (Generation) مقدار زیادی پوشش تولید میکند.
با این حال، وقتی به تعداد برنامههای اجراشده (شکل ۴ (a)) نگاه میکنیم، SYZVEGAS همچنان به جهش (Mutation) اولویت میدهد. اگر پوشش به دست آمده توسط وظیفههای مختلف را بر اساس زمان تفکیک کنیم (شکل ۴(c))، مشاهده میکنیم که پوشش تولید شده توسط تولید تقریباً تماماً در دو ساعت اول فازینگ ایجاد میشود، زمانی که فضای کد کرنل هنوز بهطور کامل کاوش نشده و یافتن پوشش جدید ساده است.
همانطور که بعداً نشان خواهیم داد، این به این دلیل است که انتخاب وظیفه در مراحل اولیه فازینگ، مقدار زیادی تولید (Generation) انجام میدهد.
انتخاب وظیفه MAB. در ادامه، نگاهی به عملکرد داخلی انتخاب وظیفه مبتنی بر MAB میاندازیم. به ویژه، میخواهیم بفهمیم که الگوریتم انتخاب وظیفه، چه احتمالی برای هر نوع وظیفه اختصاص میدهد. شکل ۵(a) انتخابهای انجام شده توسط الگوریتم انتخاب وظیفه را نشان میدهد. مشاهده میکنیم که در ابتدای فازینگ، الگوریتم انتخاب وظیفه به سرعت اهرمی تولید را انتخاب کرد (“pull”) بیش از ۱۰۰۰ بار و به این ترتیب اولویت تولید بهطور قابل توجهی بالاتر از Syzkaller پیشفرض شد. در مقابل، تریاژ در ابتدا کمتر اولویت داشت، اما با پیشرفت فازینگ، به آرامی به سطح تولید نزدیک میشود.
شکل ۵ (b) نشان میدهد که انتخاب وظیفه مبتنی بر MAB چگونه تولید و جهش را در طول زمان متعادل میکند، چه با انتخاب بذر MAB و چه بدون آن. در ابتدا، تولید و جهش با احتمال برابر مقداردهی اولیه میشوند. با کمک انتخاب بذر مرتبط (Seed Selection)، الگوریتم انتخاب وظیفه سریعاً تشخیص میدهد که جهش گزینهٔ بهتری است و به آن حدود ۵۰۰ برابر احتمال بیشتر اختصاص میدهد. بدون انتخاب بذر، الگوریتم بیشتر تولید را ترجیح میدهد و گاهی حتی احتمال اجرای تولید بیشتر از جهش میشود. این رفتار قابل پیشبینی است و ناشی از مشکلات الگوریتم انتخاب بذر پیشفرض است (بخش ۲.۲). بدون الگوریتم Seed Selection بهبود یافته، جهشها کمتر قادر به یافتن پوشش جدید هستند و بنابراین اولویت آنها کاهش مییابد.
شکل ۵ (c) تغییر احتمال انتخاب تریاژ در طول زمان را نشان میدهد. توجه داشته باشید که تریاژ همیشه در دسترس نیست (مثلاً زمانی که برنامهٔ جالب دیگری در صف کاری وجود ندارد). بنابراین، شکل تنها احتمالات آن زمانی که در دسترس است را نشان میدهد. در ابتدا، الگوریتم انتخاب وظیفه چند فرصت به تریاژ میدهد و سپس اولویت آن را بسیار پایین میآورد و بیشتر تولید و جهش را ترجیح میدهد. در این مرحله، تولید و بذرهای اولیه (که از چند وظیفه تریاژ جمعآوری شدهاند) هنوز قدرتمند هستند و باعث میشوند الگوریتم انتخاب وظیفه احتمال بالاتری به تولید و جهش بدهد. اما با کاهش قدرت بذرهای اولیه و کاهش اثرگذاری تولید، هم تولید و هم جهش پاداش منفی کسب میکنند (یعنی پوشش جدید ایجاد نمیکنند اما هزینهٔ زمانی مصرف میشود). در این شرایط، تریاژ به طور طبیعی اولویت پیدا میکند.
نقش تریاژ در تولید بذرهای جدید و حفظ تنوع مجموعه بذرها برای کشف پوشش جدید حیاتی است. این اثر بهویژه زمانی برجسته است که انتخاب بذر مبتنی بر MAB فعال باشد، زیرا جهشها مؤثرتر شده و بذرهای اولیه سریعتر خالی میشوند. در نتیجه، تریاژ زودتر فراخوانی میشود.
به کمک ویژگی رشد وزن نمایی (exponential weight growth)، SYZVEGAS به سرعت سیاست خود را تنظیم میکند و تریاژ را در زمان مناسب، در اولویت مطلق قرار میدهد، مشابه رفتار Syzkaller پیشفرض. توجه داشته باشید که احتمال نزدیک به ۱۰۰٪ برای تریاژ به این معنی نیست که SYZVEGAS تنها تریاژ انجام میدهد. وظیفههای تریاژ توسط تولید و جهش ایجاد میشوند و همیشه در دسترس نیستند. زمانی که هیچ وظیفه تریاژ برای اجرا وجود نداشته باشد، SYZVEGAS به اجرای تولید یا جهش ادامه میدهد.
بهطور شگفتانگیز، طبق الگوریتم انتخاب وظیفه، قدرت تولید و بذرهای اولیه میتواند تا ۴ تا ۱۰ ساعت دوام داشته باشد و Syzkaller پیشفرض این فرصت را به خوبی بهرهبرداری نمیکند. با تکامل Syzkaller و بهبود تمپلیتها و استراتژیهای جهش، قدرت تولید و جهش نیز ممکن است تغییر کند، که باعث میشود تنظیم خودکار انتخاب وظیفه بهترین گزینه بلندمدت باشد، به جای اینکه صرفاً یک آستانه دستی مشخص شود.
بهطور کلی، اثر اصلی انتخاب وظیفه مبتنی بر MAB این است که در مراحل اولیه فازینگ، تعداد بیشتری تولید انجام میشود و تریاژ به تعویق میافتد. پس از چند ساعت، انتخاب وظیفه مبتنی بر MAB نهایتاً به همان سیاست Syzkaller پیشفرض همگرا میشود؛ تریاژ اولویت مطلق مییابد و جهش نسبت به تولید بسیار ترجیح داده میشود. این رفتار زمانی که با انتخاب بذر ترکیب میشود، برجستهتر است، زیرا جهشها پاداش بیشتری دارند.
اکنون بررسی میکنیم که چرا ترکیب انتخاب وظیفه و انتخاب بذر مبتنی بر MAB، حتی زمانی که تنها انتخاب بذر مبتنی بر MAB اثرگذاری خود را از دست میدهد و به سیاست مشابه Syzkaller پیشفرض نزدیک میشود، عملکرد بسیار بهتری دارد. همانطور که قبلاً بحث شد، اثر اصلی انتخاب وظیفه این است که در مراحل اولیه فازینگ، تعداد بیشتری تولید و تعداد کمتری تریاژ انجام میشود که به شدت بر بذرهای اولیه اضافهشده به مجموعه تاثیر میگذارد. پژوهشگران مزایای انتخاب بذرهای اولیه خوب در فازینگ کرنل را نشان دادهاند. به دلایل مشابه، رفتار مراحل اولیه SYZVEGAS که مجموعه را با بذرهای خوب پر میکند، مزایای بلندمدتی دارد که در بخش ۴.۲ بیشتر بررسی خواهیم کرد.
