
آسیب پذیریهای امنیتی در دستگاههای اینترنت اشیاء (IoT یا Internet-of-Things)، پلتفرمهای موبایل و سیستمهای خودران (autonomous systems) همچنان بحرانی باقی ماندهاند. فازرهای سنتی مبتنی بر جهش (mutation-based fuzzers) با وجود اینکه مسیرهای کد را بهطور مؤثر کاوش میکنند عموماً تغییرات را در سطح بایت یا بیت انجام میدهند و از منطق معنایی غافلاند. ابزارهای هدایتشده توسط پوشش کد (Coverage-guided) مانندAFL++ بر دیکشنریها، گرامرها و هورستیکهای ترکیبی (splicing heuristics) تکیه میکنند تا محدودیتهای ساختاری سطحی را اعمال کنند، در حالی که منطق عمیق پروتکل، وابستگیهای بین فیلدها و معنای ویژه دامنه را نادیده میگیرند.
در مقابل، مدلهای زبانی بزرگ (LLM یا Large Language Models) با قابلیت استدلال، توانایی بهرهگیری از دانش انسانی تعبیهشده در پیشآموزش (pretraining) را دارند تا فرمت ورودیها را درک کنند، محدودیتهای پیچیده را رعایت کنند و جهشهای هدفمند پیشنهاد دهند—مانند یک مهندس معکوس (reverse engineer) یا کارشناس تست باتجربه (testing expert). با این حال، در نبود حقیقت پایه برای «استدلال صحیح» در تولید جهشها، آموزش تحت نظارت عملی نیست؛ این موضوع انگیزهای برای استفاده از LLMهای آماده و یادگیری چندنمونهای مبتنی بر پرامپت (prompt) ایجاد میکند.
برای پر کردن این خلأ، ما یک چارچوب میکروسرویس (microservices framework) متنباز ارائه میکنیم که LLMهای استدلالمحور را توسط AFL++ در FuzzBench گوگل یکپارچه میکند و مسائل اجرای غیرهمزمان و نیازهای سختافزاری متفاوت (مبتنی بر GPU و CPU) بین LLMها و فازرها را مدیریت میکند.
ما چهار پرسش پژوهشی را ارزیابی میکنیم:
- چگونه میتوان LLMهای مبتنی بر استدلال را در حلقه جهش فازینگ ادغام کرد؟
- آیا پرامپتهای چندنمونهای (few-shot) جهشهای باکیفیتتری نسبت به پرامپتهای بدون نمونه (zero-shot) تولید میکنند؟
- آیا مدلهای استدلال آماده میتوانند مستقیماً با مهندسی پرامپت کیفیت فازینگ را بهبود دهند؟
- کدام LLMهای متنباز استدلالی تحت شرایط پرامپت تنها بهترین عملکرد را دارند؟
آزمایشها با مدلهای Llama3.3، Deepseek-r1-Distill-Llama-70B، QwQ-32B و Gemma3 نشان میدهد که Deepseek-r1-Distill-Llama-70B امیدوارکنندهترین مدل است. اثربخشی جهشها بیشتر به پیچیدگی پرامپت و انتخاب مدل بستگی دارد تا صرفاً تعداد نمونهها.
تاخیر پاسخ و گلوگاههای توان عملیاتی همچنان از موانع اصلی هستند. چارچوب ما که بهصورت متنباز منتشر شده، از بازتولیدپذیری و توسعه توسط جامعه پشتیبانی میکند. مسیرهای پژوهشی آینده شامل زمانبندی پویا، بازخورد سبک و استقرار مقیاسپذیر است.
اصطلاحات کلیدی: تست نرمافزار، فازینگ جعبه خاکستری، تست جهش، شناسایی آسیب پذیری، قابلیت اطمینان نرم افزار، یادگیری ماشین، مدلهای زبان بزرگ (LLM) ، مهندسی پرامپت، مدلهای استدلال، پوشش کد، امنیت خودکار نرم افزار.
1. مقدمه
هر سال، دهها هزار آسیبپذیری و نقاط ضعف عمومی (CVE) جدید در پایگاه داده ملی آسیبپذیریها (NVD) ثبت میشوند که نشاندهنده گسترش سریع سطح حمله در دستگاههای اینترنت اشیاء (IoT)، پلتفرمهای موبایل و سیستمهای خودران است [1]–[4]. بازبینی دستی کد که شامل مهندسی معکوس زمانبر باینریها نیز میشود نمیتواند با این رشد سریع همگام شود، زیرا تحلیلگران خبره تنها میتوانند بخش محدودی از فریمورهای پیچیده، برنامهها یا کنترلکنندههای تعبیه شده را در بازههای زمانی معقول بررسی کنند.
در مقابل، فازینگ (Fuzzing) یک روش خودکار تست به سَبک «shift-right» که نیازی به کد منبع ندارد و به جای آن باینریهای کامپایلشده را با ورودیهای خراب یا تصادفی آزمایش میکند به یکی از مؤثرترین تکنیکهای کشف آسیب پذیری تبدیل شده است و مسئول شناسایی بخش عمدهای از باگهای با شدت بالا در پروژههای نرمافزاری بزرگ میباشد [5-10].
فازرهای هدایت شده توسط پوشش کد و مبتنی بر جهش مانند AFL++ [11] با ترکیب ابزارسازی سبک و جهشهای مبتنی بر بذر یا نمونه اولیه (seed)، مسیرهای اجرای برنامه را به سرعت کاوش میکنند و در شناسایی آسیب پذیریها در فریمورهای IoT [12], [13]، برنامههای موبایل [14] و سیستمهای خودران [15] موفق بودهاند.
با وجود این پیشرفتها، فازرهای موجود همچنان عمدتاً به جهشهای کور (blind) یا مبتنی بر هورستیک (heuristic-driven mutations) متکی هستند و در نفوذ به منطق عمیق پروتکلها و فرمتهای پیچیده ورودی محدودیت دارند، که این موضوع انگیزهای برای تحقیقات بیشتر در زمینه استراتژیهای جهش آگاه به معنا (semantic-aware mutation) ایجاد میکند.
تلاشهای اخیر در فازینگ مبتنی بر مدلهای زبانی بزرگ (LLM) نشان دادهاند که میتوان با استفاده از مهندسی پرامپت، بذرهای اولیه ورودی (initial seeds) و جهشهای هدفمند (targeted mutations) برای ورودیهای ساختیافته (structured inputs) تولید کرد. پروژههایی مانند Fuzz4All (گرامرهای زبانهای برنامهنویسی)، PromptFuzz (رابطهای کتابخانهای) و CHATAFL (تعامل به سبک چت برای پروتکلها) پتانسیل خودکارسازی تولید ورودیهای پیچیده را نشان دادهاند.
با این حال، بیشتر این رویکردها مدل را بهعنوان جعبه سیاه (black box) در نظر میگیرند و تنها بر نگاشت ورودی به خروجی تمرکز دارند و مراحل استدلالی میانی که کیفیت تولید را تضمین میکنند نادیده میگیرند. روش استدلال زنجیرهای (Chain-of-Thought, COT) نشان داده است که با شفافسازی فرایند تحلیلی مدل، وفاداری LLM و تنوع خروجیها افزایش مییابد و خطاهای هذیانی کاهش مییابد. در همین حال، سیستمهایی مانند [19] LLAMAFUZZ از تنظیم دقیق نظارت شده روی ++AFL استفاده میکنند تا جهشهای «خوب» تولید کنند اما خلاقیت مدل را محدود کرده و به دادههای برچسبگذاریشده پرهزینه نیاز دارند.
در مقابل، کار ما بررسی میکند که آیا پرامپتدهی به LLMهای آماده با قابلیت استدلال بدون آموزش اضافی (fine-tuning) اضافی میتواند از بازنماییهای نهفته دانش انسانی آنها برای تولید جهشهای جدید و غنی از نظر معنایی فراتر از راهبردهای متداول ++AFL بهره بگیرد یا خیر.
بر پایه این مشاهدات، ما این فرضیه را مطرح میکنیم که LLMهای دارای قابلیت استدلال میتوانند جریان کاری تحلیلی یک مهندس معکوس خبره را تقریب بزنند؛ بهگونهای که با بررسی ساختار یک ورودی، استنتاج وابستگیهای بین فیلدها و اعمال دانش دامنه، جهشهای هدفمند تولید کنند، نه اینکه صرفاً به ویرایشهای سطحی متکی باشند. با آشکارسازی «زنجیره تفکر» (Chain-of-Thought) درونی مدل [20] از طریق پرامپتهای طراحیشده بهصورت تجربی، هدف ما فعالسازی این قابلیت استدلال نهفته، کاهش نقاط کور در منطق پروتکلها و به حداقل رساندن جهشهای تکراری یا نامعتبر است.
از آنجا که هیچ «حقیقت پایه» قطعی برای نحوه پیشروی چنین فرایند استدلالی وجود ندارد، و از آنجا که آموزش اضافی تحت نظارت بر خروجیهای ++AFL ذاتاً مدل را به هورستیکهای موجود محدود میکند، ما مطالعه تجربی خود را بر پرامپتدهی zero-shot و few-shot متمرکز کردهایم، جایی که تعداد نمونههای ارائهشده در متن ورودی به مدل، تعداد «shot» را تعریف میکند. این پیکربندی به ما امکان میدهد توان استدلال خام و راهبردهای خلاقانه جهش LLMهای آماده را بدون محدود کردن ظرفیت بالقوه آنها یا تحمیل هزینه بالای دادههای برچسبگذاریشده ارزیابی کنیم. ما بررسی تجربی خود را حول چهار پرسش پژوهشی سازماندهی میکنیم:
پرسش پژوهشی R1: چگونه میتوان LLMهای مبتنی بر استدلال را در حلقه جهش (mutation loop) یک فازر هدایت شده توسط پوشش کد ادغام کرد؟ این امر مستلزم هماهنگسازی سرعت اجرای غیرهمزمان و نیازهای سختافزاری متفاوت میان فازرهای CPU-محور و LLMهای متکی بر GPU است، بدون آنکه توان عملیاتی کلی (overall throughput) سیستم کاهش یابد.
پرسش پژوهشی R2: آیا ارائه نمونههای few-shot در پرامپتها منجر به تولید جهشهایی با کیفیت بالاتر و آگاهی معنایی بیشتر نسبت به پرامپتهای zero-shot میشود؟ این پرسش بررسی میکند که آیا پرامپتدهی مبتنی بر مثال بهطور پیوسته اعتبار (validity) و تنوع (diversity) جهشها را در مقایسه با طراحیهای حداقلی پرامپت بهبود میدهد یا خیر.
پرسش پژوهشی R3: آیا LLMهای آماده با قابلیت استدلال میتوانند صرفاً از طریق استدلال مبتنی بر پرامپت، اثربخشی فازینگ را افزایش دهند؟ این پرسش بررسی میکند که آیا رویکردی که تنها از پرامپت استفاده میکند و هیچ آموزش اضافی ندارد، قادر است جهشهایی دارای معنای واقعی تولید کند که به پوشش کد بالاتر یا کشف باگهای بیشتر منجر شوند.
