")
پیادهسازیهای پروتکلهای شبکه، بهعنوان اجزای اساسی سامانههای ارتباطات اطلاعاتی، از اهمیت حیاتی در حوزه امنیت برخوردارند. به دلیل کارایی بالا و سطح بالای خودکارسازی، فازینگ به یکی از روشهای پرکاربرد برای شناسایی آسیبپذیریهای امنیتی پروتکلها تبدیل شده است. با این حال، تکنیکهای موجود فازینگ پروتکل با چالش اساسی تولید ورودیهای باکیفیت مواجه هستند.
ما برای حل این مشکل، در این مقاله، MSFuzz را معرفی میکنیم؛ روشی برای فازینگ پروتکل که مبتنی بر درک نحو پیامها (Message Syntax Comprehension) است. مشاهدهی کلیدی MSFuzz این است که کد منبع پیادهسازیهای پروتکل حاوی دانش دقیق و جامعی از نحو پیامهای پروتکلی میباشد. بهطور مشخص، ما از قابلیتهای درک کد مدلهای زبانی بزرگ (LLMs) برای استخراج نحو پیامها از کد منبع و ساخت درختهای نحو پیام (Message Syntax Trees) استفاده کردیم.
سپس با بهرهگیری از این درختهای نحوی، مجموعه بذر اولیه (Initial Seed Corpus) را گسترش داده و یک راهبرد جهش آگاه از نحو (Syntax-Aware Mutation Strategy) جدید طراحی کردیم تا فرآیند فازینگ را بهصورت هدفمند هدایت کند.
بهمنظور ارزیابی عملکرد MSFuzz، آن را با فازرهای پیشرفتهی روز ( SOTA یا State-of-the-Art) در حوزه فازینگ پروتکل، یعنی AFLNET و CHATAFL، مقایسه کردیم. نتایج تجربی نشان داد که MSFuzz در مقایسه با AFLNET و CHATAFL بهطور متوسط بهترتیب به:
- 22.53٪ و 10.04٪ افزایش در تعداد حالتها (States)،
- 60.62٪ و 19.52٪ افزایش در تعداد انتقال حالتها (State Transitions)،
- و 29.30٪ و 23.13٪ بهبود در پوشش شاخهای (Branch Coverage)
دست یافته است. علاوه بر این، MSFuzz موفق به کشف تعداد بیشتری آسیبپذیری نسبت به فازرهای SOTA پیشرفتهی موجود شد.
کلمات کلیدی: فازینگ؛ آگاه از نحو؛ پیادهسازیهای پروتکل؛ مدلهای زبان بزرگ
1. مقدمه
در عصر دیجیتال، پروتکلهای شبکه به عنوان پایه و اساس تبادل اطلاعات عمل میکنند، نه تنها قوانین و قالبهایی را برای انتقال دادهها ایجاد میکنند، بلکه دقت و کارایی اطلاعات شبکه را نیز تضمین میکنند [1]. اگرچه این پروتکلها برای پیشرفت اطلاعرسانی و هوشمندسازی مدرن بسیار مهم هستند، اما پیچیدگی و تنوع آنها خطرات امنیتی را افزایش میدهد. علاوه بر این، اشتباهات یا خطاهای احتمالی در طول توسعه پروتکل اغلب منجر به آسیبپذیری میشود. این امر فضای زیادی را برای هکرها فراهم میکند تا برنامههای شبکه را هدف قرار دهند [2]. بنابراین، شناسایی و اصلاح مؤثر این آسیبپذیریهای پیادهسازی برای حفظ امنیت و ثبات فضای مجازی حیاتی است.
فازینگ یک روش تست نرمافزار کارآمد است که به طور گسترده در برنامههای نرمافزاری مختلف استفاده میشود و ثابت شده است که در کشف آسیبپذیریهای بحرانی بسیار مؤثر و قدرتمند است [3,4]. به دلیل اتوماسیون و کارایی آن، فازینگ به یکی از روشهای محبوب برای تشخیص آسیبپذیریهای امنیتی در پروتکلهای شبکه تبدیل شده است.
این روش شامل ارسال حجم زیادی از دادههای تصادفی یا نیمهتصادفی به پیادهسازیهای پروتکل برای ایجاد رفتار غیرعادی و در نتیجه کشف آسیبپذیریهای بالقوه است. فازینگ پروتکل شبکه در مقایسه با سایر فازینگها، با چالشهای بیشتری در تولید موارد آزمایشی با کیفیت بالا مواجه است که عمدتاً به دلیل ماهیت بسیار ساختاریافته ورودیهای آن است. به طور خاص، ورودی شامل مجموعهای از پیامهای درخواست است که هر کدام به فیلدهایی تقسیم میشوند که توسط قوانین نحوی دقیق با محدودیتهای مقداری دقیق تعریف شدهاند. اگر پیامهای ورودی الزامات نحوی اولیه را رعایت نکنند، سرور، آنها را در مرحله اولیه پردازش دور میاندازد. این الزام سختگیرانه برای نحو ورودی به طور قابل توجهی بر کیفیت موارد آزمایشی تأثیر میگذارد.
در سالهای اخیر، مطالعات قبلی بر کسب دانش نحوی پیامهای پروتکل برای تولید موارد آزمایشی با کیفیت بالا متمرکز بودهاند. این روشها در چهار دسته اصلی قرار میگیرند: استخراج مشخصات پروتکل [10-5]، تحلیل ترافیک شبکه [15-11]، تحلیل رفتار برنامه [19-16] و تحلیل یادگیری ماشین [21-20]. روشهای استخراج مشخصات پروتکل در درجه اول قالبهای نحوی پیام را از اسناد مشخصات RFC پروتکل استخراج میکنند. روشهای تحلیل ترافیک شبکه با جمعآوری و تحلیل ترافیک شبکه، در مورد کلمات کلیدی و مرزهای فیلد در پیامها اطلاعات کسب میکنند. روشهای تحلیل رفتار برنامه با تحلیل نحوه رفتار برنامهها هنگام پردازش دادههای پیام، اطلاعات قالب پروتکل را به دست میآورند. روشهای تحلیل یادگیری ماشین از تکنیکهای پردازش زبان طبیعی برای یادگیری نحو پروتکل استفاده میکنند. اگرچه این روشها میتوانند دانش جزئی از پروتکل را به دست آورند، با وجود اینکه الگوریتمهای فازینگ مبتنی بر جهش، هنوز با سه چالش کلیدی در تولید موارد آزمایشی با کیفیت بالا مواجه هستند:
چالش ۱: دانش ورودی ناکافی. فازکنندههای پروتکل فعلی [5,11,16,20] فاقد درک مؤثر و دقیقی از نحو پیام هستند. این ابزارها معمولاً فقط ساختار نحوی اولیه یا محدودیتهای نحوی فیلدهای خاص را آشکار میکنند و نمیتوانند دانش نحوی جامع پیام را به طور کامل درک کنند. این درک جزئی از نحو پیام، توانایی تولید ورودیهای با کیفیت بالا را محدود میکند و در نتیجه بر اثربخشی کلی فازینگ تأثیر میگذارد.
چالش ۲: تنوع ناکافی بذر (Seed). اثربخشی موارد آزمایشی در فازینگ مبتنی بر جهش تا حد زیادی به کیفیت مجموعه بذر اولیه بستگی دارد. با این حال، پرکاربردترین معیار فازینگ پروتکل شبکه، ProFuzzBench [22]، اغلب فقدان تنوع بذر را نشان میدهد. اگر بذرهای اولیه جامع نباشند و صرفاً به جهشهای ساده متکی باشند، فازینگ ممکن است در بررسی کافی پیادهسازیهای پروتکل شکست بخورد. این محدودیت، تشخیص طیف وسیعتری از آسیبپذیریها را محدود میکند.
چالش ۳: استراتژیهای جهش ناکارآمد. استراتژیهای جهش معمولاً کیفیت موارد آزمون را هنگام فازینگ تعیین میکنند. اکثر فازکنندههای پروتکل فعلی [23,24,25] به روشهای جهش تصادفی متکی هستند که از رویکردهای هدفمند یا استراتژیک استفاده نمیکنند. این رویکردها در تولید موارد آزمون متنوع و با کیفیت بالا که میتوانند به طور مؤثر استحکام پیادهسازیهای پروتکل را ارزیابی کنند، شکست میخورند. چنین کاستیهایی در استراتژیهای جهش، عمق و وسعت پوشش فازینگ را محدود میکند و در نتیجه اثربخشی کلی فازینگ را به طور قابل توجهی کاهش میدهد.
ما در این مقاله برای غلبه بر چالشهای مطرحشده، MSFuzz را معرفی میکنیم؛ روشی برای فازینگ پروتکل که مبتنی بر درک نحو (Syntax) پیامها است. با مقایسهی نحو پیام استخراجشده در پژوهشهای پیشین با نحوی که مستقیماً از کد منبع بهدست آمده است، دریافتیم که کد منبع حاوی دانش نحوی دقیقتر و مؤثرتری از پیامهای پروتکلی میباشد.
بهمنظور رفع چالش اول، روشی را ارائه میدهیم که از مدلهای زبانی بزرگ (LLM) برای استخراج نحوی پیام از کد منبع و ساخت درختهای نحوی پیام به منظور پیادهسازیهای پروتکل استفاده میکند.
برای مواجهه با چالش دوم، از LLMها در کنار درختهای نحو پیام ساخته شده به منظور گسترش مجموعه بذر اولیه (Initial Seed Corpus) پیادهسازی پروتکل بهره گرفتیم.
در نهایت، برای حل چالش سوم، یک راهبرد جهش آگاه از نحو (Syntax-Aware Mutation Strategy) نوین طراحی کردیم که جهشهای فازینگ را در امتداد درختهای نحو پیام هدایت میکند و در نتیجه نمونههای آزمون باکیفیت بالا را تولید مینماید که قیود نحوی پیامها را رعایت میکنند.
بهطور مشخص، ابتدا از میان حجم گستردهای از کد منبع پیادهسازی پروتکل، فایلهای کد مرتبط با پارس پیامها (Message Parsing) را فیلتر و انتخاب کردیم. سپس با بهرهگیری از قابلیت درک کد مدلهای زبانی بزرگ (LLMs)، بهصورت گامبهگام انواع پیامها را استخراج کرده و همچنین پارامترهای خط درخواست (Request-Line Parameters) و قیود مقادیر آنها، و نیز فیلدهای هدر (Header Fields) به همراه محدودیتهای مقادیرشان را از کد منبع پالایششده استخراج نمودیم. این فرآیند در نهایت ما را قادر ساخت تا درخت نحو پیام (Message Syntax Tree) مربوط به پیادهسازی پروتکل را ایجاد کنیم.
بر اساس درخت نحو پیام ساخته شده و فایلهای پیکربندی پیادهسازی پروتکل، مجموعه اولیه بذر (Seed) را گسترش دادیم و مجموعهای متنوع و جامع از بذرها را ایجاد کردیم. در نهایت، از درخت نحو پیام ساخته شده برای هدایت استراتژی جهش استفاده کردیم. با تجزیه پیامهایی که قرار است جهش داده شوند و تطبیق آنها با درخت نحو، محدودیتهای نحوی فیلدهای پیام را تعیین کردیم و موارد آزمایشی با کیفیت بالا را بر اساس این محدودیتها تولید نمودیم. ما تاکنون، یک نمونه اولیه از MSFuzz را پیادهسازی کردهایم.