جهش، اصلیترین عامل یافتن پوشش جدید، نیازمند بذرها برای عملکرد است. بنابراین قدرت بذرها، یعنی میزان پوششی که یک بذر از طریق جهش تولید میکند، تأثیر زیادی بر کارایی فازینگ دارد. شکل ۶ (a) تعداد بذرهای تولیدشده توسط فازر در طول ۲۴ ساعت را نشان میدهد. مشاهده میکنیم که با انتخاب وظیفه مبتنی بر MAB، Syzkaller بذرهای بسیار کمتری تولید میکند. شکل ۶ (b) توزیع پوشش جدید حاصل از جهش این بذرها، یا همان قدرت بذرها، را نشان میدهد. همانطور که انتظار میرود، انتخاب بذر مبتنی بر MAB قدرت بذرها را افزایش میدهد، زیرا بذرهای خوب برای جهش ترجیح داده میشوند. جالب است که افزودن انتخاب وظیفه مبتنی بر MAB نیز قدرت بذرها را افزایش میدهد، با وجود اینکه مستقیماً بر انتخاب بذر اثر نمیگذارد. بنابراین، مزایای پوشش ناشی از انتخاب وظیفه مبتنی بر MAB باید ناشی از بهبود کیفیت بذرها باشد؛ این همان جایی است که تولیدهای اولیه فراخوانی شده توسط انتخاب وظیفه MAB کمک میکنند، با ایجاد برخی بذرهای بسیار قدرتمند.
شکل ۶ (c) توزیع قدرت بذرها (میزان پوشش جدیدی که هر بذر تولید میکند) را بر اساس منبع بذرها نشان میدهد. مشاهده میکنیم که انتخاب وظیفه قدرت بذرهای ایجادشده توسط تولید را بهبود میبخشد. این فرضیه و انگیزهٔ ما را تأیید میکند: داشتن تعداد بیشتری تولید در مراحل اولیه به فرایند فازینگ Syzkaller کمک میکند.
در نهایت، سربارهای الگوریتمهای انتخاب وظیفه و انتخاب بذر مبتنی بر MAB را بررسی میکنیم. سربارها از دو منبع ناشی میشوند: (۱) محاسبه و بهروزرسانی وزنها و احتمالات وظیفهها و بذرها، و (۲) همگامسازی وضعیت MAB بین VM فازر و میزبان مدیریت. مورد دوم به میزان خرابی فازر وابسته است، زیرا هنگام خرابی، نیاز است تمام اطلاعات مجموعه بذرها دوباره از میزبان بازیابی شود. در آزمایش ۲۴ ساعته، بهروزرسانی حدود ۹ دقیقه طول کشید و همگامسازی حدود ۲۲ دقیقه. در مجموع، سربار SYZVEGAS کمتر از ۲.۱٪ بود.
در مورد حافظه، SYZVEGAS باید اطلاعات اضافی مانند وزن اهرمها و مجموع پاداش تا کنون را ذخیره کند. این اطلاعات باید توسط هر VM فازر و میزبان مدیریت نگهداری شود تا در صورت خرابی قابل بازیابی باشد. برای انتخاب وظیفه، ۲۵۰ بایت برای ذخیره اطلاعات لازم استفاده میکنیم. برای انتخاب بذر، ۱۰۴ بایت حافظه اضافی برای هر بذر مصرف میشود. با تقریباً ۵٬۰۰۰ بذر تولیدشده توسط SYZVEGAS در ۲۴ ساعت، حدود ۵۲۰ کیلوبایت سربار حافظه برای هر VM/میزبان ایجاد میشود.
۴.۲ فازینگ با تنظیمات مختلف
فازینگ با مجموعه بذر اولیه. فازینگ کرنل اغلب با یک مجموعه بذر اولیه انجام میشود. این کار باعث میشود تعداد برنامههایی که Syzkaller باید در ابتدا تولید کند کاهش یابد و نرخ رشد پوشش افزایش پیدا کند.
برای ارزیابی SYZVEGAS در چنین شرایطی، دو مجموعه بذر ایجاد کردیم:
- مجموعهٔ اول با اجرای Syzkaller پیشفرض از صفر به مدت ۲۴ ساعت ساخته شد و شامل ۷٬۴۷۸ بذر با ۱۷٬۱۴۹ فراخوانیهای سیستمی (syscalls) است.
- مجموعهٔ دوم از Moonshine [24] به دست آمد که ردیابی فراخوانیهای سیستمی را از Linux Testing Project (LTP) [12]، kselftest [1] و Open Posix Tests [2] تحلیل میکند. بهطور مشخص، ردیابیها مستقیماً از نویسندگان دریافت شد تا مجموعه Moonshine شامل ۵۶۱ برنامه بذر با مجموع ۸٬۱۲۷ سیستم کال تولید شود.
SYZVEGAS و Syzkaller را با و بدون هر مجموعه (۱۰ نمونه برای هر حالت) به مدت ۲۴ ساعت اجرا کردیم که نتایج آن در شکل ۷ (a) نشان داده شده است.
مشاهده میکنیم که مجموعه بذر اولیه برای Syzkaller پیشفرض مزایای محدودی دارد. با مجموعه بذر ۲۴ ساعته، پوشش در ابتدا افزایش شدیدی دارد، زمانی که Syzkaller بذرها را وارد و تریاژ میکند، اما بعدها به دلیل استفاده ناکارآمد از این بذرها مسطح میشود. جالب است که Moonshine تقریباً هیچ افزایش پوششی ایجاد نمیکند.
وارد کردن مستقیم مجموعه بذر ۲۴ ساعته، بیش از ۱۰۹٬۰۰۰ شاخه پوشش ایجاد میکند، در حالی که مجموعه Moonshine تنها مسئول مستقیم ۳۳٬۷۰۰ شاخه پوشش است. همانطور که در بخشهای ۲.۱ و ۴.۱ بحث شد، Syzkaller به دلیل کاوش عمقی (Depth-First) تعداد کمی بذر به عنوان ریشهها، بسیاری از بذرها را جهش نمیدهد. در نتیجه، اکثر بذرهای واردشده (بذرهای جلویی) هیچ فرصتی برای کاوش نخواهند داشت.
علاوه بر این، استراتژی فعلی انتخاب بذر Syzkaller فقط به بذرهایی با پوشش اولیه بالاتر اولویت میدهد (بدون جهش). بسیاری از بذرهای وارد شده حتی وقتی صفهای کاری خالی میشوند، فرصت جهش پیدا نمیکنند، زیرا بذرهای دیگر با پوشش اولیه بسیار بالا، اولویت بیشتری دارند. در نتیجه، بذرهای موجود در مجموعههای اولیه به شدت کمتر استفاده میشوند. در آزمایشهای ما با هر دو مجموعه، بذرهای اولیه بهطور متوسط کمتر از ۲ جهش دریافت کردند.
تنها مزیت داشتن مجموعه بذر اولیه برای Syzkaller، پوششی است که از اجرای بذرها حاصل میشود، نه از جهش آنها؛ به همین دلیل مجموعه ۲۴ ساعته (با پوشش خام بیشتر) نسبت به مجموعه Moonshine بهتر عمل میکند. توجه داریم که هنگام توسعه و آزمایش Moonshine،Syzkaller تفاوتی بین بذرها قائل نمیشد، یعنی همه بذرها احتمال یکسانی برای جهش داشتند. این یک تفاوت مهم است که اجازه میدهد بذرهای Moonshine مزایای بیشتری داشته باشند.