پرسش پژوهشی R4: کدام LLM متنباز، زمانی که صرفاً با مهندسی پرامپت هدایت میشود، بهترین عملکرد را ارائه میدهد؟ این پرسش مدلها را با یکدیگر مقایسه میکند تا مشخص شود دانش نهفته و قابلیتهای استدلالی کدام مدل بهطور مؤثرتری به جهشهای تست معتبر و باکیفیت تبدیل میشود.
بر پایه این پرسشها، ما یک چارچوب متنباز مبتنی بر معماری میکروسرویس ارائه میکنیم که ++AFL را از طریق Redis و Docker به LLMهای آماده با قابلیت استدلال متصل میکند و بدون استفاده از آموزش اضافی، هماهنگی مؤثری میان اجزای CPU-محور و GPU-محور ایجاد مینماید. چارچوب ما برای استقرار خودکار در FuzzBench گوگل بستهبندی شده است و امکان ارزیابی بازتولیدپذیر و مقیاسپذیر را بر روی طیف متنوعی از اهداف باینری فراهم میکند [21].
تا آنجا که اطلاع داریم، ما نخستین مطالعه نظاممند را ارائه میکنیم که در آن LLMهای دارای قابلیت استدلال تنها با استفاده از مهندسی پرامپت و بدون هیچ آموزش اضافی برای فازینگ باینری مبتنی بر جهش به کار گرفته شدهاند. در این مطالعه، راهبردهای zero-shot، one-shot و three-shot با یکدیگر مقایسه میشوند تا اثر آنها بر اعتبار جهشها، پوشش کد و کشف کرشها بهصورت کمّی ارزیابی شود [22].
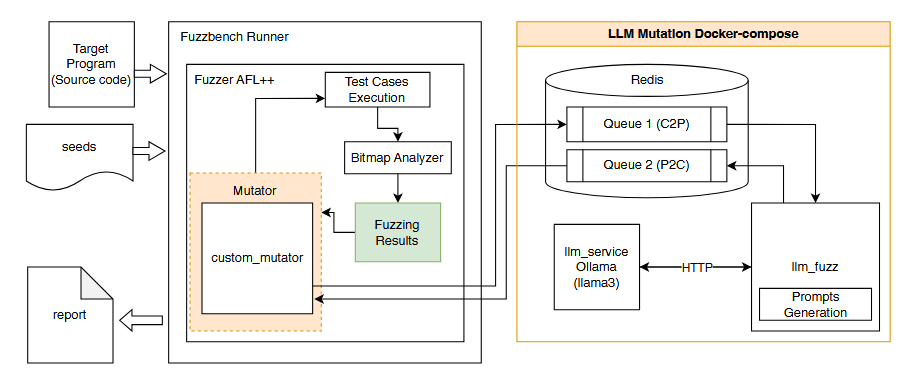
ما بهطور همزمان، چهار مدل متنباز پیشرفته با قابلیت استدلال شامل Llama 3.3، DeepSeek-r1-Distill-Llama-70B، QwQ-32B و Gemma 3 را بهصورت تجربی بنچمارک میکنیم و عملکرد جهش آنها در حالت آمادهبهکار (out-of-the-box) را در فازینگ هدایتشده توسط پوشش کد ارزیابی مینماییم [23–26]. در نهایت، ما محدودیتهای عملی این رویکرد از جمله تأخیر مدل، بدهبستانهای توان عملیاتی، و عمق معنایی را تحلیل کرده و مسیرهایی را برای زمانبندی پویا، حلقههای بازخورد سَبُک (lightweight feedback loops)، و استقرار مقیاسپذیر در فازینگ هدایت شده توسط LLMها ترسیم میکنیم.
2. روششناسیها
ما راهکاری را پیشنهاد میکنیم که در آن یک مدل زبانی بزرگ (LLM) بهعنوان یک سرویس مستقل برای پشتیبانی از مرحله جهش در یک فازر جعبه خاکستری (grey-box) مبتنی بر پوشش کد (code-coverage-based) به کار گرفته میشود. یکپارچهسازی LLM با فازر (پرسش R1) دو چالش اساسی را به همراه دارد.
در حالی که LLMها قادر به انجام استدلال پیشرفته هستند، معمولاً برای پردازش ورودی و تولید پاسخ با تأخیر پاسخدهی بالا مواجهاند [27]. این موضوع در تضاد با توان اجرایی بسیار بالای فازرهای مدرن مانند AFL++ [11] است که میتوانند بیش از ۳۰۰۰ اجرا در ثانیه را پردازش کنند [28]. در نتیجه، تعبیه مستقیم یک LLM در حلقه فازینگ، موجب کاهش سرعت فازینگ شده و حفظ کارایی آن را دشوار میسازد (چالش ۱).
برای حفظ عملکرد فازر، ما فرایند فازینگ و فرایند جهش هدایتشده توسط LLM را به دو مؤلفه مجزا تفکیک میکنیم:
- یک مؤلفه فازر مبتنی بر زبان C، و
- یک مؤلفه مبتنی بر پایتون هدایتشده توسط LLM.
این مؤلفهها به صورت مستقل بستهبندی و مستقر میشوند که به دلیل تفاوت زبانهای پیادهسازی و محیطهای اجرای توزیعشده، یک چالش همگامسازی (چالش ۲) را برای برقراری ارتباط میان این دو مؤلفه ایجاد میکند.
برای امکانپذیر ساختن ارتباط میان فازر و سرویس جهشدهی مبتنی بر LLM، ما منطق جهش ++AFL را از طریق یک اتصال جهش سفارشی (custom mutation hook) و رابط custom_mutator گسترش دادیم (راهکار ۲). این پیادهسازی به فازر اجازه میدهد تا جهشهای تولیدشده توسط LLM را بهصورت انتخابی و غیرهمزمان فراخوانی کند.
سرویس جهش مبتنی بر LLM بهصورت یک سرویس مستقل مبتنی بر Docker Compose اجرا میشود که شامل سه مؤلفه اصلی است:
- واسط پیام (message broker) مبتنی بر Redis،
- Ollama بهعنوان سرویس LLM، و
- یک مولد پرامپت LLM با نام llm fuzz.
برای تضمین ارتباط کارآمد و قابل اطمینان، چندین صف پیام نامگذاریشده در سرور Redis ایجاد شدهاند (راهکار ۱). هنگامی که موارد تست جهش یافته تولیدشده توسط LLM در صف Redis در دسترس باشند، فازر آنها را مصرف کرده و مورد استفاده قرار میدهد؛ در غیر این صورت، بهطور پیشفرض از منطق جهش داخلی خود استفاده میکند.
نمای کلی یکپارچهسازی و معماری سامانه در شکلهای ۱، ۲ و ۳ ارائه شده است.
2.1 زیرساخت
سامانه پیشنهادی بر پایه FuzzBench [21] یک پلتفرم متنباز ارزیابی فازینگ که توسط گوگل توسعه داده شده است ساخته شده و یک محیط استاندارد برای ارزیابی فازرها از طریق اجرای خودکار بنچمارکها، تحلیل نتایج و تولید گزارش فراهم میکند. سامانه ما که از یک فازر سفارشی و یک ماژول جهش مبتنی بر LLM تشکیل شده است، از این زیرساخت برای ارزیابی فازینگ هدایتشده توسط LLM در میان چندین بنچمارک استفاده میکند. زیربخش بعدی، فرایند یکپارچهسازی و چالشهای پیادهسازی مرتبط را تشریح میکند.
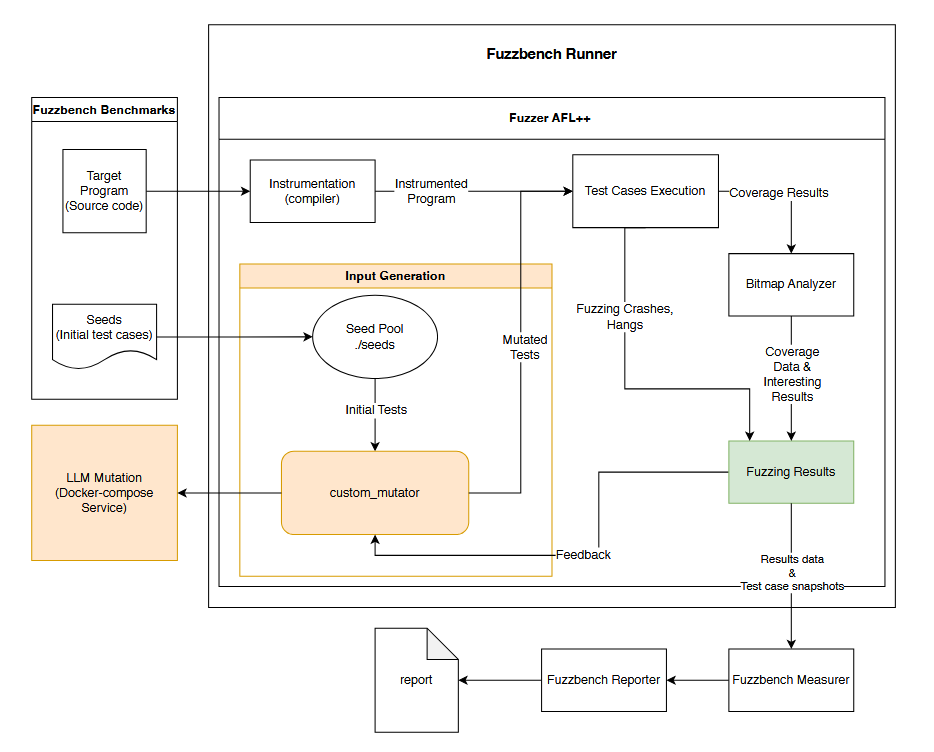
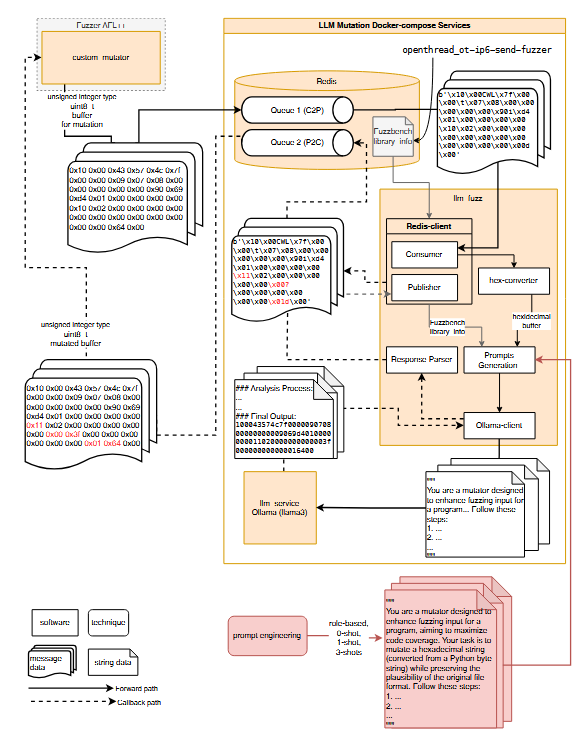
2.1.1 یکپارچهسازی فازر با FuzzBench
اگرچه FuzzBench [29] با هدف سادهسازی ارزیابی و مقایسه تکنیکهای فازینگ طراحی شده است، اما معماری زیربنایی آن برای ساخت، استقرار و اجرای فازرها ذاتاً پیچیده است. در نتیجه، یکپارچهسازی یک فازر سفارشی با این پلتفرم همچنان فرایندی پیچیده باقی میماند (چالش ۳).