ما عملکرد MSFuzz را بر روی سه پروتکل پرکاربرد شبکه، یعنی RTSP، FTP و DAAP ارزیابی کردیم. در این ارزیابی، MSFuzz با دو فازر پیشرفتهی روز (State-of-the-Art) در حوزه فازینگ پروتکل، یعنی AFLNET و CHATAFL مقایسه شد. نتایج تجربی نشان داد که در بازهی زمانی 24 ساعت، MSFuzz در مقایسه با AFLNET و CHATAFL بهطور متوسط بهترتیب باعث افزایش 22.53٪ و 10.04٪ در تعداد حالتها (States) و افزایش 60.62٪ و 19.52٪ در تعداد انتقال حالتها (State Transitions) شده است.
علاوه بر این، MSFuzz با کاوش مؤثر فضای کد (Code Space Exploration) توانست پوشش شاخهای (Branch Coverage) را بهطور میانگین 29.30٪ و 23.13٪ نسبت به فازرهای پیشرفتهی موجود بهبود دهد. در مطالعه حذف مؤلفهها (Ablation Study) مشخص شد که دو مؤلفهی کلیدی، یعنی گسترش بذرها (Seed Expansion) و جهش آگاه از نحو (Syntax-Aware Mutation)، نقش بسزایی در ارتقای عملکرد فازینگ ایفا میکنند. افزون بر این، MSFuzz در مقایسه با فازرهای پیشرفتهی موجود، تعداد بیشتری آسیبپذیری را کشف کرد.
موارد اصلی این مقاله به شرح زیر خلاصه میشود:
- برای پرداختن به مشکل تولید موارد آزمون با کیفیت بالا، MSFuzz را پیشنهاد میکنیم که یک تکنیک فازینگ پروتکل جدید است. MSFuzz بر اساس سه مؤلفهی اصلی ساخته شده است: ساخت درخت نحو پیام، گسترش بذر و جهش آگاه از نحو.
- با بهکارگیری یک انتزاع جدید از ساختارهای نحو پیام، MSFuzz از قابلیتهای درک کد LLMها برای استخراج مؤثر نحو پیام از کد منبع پیادهسازیهای پروتکل استفاده میکند و در نتیجه درختهای نحو پیام با ساختار یکنواخت میسازد.
- MSFuzz از پروتکل ساخته شده استفاده میکند، درختهای نحوی برای گسترش مجموعه اولیه و اعمال استراتژیهای جهش آگاه از نحو برای تولید موارد آزمایشی با کیفیت بالا که مطابق با محدودیتهای مشخص شده هستند.
- ما MSFuzz را در پیادهسازیهای پروتکل پرکاربرد ارزیابی کردیم. نتایج نشان میدهد که MSFuzz در پوشش حالت، پوشش کد و کشف آسیبپذیری از فازرهای پروتکل SOTA بهتر عمل کرده است.
2. پیشینه و انگیزه
در این بخش، فازینگ پروتکل، مدلهای زبان بزرگ و یک مثال انگیزشی را معرفی میکنیم. ابتدا، مروری مختصر بر فازینگ پروتکل ارائه میدهیم. سپس، اطلاعات پیشینهای در مورد مدلهای زبان بزرگ و پیشرفتهای اخیر آنها در کشف آسیبپذیری ارائه میدهیم. در نهایت، محدودیتهای روشهای موجود را از طریق یک مثال انگیزشی نشان میدهیم.
2.1 فازینگ پروتکل
فازینگ بهعنوان یکی از موثرترین و کارآمدترین روشها برای کشف آسیبپذیریها، در حوزه پروتکلهای شبکه بهطور گسترده بهکار گرفته شده است. معرفی PROTOS [26] به عنوان نخستین ابزار فازینگ با تمرکز ویژه بر پروتکلها، نقطهی آغاز رسمی فازینگ پروتکل بهشمار میرود. پس از آن، این حوزه مورد توجه گستردهی پژوهشگران قرار گرفت و منجر به شکلگیری دستاوردهای پژوهشی متعددی شد، بهگونهای که امروزه فازینگ پروتکل بهعنوان یکی از محورهای اصلی پژوهش در امنیت شبکه شناخته میشود.
فازرهای پروتکل در درجه اول با شبیهسازی رفتار کلاینت، پیادهسازیهای سمت سرور را هدف قرار میدهند. این ابزارها به طور مداوم پیامهای کلاینت را ایجاد و به سرورها ارسال میکنند. بسته به روش تولید پیام، فازرهای پروتکل را میتوان به طور کلی به دو نوع طبقهبندی کرد: مبتنی بر تولید (generation based) و مبتنی بر جهش (mutation based).
فازرهای پروتکلی مبتنی بر تولید (Generation-based Protocol Fuzzers) برای تولید نمونههای آزمون به دانش پیشین از قالب و ساختار پروتکل متکی هستند [26,27,28,29,30]. ابزار PROTOS [26] با اتکا به مشخصات پروتکل، ورودیهای نادرست (Malformed Inputs) را تولید میکند تا آسیبپذیریهای خاصی را تحریک نماید. SPIKE [27] از یک رویکرد مدلسازی مبتنی بر بلوک (Block-based Modeling) استفاده میکند که در آن پروتکل به بلوکهای مجزا تقسیم شده و دادههای معتبر برای پیامهای پروتکلی بر اساس قوانین تولید از پیش تعریفشده بهصورت خودکار ایجاد میشوند. ابزار Peach [31] با تعریف مدلهای دادهای پروتکل از طریق ساخت دستی فایلهای Pit، این مدلها را برای تولید نمونههای آزمون بهکار میگیرد.
در همین راستا، SNOOZE [6] مستلزم آن است که آزمونگران بهصورت دستی مشخصات پروتکل را از اسناد RFC (Request for Comments) استخراج کنند؛ از جمله ویژگیهای فیلدهای پروتکل، نحو تبادل اطلاعات و ماشینهای حالت (State Machines). سپس، آزمونگران با ارسال توالیهای خاصی از پیامها به حالت موردنظر رسیده و بر اساس مشخصات پروتکل، تعداد زیادی نمونهی آزمون تصادفی تولید میکنند.
فازرهای پروتکلی مبتنی بر جهش (Mutation-based Protocol Fuzzers) با اعمال تغییرات بر روی بذرها (Seeds) که شامل مجموعهای از پیامهای درخواست هستند، نمونههای آزمون جدیدی تولید میکنند [19,24,32,33,34]. این عملگرهای جهش شامل تغییر مقادیر فیلدهای پیام، درج، حذف یا جایگزینی بخشهای خاصی از پیامها، و همچنین ترکیب مجدد (Recombination) یا بازچینی (Reordering) پیامها میباشند.
ابزار AFLNET [24] از راهبردهای جهش در سطح بایت (Byte-level) و ناحیه (Region-level) استفاده میکند؛ بهگونهای که ترافیک ثبتشده در حین ارتباط کلاینت–سرور را بهعنوان بذر اولیه دریافت کرده و در طول فرآیند فازینگ، نمونههای آزمون را تولید مینماید. در مقابل، SGPFuzzer [32] مجموعهای از عملگرهای جهش متنوع را معرفی میکند که فایلهای بذر انتخابشده را بهصورت ساده و ساختیافته دچار جهش میکنند؛ از جمله جهش توالی (Sequence Mutation)، جهش پیام (Message Mutation)، جهش فیلدهای دودویی (Binary Field Mutation) و جهش رشتههای متغیر (Variable String Mutation).
در مقایسه با سایر انواع فازینگ، فازینگ پروتکلهای شبکه با چالشهای بیشتری مواجه است که یکی از مهمترین آنها، ساختاریافتگی شدید ورودیها میباشد. پیامهای پروتکل شبکه معمولاً از قیود نحوی سختگیرانهای پیروی میکنند که شامل انواع مختلف پیامها و همچنین محدودیتهای نحوی در فیلدهای داخلی پیام است. هرگونه انحراف از این قیود میتواند منجر به نادیدهگرفتن یا دور انداختهشدن پیامهای دریافتی توسط سرور شود و در نتیجه اثربخشی و کارایی فرآیند فازینگ را بهطور قابلتوجهی کاهش دهد.
2.2 مدلهای زبان بزرگ
مدلهای زبانی بزرگ (LLM)، به عنوان شکلی از فناوری هوش مصنوعی مبتنی بر یادگیری عمیق، قابلیتهای قدرتمندی در پردازش زبان طبیعی از خود نشان میدهند. این مدلها تحت آموزش اولیه گستردهای روی مجموعه دادههای بزرگ قرار میگیرند و به توانایی درک عمیق و تولید متن زبان طبیعی مجهز میشوند. آنها درک عمیق و غنی از دانش زبانی دارند و درک آنها از زمینه به طور قابل توجهی کامل است.
LLMها در مطالعات اخیر، پتانسیل بالایی در زمینه تشخیص آسیبپذیری نشان دادهاند. GPTScan [35] با ترکیب GPT و تکنیکهای تحلیل ایستا (Static Analysis) برای شناسایی هوشمندانهی باگهای منطقی در قراردادهای هوشمند بهکار گرفته میشود. CHATAFL [10] از مدلهای زبانی بزرگ (LLMs) برای هدایت فازینگ پروتکل استفاده میکند؛ این ابزار گرامر پروتکلها را میسازد، بذرهای اولیه را گسترش میدهد و نمونههای آزمونی تولید میکند که قادر به تحریک انتقالهای حالت (State Transitions) از طریق تعامل با LLMها هستند.
Fuzz4All [36]از LLMها بهعنوان موتور تولید ورودی و جهش (Mutation Engine) برای فازینگ در زبانها و ویژگیهای ورودی متعدد بهره میبرد. ChatFuzz [37] از LLMها برای جهش بذرها (Seed Mutation) استفاده میکند و TitanFuzz [38] از LLMها برای فازینگ کتابخانههای یادگیری عمیق (Deep Learning Libraries) بهره میگیرد.
این پژوهشها تجربههای عملی غنیای در کاربرد مدلهای زبانی بزرگ برای کشف آسیبپذیریها ارائه میدهند و پتانسیل و ارزش این مدلها در بهبود توانمندیهای کشف آسیبپذیری را بهخوبی نشان میدهند.
اگرچه اعمال LLMها در فازینگ پروتکل شبکه پتانسیل بالایی دارد، اما با چالشهای متعددی روبرو است. هنگام استفاده از LLMها برای تجزیه و تحلیل کد منبع، وارد کردن مستقیم کل کد منبع اغلب به دلیل محدودیتهای اندازه ورودی با شکست مواجه میشود. بنابراین، هنگام استفاده از LLMها، فیلتر کردن کد منبع و استخراج قطعههای کلیدی ضروری است.