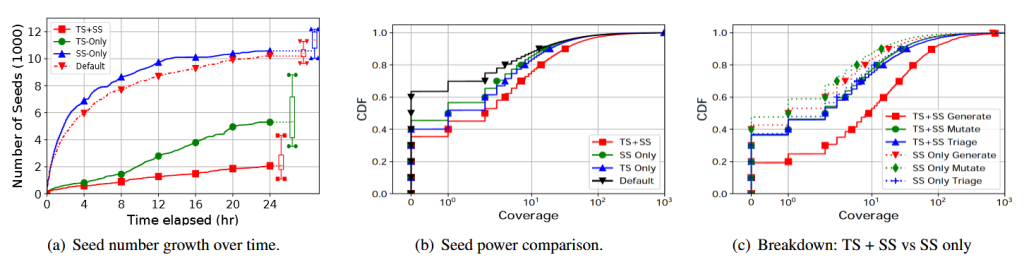
در مقابل، SYZVEGAS از هر دو مجموعه بذر اولیه بهتر استفاده میکند. نسبت به Syzkaller پیشفرض با همان مجموعه، SYZVEGAS با مجموعه Moonshine به طور میانگین ۵۲٬۴۱۶ شاخه (۴۵.۸٪) پوشش بیشتر و با مجموعه ۲۴ ساعته ۴۵٬۷۵۲ شاخه (۳۵.۱٪) پوشش بیشتر به دست میآورد. نسبت به SYZVEGAS استاندارد، مجموعه Moonshine و مجموعه ۲۴ ساعته به ترتیب ۱۲٬۲۳۰ (۷.۹٪) و ۲۱٬۵۶۴ (۱۴.۰٪) پوشش بیشتر ایجاد میکنند.
اگرچه SYZVEGAS هنوز با مشکل واردسازی آهسته (slow-import) مشابه Syzkaller مواجه است، اما استراتژی انتخاب بذر آن هوشمندتر است و از مجموعه بذر اولیه بهتر استفاده میکند (Moonshine: ~۱۲۰ جهش برای هر بذر؛ ۲۴ ساعته: ~۴۰ جهش برای هر بذر). استفادهٔ بهینه از بذرهای Moonshine همچنین آن را از نظر هزینه بهینهتر میکند، زیرا مجموعهای بسیار کوچکتر است اما همچنان افزایش پوشش قابل توجهی ارائه میدهد. جالب است که تغییرات مشاهده شده در SYZVEGAS با مجموعه ۲۴ ساعته بسیار کمتر است. دلیل آن احتمالاً این است که این مجموعه بیشتر اشباع شده است و گزینههای انتخاب بذر خوب محدودتر هستند.
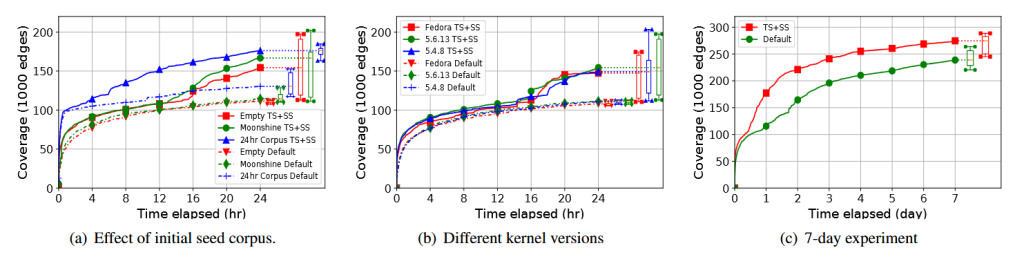
فازینگ نسخههای مختلف کرنل. برای بررسی قابلیت تعمیم SYZVEGAS، آن را روی نسخههای مختلف کرنل اجرا کردیم. علاوه بر کرنل اصلی ذکرشده در بخش ۴.۱، آزمایشهای مشابه روی:
- نسخه ۵.۴.۸ کرنل لینوکس
- نسخه ۵.۸.۰-rc1 کرنل Fedora
تمام آزمایشهای فازینگ روی همان سرور بخش ۴.۱ انجام شدند. شکل ۷(b) مقایسه رشد میانگین پوشش بین SYZVEGAS و Syzkaller پیشفرض روی این کرنلها را نشان میدهد. مشاهده میکنیم که SYZVEGAS در تمام کرنلهای آزمایش شده اثرگذار است. این امر انتظار میرود، زیرا مدل SYZVEGAS MAB متخاصم نیازی به آموزش آفلاین ندارد و کاملاً بهصورت آنلاین بر اساس پوشش مشاهدهشده و هزینه زمانی تنظیم میشود.
فازینگ کرنل لینوکس به مدت ۷ روز. برای بررسی عملکرد بلند مدت SYZVEGAS، یک آزمایش فازینگ ۷ روزه روی کرنل Linux 5.6.13 انجام دادیم. شکل ۷(c) رشد میانگین پوشش را نشان میدهد، با ۱۰ اجرای هر تنظیم (مانند قبل). نسبت به Syzkaller، SYZVEGAS ۳۵٬۷۳۶ شاخه (۱۵.۰٪) پوشش بیشتر در حالت میانگین ایجاد میکند. مشاهده میکنیم که SYZVEGAS بیشترین اثرگذاری را در ۲۴ تا ۴۸ ساعت اول فازینگ دارد و در طولانیمدت نیز هنوز در بهبود رشد پوشش مؤثر است.
جدول ۲: کرشهای کشفشده در فازینگ هسته لینوکس به مدت ۷ روز
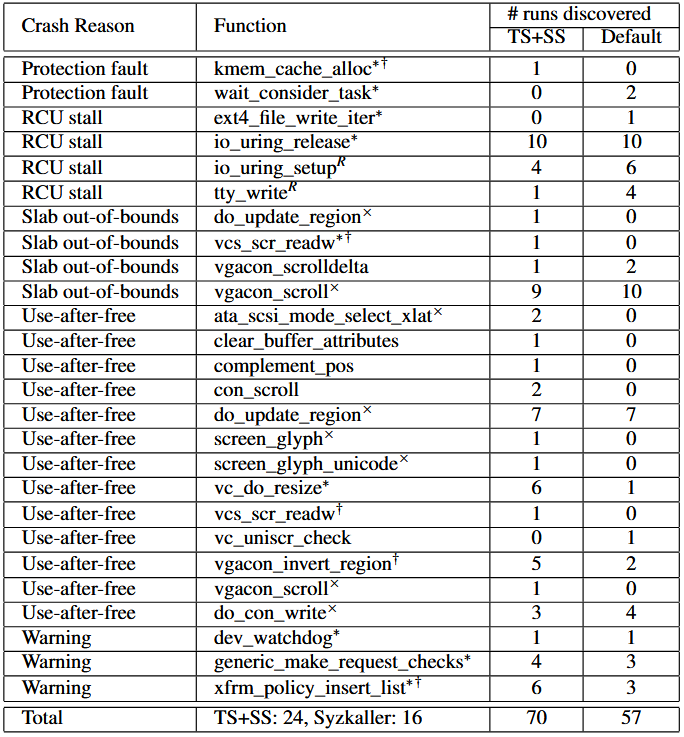
جدول ۲ کرشهای منحصربهفرد یافته شده را نشان میدهد. SYZVEGAS توانست ۵۷ کرش (۲۴ مورد منحصربهفرد) و Syzkaller پیشفرض ۷۰ کرش (۱۶ مورد منحصربهفرد) پیدا کند. از این کرشها، ۷ مورد مربوط به باگهای جدید میباشند؛ SYZVEGAS ۶ مورد از این ۷ کرش را شناسایی کرد، در حالی که Syzkaller پیشفرض ۴ مورد را تشخیص داد.
متأسفانه، بازتولید خودکار تنها میتواند ۲ مورد از این باگها را بازتولید کند؛ این مسئله یک مشکل شناختهشده در فازینگ واقعی کرنل است که ناشی از حالتپذیری، غیرقطعی بودن و همزمانی است. برای مثال، تابع clear_buffer_attributes در مسیر drivers/tty/vt به یک آرایه سراسری vc_cons دسترسی دارد. این آرایه میتواند توسط بسیاری از توابع دیگر تغییر کند و بنابراین تولید دقیق همان حالت که باعث دسترسی user-after-free میشود، بسیار دشوار است.