برای وارد کردن فازر هدایت شده توسط LLM خود، ابتدا راهبردهای بستهبندی و استقرار ++AFL در FuzzBench را کپی کرده و آنها را برای پیادهسازی خود گسترش میدهیم. فازر جدید به دایرکتوری fuzzers/. افزوده میشود و کانتینرهای Docker با استفاده از تصویر پایه FuzzBench برای هر دو مؤلفه builder و runner سفارشی ساخته میشوند.
با این حال، برای پشتیبانی همزمان از مؤلفههای فازر و LLM، اصلاحات اضافی مورد نیاز است؛ از جمله ایجاد اسکریپتهای جدید استقرار، بهروزرسانی پیکربندیها برای راهبردهای جهش سفارشی، و رفع ناسازگاریهای نسخه پایتون و مشکلات مربوط به تولید گزارشهای HTML.
از طریق این اصلاحات (راهکار ۳)، سامانه با موفقیت در FuzzBench یکپارچه میشود و امکان اجرای آزمایشهای بازتولیدپذیر در میان بنچمارکهای مختلف را فراهم میکند. هر اجرای آزمایشی، گزارشهای پوشش کد دقیق تولید میکند که مبنایی برای ارزیابی نظاممند عملکرد فازر بر روی بنچمارکهای انتخابشده فراهم میآورد.
2.1.2 مؤلفه فازر
AFL++ [11]، که به خاطر ابزارسازی کارآمد و راهبردهای جهش خود شناخته شده است، بهعنوان هسته فازر در مؤلفه فازر عمل میکند. همانطور که در شکل ۲ نشان داده شده، برنامه هدف و موارد آزمون اولیه، معروف به seed corpus، توسط FuzzBench تأمین میشوند.
++AFL در مرحله ساخت (build stage)، برنامه هدف را در هنگام کامپایل، ابزارسازی (instrument) میکند تا پوشش کد در طول اجرا بهصورت بلادرنگ (real-time) نظارت شود. سپس این باینریهای ابزارسازیشده توسط موتور فازینگ استفاده میشوند تا بازخورد پوشش کد مشاهده و جمعآوری گردد.
در نهایت، بازخورد حاصل از هر اجرا مانند مسیرهای جدید کشف شده در کد یا کرشها (Crash) تحلیل میشود تا جهشهای آینده هدایت شده و کارایی کلی فرایند فازینگ افزایش یابد.
مراحل اصلی در فرایند فازینگ ما عبارتند از:
- تولید ورودی (Input generation): بذرها یا نمونههای اولیه (seeds) در یک مخزن نمونهها (seed pool) ذخیره میشوند و بهعنوان پایهای برای تولید موارد آزمون استفاده میشوند.
- جهش (Mutation): موارد آزمون، که همان بافرهای ورودی هستند، با استفاده از یک استراتژی دوگانه جهش که در custom mutator پیادهسازی شده است، تغییر داده میشوند و روشهای اصلی ++AFL را اصلاح میکنند. جهش ما شامل دو بخش است: (1) اپراتورهای استاندارد ++AFL مانند تغییر بیتها (bit flipping)، عملیات حسابی و جایگزینی با دیکشنری [11] و (2) سرویس جهش هدایتشده توسط LLM. این سرویس که در Docker Compose با Redis، Ollama و یک ماژول تولید پرامپت اجرا میشود با هدفگیری بخشهای ورودی که بیشترین احتمال کشف مسیرهای جدید کد را دارند، جهشهای آگاه به معنا (semantic-aware mutations) انجام میدهد.شکل ۳ معماری سرویس جهش LLM را نشان میدهد.
- اجرای موارد آزمون (Test Case Execution): موارد آزمون جهشیافته بر روی برنامه هدف ابزارسازی شده (instrumented) اجرا میشوند، و AFL++ [11] نقشههای پوشش کد (coverage bitmaps) تولید میکند تا مسیرهای اجرا را پیگیری کند. موارد آزمون که موجب crash یا timeout میشوند، در صفهای خروجی جداگانه به نامهای crashes و hangs ذخیره میشوند تا برای تحلیلهای بعدی مورد استفاده قرار گیرند.
- تحلیل نتایج (Results analysis): نقشه پوشش کد نشاندهنده تنوع و فراوانی اجرای شاخهها (branch tuples) است. در این نقشه، موارد آزمونی که مسیرهای جدیدی را کاوش میکنند بهعنوان «جالب» (interesting) در نظر گرفته شده و پوشش را افزایش میدهند؛ این موارد در دورهای بعدی فازینگ اولویت مییابند.
- مکانیزم بازخورد (Feedback mechanism): فازر استراتژی جهش و زمانبندی خود را بهصورت پویا بر اساس بازخورد نقشه پوشش تنظیم میکند. موارد آزمون جالب اولویتبندی میشوند و جهشهای بعدی با توجه به میزان افزایش پوشش آنها هدایت میشوند.
- تولید گزارش (Report generation): پس از اتمام فازینگ، FuzzBench [21] همه خروجیها را با استفاده از ماژول measurer جمعآوری کرده و پوشش نهایی کد را محاسبه میکند، سپس نتایج تحلیلشده را به ماژول reporter ارسال میکند. ماژول reporter اطلاعات را به فرمت HTML نمایش میدهد و گزارش نهایی را تولید میکند.
2.1.3 مؤلفه جهش مبتنی بر LLM(LLM Mutation Component)
مؤلفه جهش هدایتشده توسط LLM بهصورت یک سرویس مستقل عمل میکند و در زیرساخت فازینگ یکپارچه شده است. معماری و جریان پردازش پیامها در شکل ۳ نشان داده شده است، که نمونه بنچمارک openthread ot-ip6-send-fuzzer برای آن استفاده شده است. این مؤلفه از سه میکروسرویس اصلی تشکیل شده است:
2.1.3.1. Redis – واسط پیام و ذخیرهساز زمینهای (Message Broker and Context Store)
Redis [30] یک سیستم متنباز ذخیرهسازی داده در حافظه (in-memory) است که معمولاً بهعنوان واسط پیام و حافظه کش (cache) استفاده میشود. Redis از مدل داده کلید–مقدار (key–value) پشتیبانی میکند و در دسته پایگاه دادههای NoSQL قرار دارد [31]. در این معماری، Redis فازر AFL++ (پیادهسازی C) را به سرویس جهش LLM (پیادهسازی Python) متصل میکند و این ارتباط از طریق چندین صف پیام با نامهای یکتا برقرار میشود. دو صف اصلی عبارتاند از:
- C2P (Client-to-Prompt): حاوی پیامهایی است که بافرهای ورودی منتشر شده توسط ++AFL را ذخیره میکند و توسط سرویس جهش LLM مصرف میشوند.
- P2C (Prompt-to-Client): حاوی پیامهایی است که بافرهای جهشیافته LLM را منتشر میکند و توسط AFL++ مصرف میشوند.
علاوه بر این، Redis یک زوج کلید–مقدار (key–value) پایدار با نام library info نگه میدارد که شامل متادیتای کتابخانههای بنچمارک FuzzBench [21] است. این اطلاعات زمینهای برای تولید پرامپتهای آگاه و مبتنی بر زمینه (context-aware) برای LLM در طول فرایند جهش ضروری است.
در نتیجه، Redis به عنوان واسط پیام، مدیریت وضعیتهای مشترک، امکان ارتباط غیرهمزمان و یکپارچگی بدون نقص بین مؤلفههای فازینگ و LLM عمل میکند.
2.1.3.2. Ollama: موتور اجرای LLM (LLM Execution Engine)
Ollama [32] یک پلتفرم متنباز برای استقرار و اجرای LLM است. این پلتفرم از طریق Docker کانتینریزه شده است که استقرار و جداسازی مدل را ساده میکند. در این معماری،Ollama بهعنوان هسته موتور استنتاج (inference engine) برای فرایند جهش هدایت شده توسط LLM عمل میکند. این سرویس درخواستهای جهش را پردازش کرده، با استفاده از مدل بارگذاری شده، استنتاج (inference) انجام میدهد و خروجی تولیدشده را بازمیگرداند. اگرچه Ollama از آموزش اضافی مستقیم پشتیبانی نمیکند، اما از کوانتیزاسیون داخلی (internal quantization) و بهینهسازیهای زمان اجرا برای کاهش تأخیر استنتاج (inference latency) استفاده میکند. این طراحی، Ollama را به مؤلفهای کاربردی و کارآمد برای یکپارچهسازی در سامانه فازینگ ما تبدیل کرده است.
2.1.3.3. llm fuzz – تولید پرامپت و مدیریت پیامها (Prompt Generation and Message Management)
سرویس llm fuzz یک ماژول هماهنگی مبتنی بر Python است که مسئول انتشار و مصرف پیامها، تولید پرامپت و مدیریت پاسخ LLM است. این سرویس:
- ارتباط با Redis برای انتشار و مصرف پیامها را مدیریت میکند،
- پرامپتها را تولید و به Ollama برای استنتاج ارسال میکند، و
- پاسخهای بازگشتی از LLM را تحلیل و پردازش میکند.
از آنجایی که LLMها بهطور ذاتی برای تحلیل فرمتهای باینری پیچیده مانند فایلهای object (مثلاً OTT) بهینه نشدهاند، بافرهای ورودی ابتدا با استفاده از یک hexconverter اختصاصی به نمایش هگزادسیمال تبدیل میشوند. این تبدیل ثبات فرمت ورودی را تضمین کرده و پردازش محتوا توسط LLM را قابل اعتمادتر میکند.
تولید پرامپت در llm fuzz با استفاده از تکنیکهای طراحی و مهندسی پرامپت بهینهسازی شده است، بهطوری که ورودی و زمینه (مثلاً library info) ساختار یافته و توانایی جهش LLM افزایش یابد.
خروجی جهشیافته در بخش“Final Output” پاسخ بازگشتی از Ollama قرار دارد. این بخش توسط یک تجزیهگر پاسخ سفارشی (custom response parser) پردازش میشود تا موارد آزمون جهشیافته واقعی استخراج و به فازر ارسال شود.