2.3 مثال انگیزشی
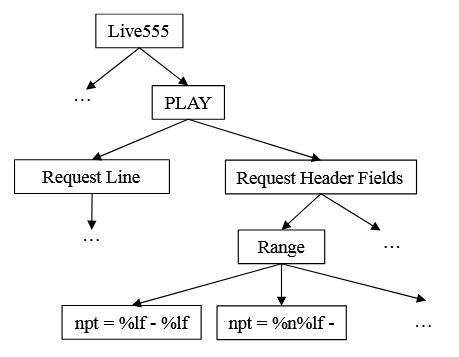
CHATAFL [10] به عنوان یکی از فازرهای پروتکل شبکه SOTA، ساختارهای نحوی پیام را از مشخصات پروتکل استخراج میکند. اگرچه پیادهسازیهای پروتکل عموماً به اسناد RFC پایبند هستند، اما بین پیادهسازیهای مختلف تفاوتهایی وجود دارد و محدودیتهای نحوی پیام واقعی اغلب دقیقتر از مشخصات هستند. به عنوان مثال، شکل 1 ساختار نحوی پیام PLAY را که CHATAFL از مشخصات RTSP استخراج میکند، نشان میدهد. اگرچه نحو اولیه پیام تعیین شده است، مقادیر خاص فیلدهای کلیدی، مانند محدوده، ناشناخته باقی میمانند.

لیست ۱ یک قطعه کد از سرور Live555 مبتنی بر پروتکل RTSP را نشان میدهد که فرآیند پارس کردن فیلد Range را به تصویر میکشد. این کد شش نوع قید مقداری (Value Constraint) برای فیلد Range شناسایی میکند:
- npt = %lf – %lf
- – npt = %n%lf
- npt = now – %lf
- npt = now – %n
- clock = %n
- smpte = %n
سرور Live555 به ترتیب، شش تطابق مربوطه را امتحان میکند تا مقادیر rangeStart و rangeEnd را تعیین نماید. در صورتی که مقدار فیلد Range پیام با هیچیک از این قیود مطابقت نداشته باشد، تابع False بازمیگرداند که نشاندهنده خطای پارس پیام (Parsing Failure) است.
لیست ۱. قطعه کد سادهشده از Live555:

هنگامی که CHATAFL، فیلد Range در Live555 را بر اساس نحو پیام نشاندادهشده در شکل ۱ جهش میدهد، تنها موقعیت مقدار فیلد را شناسایی میکند و محدودیتهای مقداری (Value Constraints) فهرستشده در لیست ۱ را درک نمیکند. در نتیجه، همچنان از راهبرد جهش تصادفی (Random Mutation Strategy) استفاده میکند.
نمونههای آزمونی که از این نحو پیام درشتدانه (Coarse-Grained Message Syntax) تولید میشوند، هرچند ساختار نحوی پایه را رعایت میکنند، اما به دلیل عدم رعایت محدودیتهای نحوی مقادیر فیلدها، به احتمال زیاد با شکست مواجه خواهند شد (Failing Test Cases).
بنابراین، به دست آوردن ساختار نحو پیام صرفاً از مشخصات پروتکل کافی نیست. کد منبع پیادهسازی پروتکل شامل نحو پیام کلاینت دانه ریزتر است. تجزیه و تحلیل این کد منبع برای دستیابی به درک جامعتر و دقیقتر از نحو پیام برای بهبود تولید موارد آزمایشی با کیفیت بالا ضروری است. تولید موارد آزمایشی با کیفیت بالا که به محدودیتهای نحو پروتکل پایبند هستند، میتواند پوشش فازینگ را به طور قابل توجهی افزایش دهد، در نتیجه فضای کد عمیقتر را کاوش کرده و احتمال کشف آسیبپذیریهای پیچیده را افزایش دهد.
۳. روششناسی
۳.۱ مرور کلی
شکل ۲ نمای کلی MSFuzz را نشان میدهد که از چهار جزء تشکیل شده است: پیشپردازش، ساخت درخت نحوی پیام، گسترش بذر و فازینگ با جهش آگاه از نحو. هدف اصلی آن پرداختن به چالشهای مرتبط با تولید موارد آزمون با کیفیت بالا در فازینگ پروتکل است، در نتیجه کارایی و اثربخشی فرآیند فازینگ را بهبود میبخشد.
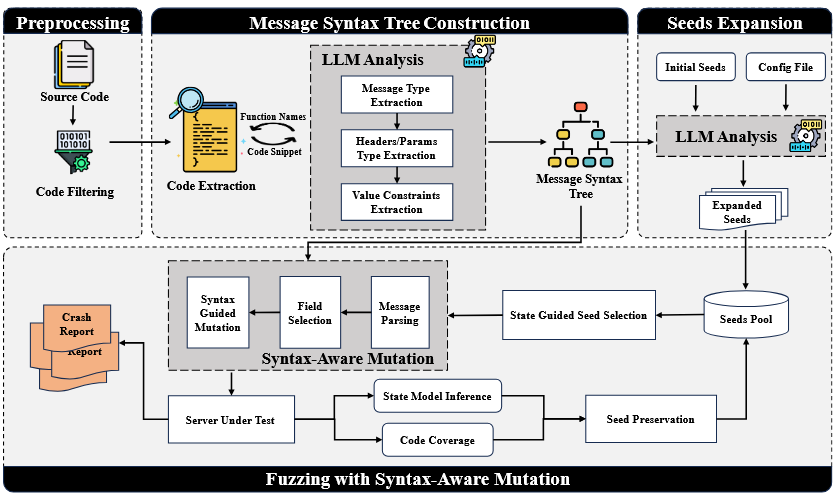
پیشپردازش (Preprocessing). قبل از استخراج نحو پیام از کد منبع، پیشفیلتر کردن فایلهای کد منبع ضروری است، زیرا همه کدها مربوط به تجزیه پیام نیستند.
با انجام یک تحلیل اولیه و فیلتر کردن کدهای نامربوط، دامنه جستجو و تحلیل LLMها در طول ساخت درخت نحو محدود میشود و در نتیجه کارایی LLMها افزایش مییابد.
ساخت درخت نحو پیام (Message Syntax Tree Construction). ما ساختار پیامهای کلاینت پروتکل مبتنی بر متن را بررسی کردیم و یک الگوی نحو پیام کلی را انتزاع کردیم. بر اساس ساختار نحو پیام انتزاع شده و قوانین اکتشافی حاصل از مشاهده کد منبع، روشی را برای استخراج نحو پیام از کد منبع پیادهسازی پروتکل با استفاده از LLMها طراحی کردیم. این رویکرد امکان ساخت درختهای نحو پیام را برای پیادهسازی پروتکل فراهم میکند.
گسترش بذر (Seed Expansion). با توجه به نقش حیاتی تنوع و کیفیت بذر اولیه در فازینگ، ما بر افزایش این جنبهها تمرکز کردیم. ما از درخت نحو پیام ساخته شده و فایلهای پیکربندی پیادهسازی پروتکل برای هدایت LLMها استفاده کردیم. این رویکرد به گسترش مجموعه اولیه بذر کمک کرد و در نتیجه تنوع و کیفیت بذر را افزایش داد.
فازینگ با جهش آگاه از نحو (Fuzzing with Syntax-Aware Mutation). ما در حلقه فازینگ، از بذرهای گسترش یافته به عنوان ورودی استفاده کردیم. MSFuzz برای جهش بذر، از درخت نحو پیام به منظور هدایت جهش پیام استفاده میکند. این کار، تضمین میکند که موارد آزمایشی تولید شده به ساختار نحو و محدودیتهای مقداری پروتکل پایبند باشند و در نتیجه کارایی فازینگ را بهبود بخشند. برای اطمینان از اینکه MSFuzz قابلیت بررسی سناریوهای شدید را دارد، ما همچنین از یک استراتژی جهش تصادفی با احتمال مشخص استفاده کردیم.
در ادامه، شرح مفصلی از طرحهای اصلی MSFuzz، از جمله ساخت درخت نحو پیام، گسترش بذر و فازینگ با جهش آگاه از نحو، ارائه میدهیم.
3.2 ساخت درخت نحوی پیام
MSFuzz از قابلیتهای درک کد LLMها برای استخراج نحو پیام از فایلهای کد منبع پیشپردازششده استفاده میکند. برای تسهیل ساخت درختهای نحوی با ساختار سازگار، ابتدا چندین پروتکل مبتنی بر متن را تجزیه و تحلیل کردیم و یک الگوی نحوی پیام کلی را خلاصه کردیم. سپس، بر اساس این الگو و چندین قانون اکتشافی که از مشاهده کد منبع به دست آمدهاند، روشی را برای استفاده از LLMها برای استخراج نحو از کد منبع طراحی کردیم و در نتیجه درخت نحوی پیام را برای پیادهسازی پروتکل ساختیم.
3.2.1 ساختار نحوی پیام
تعریف یک ساختار نحوی پیام کلی قبل از استفاده از LLMها برای ساخت درختهای نحوی پیام ضروری است. با تجزیه و تحلیل چندین پروتکل مبتنی بر متن، یک ساختار نحوی پیام کلی را خلاصه کردیم. این یک ساختار استاندارد برای تفسیر و پردازش پیادهسازیهای مختلف پروتکل فراهم کرد. این امر تضمین میکرد که درختهای نحوی تولید شده توسط LLMها سازگار و یکنواخت باشند. ما پروتکلهای مختلف مبتنی بر متن را تجزیه و تحلیل و کشف کردیم که ساختارهای پیام کلاینت آنها را میتوان به شکل کلی نشان داده شده در شکل 3 خلاصه کرد. این ساختار نحوی پیام کلی شامل سه بخش است: خط درخواست، فیلد هدر درخواست، و کاراکترهای بازگشت به خط و تغذیه خط (CRLF) همه پروتکلها شامل فیلدهای هدر درخواست و CRLF پایانی در پیامهای کلاینت خود نیستند.
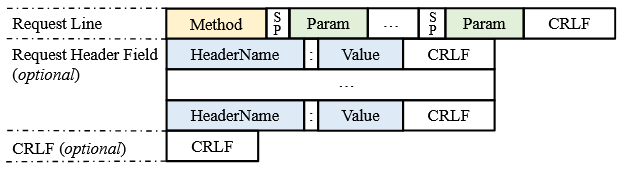
به طور خاص، خط درخواست شامل نام روش و چندین پارامتر است که با کاراکترهای فاصله (SP) از هم جدا شدهاند و با یک CRLF پایان مییابند. فیلد هدر درخواست شامل جفتهای کلید-مقدار در قالب HeaderName: Value است و همچنین با یک CRLF پایان مییابد. کل پیام معمولاً با یک CRLF به پایان میرسد.
3.2.2 استخراج نحو از طریق LLMها
بر اساس ساختار نحو عمومی که در بخش ۳.۲.۱ معرفی شد، ما از مدلهای زبانی بزرگ (LLMs) برای استخراج نحو پیامها از فایلهای کد منبع پیشپردازششده استفاده کردیم، با تمرکز بر خط درخواست (Request Line) و فیلدهای هدر درخواست (Request Header Fields) در ساختار نحو عمومی.
بهطور مشخص:
- نام متد (Method Name / نوع پیام)، نوع پارامترها (Parameter Types) و محدودیتهای مقادیر پارامترها (Parameter Value Constraints) از خط درخواست استخراج شدند.