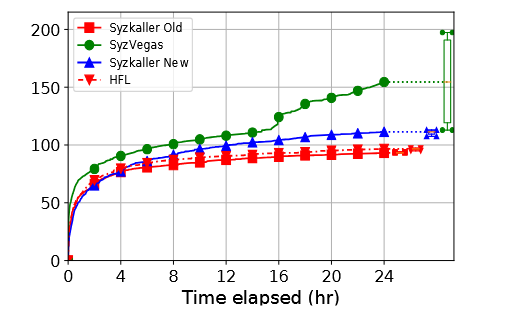
مقایسه با HFL. در ادامه، SYZVEGAS را با یک بهینهسازی پیشرفته مبتنی بر Syzkaller، یعنی HFL [18] مقایسه میکنیم. HFL را انتخاب کردیم زیرا مشابه SYZVEGAS، به طور کلی برای فازینگ کرنل طراحی شده است و مختص فازینگ درایور خاصی (مثلاً [29, 30]) یا یافتن نوع خاصی از باگها (مثلاً [16]) نیست.
HFL را از مخزن آنها [3] با همان پیکربندی سایر آزمایشها اجرا کردیم و نتایج در شکل ۴.۲ نشان داده شده است. توجه داریم که HFL بر پایه نسخه قدیمیتر Syzkaller از اواسط ۲۰۱۸ ساخته شده است، در حالی که SyzVegas و نسخه Syzkaller مورد استفاده در آزمایشهای ما مربوط به می ۲۰۲۰ هستند. Syzkaller بین این دو نسخه تحولات قابل توجهی داشته است، از جمله:
- سیستمکالهای جدید پشتیبانی شده (فضای پوشش بزرگتر)
- الگوریتم انتخاب بذر بهتر (نرخ رشد پوشش بهتر)
بنابراین، HFL تنها نسبت به نسخه قدیمیتر Syzkaller برتری دارد و نسبت به نسخه فعلی Syzkaller موجود در آزمایشها برتری ندارد. بازپایهسازی HFL روی نسخه جدید Syzkaller نیازمند تلاش مهندسی بسیار زیاد است، زیرا شامل تغییرات غیرجزئی در Syzkaller (بیش از ۸۰۰۰ خط کد) میشود.
نکته مهم این است که SYZVEGAS رشد پوشش را نسبت به Syzkaller فعلی با حاشیهای بزرگتر بهبود میدهد، حتی بیشتر از بهبودی که HFL روی نسخه قدیمی Syzkaller ایجاد کرده بود.
۴.۳ کاربرد انتخاب بذر SYZVEGAS در فضای کاربر
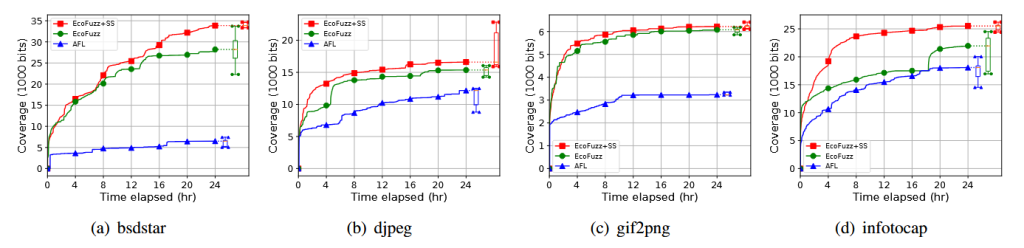
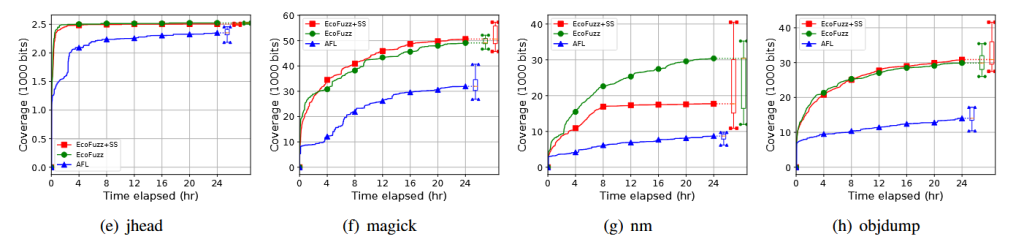
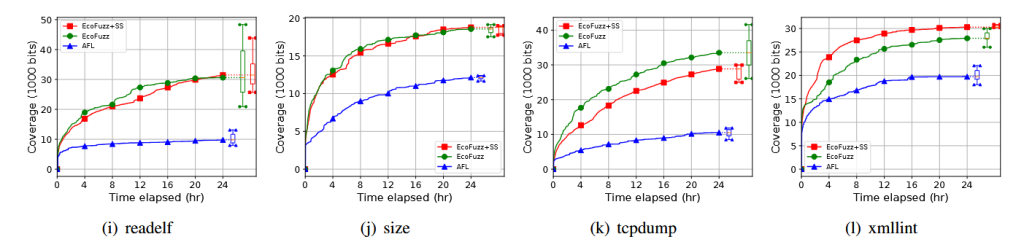
فازرهای فضای کاربر (User-space fuzzers) مانندAFL نیز از الگوریتمهای انتخاب بذر استفاده میکنند. کارهای اخیر مانند EcoFuzz [34] الگوریتم انتخاب بذر AFL را به عنوان یک مسئله MAB متخاصم مدل سازی میکنند، اما زمان مورد نیاز هر بذر برای کشف پوشش جدید مربوطه را مانند SYZVEGAS در نظر نمیگیرند.
ما الگوریتم انتخاب بذر EcoFuzz را با الگوریتم SYZVEGAS جایگزین کردیم و همان مجموعه بنچمارکها را به مدت ۲۴ ساعت، ۱۰ بار برای هر مورد اجرا کردیم. شکل ۹ پوشش به دستآمده را نشان میدهد (بر حسب تعداد بیتهای ست شده). نتایج نشان میدهد کهSYZVEGAS نسبت به EcoFuzz استاندارد عملکرد مناسبی دارد. به لطف در نظر گرفتن زمان اجرا در مدل پاداش SYZVEGAS، این الگوریتم در ۴ بنچمارک از ۱۲ بنچمارک بهتر از EcoFuzz عمل میکند و در ۶ بنچمارک دیگر عملکرد مشابهی دارد.
با این حال، مشاهده شد که زمانهای اجرای ورودیهای تولیدشده توسط AFL اغلب مشابه هم هستند، برخلاف حالت کرنل. بنابراین، مزیت در نظر گرفتن زمان در مدل پاداش تنها سود متوسطی در رشد پوشش فازینگ دارد؛ در فقط ۲ مورد از ۱۲ برنامه مورد بررسی، SYZVEGAS نسبت به EcoFuzz در پوشش عملکرد پایینتری نشان داد.