بهطور کلی، llm fuzz بهعنوان مدیر پیام و پرامپت عمل میکند و شامل یک کلاینت Redis برای تبادل داده، یک کلاینت Ollama برای تعامل با LLMو یک مجموعه ابزار کمکی برای تبدیل هگز، تولید پرامپت و تحلیل پاسخ است.
2.2 جریان دادهها (Data Flow)
روش جهش پیشنهادی در الگوریتم ۱ تشریح شده است. در تکمیل کد شبه (pseudo-code)، شکل ۴ جریان دادهها را بهصورت تصویری نشان میدهد و تعامل بین ++AFL و مؤلفههای جهش هدایت شده توسط LLM را در چارچوب پیشنهادی ما نمایش میدهد. پردازش بافرهای ورودی در طول جهش در مراحل زیر انجام میشود:
- انتشار پیام در ++AFL: بافرهای ورودی، که به صورت uint8_t (اعداد صحیح بدون علامت ۸ بیتی) نمایش داده میشوند، ابتدا با استراتژیهای جهش پیشفرض ++AFL جهش داده میشوند. سپس بافرهای جهشیافته سریالیزه شده (serialized) و در صف Redis با نام C2P منتشر میشوند.
- مصرف پیام درllm fuzz : سرویس llm fuzz با استفاده از کلاینت Redis به صف C2P گوش میدهد. وقتی پیامی دریافت شد، به عنوان Python byte string مصرف میشود. در غیر این صورت، برنامه وارد حالت انتظار (wait state) خواهد شد.
- پردازش پیام در llm fuzz: پیامهای مصرف شده در سرویس llm fuzz در دو مرحله کلیدی پردازش میشوند:
- تقسیم بافر (Buffer Splitting): بافرهایی که طول آنها بیش از ۲۰۰۰ بایت است، برای جلوگیری از سرریز حافظه در سیستمهای CUDA-enabled تقسیم میشوند. ۲۰۰۰ بایت اول توسط LLM جهش داده میشوند. بخشهای باقیمانده برای ترکیب مجدد ذخیره میشوند. بافرهایی که کمتر یا مساوی ۲۰۰۰ بایت هستند، بهطور کامل در جهش استفاده میشوند و بخشهای باقیمانده بهعنوان خالی در نظر گرفته میشوند.
این استراتژی اولویت را به جهش بخش اول میدهد، زیرا شناسههای فرمت فایل معمولاً در ابتدای فایلها ظاهر میشوند. - تبدیل به هگزادسیمال (Hexadecimal Conversion): بافرهایی که برای جهش تعیین شدهاند، به رشتههای هگزادسیمال تبدیل میشوند تا سازگاری با LLM تضمین شود.
- تولید پرامپت در llm fuzz: پرامپتهای اصلاحشده با استفاده از مهندسی پرامپت (prompt engineering) ایجاد میشوند و شامل زمینه کاربر میباشند، از جمله: بافر ورودی هگزادسیمال و اطلاعات زمینهای بنچمارک بازیابیشده از Redis. این پرامپتها سپس از طریق ارتباط HTTP کلاینت Ollama به سرویس Ollama ارسال میشوند.
- تولید پاسخ در LLM: LLM پرامپت را پردازش کرده و یک پاسخ ساختاریافته بازمیگرداند که شامل دو بخش کلیدی است: Analysis و Final Output. بخش Final Output شامل بافرهای جهشیافته به فرمت هگزادسیمال است و قواعد قالببندی سختگیرانه رعایت شدهاند.
- تحلیل پاسخ در llm fuzz: بافر جهشیافته از Final Output استخراج شده و از هگزادسیمال به Python byte string تبدیل میشود. اگر ValueError به دلیل طول فرد رشته هگزادسیمال رخ دهد، یک “0” به انتهای آن اضافه میشود تا قالب اصلاح شود. بافرهایی که همچنان با خطا مواجه شوند، دور انداخته شده و به فازر ارسال نمیشوند.
- انتشار پیام در llm fuzz: بافرهای جهشیافته که بهدرستی تبدیل و ترکیب مجدد شدهاند از جمله بخشهایی که قبلاً تقسیم شده بودند در صف Redis با نام P2C منتشر میشوند، جایی که ++AFL میتواند آنها را مصرف و اجرا کند.
- مصرف پیام در ++AFL: مؤلفه ++AFL بهطور مداوم صف P2C روی سرور Redis را نظارت میکند. وقتی پیامی شامل بافرهای جهشیافته توسط LLM دریافت شود، ++AFL دادهها را مصرف میکند، همچنین در فرمت uint8_t، و آنها را در حلقه فازینگ استفاده میکند. در غیر این صورت، ++AFL ادامه اجرای خود را با استفاده از جهشهای پیشفرض دنبال میکند.
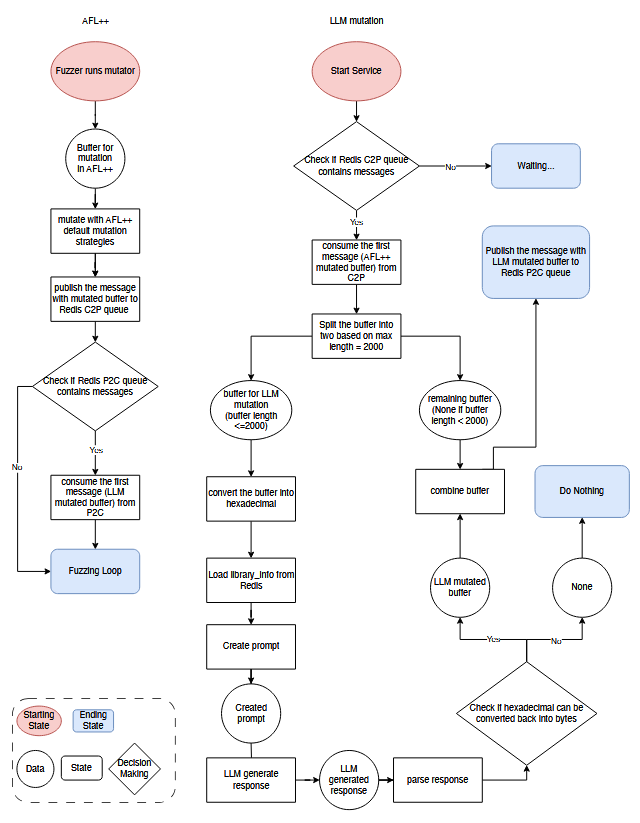
2.3 استقرار
مؤلفه فازر با چارچوب FuzzBench [21] یکپارچه شده و در کنار بنچمارکهای هدف با استفاده از pipeline استاندارد FuzzBench مستقر میشود. در مقابل، مؤلفه جهش هدایت شده توسط LLM بهصورت مستقل با استفاده از Docker Compose مستقر میشود.
پیکربندی Docker Compose، میکروسرویسهای Redis، Ollama و llm fuzz را تعریف و هماهنگ میکند، که با دستور docker-compose up build– به طور همزمان راهاندازی میشوند. پس از فعال شدن این سرویسها و بارگذاری مدلهای LLM در Ollama، فرایند فازینگ میتواند از طریق اسکریپت سفارشی ما run_benchmark.sh آغاز شود، که پیکربندی بنچمارک را ساده کرده و ساخت و استقرار مؤلفه فازر در کانتینرهای Docker را خودکار میکند.
استقرار مؤلفه جهش هدایت شده توسط LLM با استفاده از Docker Compose سه مزیت دارد:
- ماژولار بودن (Modularity): سرویس جهش هدایت شده توسط LLM کاملاً از مؤلفه فازر جدا شده است و امکان استقرار مستقل حتی روی سرورهای مختلف را فراهم میکند و یکپارچهسازی LLM در جریانهای کاری فازینگ را بدون مشکل امکانپذیر میسازد.
- انعطافپذیری (Flexibility): هر دو مؤلفه فازر و LLM بهسادگی از طریق متغیرهای محیطی و آرگومانهای خط فرمان در اسکریپت استقرار قابل پیکربندی هستند، که سفارشیسازی سریع برای بنچمارکها، استراتژیهای فازینگ و نسخههای مدل را ممکن میسازد.
- گسترشپذیری پایدار (Sustainable Extension): معماری ما اجازه میدهد فازرهای دیگر که با FuzzBench یکپارچه شدهاند با استفاده از اتصال custom_mutator و پیکربندی مناسب صفهای Redis، سرویس LLM را بپذیرند و از آن بهره ببرند.
الگوریتم ۱. فازینگ مبتنی بر جهش هدایت شده توسط LLM:
Input: Seed corpus C0, Target program F, Pre-trained LLM
MLLM, Prompt shots Pk (k ∈ {0, 1, 3}), Fuzzing time inter-val T
Output: Set of interesting inputs Cmut, Coverage results Rcov,
LLM response metrics Rlog
Initialize input queue Q ← C0
Initialize coverage map Mcov ← ∅
Initialize Rlog, Cmut, Qcrash, Qhang ← ∅
for t = 1 to T do
Select input x ∼ Q using queue strategy
Split string x
xlength2000 ← LengthSplitter(x)
Convert xlength<=2000 to hex string hx
hx ← HexEncode(xlength2000)
Run x′ on F: (O, C) ← F(x′)
if O = CRASH then
Add x′ to crash queue: Qcrash ← Qcrash ∪ {x′}
continue
else if O = TIMEOUT then
Add x′ to hang queue: Qhang ← Qhang ∪ {x′}
continue
else if isNewCoverage(C) then
Add x′ to queue and corpus:
Q ← Q ∪ {x′}, Cmut ← Cmut ∪ {x′}
end if
Log metrics Rlog ← Rlog ∪ {(x′, FMR, HCER, RDR)}
end for
Generate final report Rcov
2.4 بهینه سازی پرامپت (Prompt Refinement)
در مرحله تولید پاسخ توسط LLM، انتظار میرود خروجی شامل یک رشته هگزادسیمال تمیز باشد که نمایانگر ورودی جهشیافته است (بدون هیچ متن اضافی، کاراکتر ویژه یا توضیحی). بنابراین، یک پرامپت حداقلی مانند «بافر داده شده {input buffer} را با استفاده از {library info} ارائه شده جهش دهید و تنها رشته هگزادسیمال جهشیافته را تولید کنید»، میتواند کافی باشد.
با این حال، استفاده از چنین پرامپتهای ساده دو محدودیت مهم (چالش ۴) دارد:
- فرمت خروجی نامنظم: به دلیل ماهیت تصادفی LLMها، خروجیها ممکن است حتی با پارامترهای ثابت مانند temperature [33] از فرمت مورد انتظار خارج شوند.
- تفسیر محدود: پرامپتهای ساده بینشی از فرایند استدلال مدل ارائه نمیکنند و تحلیل نحوه تولید نتایج دشوار میشود.