- در صورتی که فیلدهای هدر درخواست وجود داشته باشند، نام هدرها و محدودیتهای مقادیر آنها استخراج شد.
در نهایت، بر اساس نحو پیام استخراجشده، درخت نحو پیام (Message Syntax Tree) مربوط به پیادهسازی پروتکل ساخته شد.
اگرچه ما فایلهای غیرمرتبط را از پیادهسازی پروتکل حذف کردیم، ارائهی تمام فایلهای پالایششده به مدلهای زبانی بزرگ (LLMs) اغلب از محدودیت ورودی مدل فراتر میرود. علاوه بر این، ممکن است برخی محتوای غیرمرتبط هنوز باقی مانده باشد که میتواند خروجی LLMها را تحت تأثیر قرار دهد.
بنابراین، نیاز بود که انتخاب کدها را دقیقتر کنیم و تنها قطعهکدهای مرتبط با وظیفه مورد نظر را استخراج نماییم. بر اساس تحلیل ما از پیادهسازی پروتکلهای شبکه، از قواعد هیوستیک زیر (Heuristic Rules) برای استخراج قطعهکدهای کلیدی (Key Code Snippets) استفاده کردیم. این کار اطمینان میدهد که LLMها میتوانند نحو پیامها را بهطور مؤثر یاد گرفته و استخراج کنند.
- در کد منبع پیادهسازی پروتکل، انواع مختلف پیامها یا فیلدهای هدر دارای توابع پارس مستقل هستند. بنابراین، هنگام پارس کردن یک نوع خاص از پیام یا فیلد هدر، LLMها میتوانند تنها تابع پارس مربوط به همان نوع را تحلیل کنند تا دامنه تحلیل محدود و متمرکز شود.
- نام توابع اغلب از قاعدههای نامگذاری واضح پیروی میکنند و وظایف پایهای خود را در کد منبع بهروشنی بیان میکنند. بنابراین، ارائه تنها نام توابع به مدلهای زبانی بزرگ (LLMs)، به آنها امکان میدهد هدف و عملکرد توابع را استنتاج کنند و در نتیجه شناسایی دقیقتر توابع پارس هدفمند (Target Parsing Functions) فراهم شود.
بر اساس قوانین اکتشافی ذکر شده در بالا، ما یک چارچوب خودکار پیشنهاد میکنیم که از LLM ها برای ساخت درختهای نحو پیام برای پیادهسازی پروتکل هدف استفاده میکند. این روش از یک استراتژی سلسله مراتبی و گام به گام استفاده میکند. این روش کد تجزیه کلیدی استخراج شده از فایلهای کد منبع را به LLM ها وارد میکند. از این طریق، چارچوب انواع پیام، پارامترهای خط درخواست، انواع فیلدهای سرآیند و محدودیتهای مقداری آنها را استخراج میکند و به تدریج درخت نحوی پیام را میسازد. این روش از یک استراتژی استخراج سلسله مراتبی همسو با ساختار نحوی نشان داده شده در شکل 3 استفاده میکند. در ابتدا، چارچوب نوع پیام را شناسایی میکند. متعاقباً، انواع پارامترهای خط درخواست و فیلدهای سرآیند (در صورت وجود) را استخراج میکند. در نهایت، محدودیتهای مقداری برای پارامترهای خط درخواست و فیلدهای سرآیند را تعیین میکند. این فرآیند به صورت تدریجی درخت نحوی پیام را میسازد و نمایش جامعی از ساختار پیام پروتکل را تضمین میکند.
استخراج نوع پیام (Message type extraction). MSFuzz با استفاده از ماژول استخراج کد در شکل 2، تمام نامهای تابع را از کد منبع فیلتر شده استخراج میکند. این ماژول کد منبع را تجزیه میکند تا نامهای تابع مربوطه را شناسایی کند، که سپس در مهندسی سریع برای فعال کردن LLM برای شناسایی انواع پیام در پیادهسازی پروتکل هدف استفاده میشوند. این اعلان شامل تمام نامهای توابع فیلتر شده است و هدف آن شناسایی تمام انواع پیامهایی است که پیادهسازی پروتکل هدف میتواند مدیریت کند و آنها را به توابع مدیریتکننده مربوطهشان نگاشت میکند، همانطور که در شکل 4a نشان داده شده است.
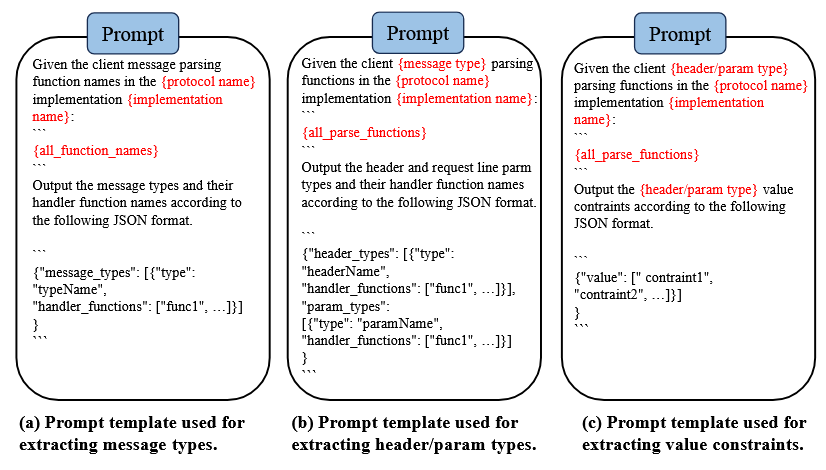
استخراج نوع هدر/پارامتر (Header/parameter type extraction). برای هر نوع پیام، MSFuzz از ماژول Code Extraction برای یافتن و استخراج کد تابع مربوطه از کد منبع بر اساس نامهای تابع هندلر شناساییشده در مرحله قبل استفاده میکند. شکل 4b دستورالعملی را که MSFuzz برای بهرهبرداری از LLM برای استخراج پارامترهای خط درخواست پیام و فیلدهای هدر (در صورت وجود) استفاده میکند، نشان میدهد. این دستورالعمل شامل کد تابع تجزیه برای پیام است و هدف آن ایجاد نگاشت بین پیام و پارامترهای خط درخواست و فیلدهای هدر آن است.
استخراج محدودیتهای مقداری (Value Constraints Extraction). MSFuzz برای پارس کردن مقادیر فیلدهای هدر یا پارامترهای خط درخواست (Request Line Parameters)، از ماژول استخراج کد (Code Extraction Module) استفاده میکند تا بر اساس نام توابع شناساییشده در مرحلهی قبل، کد تابع مرتبط را از فایلهای منبع یافته و استخراج نماید.
شکل 4c، ورودی هدایتکننده (Prompt) را نشان میدهد که MSFuzz برای استخراج محدودیتهای مقداری از LLM استفاده میکند. MSFuzz در این ورودی هدایتکننده، کد تابع تجزیه مربوط به پارامترها یا فیلدهای هدر را ارائه میدهد تا نگاشت بین پارامترها / فیلدها و محدودیتهای مقداری متناظر آنها ایجاد شود.
ما برای روشن شدن فرآیند ساخت درخت نحو پیام (Message Syntax Tree)، از رویکرد MSFuzz در مثال انگیزشی (شکل ۱) استفاده کرده و نتایج را در شکل ۵ ارائه دادهایم. شایان ذکر است که شکل ۵ تنها محدودیتهای نحوی فیلد هدر Range در پیام PLAY سرور Live555 را نشان میدهد.
۳.۳ گسترش بذر (Seed Expansion)
ما به منظور افزایش تنوع و کیفیت مجموعه بذر اولیه، از LLMها برای گسترش آن استفاده کردیم. اگرچه LLMها میتوانند بذرهای جدیدی برای پیادهسازی پروتکل هدف تولید کنند، اما سه مشکل کلیدی باید برطرف شوند: (۱) چگونه محدودیتهای نحوی پیام را به طور جامع پوشش دهیم؟ (۲) چگونه بذرهای مخصوص پیادهسازی پروتکل هدف را تولید کنیم؟ (۳) چگونه بذرهای قابل خواندن توسط ماشین تولید کنیم؟
در مورد مسئله اول، MSFuzz یک درخت نحو پیام برای پیادهسازی پروتکل هدف میسازد، همانطور که در بخش ۳.۲ به تفصیل شرح داده شده است. این درخت به طور گسترده پیامها، پارامترهای خط درخواست و محدودیتهای مقدار آنها، و همچنین انواع فیلدهای هدر و محدودیتهای مقدار آنها را پوشش میدهد MSFuzz با ادغام این درخت نحو در اعلانهای ما، LLMها را قادر میسازد تا سیدهای جامعتری تولید کنند.
در مورد مسئله دوم، فایلهای پیکربندی برای پیادهسازی پروتکل معمولاً حاوی اطلاعات حیاتی سرور مانند نامهای کاربری، رمزهای عبور و آدرسهای شبکه هستند. ادغام این فایلهای پیکربندی در اعلانهای LLM امکان تولید بذرهای دقیقتری را فراهم میکند که منعکسکننده محیط عملیاتی هستند. در مورد مسئله سوم، یک LLM مهارت خود را در یادگیری از دادههای ارائه شده و تولید خروجیهای استاندارد نشان میدهد. با وارد کردن بذرهای اولیه از پیادهسازی پروتکل به اعلانها و تعریف فرمت آنها، این امر تولید بذرهای قابل خواندن توسط ماشین را که بلافاصله برای فازینگ قابل استفاده هستند، تسهیل میکند.
شکل 6 اعلانی را که توسط MSFuzz برای گسترش مجموعه بذر با استفاده از LLMها استفاده میشود، نشان میدهد. اعلانهای نمایش داده شده در شکل 6 شامل درخت نحوی پیام پیادهسازی پروتکل هدف، فایل پیکربندی و مجموعه بذر اولیه هستند که به صراحت LLM را برای تولید خروجیهایی که به فرمت مجموعه بذر اولیه پایبند هستند، هدایت میکنند.

۳.۴ فازینگ با جهش آگاه از نحو
اگرچه MSFuzz یک درخت نحوی پیام از پیادهسازی پروتکل میسازد، اما هنگام استفاده از این درخت نحوی برای جهش پیام با دو مشکل اساسی مواجه میشود:
- چگونه مکانهای جهش را برای حفظ ساختار نحوی اولیه پیام انتخاب کنیم؟
- چگونه از درخت نحوی پیام برای هدایت دقیق جهشها استفاده کنیم؟
ما برای حل این مشکلات، یک رویکرد فازینگ آگاه از نحو (Syntax-Aware Fuzzing) طراحی کردیم که جزئیات آن در الگوریتم ۱ ارائه شده است. بهطور مشخص، MSFuzz ابتدا سعی میکند پیام را پارس کند تا ساختار نحو پایهای آن (Basic Syntax Structure) را بهدست آورد (خط ۷). پس از آنکه پیام در برابر درخت نحو پیام (Syntax Tree) بررسی شد (خط ۹)، MSFuzz یک فیلد را بهصورت تصادفی برای جهش انتخاب میکند (خط ۱۱). سپس، بر اساس محدودیتهای مقداری آن فیلد در درخت نحو پیام، جهشها اعمال میشوند (خطوط ۱۲–۱۳).