۵. بحث و کارهای آینده
انتخاب الگوریتمهای MAB متخاصم. ما مسئله MAB متخاصم را به ویژه مناسب SYZVEGAS میدانیم و نشان دادیم که یک الگوریتم ساده و بدون حالت (stateless) میتواند مزایای قابل توجهی ایجاد کند. سایر تکنیکهای پیشرفته یادگیری تقویتی/یادگیری ماشینی (مانند Q-learning [9]، PPO [27]) اصولاً برای انتخاب وظیفه و بذر قابل اعمال هستند. با این حال، ما معتقدیم که مدل MAB متخاصم بهترین تطابق را با نیازهای ما دارد، به دلایل زیر:
الگوریتمهای MAB تهاجمی که ما انتخاب کردیم، «غیرهمبسته» (non-associative) یا “غیرمتنی” (non-contextual) [31] هستند، یعنی نیازی به تعریف حالت (state) ندارند، که تعریف آن در زمینه فازینگ کرنل سخت و پیچیده است. بنابراین، این الگوریتمها بهطور آماده و بدون نیاز به تغییر روی پیکربندیهای مختلف فازینگ (مثلاً نسخهها/نوعهای مختلف کرنل، مجموعه بذر اولیه و غیره) کار میکنند. در مقابل، بسیاری از الگوریتمهای RL جایگزین مانند Q-learning به تعریف حالت نیاز دارند.
- مسئله MAB تهاجمی امکان تغییر پاداشها برای هر انتخاب را در نظر میگیرد، برخلاف مسائل استاندارد MAB و راهحلهای آنها (مثلاً UCB). الگوریتم Exp3 که پایه SYZVEGAS است، نشان داده که میتواند سریعاً این تغییرات را شناسایی و خود را با آنها تطبیق دهد. این ویژگی آن را برای فازینگ کرنل مناسب میسازد، جایی که قدرت بذرها کاهش مییابد و اثربخشی وظایف به صورت دینامیک تغییر میکند.
- الگوریتمهای MAB تهاجمی از نظر محاسباتی کارآمد هستند، که در حفظ توان عملیاتی (throughput) فازینگ حیاتی است. نگرانی از عملکرد، یکی از دلایل اصلی انتخاب آنها در کارهای مرتبط مانند [34] نیز بوده است.
یکی از معایب راهحلهای MAB تهاجمی این است که تنها انتخابهای بهینه محلی (locally optimal) انجام میدهند و بنابراین ممکن است استراتژیهای بهینه بلندمدت و سراسری ایجاد نکنند، برخلاف سایر الگوریتمهای پیچیدهتر یادگیری تقویتی که همبسته (associative) [31] هستند.
برای مثال، SYZVEGAS ممکن است در ابتدای فازینگ تعداد زیادی برنامه تولید کند و این میتواند منجر به ایجاد بذرهای ضعیف و کاهش کارایی فازینگ در طولانیمدت شود. خوشبختانه، مولفه انتخاب بذر SYZVEGAS تضمین میکند که بذرهای خوب بهطور گسترده استفاده شوند و بذرهای ضعیف در نهایت اولویتشان کاهش یابد.
یک نگرانی دیگر در مورد الگوریتم MAB این است که فقط پوشش تجمعی را در نظر میگیرد و رابطه بین بلاکها یا لبههای مختلف پایه (basic blocks/edges) را نادیده میگیرد. بنابراین، بهطور دقیق نمیتواند مشخص کند که کدام بلاک/لبه بیشترین پتانسیل را برای کشف پوشش جدید دارد و بذر متناظر با آن را پاداش دهد. با این حال، ما معتقدیم (و مشاهده کردهایم) که این اثر با گذر زمان و اجرای طولانی فازر کاهش مییابد. به لطف ماهیت تصادفی الگوریتم MAB، بذرهای توانمند در نهایت شناسایی و استفاده میشوند. با این حال، ما امیدواریم که ترکیب رویکرد MAB با روشهای whitebox (که ساختار داخلی برنامهها را در نظر میگیرند) بتواند همزمان استفاده شود و کارایی فازینگ را بیشتر بهبود دهد (این موضوع به عنوان کار آینده باقی مانده است).
به تأخیر انداختن تریاژ. Syzkaller معمولاً تریاژ را اولویت میدهد تا برنامهها را سریعاً وارد مجموعه بذر کند؛ این کار باعث میشود بذرها حتی در صورت کرش VM/دستگاه فازر حفظ شوند. با این حال، در SYZVEGAS، وظایف تریاژ اغلب به نفع تولید/ جهش (Generation/Mutation) به تعویق میافتند و این میتواند باعث از دست رفتن بیشتر در صورت کرش VM/دستگاه شود. با این حال، این مسئله قابل قبول است زیرا صف کاری تریاژ تنها در ابتدای فازینگ به شدت پر میشود، زمانی که برنامهها به راحتی میتوانند پوشش جدید پیدا کنند. این برنامههای اولیه اغلب فقط پوشش “سطحی” ایجاد میکنند و بازتولید آنها دشوار نیست. در نهایت، SYZVEGAS اولویت مطلق تریاژ را بازیابی میکند و این مشکل در مراحل بعدی فازینگ رفع میشود.
بهینهسازی بر اساس زمان اجرا. SYZVEGAS برای پوشش به ازای واحد زمان بهینهسازی میکند و در ابتدا بهطور طبیعی بذرهایی با سیستمکالهای کمهزینه را ترجیح میدهد. در عمل، برخی بخشهای کرنل ممکن است تنها از طریق سیستمکالهای زمانبر قابل دسترسی باشند (که در ابتدا توسط SYZVEGAS ترجیح داده نمیشوند). با این حال، با ادامه فازینگ، بذرهایی با سیستمکالهای کمهزینه برای یافتن پوشش جدید با مشکل مواجه میشوند و SYZVEGAS به طور طبیعی به سمت بذرهایی با سیستمکالهای پرهزینهتر که کمتر کاوش شدهاند، تغییر مسیر میدهد.
بهینهسازی برای پوشش. هدف نهایی فازینگ یافتن آسیبپذیریها است، یعنی پیدا کردن ورودیهایی که بتوانند برنامهٔ هدف را دچار کرش کنند. با این حال، SYZVEGAS همانند بیشتر کارهای دیگر (مانند 8] ، 26، 34، 35[) بهجای یک مدل پاداش مبتنی بر کرش (مانند [33]) از مدل پاداش مبتنی بر پوشش استفاده میکند. استدلال ما به شرح زیر است: (۱) یافتن پوشش جدید بسیار آسانتر از یافتن یک کرش جدید است، بنابراین مدل پاداش مبتنی بر پوشش بازخورد را با دفعات بیشتری در اختیار فازر قرار میدهد؛ (۲) جهش دادن بذرهایی که منجر به کرش میشوند معمولاً همان کرشها را دوباره تولید میکند، بنابراین لزوماً سیگنال پاداش مناسبی محسوب نمیشوند؛ و (۳) کرشها زمانی رخ میدهند که یک مسیر کدی مشخص اجرا شود، که این موضوع ارتباط نزدیکی با پوشش کد (یعنی شاخههای طیشده) دارد.
سایر کارهای آینده. چارچوبهای فازینگ کرنل در دنیای واقعی مانند syzbot [15] معمولاً بر پایهٔ اجرای فازینگهای قبلی اجرا میشوند. در بخش 4.2 نشان دادیم که SYZVEGAS در حضور یک مجموعهٔ بذر موجود نیز عملکرد بهتری نسبت به Syzkaller معمولی دارد. با این حال، وضعیت انتخاب وظیفه/بذر در MAB (یعنی پاداش تجمعی وظایف/بذرها) نیز میتواند برای استفاده در اجرایهای فازینگ آینده ذخیره شود. ما حدس میزنیم که بهدلیل ماهیت سازگارشوندهٔ سریع الگوریتم MAB متخاصم، مزیت ادامه دادن از یک وضعیت MAB موجود محدود باشد. ارزیابی این مسیر را به کارهای آینده واگذار میکنیم.