برای رفع این محدودیتها و بهبود دقت و قابلیت تفسیر خروجیها، پرامپتها با استفاده از دو تکنیک اصلی: طراحی پرامپت و مهندسی پرامپت بهینهسازی میشوند (راهکار ۴). استراتژیهای طراحی پرامپت ما شامل موارد زیر است:
- ایفای نقش (Role playing): با الهام از [34]، به LLM یک نقش تخصصی در حوزه فازینگ داده میشود تا همراستایی با وظیفه و ارتباط زمینهای بهبود یابد.
- توضیح وظیفه (Task clarification): پرامپتها بهطور شفاف و صریح هدف را تعریف میکنند تا LLM بداند چه چیزی باید انجام دهد. مثال: «وظیفه شما جهش دادن یک رشته هگزادسیمال (تبدیلشده از Python byte string) است، در حالی که قابلیت پذیرش فرمت اصلی فایل حفظ شود».
- تخصصیسازی دستورالعملها (Instruction specialization): وظیفه جهش به دستورالعملهای گامبهگام و ریز تقسیم میشود، شامل تحلیل بافر ورودی، شناسایی اهداف مناسب برای جهش و اعمال جهشهای ساختاریافته. هر گام با جزئیات بیشتری توضیح داده میشود. مثال: در گام ۱، ورودی هگزادسیمال رمزگشایی میشود، اجزای ساختاری مانند فیلدهای کلیدی، مناطق و الگوهای شناخته شده کتابخانهها شناسایی میشوند، بخشهای حیاتی برای یکپارچگی فرمت تشخیص داده شده و نواحی امن برای جهش مشخص میشوند.
- ساختاربندی بخشها (Section structuring): پرامپتها به بخشهای منطقی سازماندهی میشوند: دستورالعملها (Instruction)، زمینه (Context)، دادههای ورودی (Input data) و شاخصهای فرمت خروجی (Output format indicators. پاسخ LLM نیز به دو بخش ساختار یافته است: یکیAnalysis دلایل مفصل یا زنجیره فکری (Chain-of-Thought, COT) [20] که منطق جهش را توضیح میدهد و به بهینهسازی پرامپت کمک میکند و دیگریFinal Output رشته هگزادسیمال با قالب سختگیرانه شامل تنها بافر جهشیافته بدون توضیح یا کاراکتر اضافی برای پردازش مؤثر پاسخ LLM.
با وجود توانایی LLM در درک پرامپتهای پیچیده، وابستگی به حافظه میتواند منجر به از دست رفتن زمینه در توالیهای طولانی ورودی شود و پاسخها کمتر دقیق یا نامنظم شوند. برای کاهش این مشکل، استراتژی ساختاردهی پیام مبتنی بر نقش (role-based message structuring) استفاده میشود تا پرامپت به بخشهای معنایی تقسیم و هدف دستورالعملها واضحتر شود. این روش مؤثر است، زیرا LLM میتواند ورودی را بسته به نقش اختصاصیافته متفاوت تفسیر کند. بنابراین، در استراتژی مهندسی پرامپت پژوهش ما، دو نقش متمایز در پرامپت لحاظ شدهاند:
2.4.1 نقش سیستم (System Role)
پرامپتهای مبتنی بر سیستم (System-based prompts) شامل دستورالعملهای اساسی برای تعریف محدودیتهای رفتاری و دامنه زمینهای (contextual scope) LLM هستند. این پرامپتها محدودیتها، قوانین و مرزهای اخلاقی را مشخص میکنند تا تولید پاسخ بهدرستی هدایت شود.
در مطالعه ما، پرامپتهای سیستم شامل موارد زیر است:
- نقش اختصاص یافته (assigned role)
- وظایف اصلی (primary tasks)
- دستورالعملهای گامبهگام همراه با زمینهها (step-by-step instructions with contexts)
- نیازمندیهای سختگیرانه فرمت خروجی (strict output format requirements)
از آنجا که فازر تنها بافر جهشیافته را انتظار دارد، یک بخش ویژه به نام “Strict Output Formatting Requirements” در پرامپت سیستم گنجانده شده است تا رعایت فرمت خروجی تضمین شود. شکل ۵ نمونهای از یک پرامپت مبتنی بر نقش سیستم را نشان میدهد.

2.4.2 نقش کاربر (User Role)
پرامپتهای کاربر (User prompts) دادههای ورودی پویا و وابسته به وظیفه را فراهم میکنند. با این حال، به دلیل تغییرپذیری خروجیهای تولید شده توسط LLM [33]، صرفاً اعمال محدودیتهای سختگیرانه فرمت نمیتواند ثبات خروجی را تضمین کند.
برای بهبود پایداری، ما از few-shot prompting در پرامپت کاربر استفاده میکنیم، با نمونههای ملموس تعبیه شده (embedded concrete examples) که فرمت خروجی مورد نظر را رعایت میکنند. همچنین، یادآوریهای فرمت (format reminders) اضافه میشوند تا احتمال انحراف زمینهای (context drift) به حداقل برسد. شکل ۷ نمونهای از یک پرامپت few-shot را نشان میدهد.
پژوهش ما سه استراتژی مهندسی پرامپت را بررسی میکند [35]:
- Zero-shot prompting:
- تنها شامل دستورالعملهای وظیفه است و هیچ مثال یا نمایش عملی ارائه نمیدهد.
- همانطور که در شکل ۶ نشان داده شده، بخش “Example Output” شامل بافرهای جهشیافته واقعی نیست.
- Few-shot prompting:
- نیازمند نمونههای صریح در پرامپت است.
- One-shot وThree-shot prompting بهترتیب یک و سه نمونه موفق جهش را وارد پرامپت میکنند.
- این نمونهها (شکل ۸) خروجیهای قبلی LLM هستند که نیازمندیهای فرمت خروجی را رعایت کردهاند.
- Chain-of-thought prompting (COT) [20]:
- گامهای استدلال میانی را به پرامپت اضافه میکند.
- نمونههای few-shot ما شامل بخش Analysis هستند که منطق جهشها را توضیح میدهند، مانند «چرا کاراکترهای خاصی در بافر ورودی جهش داده شدند؟» و یا «چگونه خروجی نهایی تولید شده است؟».
- برای جلوگیری از از دست رفتن زمینه (context loss)، مشخصات سختگیرانه فرمت خروجی پس از نمونهها دوباره تکرار میشود.
مهندسی مؤثر پرامپت اغلب چالشبرانگیز است، زیرا پرامپتهای بهینه به ندرت در اولین تلاش موفق هستند. بنابراین، این فرایند معمولاً نیازمند بهینهسازی تکراری و مستمر (iterative refinement) است.
ما از رویکرد آزمون و خطای مداوم (continuous trial-and-error) [36] استفاده میکنیم، که شامل مراحل زیر است:
- تولید پاسخ با استفاده از پرامپت فعلی.
- ارزیابی اینکه آیا خروجیها نیازمندیهای ساختاری و معنایی را رعایت میکنند.
- اعمال تعدیلات هدفمند کوچک مانند تأکید بیشتر بر محدودیتهای فرمت، تغییر ساختار نمونهها و اصلاح اصطلاحات کلیدی.
- تکرار این فرایند تا زمانی که پرامپتها بهطور مداوم نتایج رضایتبخش تولید کنند.
این فرایند، نسخههای نهایی پرامپتهای zero-shot، one-shot و three-shot را تولید میکند، که تنها پس از رعایت دقیق فرمت خروجی نگهداری میشوند.


۳. تنظیمات تجربی
گرچه فازرها بهطور نظری میتوانند بهصورت نامحدود اجرا شوند تا باگها را کشف کنند، اما در سناریوهای عملی و صنعتی، زمان اجرا محدود است. برای بازتاب محدودیتهای واقعی، هر پیکربندی در دو بازه زمانی ثابت یک ساعت و چهار ساعت ارزیابی شد. هر جفت فازر و بنچمارک با سه آزمایش مستقل مورد بررسی قرار گرفت تا تصادفی بودن کاهش یافته و اعتبار نتایج افزایش یابد.
تمام آزمایشها بر روی یک سرور با عملکرد بالا اجرا شدند که دارای مشخصات زیر بود:
- سیستمعامل: Ubuntu 20.04.2 LTS
- پردازنده: Intel Xeon Gold 5218 CPU (۶۴ هسته)
- حافظه رم: ۷۵۴ GiB
- حافظه ذخیرهسازی: ۳ ترابایت
- کارت گرافیک: دو عدد NVIDIA Quadro RTX 6000 (هر کدام با ۲۴ GiB VRAM)
این بخش معیارهای عملکرد (performance metrics) را تعریف کرده و بنچمارکها، پایه مقایسه (baseline) و مدلهای LLM انتخابشده را توصیف میکند. جزئیات بیشتر درباره تنظیمات آزمایش و نتایج تولیدشده در بخش ۴ ارائه شده است.

۳.۱ معیارهای ارزیابی
ما از FuzzBench [29] برای جمعآوری و تحلیل دادههای پوشش کد (coverage data) در چندین هدف استفاده میکنیم و پوشش کد را از چهار دیدگاه ارزیابی میکنیم:
- پوشش تابع (Function Coverage): نسبت توابع اجراشده به کل توابع موجود در فایل اجرایی را اندازهگیری میکند.
- پوشش خط (Line Coverage): درصد خطوط اجرایی داخل توابع که مورد آزمایش قرار گرفتهاند را ارزیابی میکند.
- پوشش ناحیه (Region Coverage): نواحی کنترل جریان مجزا را بررسی میکند، که شامل توالیای از دستورها با یک نقطه ورود و خروج واحد هستند.
- پوشش شاخه (Branch Coverage): که به نام پوشش تصمیم (decision coverage) نیز شناخته میشود، شاخههای اجراشده در ساختارهای شرطی مانند if، switch-case، حلقهها، و try-catch را اندازهگیری میکند تا اطمینان حاصل شود که مسیرهای true و false هر دو بررسی شدهاند.
ما استراتژی جهش هدایت شده توسط LLM را عمدتاً از طریق پوشش کد ارزیابی میکنیم، و از درصد بهبود پوشش (Coverage Improvement Percentage – CIP) برای محاسبه سودمندی LLM (CoverageLLM) نسبت به فازر پایه (CoverageBaseline) استفاده میکنیم.
- مقادیر مثبت نشان میدهند که LLM عملکرد بهتری نسبت به فازر پایه دارد.
- این معیار بهبود کارایی فازینگ را کمّی میکند و بهطور ضمنی کیفیت جهشهای LLM را منعکس میکند، زیرا جهشهای بهتر احتمالاً بخشهای بیشتری از کد را کشف میکنند.