تجزیه پیام (Message parsing). قبل از جهش پیامها، شناسایی دقیق مکانهای مناسب جهش بسیار مهم است. انتخاب تصادفی مکانهای جهش میتواند ساختار اساسی پیام را مختل کند و آن را بیاثر کند. بنابراین، بر اساس ساختار کلی نحو پیام که در شکل 3 نشان داده شده است، MSFuzz پیام تعیین شده برای جهش را تجزیه میکند. در ابتدا، MSFuzz خط درخواست را برای تعیین نوع پیام و فیلدهای پارامتر خط درخواست تجزیه و تحلیل میکند و جابجاییهای این فیلدها را ثبت میکند. متعاقباً، MSFuzz نامها و مقادیر فیلدهای سرآیند را تجزیه و تحلیل و جابجاییهای آنها را نیز یادداشت میکند. MSFuzzدر طول جهش، موقعیتهایی را در فیلدهای پارامتر خط درخواست یا فیلدهای سرآیند انتخاب میکند تا یکپارچگی ساختار نحوی اساسی پیام را حفظ کند.
جهش هدایت شده توسط نحو (Syntax-guided mutation). برای هدایت جهش پیام با استفاده از درخت نحو، ابتدا لازم است مشخص شود که آیا نوع پیام در درخت نحو وجود دارد یا خیر. اگر نوع پیام وجود نداشته باشد، یک استراتژی جهش تصادفی اعمال میشود. اگر نوع پیام در درخت نحو یافت شود، یک فیلد پارامتر خط درخواست یا یک فیلد سرآیند به طور تصادفی به عنوان هدف جهش انتخاب میشود.
در مرحله بعد، محدودیتهای فیلد انتخابشده از درخت نحوی شناسایی میشوند. یکی از این محدودیتها به صورت تصادفی انتخاب میشود و مقداری که به این محدودیت پایبند است، برای جایگزینی مقدار فیلد اصلی تولید میشود. اگر مقدار فیلد جدید تولید شده از نظر طول با مقدار فیلد اصلی متفاوت باشد، جابجایی فیلدهای بعدی تنظیم میشود تا اطمینان حاصل شود که هر فیلد در پیام تغییر یافته، جابجایی صحیح خود را حفظ میکند.
برای اطمینان از اینکه MSFuzz قابلیت بررسی سناریوهای حدی ((Extreme Scenarios Exploration)) را دارد، ما با احتمال معینی از یک راهبرد جهش تصادفی (Random Mutation Strategy) نیز استفاده کردیم.
به عنوان مثال، یک پیام PLAY را در نظر بگیرید که به ساختار نحوی در شکل 1 پایبند است و توسط درخت نحوی پیام در شکل 5 به جهش هدایت میشود. ابتدا، تأیید میشود که آیا نوع پیام PLAY در درخت نحوی Live555 وجود دارد یا خیر. همانطور که در شکل 5 نشان داده شده است، این نوع ساختار نحوی پیام وجود دارد. در مرحله بعد، یک فیلد در پیام PLAY به صورت تصادفی انتخاب میشود، مانند فیلد Range. محدودیتهای مقدار فیلد سرآیند Range در درخت نحوی پیام جستجو میشوند و یکی به صورت تصادفی انتخاب میگرددد، مانند: npt = %lf – %lf.
این محدودیت مقدار، محدوده پخش را بر حسب ثانیه مشخص میکند، که در آن %lf نشان دهنده یک عدد ممیز شناور است که زمان شروع و پایان را نشان میدهد. سپس MSFuzz نوع داده متغیرهای موجود در فیلد را شناسایی میکند که در این مورد، اعداد ممیز شناور هستند. برای تولید یک مقدار تصادفی که با این نوع مطابقت داشته باشد، MSFuzz از یک تابع تولید عدد ممیز شناور استفاده میکند. به عنوان مثال، ممکن است به ترتیب 10.5 و 20.0 را برای زمانهای شروع و پایان تولید کند و آنها را به صورت npt = 10.5 – 20.0 قالببندی نماید. در نهایت، MSFuzz مقدار اصلی را در فیلد Range با مقدار تازه تولید شده جایگزین و اطمینان حاصل میکند که پیام اصلاح شده به محدودیتهای نحوی مشخص شده در درخت نحوی پیام پایبند است. پس از جایگزینی مقدار، MSFuzz انحراف هر فیلد در پیام را تنظیم میکند. این تنظیم برای حفظ یکپارچگی ساختاری پیام بسیار مهم است، زیرا تغییر طول یک فیلد میتواند بر موقعیت فیلدهای بعدی تأثیر بگذارد. با دنبال کردن این فرآیند، MSFuzz میتواند موارد آزمایشی تولید کند که به محدودیتهای نحوی پایبند باشند و در نتیجه اعتبار پیامهای تولید شده را تضمین کند.
الگوریتم ۱. فازینگ با جهش آگاه از نحو (Syntax-Aware Mutation):
Input: P: protocol implementation
Input: E: expanded seeds
Input: T: message syntax tree
Output: Cx: crash reports
struct Field { type;values }
struct Message { type;params;headers }
StateMachine S ← ∅
repeat
Seed M ← StateGuidedSeedChoice(S, E)
⟨M1, M2, M3⟩ ← Split(M)
Message m ← ParseMessage(T, M2)
for i ← 1 to AssignEnergy(M) do
if m.type ∈ T then
Field f ield
f ield ← Choice(m.params, m.headers)
if f ield.type ∈ T and Rand() < ε then
M′2 ← FieldMutate( f ield, T)
M′ ← ⟨M1, M′, M3⟩
else
M′2 ← RandomMutate(M2, T)
M′ ← ⟨M1, M′2, M3⟩
end if
else
M′2 ← RandomMutate(M2, T)
M′ ← ⟨M1, M′2, M3⟩
end if
Response R′ ← SendToServer(P, M′)
if IsCrash(M′, P) then
Cx ← Cx ∪ {M′}
end if
if IsInteresting(M′, P, S) then
E ← E ∪ {(M′, R′)}
S ← UpdateStateMachine(S, R′)
end if
end for
until timeout reached or abort-signal
۴. ارزیابی
در این بخش، عملکرد MSFuzz را ارزیابی و با فازرهای پروتکل SOTA مقایسه میکنیم. هدف ما پاسخ به سوالات تحقیقاتی زیر با ارزیابی MSFuzz است.
RQ1. پوشش حالت: آیا MSFuzz میتواند به پوشش فضای حالت بالاتری نسبت به فازرهای SOTA دست یابد؟
RQ2. پوشش کد: آیا MSFuzz میتواند به پوشش فضای کد بالاتری نسبت به فازرهای SOTA دست یابد؟
RQ3. مطالعه حذف: تأثیر دو مؤلفه کلیدی بر عملکرد MSFuzz چه بود؟
RQ4. کشف آسیبپذیری: آیا MSFuzz میتواند آسیبپذیریهای بیشتری نسبت به فازرهای SOTA کشف کند؟
۴.۱ راهاندازی آزمایشی
پیادهسازی. ما با تکیه بر چارچوب فازینگ پروتکل پرکاربرد AFLNET، ابزار MSFuzz را توسعه دادیم. پیادهسازی MSFuzz شامل حدود ۱٫۲ هزار خط کد به زبان C++/C و ۸۰۰ خط کد پایتون است. بهطور مشخص، یک اسکریپت پایتون توسعه دادیم که با مدل زبانی بزرگ (LLM) تعامل برقرار میکند تا نحو پیام پیادهسازیهای پروتکل شبکه را استخراج کرده و درختهای نحو پیام را ایجاد نماید.
بهمنظور کاهش مشکلات احتمالی ناشی از ناقصبودن یا ناسازگاری نحو استخراجشده توسط LLM، فرآیند استخراج را سه بار تکرار کرده و از اجتماع (Union) نتایج برای ساخت درخت نحو پیام استفاده کردیم.
در ادامه، با بهرهگیری از مجموعه بذر اولیه (Initial Seed Corpus) و درخت نحو پیام، مجموعه بذرها را با استفاده از LLM گسترش دادیم. بخش عمدهی جهش آگاه از نحو (Syntax-Aware Mutation) در فاز جهش حلقه فازینگ و بر اساس درخت نحو پیام ساختهشده، به زبان C پیادهسازی شد.
روش بهبود فازینگ پروتکل در MSFuzz وابسته به یک LLM خاص نیست و میتوان از چندین مدل زبانی بزرگ رایج موجود در بازار استفاده کرد. در این پژوهش، ما Qwen-plus را بهعنوان LLM برای استخراج نحو و گسترش بذرها انتخاب کردیم؛ چرا که یکی از پیشرفتهترین مدلهای زبانی ازپیشآموزشدیدهی موجود محسوب میشود. این مدل دارای پارامترهایی در مقیاس تریلیون بوده و بر روی مجموعهدادهای گسترده و متنوع شامل کدهای نرمافزاری و مستندات فنی آموزش دیده است. چنین آموزش گستردهای، این مدل را به قابلیتهای عمیق درک و تولید زبان مجهز کرده و امکان فهم ساختار منطقی و معناشناسی کد منبع را برای آن فراهم میسازد. افزون بر این، این مدل تعداد قابلتوجهی توکن رایگان در اختیار قرار میدهد که انجام آزمایشها و کاربردهای گستردهتر را تسهیل میکند.
برای پیکربندی پارامترهای ورودی LLM، از تنظیمات پیشفرض استفاده کردیم؛ از جمله:
- max_token = 2000
- top_p = 0.8
معیار. جدول ۱ اطلاعات جزئی و دقیق مربوط به پیادهسازیهای پروتکل شبکه که در ارزیابی عملکرد MSFuzz استفاده شدهاند را ارائه میدهد. معیار ما شامل پنج پیادهسازی پروتکل شبکه است که شامل سه پروتکل پرکاربرد میباشد: RTSP،FTP و DAAP. این پروتکلها از قالبهای متنی برای ارتباط استفاده میکنند و بخشی از معیار فازینگ پروتکل شناخته شده ProFuzzBench [22] هستند. با توجه به کاربرد گسترده آنها، ما این پنج برنامه هدف را نماینده برنامههای دنیای واقعی در نظر میگیریم.

معیار پایه. ما یک مقایسه جامع و دقیق بین MSFuzz و فازرهای پیشرفته شبکه (State-of-the-Art, SOTA)، شامل AFLNET و CHATAFL انجام دادیم.
- AFLNET، بهعنوان اولین فازر Grey-box یا جعبه خاکستری طراحیشده برای پیادهسازیهای پروتکل شبکه، عمدتاً بر روشهای تولید مبتنی بر جهش (Mutation-Based Generation) متکی است.
- CHATAFL، یکی از فازرهای Grey-box پیشرفته (SOTA)، از مدلهای زبانی بزرگ (LLMs) برای گسترش بذرها (Seed Expansion)، استخراج ساختار پیامها (Message Structures) و هدایت جهشها (Guiding Mutation) استفاده میکند.
محیط. تمام آزمایشها بر روی سروری با سیستم عامل ۶۴ بیتی Ubuntu 20.04 اجرا شدند، که مجهز به دو پردازنده Intel(R) Xeon(R) E5-2690 با فرکانس ۲.۹۰ گیگاهرتز و ۱۲۸ گیگابایت حافظه RAM بود.