از نظر تئوری، SYZVEGAS میتواند در کنار سایر بهینهسازیهای فازینگ که از تحلیل برنامه و/یا یادگیری ماشین استفاده میکنند نیز بهکار گرفته شود. از آنجا که SYZVEGAS تنها وظیفهٔ انتخاب وظیفه و بذر را بر عهده دارد، بهینهسازیهایی که عملگرهای جهش (mutation operators) را هدف قرار میدهند (مانند [9]) باید بدون نیاز به تغییر خاصی همراه با SYZVEGAS کار کنند. چنین بهینهسازیهایی میتوانند بر میزان اثربخشی جهش تأثیر بگذارند و در نتیجه تصمیمهای SYZVEGAS را نیز تحت تأثیر قرار دهند. در مورد بهینهسازیهایی که مستقیماً انتخاب بذر را هدف میگیرند (مانند [35])، میتوان SYZVEGAS را با الگوریتمهای MAB مانند Exp4 [7] ترکیب کرد که قادرند بردارهای راهنمای اضافی را بهعنوان ورودی دریافت کنند.
یادگیری تقویتی همچنین میتواند برای تنظیم سایر ثابتها یا راهبردهای ایستایی که در پیادهسازی Syzkaller فراوان هستند بهکار رود؛ برای مثال اندازهٔ برنامه، راهبرد تولید (generation strategy)، انتخاب عملگرهای جهش و موارد مشابه. با این حال، مدلهای ارزیابی پاداش موردنیاز در این حالت میتوانند تفاوت زیادی با مدل SYZVEGAS داشته باشند. ما معتقدیم بررسی یک مدل یکپارچه که بتواند همهٔ «دکمههای قابل تنظیم» در فازینگ کرنل را بهصورت مشترک در نظر بگیرد، یک مسیر آیندهٔ بسیار امیدوارکننده است. جهت جالب دیگر برای پژوهشهای آینده، بررسی قابلیت بهکارگیری سایر الگوریتمهای پیشرفتهتر یادگیری تقویتی در فازینگ کرنل است.
6. کارهای مرتبط
تکنیکهای MAB در فازینگ. تلاشهایی برای بهکارگیری تکنیکهای MAB بهمنظور بهبود عملکرد فازینگ، بهویژه در انتخاب بذر، انجام شده است. Woo و همکاران [33] تعداد کرشها را بهعنوان تابع پاداش برای انتخاب «موثرترین» بذرها استفاده میکنند. Patil و همکاران [25] تعداد تستکیسهای جالب را بهعنوان تابع پاداش در قالب یک مسئلهٔ «Contextual Bandit» بهکار میگیرند. Yue و همکاران،EcoFuzz [34] را پیشنهاد میکنند که از یک الگوریتم MABمتخاصم برای انجام انتخاب بذر استفاده میکند. آزمایشهای ما نشان میدهد که راهبرد انتخاب بذر در SYZVEGAS قابل انتقال به فضای کاربر (user-space) است و عملکردی قابلمقایسه و مطلوب نسبت به EcoFuzz دارد. علاوه بر این،SYZVEGAS پارامتر منحصربهفرد زمانبندی وظیفه میان تولید، جهش و تریاژ را نیز در نظر میگیرد؛ قابلیتی که مخصوص فازینگ کرنل است (و در EcoFuzz وجود ندارد). ما نشان میدهیم که تنها زمانی که این پارامترها بهصورت مشترک در نظر گرفته شوند، مدل MAB میتواند بهترین عملکرد را ارائه دهد.
سایر روشهای فازینگ مبتنی بر بهینهسازی. علاوه بر MAB، مدلهای دیگری نیز برای بهینهسازی جنبههای مختلف فازینگ پیشنهاد شدهاند، از جمله انتخاب بذر [8، 26، 35] و راهبردهای جهش [9، 17، 22]. مدلها و تکنیکهای پیشنهادی شامل زنجیرهٔ مارکوف (markov-chain) [8]، Q-learning [9]، نمونهبرداری مونتکارلو [35]، Thompson Sampling [17] و بهینهسازی ازدحام ذرات (Particle Swarm Optimization) [22] هستند. ما MAB را انتخاب کردیم زیرا سادگی آن امکان یکپارچهسازی انتخاب وظیفه و انتخاب بذر را در فازینگ کرنل فراهم میکند. در عمل،SYZVEGAS میتواند در کنار هر الگوریتمی که هدف آن بهینهسازی توزیع عملگرهای جهش است نیز کار کند. تنظیم راهبرد جهش را میتوان یک پارامتر قابلتنظیم دیگر دانست که در آینده قابل اضافه شدن است.
فازینگ کرنل. پژوهشهای زیادی برای بهینهسازی فازینگ کرنل انجام شده است. پروژه Moonshine [24] تلاش میکند کیفیت بذرهای اولیه در Syzkaller را با «استخراج» بذرها از ردگیری فراخوانهای سیستم (system call traces) برنامههای واقعی بهبود بخشد. ما در بخش 4.2 نشان دادهایم که SYZVEGAS میتواند بهخوبی در کنار Moonshine عمل کند.
HFL [18] فازینگ را با اجرای نمادین (symbolic execution) ترکیب میکند و در بخش 4.2 نشان دادیم که SYZVEGAS رشد پوشش را با اختلاف بیشتری نسبت به HFL بهبود میدهد. kAFL [28] بر پایهٔ AFL ساخته شده و برخلاف Syzkaller قالبهای syscall ندارد.
طبق مقالهٔ آنها، مقایسهٔ پوشش (با Syzkaller) میتواند بهشدت گمراهکننده باشد. FastSyzkaller [21] با ترکیب Syzkaller و یک مدل N-Gram فرایند تولید تستکیس (مورد آزمون) را بهینه میکند. Difuze [11] از تحلیل ایستا برای ساخت ورودیهای با ساختار صحیح در فضای کاربر جهت کاوش درایورهای کرنل استفاده میکند. این دو کار بر فرایند تولید برنامه تمرکز دارند، در حالی که کار ما بر زمانبندی برنامههای تولیدشده یا جهشیافته تمرکز دارد. RAZZER [16] بر شناسایی باگهای رقابتی (race bugs) در کرنل متمرکز است. Agamotto [30] سرعت checkpoint گرفتن ماشین مجازی را بهبود میدهد که بهطور غیرمستقیم سرعت فازینگ را افزایش میدهد. Periscope [29] بر فازینگ رابط سختافزار تمرکز دارد. اهداف این پژوهشها با اهداف SYZVEGAS متعامد هستند، زیرا ما به دنبال بهبود نرخ رشد پوشش از طریق تنظیم هوشمندانهتر پارامترهای موجود فازینگ هستیم. تغییر توابع پاداش SYZVEGAS برای کاربردهای دیگری که در این آثار بررسی شدهاند خارج از محدودهٔ این کار است و به پژوهشهای آینده واگذار میشود.
7. نتیجهگیری
در این مقاله، با الهام از این مشاهده که راهبردهای فازینگ کرنل دارای تصمیمهای ثابت متعدد و پارامترهای hard-coded هستند،SYZVEGAS را پیشنهاد کردیم تا در Syzkaller بتواند بهصورت پویا وظیفه مناسب فازینگ را همراه با بذر مناسب انتخاب کند. برای این منظور، وظیفههای فازینگ را در قالب یک مسئله باندیت چند اهرمی (multi-armed bandit) مدلسازی کردیم؛ رویکردی که به سیستم اجازه میدهد راهبردهای مؤثر را یاد بگیرد و در طول زمان سازگار شود، آن هم با استفاده از یک مدل ارزیابی پاداش جدید اما شهودی که هم مزایا و هم هزینهها را در نظر میگیرد.