فرمول CIP به صورت زیر بیان میشود:
نرخ صحت نحو (Syntactic Correctness Rate – SCR) درصد خروجیهای LLM را که فرمت مورد انتظار را رعایت میکنند ارزیابی میکند و نشاندهنده میزان هدایت موفق مدل توسط پرامپتها برای تولید نتایج قابل استفاده است. Ncorrect تعداد پاسخهای تولیدشده توسط LLM است که از نظر نحوی (Syntactic) معتبرند و Ncorrect تعداد کل پاسخهای تولیدشده توسط LLM میباشد. نرخ SCR به صورت زیر بیان میشود:
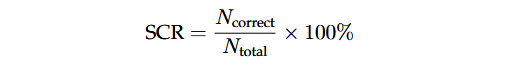
با وجود فرمتبندی سختگیرانه پرامپت و تنظیم دمای مدل روی صفر (zero temperature) برای تولید خروجیهای قطعی، LLMها همچنان ممکن است خطاهای نحوی (syntactic errors) تولید کنند. این خطاهای نحوی از دو مشکل اصلی ناشی میشوند:
- استثناهای تبدیل هگزادسیمال: زمانی که رشته هگزادسیمال نتواند به یک شی Python bytes تبدیل شود.
- عدم تطابق فرمت: وقتی که بخش مورد انتظار “Final Output” وجود ندارد یا شامل محتوای نامعتبر است.
در حالی که ما استثناهای تبدیل هگزادسیمال را بهصورت دستی مدیریت میکنیم، عدم تطابق فرمت همچنان علت اصلی خطاهای نحوی باقی میماند.
بنابراین، SCR (Syntactic Correctness Rate) نشان میدهد که LLM چند بار خروجیهای نحوی معتبر و با فرمت صحیح تولید کرده است. SCR بالاتر نشاندهنده این است که بافرهای جهشیافته بیشتری با فرمت معتبر یا قابل استفاده تولید شدهاند، که میتواند اثربخشی فازینگ را افزایش دهد.
پایداری پاسخهای LLM میتواند بر اثربخشی فازینگ تأثیر بگذارد، زیرا خروجیهای تکراری تنوع جهشها را کاهش داده و پوشش کد را محدود میکنند. بنابراین، نرخ تکرار پاسخ (Response Duplication Rate – RDR) بهعنوان معیاری برای اندازهگیری تعیینکنندگی LLM معرفی میشود. پاسخها زمانی تکراری محسوب میشوند که بخش «Final Output» آنها با خروجی قبلی در همان جفت فازر-بنچمارک و تنظیم prompt-shot مطابقت داشته باشد. RDR بالا نشاندهنده کاهش تنوع جهشها و احتمال بیشتعینکنندگی مدل است. بهطور رسمی، RDR نسبت پاسخهای تکراری LLM (NDuplicateN) به کل تولیدات LLM (NTotalN) است.
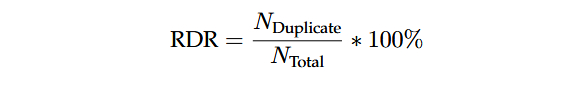
به طور خلاصه، ما روش پیشنهادی را با استفاده از چهار معیار اصلی ارزیابی میکنیم:
- پوشش کد (Code Coverage): توانایی فازر در کاوش مسیرهای اجرایی برنامه را اندازهگیری میکند.
- CIP: میزان بهبود عملکرد نسبت به فازرهای پایه را تعیین میکند.
- SCR: قابلیت اعتماد جهشهای تولیدشده توسط LLM تحت هدایت پرامپتهای ساختاریافته را ارزیابی میکند.
- RDR: میزان تعیینکنندگی خروجیهای تولیدشده توسط LLM را بررسی میکند.
3.2 انتخاب بنچمارکها، خطوط پایه (Baseline) و مدلهای زبانی بزرگ (LLM)
از آنجا که مطالعه ما بر بررسی فازینگ در حوزههایی با الزامات قابلیت اطمینان بالا و منطق داخلی پیچیده تمرکز دارد از جمله فریمورهای اینترنت اشیا، پلتفرمهای موبایل و سامانههای رانندگی خودران ما ۲۵ مورد از ۲۶ بنچمارکی را که به صورت رسمی در FuzzBench [29] نگهداری میشوند انتخاب کردهایم. اهداف فازینگ متناظر با این بنچمارکها از OSS-Fuzz [37] استخراج شده و مجموعهای متنوع از برنامههای متنباز دنیای واقعی را نمایندگی میکنند [29]. این بنچمارکها شامل انواع ورودی ساختیافته مانند قالبهای فایل، پروتکلهای شبکه و کتابخانههای رمزنگاری هستند که از نظر ویژگیهای ورودی شباهت زیادی به دامنههای هدف ما دارند و با راهبرد جهش مبتنی بر LLM پیشنهادی ما سازگارند.
در چارچوب FuzzBench، تعداد ۲۰ بنچمارک از نوع عمومی هستند که هدف آنها بیشینهسازی پوشش کد در برنامه هدف است، در حالی که ۵ بنچمارک دیگر از نوع اختصاصی بوده و برای بازتولید کرشهای (Crash) شناختهشده یا مشکوک طراحی شدهاند. افزون بر این، به دلیل نقش بنیادی و ارتباط معماری آنها با سامانه پیشنهادی ما، ابزارهای AFL [38]، AFL++ [11] و LibFuzzer [39] بهعنوان فازرهای خط پایه انتخاب شدهاند. این فازرهای خاکستری مبتنی بر هدایت پوشش کد که بهطور گسترده مورد استفاده قرار میگیرند، تأثیر بسزایی در توسعه ابزارهای مدرن فازینگ داشتهاند.
از آنجا که راهکار ما بر پایه ++AFL بنا شده است، این ابزار بهطور طبیعی بهعنوان خط پایه (Baseline) برای مقایسه مستقیم انتخاب میشود. ++AFL که نسخه توسعهیافته AFL با راهبردهای جهش هیبریدی (hybrid mutation) و زمانبندی بهبود یافته است، امکان استفاده از AFL را به عنوان یک خط پایه مناسب برای ارزیابی روند تکامل قابلیتهای فازینگ فراهم میکند. همچنین LibFuzzer نیز به دلیل کاربرد گسترده در FuzzBench و نقش آن به عنوان هسته چندین ابزار مدرن فازینگ (مانند LibFuzzer-bin [40]، LibAFL [41] و PromptFuzz [17]) در مجموعه خطوط پایه گنجانده شده است.
فازینگ هدایتشده توسط LLM بهطور مؤثر مستلزم مدلهایی با چهار قابلیت اساسی است:
(1) توانایی قوی در تولید کد برای ایجاد جهشهای ساختاریافته و از نظر نحوی معتبر؛
(2) درک زبانی مناسب برای تشخیص قالبهای ورودی و حفظ یکپارچگی ساختاری؛
(3) پیروی قابلاعتماد از دستورالعملها برای اجرای دقیق الزامات مطرحشده در پرامپت؛ و
(4) توانایی استدلال مؤثر برای توضیح منطق جهشها و فرایند تصمیمگیری.
بر اساس این معیارها، ما مدلهای Llama3.3 (70B)، Deepseek-r1-Distill-Llama-70B، QwQ-32B و Gemma3-27B را بهعنوان مدلهای پایه انتخاب میکنیم. این مدلهای متنباز نمایانگر پیشرفتهای اخیر در LLMهای کدمحور هستند و در تولید متن ساختاریافته، تبعیت از دستورالعملها و استدلال معنایی عملکرد برجستهای دارند. همچنین، این مدلها با محدودیتهای منابع سیستم ما سازگار هستند.
4. نتایج و بحث
برای ارزیابی ظرفیت LLMهای پیشرفتهِ دارای توانایی استدلال در بهبود عملکرد فازینگ، ما یک زیرساخت اختصاصی توسعه دادیم که موتورهای فازینگ سنتی را با مؤلفههای جهش مبتنی بر LLM یکپارچه میکند. این زیرساخت، پایهی تمامی ارزیابیهای تجربی ما برای پاسخ به پرسشهای پژوهشی را تشکیل میدهد.
برای پاسخ به R2، مجموعهای متمرکز از آزمایشها را انجام دادیم که تأثیر مهندسی پرامپت—بهطور مشخص پیکربندیهای Zero-shot، One-shot و Three-shot را بر کیفیت جهشهای تولیدشده توسط Llama3.3 [23] ارزیابی میکند. برای بررسی اینکه آیا سایر LLMها نسبت به Llama3.3 عملکرد بهتری دارند (در راستای پاسخ به R3 و R4)، آزمایشهای تکمیلی انجام دادیم و پوشش کد حاصل از بهکارگیری مدلهای پیشرفتهی مختلفِ دارای توانایی استدلال را تحت تنظیمات متفاوت shot با یکدیگر مقایسه کردیم.
مدلهای زبانی انتخاب شده به طور گسترده در جامعهی هوش مصنوعی بهعنوان مدلهایی با عملکرد قوی شناخته میشوند و نمایانگر پیشرفتهای کنونی در قابلیتهای استدلال هستند. همچنین، نتایج را بر اساس چهار معیار پوشش کد، CIP، SCR و RDRکه در بخش 3.1 معرفی شدهاند، از سه منظر اصلی ارزیابی میکنیم: پوشش کد، کیفیت جهش و کارایی فازینگ. دادههای پوشش کد از گزارشهای تولید شده توسط FuzzBench استخراج شدند که شامل پوشش تابع، خط، شاخه و ناحیه است. علاوه بر این، حدود 96 گیگابایت لاگ توسط مؤلفهی LLM تولید شد. از طریق پاکسازی دادهها و تحلیل لاگها، جداول تحلیل لاگی با بیش از 640٬000 ورودی ایجاد کردیم.