هر پیادهسازی پروتکل انتخاب شده و هر فازر، بهصورت جداگانه در کانتینرهای Docker مجزا راهاندازی شدند و همان منابع محاسباتی برای ارزیابی تجربی آنها تخصیص یافت.
برای اطمینان از عدالت و صحت نتایج آزمایشها، هر فازر به مدت ۲۴ ساعت برای هر پیادهسازی پروتکل اجرا شد و این آزمایشها پنج بار تکرار شدند.
۴.۲ پوشش وضعیت (State coverage)
پوشش حالت (State Coverage) یک معیار ارزیابی حیاتی در فازینگ پروتکلهای شبکه است، زیرا نشاندهندهی عمق کاوش در ماشین حالت پروتکل (Protocol State Machine) و میزان بررسی منطق داخلی پیادهسازی پروتکل میباشد.
با اندازهگیری تعداد حالتهای دستیافته شده (Number of States Reached) و تعداد انتقالهای حالت (Number of State Transitions) در طول فازینگ، میتوان بهطور مؤثر ارزیابی کرد که آیا فازر به طور کامل حالتهای مختلف پیادهسازی پروتکل و انتقالهای بین آنها را کاوش کرده است یا خیر.
جدول 2 میانگین تعداد حالتها و انتقالهای حالت پوشش داده شده توسط فازرهای مختلف را در طول پنج بار فازینگ 24 ساعته ارائه میدهد. برای ارزیابی عملکرد MSFuzz، درصد بهبود در پوشش حالت و انتقال حالت را در 24 ساعت گزارش میدهیم (بهبود). نتایج نشان میدهد که در مقایسه با AFLNET و CHATAFL، MSFuzz مزایای قابل توجهی در کشف حالتها و انتقالهای حالت جدید نشان داده است.
به طور خلاصه، MSFuzz به طور متوسط بهبودهای 22.53٪ و 10.04٪ را در تعداد حالتها در مقایسه با AFLNET و CHATAFL به ترتیب به دست آورد. علاوه بر این، بهبودهای 60.62٪ و 19.52٪ در انتقال حالتها وجود داشت. در مقایسه با سایر پیادهسازیهای پروتکل، بهبود پوشش حالت برای LightFTP کمترین اهمیت را داشت. دلیل این امر این بود که LightFTP یک پیادهسازی پروتکل FTP سبک با عملکرد ساده و حداقل پایگاه کد است. فاقد انتقال حالتهای پیچیده و عمیق است که منجر به بهبودهای نسبتاً جزئی در پوشش حالت میشود.
توجه: ردیف AVG به صورت پررنگ برجسته شده است تا میانگین درصد بهبود را در تمام موارد برای حالتها و انتقال حالتها نشان دهد.
به طور خلاصه، MSFuzz میتواند پوشش حالت بالاتری نسبت به فازرهای SOTA به دست آورد. MSFuzz نه تنها حالتهای جدید بیشتری را کشف کرد، بلکه انتقال حالتهای بیشتری نیز ایجاد کرد و در نتیجه اثربخشی و جامعیت فازینگ را افزایش داد. MSFuzz با کاوش عمیقتر در فضای حالت، مزایای قابل توجهی را در زمینه فازینگ پروتکل نشان داد.
۴.۳ پوشش کد (Code Coverage)
پوشش کد (Code Coverage) همواره بهعنوان معیار استاندارد برای ارزیابی فازرها مورد استفاده قرار گرفته است و نشاندهندهی میزان اجرای کد در پیادهسازی پروتکل طی کل فرآیند فازینگ است. پوشش کد، بهعنوان یک معیار ارزیابی، ابزار مؤثری برای سنجش عملکرد فازرها فراهم میکند و میزان اثربخشی آنها در کشف بخشهای مختلف کد را منعکس میسازد.
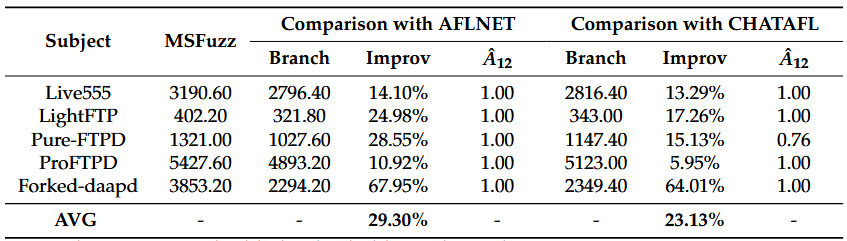
ما برای ارزیابی عملکرد MSFuzz، درصد بهبود پوشش شاخههای کد در بازه ۲۴ ساعته (Improv) را گزارش دادیم و احتمال برتری MSFuzz نسبت به فعالیتهای پایه (Baseline Activities) را با استفاده از آمار Vargha–Delaney بر اساس فعالیتهای تصادفی تحلیل کردیم.
جدول ۳، میانگین پوشش شاخههای کد را که توسط هر فازر طی پنج دوره فازینگ ۲۴ ساعته به دست آمده است، نشان میدهد.
نتایج نشان میدهند که MSFuzz در تمام پنج پیادهسازی پروتکل، پوشش شاخههای کد بالاتری نسبت به AFLNET و CHATAFL به دست آورده است، که اثربخشی روش پیشنهادی ما در بهبود پوشش کد را تأیید میکند.
بهطور مشخص:
- MSFuzz در مقایسه با AFLNET، بهطور متوسط ۲۹.۳۰٪ بهبود در پوشش شاخههای کد نشان داد.
- در مقایسه با CHATAFL، بهطور متوسط ۲۳.۱۳٪ بهبود مشاهده شد.
برای همه پیادهسازیهای پروتکل، اندازه اثر Vargha-Delaney (Aˆ12 ≥ 0.76) نشاندهنده مزیت قابل توجه MSFuzz در بررسی پوشش شاخه کد نسبت به فازرهای پایه (Baseline Fuzzers) است.
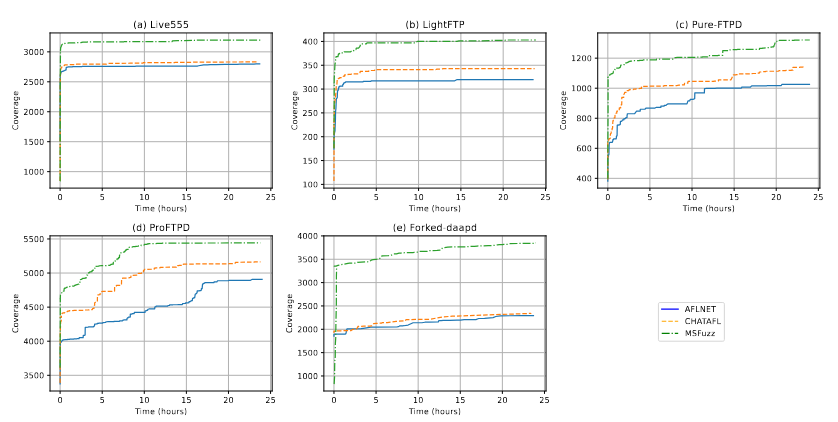
برای تأیید بیشتر اثربخشی MSFuzz، ما میانگین تعداد شاخههای کد کاوش شده توسط فازرهای مختلف را طی پنج اجرای ۲۴ ساعته تحلیل کرده و نتایج را در شکل ۷ ارائه دادیم. همانطور که در شکل مشاهده میشود، MSFuzz نه تنها بالاترین پوشش کد را در مقایسه با سایر فازرها به دست آورد، بلکه بالاترین سرعت کاوش را نیز نشان داد. شایان ذکر است که بهبودها در پیادهسازیهای Pure-FTPD و Forked-daapd بیشترین مقدار را داشتند.
4.4 مطالعهی جداسازی (Ablation Study)
MSFuzz از یک مدل زبانی بزرگ (LLM) برای استخراج نحو پیامها از کد منبع پیادهسازی پروتکلها استفاده میکند و بر اساس آن درختهای نحو پیام (Message Syntax Trees) را میسازد. با بهرهگیری از این درختها، دو استراتژی برای تولید نمونههای آزمون باکیفیت که محدودیتهای نحوی را رعایت میکنند به کار گرفته شد و عملکرد فازینگ ارتقا یافت:
- گسترش مجموعه بذرها (Seed Expansion): با استفاده از LLM و درخت نحو استخراجشده، مجموعه بذر اولیه پیادهسازی پروتکل گسترش یافته و بدین ترتیب تنوع و جامعیت بذرها افزایش یافت.
- جهش آگاه از نحو (Syntax-Aware Mutation): یک استراتژی جهش نوآورانه معرفی شد که درختهای نحو پیام ساختهشده را برای هدایت فرآیند جهش در طول فازینگ به کار میگیرد.
ما برای سنجش کمی (Quantitative) سهم هر استراتژی در عملکرد کلی MSFuzz، یک مطالعهی جداسازی اثر (Ablation Study) انجام دادیم. در این مطالعه، سه ابزار مورد ارزیابی قرار گرفتند:
ابزارهای مورد ارزیابی عبارت بودند از:
- AFLNET: با غیرفعال بودن تمام استراتژیها،
- STFuzz-E: با فعال بودن تنها استراتژی گسترش بذر (Seed Expansion)،
- MSFuzz: با فعال بودن هر دو استراتژی، شامل گسترش بذر و جهش آگاه از نحو (Syntax-Aware Mutation).
نتایج آزمایشها در جدول ۴ ارائه شده است. ما عملکرد سه ابزار را طی پنج اجرای ۲۴ ساعته فازینگ ارزیابی کردیم، بهویژه با اندازهگیری میانگین بهبود تعداد حالتها (States)، انتقالهای حالت (State Transitions) و درصد بهبود پوشش شاخههای کد (Code Branch Coverage) توسط هر فازر.
نتایج نشان میدهند که هر دو استراتژی پیادهسازیشده در MSFuzz باعث افزایش تعداد حالتها، انتقالهای حالت و پوشش شاخههای کد در سطوح مختلف شدند و این بهبودها بدون تأثیر منفی بر هیچ یک از این معیارها بوده است.
توجه: ردیف AVG به صورت پررنگ برجسته شده است تا میانگین درصد بهبود در تمام موارد برای حالتها، انتقالها و پوشش شاخهها را نشان دهد.
نتایج تجربی AFLNET و MSFuzz-E نشان میدهد که بهکارگیری استراتژی گسترش بذر (Seed)، تعداد حالتها را 19.31٪، انتقالهای حالت را 45.09٪ و پوشش شاخههای کد را 25.19٪ افزایش داده است. این نشان دهنده اثربخشی استراتژی گسترش بذر است که کیفیت و تنوع بذرها را افزایش داده است. با اطمینان از اینکه بذرهای گسترش یافته به طور جامع نحو پیام پیادهسازی پروتکل را پوشش میدهند، این استراتژی به طور قابل توجهی کاوش فازی فضای حالت و فضای کد را بهبود بخشیده است.