ما SYZVEGAS را روی نسخهٔ 5.6.13 کرنل لینوکس و چندین گونهٔ دیگر ارزیابی کردیم. نتایج نشان میدهد که SYZVEGAS تنها 2.1٪ سربار عملکردی دارد، اما در مقایسه با Syzkaller پیشفرض، بهبود قابلتوجهی در نرخ دستیابی به پوشش و تعداد کرشهای کشفشده ایجاد میکند. ما یافتههای خود را به تیم Google Syzkaller گزارش کردهایم و بهطور فعال روی upstream کردن تغییرات خود کار میکنیم [4]. در زمان نگارش این مقاله، در حال آزمایش پیادهسازی SYZVEGAS با چندین ماشین مجازی و فرایند فازر هستیم و امیدواریم بهزودی SYZVEGAS با syzbot یکپارچه شود.
منابع
[1] Linux kernel selftests. https://www.kernel.org/doc/html/v4.15/dev-tools/kselftest.html.
[2] Open posix tests. http://posixtest.sourceforge.net.
[3] Hfl bitbucket repo, 2020. https://bitbucket.org/anonyk/hfl-release.
[4] pkg/learning, syz-fuzzer: add mab-based seed scheduling, 2020. https://github.com/google/syzkaller/pull/1895.
[5] American fuzzy loop, Online. http://lcamtuf. coredump.cx/afl/.
[6] Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E Schapire. Gambling in a rigged casino: The adversarial multi-armed bandit problem. In Proceedings of IEEE 36th Annual Foundations of Computer Science, pages 322–331. IEEE, 1995.
[7] Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E Schapire. The nonstochastic multiarmed bandit problem. SIAM journal on computing, 32(1):48–77, 2002.
[8] Marcel Böhme, Van-Thuan Pham, and Abhik Roychoud-hury. Coverage-based greybox fuzzing as markov chain.IEEE Transactions on Software Engineering, 45(5):489–506, 2017.
[9] Konstantin Böttinger, Patrice Godefroid, and Rishabh Singh. Deep reinforcement fuzzing. In 2018 IEEE Security and Privacy Workshops (SPW), pages 116–122. IEEE, 2018.
[10] Norman Cliff. Dominance statistics: Ordinal analyses to answer ordinal questions. Psychological bulletin, 114(3):494, 1993.
[11] Jake Corina, Aravind Machiry, Christopher Salls, Yan Shoshitaishvili, Shuang Hao, Christopher Kruegel, and Giovanni Vigna. Difuze: Interface aware fuzzing for kernel drivers. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pages 2123–2138. ACM, 2017.
[12] LTP developers. Linux testing projects, 2012. https://linux-test-project.github.io.
[13] Patrice Godefroid, Adam Kiezun, and Michael Y. Levin. Grammar-based whitebox fuzzing. In Proceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’08, pages 206–215, New York, NY, USA, 2008. ACM.
[14] Google. Syzkaller. https://github.com/google/syzkaller.
[15] Google. Syzbot, Online. https://syzkaller. appspot.com/upstream.
[16] Dae R Jeong, Kyungtae Kim, Basavesh Shivakumar, Byoungyoung Lee, and Insik Shin. Razzer: Finding kernel race bugs through fuzzing. In Proceedings of the IEEE Symposium on Security and Privacy, 2019.
[17] Siddharth Karamcheti, Gideon Mann, and David Rosenberg. Adaptive grey-box fuzz-testing with thompson sampling. In Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security, pages 37–47. ACM, 2018.
[18] Kyungtae Kim, Dae R Jeong, Chung Hwan Kim, Yeongjin Jang, Insik Shin, and Byoungyoung Lee. Hfl: Hybrid fuzzing on the linux kernel. In Proceedings of the 2020 Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, 2020.
[19] George Klees, Andrew Ruef, Benji Cooper, Shiyi Wei, and Michael Hicks. Evaluating fuzz testing. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, pages 2123–2138. ACM, 2018.
[20] UCR Security Lab. Syzvegas git repo, 2021. https://github.com/seclab-ucr/SyzVegas.
[21] Dan Li and Hua Chen. FastSyzkaller: Improving fuzz efficiency for linux kernel fuzzing. Journal of Physics: Conference Series, 1176:022013, mar 2019.
[22] Chenyang Lyu, Shouling Ji, Chao Zhang, Yuwei Li, WeiHan Lee, Yu Song, and Raheem Beyah. MOPT: Optimized mutation scheduling for fuzzers. In 28th USENIX Security Symposium (USENIX Security 19), pages 1949-1966, 2019.
[23] Gergely Neu. Explore no more: Improved high probability regret bounds for non-stochastic bandits. In Advances in Neural Information Processing Systems, pages 3168–3176, 2015.
[24] Shankara Pailoor, Andrew Aday, and Suman Jana. Moonshine: Optimizing OS fuzzer seed selection with trace distillation. In 27th USENIX Security Symposium (USENIX Security 18), pages 729–743, 2018.
[25] Ketan Patil and Aditya Kanade. Greybox fuzzing as a contextual bandits problem. CoRR, abs/1806.03806, 2018.
[26] Alexandre Rebert, Sang Kil Cha, Thanassis Avgerinos, Jonathan Foote, David Warren, Gustavo Grieco, and David Brumley. Optimizing seed selection for fuzzing. In 23rd USENIX Security Symposium (USENIX Security 14), pages 861–875, 2014.
[27] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017.
[28] Sergej Schumilo, Cornelius Aschermann, Robert Gawlik, Sebastian Schinzel, and Thorsten Holz. kafl:Hardware-assisted feedback fuzzing for OS kernels. In 26th USENIX Security Symposium (USENIX Security 17), pages 167–182, 2017.
[29] Dokyung Song, Felicitas Hetzelt, Dipanjan Das, Chad Spensky, Yeoul Na, Stijn Volckaert, Giovanni Vigna, Christopher Kruegel, Jean-Pierre Seifert, and Michael Franz. PeriScope: An effective probing and fuzzing framework for the hardware-OS boundary. In Network and Distributed System Security Symposium (NDSS), 2019.
[30] Dokyung Song, Felicitas Hetzelt, Jonghwan Kim, Brent ByungHoon Kang, Jean-Pierre Seifert, and Michael Franz. Agamotto: Accelerating kernel driver fuzzing with lightweight virtual machine checkpoints. In 29th USENIX Security Symposium (USENIX Security 20), pages 2541–2557. USENIX Association, August 2020.
[31] Richard S Sutton and Andrew G Barto. Introduction to Reinforcement Learning. The MIT Press, 2018.
[32] Pierre Francois Verhulst. Logistic function, 1838. https://en.wikipedia.org/wiki/Logistic function.
[33] Maverick Woo, Sang Kil Cha, Samantha Gottlieb, and David Brumley. Scheduling black-box mutational fuzzing. In Proceedings of the 2013 ACM SIGSAC conference on Computer & communications security,pages 511–522. ACM, 2013.
[34] Tai Yue, Pengfei Wang, Yong Tang, Enze Wang, Bo Yu, Kai Lu, and Xu Zhou. Ecofuzz: Adaptive energysaving greybox fuzzing as a variant of the adversarial multi-armed bandit. In 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, August 2020.USENIX Association.
[35] Lei Zhao, Yue Duan, Heng Yin, and Jifeng Xuan. Send hardest problems my way: Probabilistic path prioritization for hybrid fuzzing. In NDSS, 2019.
[36] Datong P. Zhou and Claire J. Tomlin. Budgetconstrained multi-armed bandits with multiple plays.CoRR, abs/1711.05928, 2017.