4.1 آزمایش مقایسه خط پایه
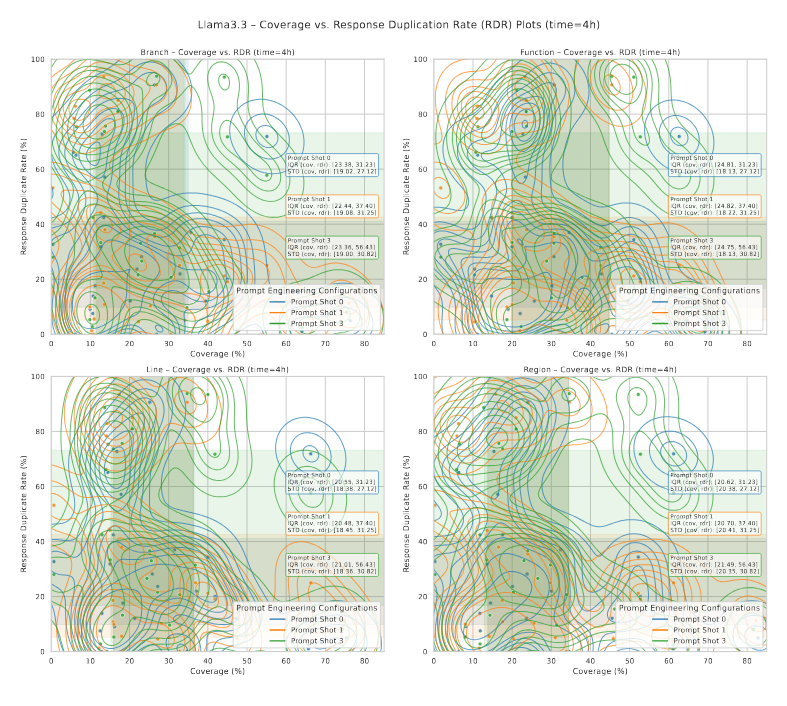
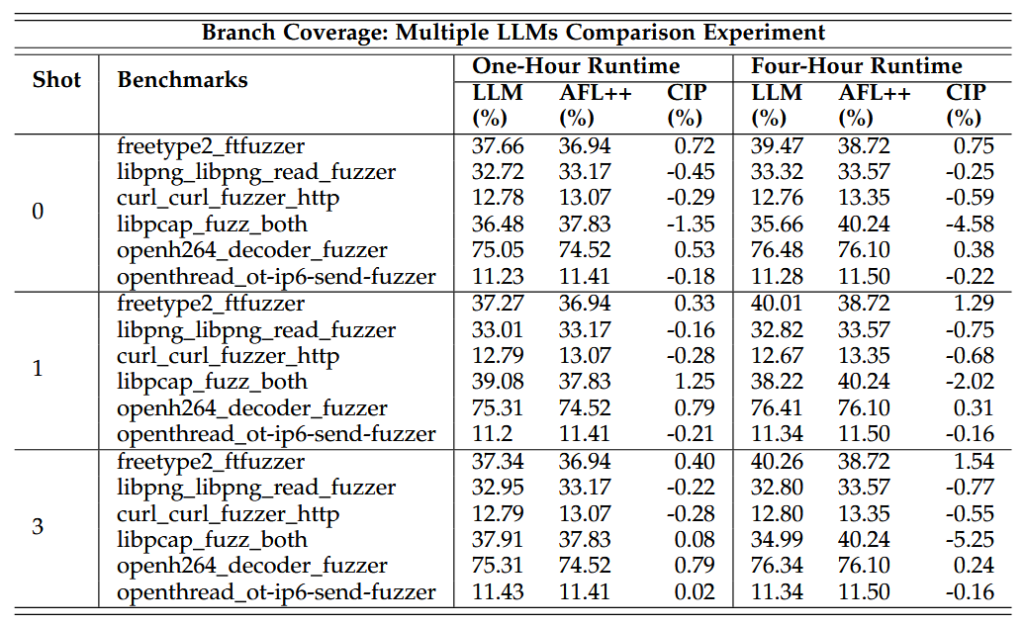
برای ایجاد یک baseline جهت مقایسه، هر یک از سه فازر مبتنی بر جهش ++AFL [11]، AFL [38] و LibFuzzer [39] در قالب سه اجرای مستقل با استفاده از چارچوب FuzzBench ارزیابی شدند. در هر اجرا، هر فازر در برابر یک مجموعهی مشترک شامل 25 بنچمارک منتخب مورد آزمایش قرار گرفت. تمامی فازرها با پیکربندیهای پیشفرض تعریف شده در FuzzBench اجرا شدند که راهبردهای جهش پایه مانند Havoc و MOpt [42] را بهکار میگیرند.
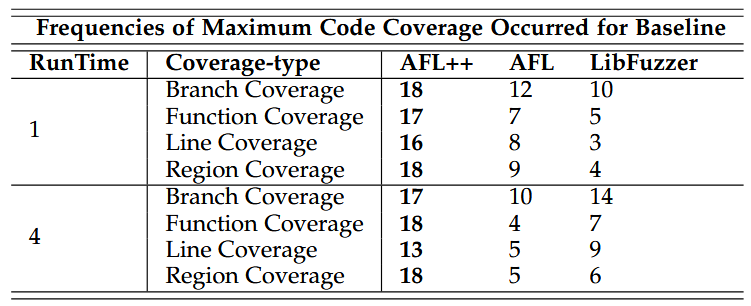
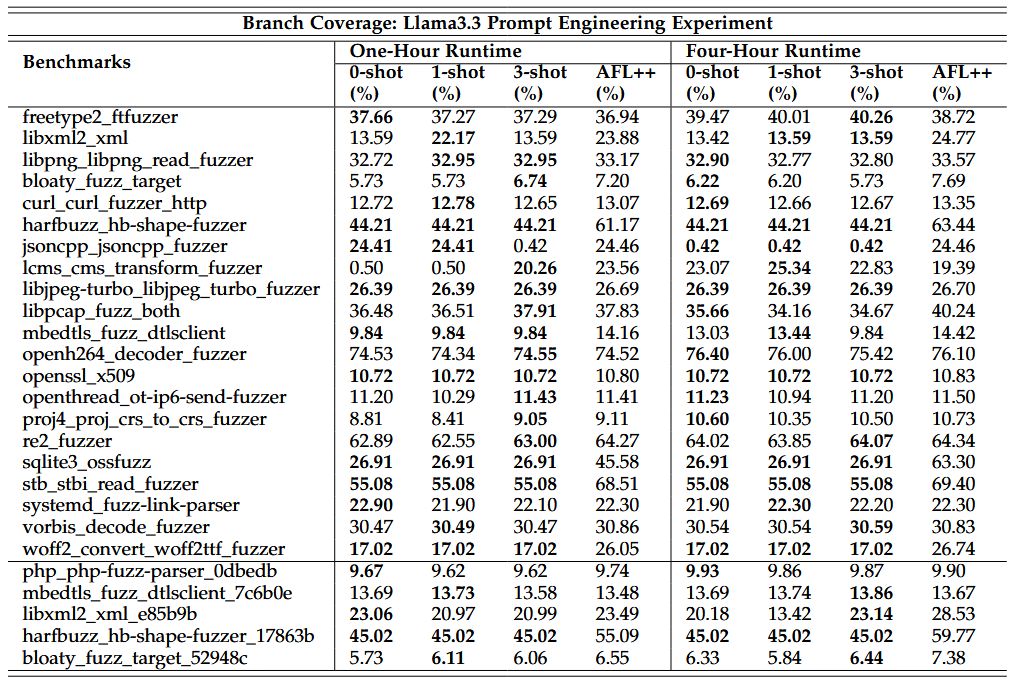
بر اساس نتایج آزمایشهای یکساعته و چهارساعته، جدول 1 تعداد دفعات دستیابی هر فازر پایه به بیشترین پوشش کد را خلاصه میکند. ++AFL بهطور مداوم در تمامی انواع پوشش و بازههای زمانی، عملکرد بهتری نسبت به سایر فازرها نشان داد. برای مثال، در اجراهای یکساعته، ++AFL در 18 بنچمارک به بیشترین پوشش شاخه (branch coverage) دست یافت که بیش از 69٪ از کل جفتهای فازر–بنچمارک پایه را شامل میشود. در اجراهای چهارساعته نیز ++AFL در 17 بنچمارک (65٪) از AFL و LibFuzzer پیشی گرفت.
با توجه به عملکرد برتر و پایدار ++AFL در هر دو بازهی زمانی، این فازر به عنوان خط پایهی اصلی برای ارزیابی اثربخشی فازرهای هدایت شده توسط LLM در آزمایشهای بعدی مورد استفاده قرار میگیرد.
4.2 آزمایش ارزیابی مهندسی پرامپت Llama3.3
این آزمایش بررسی میکند که مهندسی پرامپت (prompt engineering) به ویژه تعداد shotهای پرامپت چگونه بر اثربخشی فازینگ هدایت شده توسط LLM تأثیر میگذارد و بدینترتیب به پرسش پژوهشی R2 پاسخ میدهد. از آنجا که طراحی پرامپت ذاتاً فرایندی تکرارشونده و پرهزینه برای بهینهسازی در کل pipeline (پایپ لاین) FuzzBench است، ما در ابتدا قالبهای پرامپت را با استفاده از مدل Llama3.3 در یک محیط مستقل پایتون بهینهسازی کردیم. پرامپتهای نهایی برای تنظیمات 0-shot، -shot1 و -shot3 در بخش 2.4 با عنوان «اصلاح پرامپت» ارائه شدهاند.
پس از نهاییسازی پرامپتها، دمای LLM برابر با 0.0 تنظیم شد تا خروجیها قطعی و قابل بازتولید باشند، و مدل کامل Llama3.3-70B (با حدود 43 گیگابایت حافظه VRAM) با این قالبها و تنظیمات در pipeline (پایپ لاین) FuzzBench بارگذاری شد. برای هر تعداد shot پرامپت، سیستم از ابتدا راهاندازی شد و لاگهای تمامی اجراها بهمنظور بازتولیدپذیری، قابلیت ردیابی و تحلیل حفظ گردید.
جدول 2 روندهای مربوط به درصد پوشش شاخه (branch coverage) برای پرامپتهای 0-shot، -shot1 و -shot3 را در هر دو آزمایش فازینگ یکساعته و چهارساعته با استفاده از Llama3.3 نشان میدهد. اثر افزایش تعداد shotهای پرامپت بر پوشش کد بهشدت وابسته به بنچمارک است: بنچمارکهای libpcap fuzz both و vorbis decode fuzzer با افزایش تعداد shotها بهبود پوشش شاخه را نشان میدهند، در حالیکه harfbuzz hb-shape-fuzzer و sqlite3 ossfuzz افزایش اندک یا بدون بهبودی دارند، و بنچمارکهای libpng libpng read fuzzer و openh264 decoder fuzzer حتی در اجراهای چهارساعته کاهش پوشش را تجربه میکنند.
علاوه بر این، تحلیل لاگهای پاسخ LLM نشان داد که در حدود 35٪ موارد، وقفهی زمانی (timeout) در پاسخهای Ollama رخ داده است. اگرچه این وقفهها ممکن است تعداد جهشهای قابل استفاده را کاهش دهند، کیفیت پاسخها بهطور جداگانه با استفاده از معیارهای SCR و RDR ارزیابی میشود. در بخشهای بعدی، رابطهی میان کیفیت پاسخهای LLM و پوشش کد ترسیم شده و بینشی دربارهی ناپایداری ناشی از تغییر تعداد shotهای پرامپت ارائه میشود.