همانطور که در نتایج MSFuzz-E و MSFuzz نشان داده شده است، گنجاندن استراتژی جهش آگاه از نحو در کنار استراتژی گسترش بذر، سه معیار ارزیابی را بیشتر بهبود بخشیده است. بهبود در تعداد حالتها از ۱۹.۳۱٪ به ۲۲.۵۳٪ افزایش یافت، بهبود در انتقال حالتها از ۴۵.۰۹٪ به ۶۰.۶۲٪ افزایش یافت و بهبود در پوشش شاخه کد از ۲۵.۱۹٪ به ۲۹.۳۰٪ افزایش یافت. این نشاندهنده اثربخشی استراتژی جهش آگاه از نحو است که تضمین میکند موارد آزمایشی تولید شده پس از جهش به محدودیتهای نحوی پروتکل پایبند باشند. این استراتژی مانع از آن شد که سرور آنها را در طول مرحله اولیه بررسی نحو کنار بگذارد و در نتیجه فرصت بررسی پیادهسازی پروتکل را افزایش دهد. تجزیه و تحلیل سربار زمانی و مصرف منابع مرتبط با استراتژیهای گسترش بذر و جهش آگاه از نحو نشان داد که این استراتژیها نه سرعت اجرا را کاهش میدهند و نه مصرف منابع قابل توجهی ایجاد میکنند.
ساخت درختهای نحوی پیام و گسترش مجموعه بذر در طول مرحله آمادهسازی انجام شد و فقط یک بار اجرا شد، بنابراین به سربار زمانی و مصرف منابع فازینگ پروتکل کمکی نکرد. اگرچه جهش آگاه از نحو در طول فرآیند فازینگ انجام شد، اما توانست موارد آزمایشی ایجاد کند که به محدودیتهای پروتکل پایبند باشند و در نتیجه از زمان و ناکارآمدی قابل توجه مرتبط با جهشهای تصادفی سنتی جلوگیری کنند. این امر منجر به بهبود قابل توجهی در راندمان کلی آزمایش شد. همانطور که در جدول 4 نشان داده شده است، دادههای تجربی برای MSFuzz-E و MSFuzz این نتیجهگیری را اثبات میکنند.
4.5 کشف آسیبپذیری
به منظور ارزیابی عملکرد MSFuzz در کشف آسیبپذیریها، ما تعداد کرشهای یکتا (Unique Crashes) ایجاد شده توسط MSFuzz و فازرهای پیشرفته (SOTA) را مقایسه کردیم.
در طول پنج اجرای ۲۴ ساعته فازینگ، هیچ کرشی توسط AFLNET یا CHATAFL در میان پنج پیادهسازی پروتکل هدف ایجاد نشد. اما MSFuzz توانست کرشهایی در دو پیادهسازی پروتکل کشف کند:
- MSFuzz در LightFTP، تعداد ۹۱ کرش یکتا را شناسایی کرد.
- MSFuzz در Forked-daapd، تعداد ۲۷ کرش یکتا را شناسایی کرد.
قابل ذکر است که تاکنون تحلیل دقیقی از ۱۶ کرش انجام شده و دو آسیبپذیری جدید شناسایی شدهاند که به پایگاه داده Common Vulnerabilities and Exposures (CVE) گزارش شدهاند.
این نتایج آزمایشگاهی، عملکرد برتر MSFuzz در کشف و شناسایی آسیبپذیریهای نرمافزاری را تأیید میکنند. تفاوت در توانایی کشف کرش میان فازرهای مختلف در بازه زمانی مشابه، مزایای چشمگیر MSFuzz در افزایش کارایی فازینگ و کشف آسیبپذیریها را برجسته میسازد.
۵. بحث
اگرچه MSFuzz در مقایسه با فازرهای پیشرفته (SOTA) عملکرد خوبی در پوشش حالت (State Coverage)، پوشش کد (Code Coverage) و کشف آسیبپذیریها داشته است، اما همچنان محدودیتهایی دارد:
- چالش در کاربرد برای پیادهسازیهای پروتکل مبتنی بر باینری (Difficulty in applying to binary-based protocol implementations): پروتکلهای باینری دارای نمایش داده بسیار فشرده هستند و مرزهای فیلدها اغلب بهوضوح تعریف نشدهاند. این پروتکلها برچسب یا مارکر صریحی برای شروع و پایان هر فیلد ندارند، که تشخیص معنای دقیق و موقعیت هر فیلد هنگام پارس کد را دشوار میکند. این ابهام در تعیین مرز فیلدها، فرآیند استخراج و تفسیر پیامهای پروتکل را پیچیده میسازد و ساخت دقیق درخت نحو پیامها (Message Syntax Tree) را با مشکل مواجه میکند.
علاوه بر این، تنوع ساختاری در پروتکلهای باینری نیازمند رویکردهای پیچیدهتر برای مدیریت جزئیات هر پیادهسازی است، که یک چالش جدی برای ابزارهایی مانند MSFuzz محسوب میشود که بر مرزبندی واضح نحو متکی هستند. - محدودیت ظرفیت ورودی مدلهای زبانی بزرگ (Input capacity limitations of LLMs): اگرچه MSFuzz توابع کلیدی فیلترشده از کد را به LLM ارائه میدهد تا درک نحو پیام را بهبود بخشد، اما در برخی موارد اندازه کد توابع ممکن است از محدودیت ورودی LLM فراتر رود. این موضوع میتواند موجب چالش در پردازش حجم بالای کد شود، زیرا LLM ممکن است توانایی حفظ زمینه و دقت خود را هنگام مدیریت دادههای ورودی زیاد از دست بدهد.
محدودیت ظرفیت ورودی میتواند باعث تحلیل ناقص و از دست رفتن اطلاعات حیاتی شود که برای فازینگ مؤثر لازم است. در نتیجه، کارایی و اثربخشی MSFuzz ممکن است کاهش یابد، زیرا LLM ممکن است نتواند تمام جزئیات و ظرافتهای پیادهسازی پروتکل را بهطور کامل درک کند.
به همین دلیل، برنامهریزی ما در کارهای آتی بر بهینهسازی کد با حذف محتوای غیرمرتبط با نحو در توابع متمرکز خواهد شد تا کارایی پردازش LLMها افزایش یابد.
6. کارهای مرتبط
6.1 فازینگ آگاه از نحو
در فازینگ پروتکلها، درک نحو پیامها (Message Syntax) امری ضروری است [15]. فازرهای آگاه از نحو (Syntax-Aware Fuzzers) تلاش میکنند تا نحو دقیق پیامهای پیادهسازی پروتکلها را درک کنند، که این امکان را فراهم میآورد تا نمونههای آزمون مؤثرتری تولید شود.
برخی ابزارها و رویکردها عبارتند از:
- Peach [31] و KIF [7]: نحو را بهصورت دستی از مستندات RFC عمومی پروتکلها استخراج میکنند. این روش زمان زیادی از پژوهشگران میگیرد و برای پروتکلهای اختصاصی بدون مستندات عمومی قابل استفاده نیست.
- AspFuzz [8]: از زبان تخصصی برای توصیف مستندات RFC استفاده میکند تا نحو پروتکل را استخراج نماید.
- PULSAR [39] و Bbuzz [40]: نحو پیامها را از ترافیک شبکه با استفاده از روشهای مهندسی معکوس پروتکل استخراج میکنند.
- Polyglot [41]: از تکنیکهای تحلیل پویا (Dynamic Analysis) برای استخراج نحو پیام از لاگهای رفتار برنامه استفاده میکند.
- Polar [19]: از تحلیل استاتیک و تحلیل پویا مبتنی بر تریت (Dynamic Taint Analysis) برای استخراج نحو مرتبط با کارکردهای پروتکل بهره میبرد.
بهطور کلی، فازرهای آگاه از نحو پروتکل موجود فاقد درک جامع از نحو پیامها هستند و معمولاً تنها قادر به استخراج بخشهایی محدود از فیلدهای ساختار نحوی پیام میباشند. در مقابل، MSFuzz توانایی استخراج نحو پیام بهصورت دقیقتر، غنیتر و جامعتر از پیادهسازیهای پروتکل را دارد. افزون بر این، با بهرهگیری از گسترش مجموعه بذرها (Seed Expansion) و جهش آگاه از نحو (Syntax-Aware Mutation)، کارایی و اثربخشی فرآیند فازینگ را بهطور قابل توجهی افزایش میدهد.
6.2 فازینگ بر اساس مدلهای زبان بزرگ
در سالهای اخیر، مدلهای زبان بزرگ (LLM) محبوب، اثربخشی قابل توجهی در پردازش زبان طبیعی نشان دادهاند. محققان تلاش کردهاند تا LLMها را در فازینگ ادغام کنند تا عملکرد روشهای فازینگ سنتی را افزایش دهند. CHATAFL [10] یک فازینگ پروتکل مبتنی بر LLM است که ساختار نحوی پیامهای درخواست را میسازد و پیام بعدی را در دنباله با استفاده از LLMها پیشبینی میکند. Codamosa [42] از LLMها برای رفع مشکل پوشش کد راکد در فازینگ سنتی استفاده میکند. FuzzGPT [43] از مدلهای CodeX و CodeGen برای تولید خودکار برنامههای غیرعادی بر اساس مفاهیم اصلی استفاده میکند و از این طریق کتابخانههای یادگیری عمیق را فازینگ میکند. بینش کلیدی این است که برنامههای ایجاد اشکال تاریخی ممکن است شامل اجزای کد نادر یا ارزشمندی باشند که برای یافتن اشکال مهم هستند. KernelGPT [44] از LLMها برای استنباط خودکار مشخصات Syzkaller برای افزایش فازینگ هسته استفاده میکند. همه این کارها به دانش کسب شده توسط LLMها در طول پیشآموزش روی دادههای در مقیاس بزرگ متکی هستند. در مقابل، وقتی MSFuzz نحو پیام پیادهسازیهای پروتکل را استخراج میکند، قطعه کدهای منبع مربوطه را به LLMها ارائه میدهد. سپس LLM بر اساس این قطعه کدها، استخراج نحو را انجام میدهد و در نتیجه خروجیهای قابل اعتمادتری تولید میکند.
7. نتیجهگیری
در این مقاله، ما MSFuzz را معرفی کردیم که یک روش فازینگ پروتکل جدید با درک نحو پیام است. MSFuzz ابتدا قطعات کلیدی کد (Key Code Snippets) را از کد منبع پیادهسازی پروتکل استخراج میکند و با بهرهگیری از تواناییهای درک کد مدلهای زبانی بزرگ (LLMs)، نحو پیامها را استخراج کرده و درختهای نحو پیام (Message Syntax Trees) را میسازد.
این درختهای نحو سپس برای گسترش مجموعه بذرها (Seed Corpus) و هدایت فرآیند جهش بذرها (Seed Mutation) مورد استفاده قرار میگیرند که موجب بهبود کیفیت نمونههای آزمون و در نتیجه افزایش کارایی و اثربخشی فازینگ میشوند.
نتایج ارزیابی تجربی نشان داد که MSFuzz از فازینگهای پروتکل SOTA عملکرد بهتری دارد. به طور خاص، در مقایسه با AFLNET و CHATAFL، MSFuzz به طور متوسط به بهبود ۲۲.۵۳٪ و ۱۹.۵۲٪ در تعداد حالتها، ۶۰.۶۲٪ و ۱۰.۰۴٪ در تعداد انتقال حالتها و ۲۹.۳۰٪ و ۲۳.۱۳٪ در پوشش شاخهها دست یافت. علاوه بر این، MSFuzz تعداد بیشتری از آسیبپذیریها را نسبت به فازرهای پیشرفته کشف میکند.