8. ضمایم
۸.۱ جریان کار Syzkaller
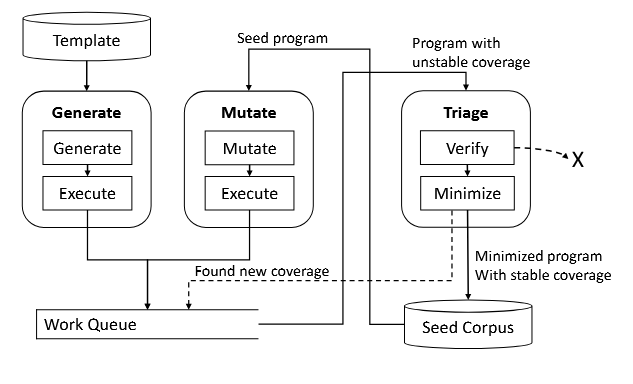
شکل ۱۰ گردشکار دقیق Syzkaller را نشان میدهد. زمانبندی وظایف تولید، جهش و تریاژ حول یک «صفکار» (workqueue) از نوع LIFO متمرکز شده است. تعامل دقیق میان وظایف و صفکار به صورت زیر است:
- تولید. تولید برنامه به سایر انواع وظایف وابسته نیست، زیرا برنامه بهطور کامل از قالبها (templates) ساخته میشود. اگر یک برنامهٔ تولیدشده (یعنی دنبالهٔ syscall مربوطه) پوشش جدیدی ایجاد کند، در صفکار تریاژ قرار داده میشود.
- جهش. برنامههای جهشیافتهای که پوشش جدید تولید کنند به صفکار تریاژ اضافه میشوند. جهش به برنامههای seed که توسط وظیفهٔ تریاژ ایجاد شدهاند متکی است.
- تریاژ. در این مرحله، Syzkaller یک برنامه را از صفکار تریاژ دریافت میکند. این برنامه به دلیل ایجاد پوشش جدید وارد صف شده است، اما هنوز مشخص نیست که این پوشش بهصورت پایدار قابل بازتولید باشد. بنابراین، Syzkaller برنامه را سه بار مجدداً اجرا میکند و پوششی را محاسبه میکند که در تمام اجراهای مجدد پایدار باقی بماند؛ اگر چنین پوششی وجود نداشته باشد، فرایند تریاژ متوقف میشود. سپس Syzkaller عملیات «Minimization» را روی برنامه انجام میدهد؛ یعنی تلاش میکند برخی system callها را حذف کرده و/یا آرگومانها را کوتاهتر کند، در حالی که پوشش پایدار حفظ شود. در نهایت، برنامهٔ کمینهشده در مجموعهٔseedها (seed corpus) قرار میگیرد تا در جهشهای بعدی استفاده شود. اگر seedهای خارجی توسط کاربر ارائه شوند (مثلاً از اجرای قبلی یا با استفاده از Moonshine [24])، آنها نیز باید مرحلهٔ تریاژ را طی کنند، زیرا ممکن است نسخهٔ کرنل و/یا Syzkaller مورد استفاده برای تولید آنها متفاوت بوده باشد.
۸.۲ الگوریتم Exp3-IX
الگوریتم ۳، الگوریتم Exp3-IX را نشان میدهد. Exp3-IX وزن هر یک از K اهرم (arm) را نگهداری میکند که از این وزنها برای تعیین متناسب احتمال انتخاب هر اهرم استفاده میشود. هنگامی که یک اهرم انتخاب میشود، الگوریتم پاداش تخمینی را بر اساس احتمال انتخاب آن اهرم و یک عامل اکتشاف ضمنی γ محاسبه میکند. وزن هر اهرم سپس بر پایهٔ این پاداش تخمینی، بهصورت نمایی تنظیم میشود؛ این تنظیم توسط ثابت نرخ رشد η کنترل میگردد. با داشتن تعداد اهرمها K، تعداد کل دفعات اجرا T، و پارامترهای اکتشاف/رشد، Exp3-IX کران regret زیر را تضمین میکند:
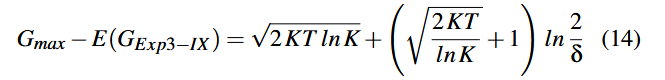
۸.۳ تکامل برنامهها در طول فازینگ کرنل
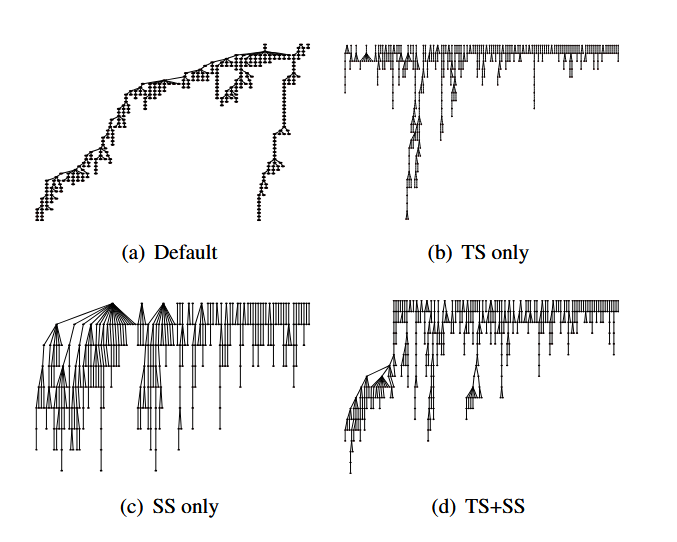
برای درک بهتر تأثیر انتخاب وظیفه (Task Selection) و انتخاب بذر (Seed Selection) در MAB، تکامل برنامهها در Syzkaller را بررسی میکنیم. همه چیز با برنامههای تولید شده آغاز میشود که سپس از طریق یک سری کاهشها (Minimization) و جهشها (Mutation) عبور کرده و یک ساختار درختی ایجاد میکنند. برای هر پیکربندی، یک اجرای نمونه انتخاب میکنیم و جنگل تکامل برنامهها را میسازیم، آن را به حدود ۵۰۰ گره کاهش میدهیم و در شکل ۱۱ نشان میدهیم.
مشاهده میکنیم که استراتژیهای مختلف رویکردهای متفاوتی برای تکامل برنامهها دارند:
- Vanilla Syzkaller (شکل ۱۱ (a)) همانطور که پیشتر در شکل ۲.۲ بحث شد، به دلیل استفاده از صف LIFO و سیاست Triag-smash-first، رویکرد عمقی (Depth-First) را ترجیح میدهد. تعداد کمی تولید انجام میدهد (۱۳ درخت قبل از نمونهگیری) و در جهش (Mutation) نیز بسیار جانبدارانه عمل میکند.
- فقط انتخاب وظیفه (شکل ۱۱ (b))، SYZVEGAS بیشترین تعداد وظایف تولید را انجام میدهد و بیشترین تعداد درختها را ایجاد میکند (۷۸۹ قبل از نمونهگیری)، اما زمان کمتری را صرف کاوش آنها میکند و هنوز تحت تأثیر کاوش جانبدارانه Vanilla Syzkaller قرار دارد.
- فقط انتخاب بذر (شکل ۱۱ (c))، تعداد مناسبی درخت ایجاد میشود (۲۰۲ قبل از نمونهگیری) و درختها متعادلتر هستند. با این حال، واضح است که درخت ایجادشده توسط اولین تولید بسیار بیشتر از درختهای بعدی کاوش شده است.
- ترکیب انتخاب وظیفه و بذر، SYZVEGAS هر دو مزیت را دارد: تعداد زیاد درختها به دلیل زمانبندی و تعادل کاوش ناشی از انتخاب بذر. به طور مشخص، با تولیدهای بیشتر در ابتدا، SYZVEGAS توانسته است تعداد بیشتری از این تولیدها (۳۴۷ قبل از نمونهگیری) را به درخت تبدیل کند.