8. منابع
Hermann, H.; Johnson, R.; Engel, R. A framework for network protocol software. In Proceedings of the OOPSLA ‘95, ACM SIGPLAN Notices, Austin, TX, USA, 15–19 October 1995. [Google Scholar]
Yazdinejad, A.; Dehghantanha, A.; Parizi, R.M.; Srivastava, G.; Karimipour, H. Secure Intelligent Fuzzy Blockchain Framework: Effective Threat Detection in IoT Networks. Comput. Ind. 2023, 144, 103801. [Google Scholar] [CrossRef]
Serebryany, K. OSS-Fuzz-Google’s Continuous Fuzzing Service for Open Source Software; USENIX: Vancouver, BC, Canada, 2017. [Google Scholar]
Xu, M.; Kashyap, S.; Zhao, H.; Kim, T. Krace: Data race fuzzing for kernel file systems. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1643–1660. [Google Scholar]
Jero, S.; Pacheco, M.L.; Goldwasser, D.; Nita-Rotaru, C. Leveraging textual specifications for grammar-based fuzzing of network protocols. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9478–9483. [Google Scholar]
Banks, G.; Cova, M.; Felmetsger, V.; Almeroth, K.; Kemmerer, R.; Vigna, G. SNOOZE: Toward a Stateful NetwOrk prOtocol fuzZEr. In Proceedings of the Information Security: 9th International Conference, ISC 2006, Samos Island, Greece, 30 August–2 September 2006; Proceedings 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 343–358. [Google Scholar]
Miki, H.; Setou, M.; Kaneshiro, K.; Hirokawa, N. All kinesin superfamily protein, KIF, genes in mouse and human. Proc. Natl. Acad. Sci. USA 2001, 98, 7004–7011. [Google Scholar] [CrossRef] [PubMed]
Kitagawa, T.; Hanaoka, M.; Kono, K. A state-aware protocol fuzzer based on application-layer protocols. IEICE Trans. Inf. Syst. 2011, 94, 1008–1017. [Google Scholar] [CrossRef]
Rontti, T.; Juuso, A.M.; Takanen, A. Preventing DoS attacks in NGN networks with proactive specification-based fuzzing. IEEE Commun. Mag. 2012, 50, 164–170. [Google Scholar] [CrossRef]
Meng, R.; Mirchev, M.; Böhme, M.; Roychoudhury, A. Large language model guided protocol fuzzing. In Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 26 February–1 March 2024. [Google Scholar]
Cui, W.; Kannan, J.; Wang, H.J. Discoverer: Automatic Protocol Reverse Engineering from Network Traces. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 6–10 August 2007; pp. 1–14. [Google Scholar]
Beddoe, M.A. Network protocol analysis using bioinformatics algorithms. Toorcon 2004, 26, 1095–1098. [Google Scholar]
Cui, W.; Paxson, V.; Weaver, N.; Katz, R.H. Protocol-independent adaptive replay of application dialog. In Proceedings of the NDSS, San Diego, CA, USA, 2–3 February 2006. [Google Scholar]
Sun, Y.; Lv, S.; You, J.; Sun, Y.; Chen, X.; Zheng, Y.; Sun, L. IPSpex: Enabling efficient fuzzing via specification extraction on ICS protocol. In Proceedings of the International Conference on Applied Cryptography and Network Security, Rome, Italy, 20–23 June 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 356–375. [Google Scholar]
Comparetti, P.M.; Wondracek, G.; Kruegel, C.; Kirda, E. Prospex: Protocol specification extraction. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Oakland, CA, USA, 17–20 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 110–125. [Google Scholar]
Lin, Z.; Jiang, X.; Xu, D.; Zhang, X. Automatic protocol format reverse engineering through context-aware monitored execution. In Proceedings of the NDSS, San Diego, CA, USA, 10–13 February 2008; Volume 8, pp. 1–15. [Google Scholar]
Wondracek, G.; Comparetti, P.M.; Kruegel, C.; Kirda, E.; Anna, S.S.S. Automatic Network Protocol Analysis. In Proceedings of the NDSS, San Diego, CA, USA, 10–13 February 2008; Volume 8, pp. 1–14. [Google Scholar]
Cui, W.; Peinado, M.; Chen, K.; Wang, H.J.; Irun-Briz, L. Tupni: Automatic reverse engineering of input formats. In Proceedings of the 15th ACM conference on Computer and Communications Security, Alexandria, VA, USA, 27–31 October 2008; pp. 391–402. [Google Scholar]
Luo, Z.; Zuo, F.; Jiang, Y.; Gao, J.; Jiao, X.; Sun, J. Polar: Function code aware fuzz testing of ics protocol. ACM Trans. Embed. Comput. Syst. (TECS) 2019, 18, 1–22. [Google Scholar] [CrossRef]
Hu, Z.; Shi, J.; Huang, Y.; Xiong, J.; Bu, X. Ganfuzz: A gan-based industrial network protocol fuzzing framework. In Proceedings of the 15th ACM International Conference on Computing Frontiers, Ischia, Italy, 8–10 May 2018; pp. 138–145. [Google Scholar]
Zhao, H.; Li, Z.; Wei, H.; Shi, J.; Huang, Y. SeqFuzzer: An industrial protocol fuzzing framework from a deep learning perspective. In Proceedings of the 2019 12th IEEE Conference on Software Testing, Validation and Verification (ICST), Xi’an, China, 22–27 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 59–67. [Google Scholar]
Natella, R.; Pham, V.T. Profuzzbench: A benchmark for stateful protocol fuzzing. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual, 11–17 July 2021; pp. 662–665. [Google Scholar]
Hu, F.; Qin, S.; Ma, Z.; Zhao, B.; Yin, T.; Zhang, C. NSFuzz: Towards Efficient and State-Aware Network Service Fuzzing-RCR Report. ACM Trans. Softw. Eng. Methodol. 2023, 32, 1–8. [Google Scholar] [CrossRef]
Pham, V.T.; Böhme, M.; Roychoudhury, A. Aflnet: A greybox fuzzer for network protocols. In Proceedings of the 2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST), Porto, Portugal, 24–28 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 460–465. [Google Scholar]
Natella, R. Stateafl: Greybox fuzzing for stateful network servers. Empir. Softw. Eng. 2022, 27, 191. [Google Scholar] [CrossRef]
Kaksonen, R.; Laakso, M.; Takanen, A. Software security assessment through specification mutations and fault injection. In Proceedings of the Communications and Multimedia Security Issues of the New Century: IFIP TC6/TC11 Fifth Joint Working Conference on Communications and Multimedia Security (CMS’01), Darmstadt, Germany, 21–22 May 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 173–183. [Google Scholar]
Aitel, D. An Introduction to SPIKE, the Fuzzer Creation Kit. 2002. Available online: https://www.blackhat.com/presen-tations/bh-usa-02/bh-us-02-aitel-spike.ppt (accessed on 6 May 2024).
Security, B. beSTORM Black Box Testing. 2024. Available online: https://beyondsecurity.com/solutions/bestorm.html (accessed on 6 May 2024).
Inc, S. Defensics Fuzz Testing. 2020. Available online: https://www.synopsys.com/software-integrity/security-testing/fuzz-testing.html (accessed on 6 May 2024).
Rapid7. Metasploit Vulnerability & Exploit Database. 2020. Available online: https://www.rapid7.com/db/?q=fuzzer&type=metasploit (accessed on 6 May 2024).
Eddington, M. Peach Fuzzing Platform. 2004. Available online: https://gitlab.com/peachtech/peach-fuzzer-community (accessed on 6 May 2024).
Yu, Y.; Chen, Z.; Gan, S.; Wang, X. SGPFuzzer: A state-driven smart graybox protocol fuzzer for network protocol implementations. IEEE Access 2020, 8, 198668–198678. [Google Scholar] [CrossRef]
Schumilo, S.; Aschermann, C.; Jemmett, A.; Abbasi, A.; Holz, T. Nyx-net: Network fuzzing with incremental snapshots. In Proceedings of the Seventeenth European Conference on Computer Systems, Rennes, France, 5–8 April 2022; pp. 166–180. [Google Scholar]
Feng, X.; Sun, R.; Zhu, X.; Xue, M.; Wen, S.; Liu, D.; Nepal, S.; Xiang, Y. Snipuzz: Black-box fuzzing of iot firmware via message snippet inference. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 15–19 November 2021; pp. 337–350. [Google Scholar]
Sun, Y.; Wu, D.; Xue, Y.; Liu, H.; Wang, H.; Xu, Z.; Xie, X.; Liu, Y. Gptscan: Detecting logic vulnerabilities in smart contracts by combining gpt with program analysis. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, Lisbon, Portugal, 14–20 April 2024; pp. 1–13. [Google Scholar]
Xia, C.S.; Paltenghi, M.; Le Tian, J.; Pradel, M.; Zhang, L. Fuzz4all: Universal fuzzing with large language models. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, Lisbon, Portugal, 14–20 April 2024; pp. 1–13. [Google Scholar]
Hu, J.; Zhang, Q.; Yin, H. Augmenting greybox fuzzing with generative ai. arXiv 2023, arXiv:2306.06782. [Google Scholar]
Deng, Y.; Xia, C.S.; Peng, H.; Yang, C.; Zhang, L. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, Seattle, WA, USA, 17–21 July 2023; pp. 423–435. [Google Scholar]
Gascon, H.; Wressnegger, C.; Yamaguchi, F.; Arp, D.; Rieck, K. Pulsar: Stateful black-box fuzzing of proprietary network protocols. In Proceedings of the Security and Privacy in Communication Networks: 11th EAI International Conference, SecureComm 2015, Dallas, TX, USA, 26–29 October 2015; Proceedings 11. Springer: Berlin/Heidelberg, Germany, 2015; pp. 330–347. [Google Scholar]
Blumbergs, B.; Vaarandi, R. Bbuzz: A bit-aware fuzzing framework for network protocol systematic reverse engineering and analysis. In Proceedings of the MILCOM 2017—2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 707–712. [Google Scholar]
Caballero, J.; Yin, H.; Liang, Z.; Song, D. Polyglot: Automatic extraction of protocol message format using dynamic binary analysis. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 31 October–2 November 2007; pp. 317–329. [Google Scholar]
Lemieux, C.; Inala, J.P.; Lahiri, S.K.; Sen, S. Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, 14–20 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 919–931. [Google Scholar]
Deng, Y.; Xia, C.S.; Yang, C.; Zhang, S.D.; Yang, S.; Zhang, L. Large language models are edge-case generators: Crafting unusual programs for fuzzing deep learning libraries. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, Lisbon, Portugal, 14–20 April 2024; pp. 1–13. [Google Scholar]
Yang, C.; Zhao, Z.; Zhang, L. KernelGPT: Enhanced Kernel Fuzzing via Large Language Models. arXiv 2023, arXiv:2401.00563. [Google Scholar]