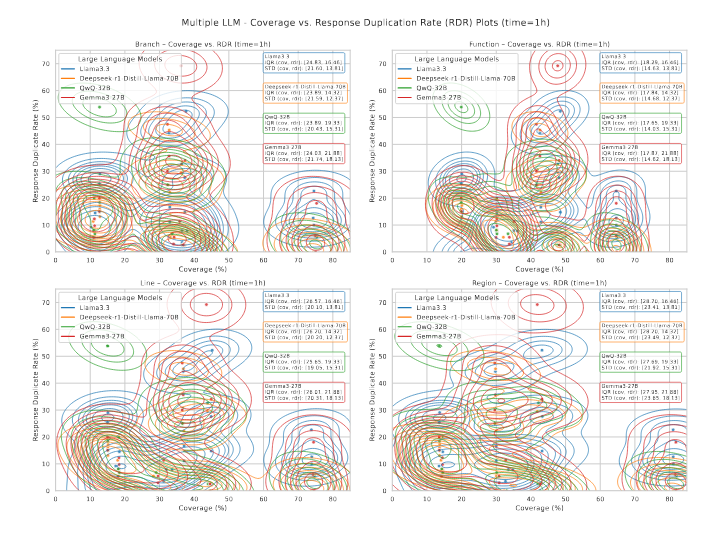
4.2.1 تحلیل نمودار: SCR و RDR در میان بنچمارکها
هر دو معیار را بر اساس لاگهای اجرای هر جفت فازر–بنچمارک (fuzzer–benchmark) و با استفاده از جداول تحلیل لاگ ساختاریافته محاسبه میکنیم. پاسخهای دارای اعتبار نحوی (syntactic-valid) از خروجیهای تولید شده توسط LLM که در این جداول ثبت شدهاند شمارش میشوند، و پاسخهای تکراری از طریق مقایسهی بخشهای «Final Output» درون همان تنظیم shot پرامپت و همان جفت فازر–بنچمارک (fuzzer–benchmark) شناسایی میگردند.
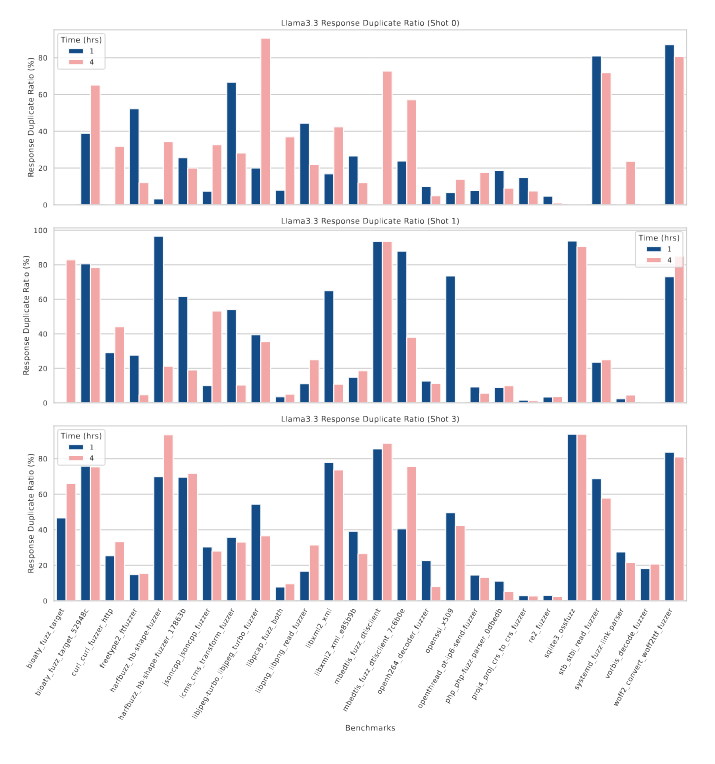
شکلهای 9 و 10 مقادیر SCR و RDR را برای هر بنچمارک در میان پرامپتهای مختلف و بازههای زمانی متفاوت نشان میدهند و اعتبار پاسخها و گرایشهای تکرار آنها را به تصویر میکشند. هر بنچمارک در نمودارها با دو مدت زمان فازینگ مرتبط است—اجرای یکساعته و چهارساعته—و رنگها این بازهها را برای مقایسه آسانتر متمایز میکنند.
با بررسی نمودارهای SCR، مشاهده میکنیم که نرخ SCR برای اکثر بنچمارکها با افزایش تعداد shotهای پرامپت کمی کاهش مییابد، که نشان میدهد پرامپتهای طولانی یا پیچیده ممکن است ریسک خطاهای قالببندی را افزایش دهند. بنچمارکهایی مانند openthread ot-ip6-send-fuzzer و woff2 convert woff2ttf fuzzer مقادیر SCR بالایی را بهطور پایدار حفظ میکنند؛ در حالیکه vorbis decode fuzzer کاهش قابل توجهی را نشان میدهد.
در نمودارهای RDR، بنچمارکهایی مانند re2 fuzzer و openthread ot-ip6-send-fuzzer در تمام shotهای پرامپت مقادیر پایینی دارند که نشاندهندهی تنوع مؤثر پاسخها است؛ در حالیکه mbedtls fuzz dtlsclient و woff2 convert woff2ttf fuzzer مقادیر بالای RDR دارند، که بیانگر تکرار مکرر خروجیهای LLM است و ممکن است توانایی مدل در کشف مسیرهای اجرایی جدید از طریق جهشهای متنوع را محدود کند.
این مشاهدات پرسشی را مطرح میکند: آیا مشکلات قالببندی یا تکرار پاسخها روند جهشها را مختل میکنند و در نتیجه پوشش کد حاصل از فازر را کاهش میدهند؟ برای بررسی رابطه بین پوشش کد و صحت نحوی و تنوع پاسخهای تولیدشده توسط LLM، ما تجسمهای اضافیای ایجاد کردیم که انواع مختلف پوشش کد (تابع، خط، شاخه و ناحیه) را با SCR و RDR در میان زمانهای فازینگ و shotهای پرامپت مختلف همبسته میکنند. نتایج این تحلیلها در بخشهای بعدی ارائه و مورد بحث قرار گرفتهاند.
4.2.2 تحلیل نمودار: پوشش کد در مقابل SCR
شکلهای 11 و 12 رابطه بین SCR و معیارهای مختلف پوشش کد را با تغییر shotهای پرامپت در طول زمان نشان میدهند. هر شکل ترکیبی از نمودار پراکندگی (scatter) و نمودار برآورد چگالی هستهای (KDE) است تا روندها و همبستگیها را برجسته کند. هر نقطه داده نمایانگر یک جفت بنچمارک–فازر است و shotهای مختلف پرامپت با رنگهای متمایز—آبی، نارنجی و سبز—نمایش داده شدهاند. نوارهای رنگی محدوده چارکها (IQR) بین چارکهای 0.25 و 0.75 را نشان میدهند و محل تجمع اکثر نقاط داده برای هر shot پرامپت را مشخص میکنند.
نمودارها نشان میدهند که مقادیر SCR عموماً با افزایش تعداد shotهای پرامپت کاهش مییابند. اگرچه برخی نقاط پرت (outlier) وجود دارند، پرامپتهای 3-shot توزیع SCR متمرکزتر و قابل پیشبینیتری دارند، با پراکندگی کمی کمتر و پوشش کد متمرکزتر نسبت به پرامپتهای 0-shot و 1-shot. این امر نشان میدهد که نمونههای اضافی به تثبیت قالببندی LLM کمک میکنند.
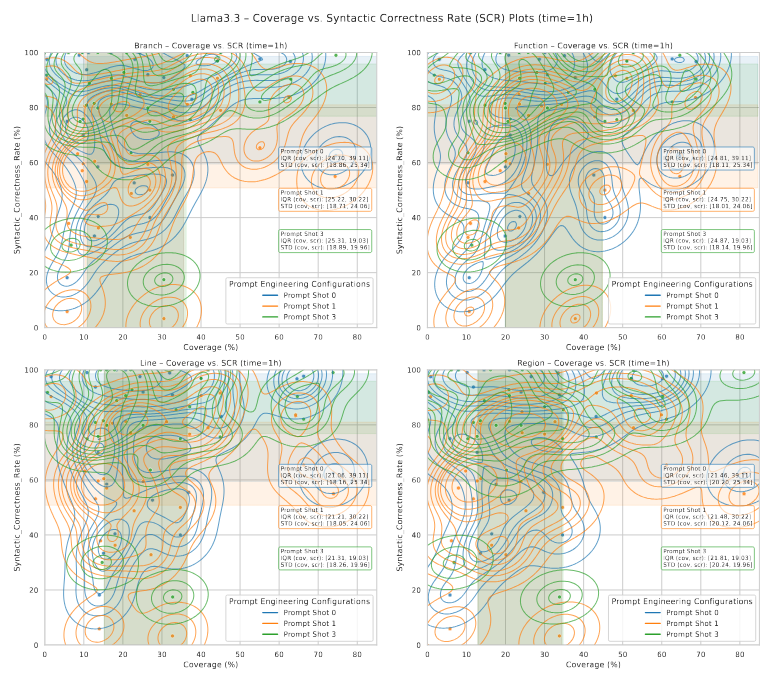
در تمامی shotهای پرامپت، مقادیر SCR حول 70–80٪ تجمع میکنند و الگوی «L شکل» در نمودارها مشاهده میشود: پوشش کد ابتدا با افزایش SCR بالا میرود اما پس از این محدوده به حالت سیر ثابت (plateau) میرسد.
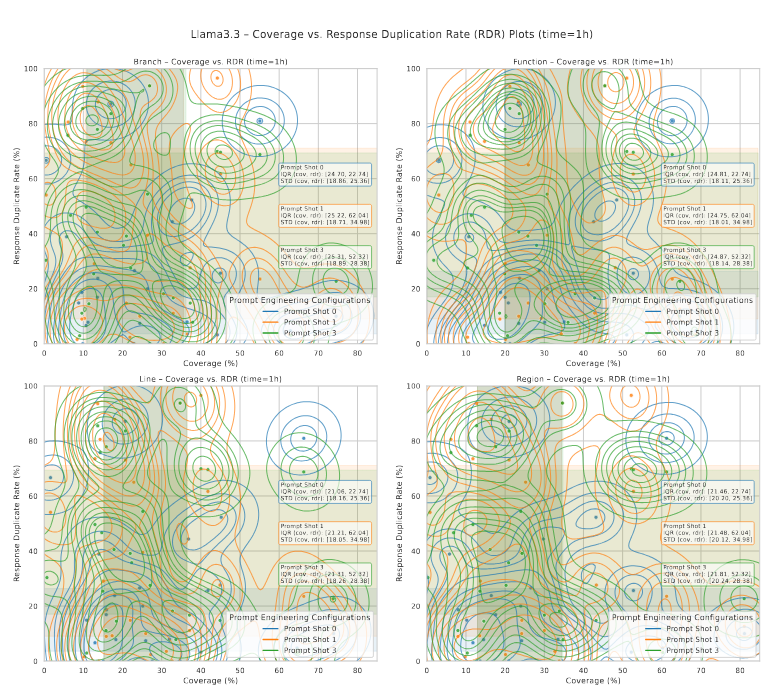
4.2.3 تحلیل نمودار: پوشش کد در مقابل RDR
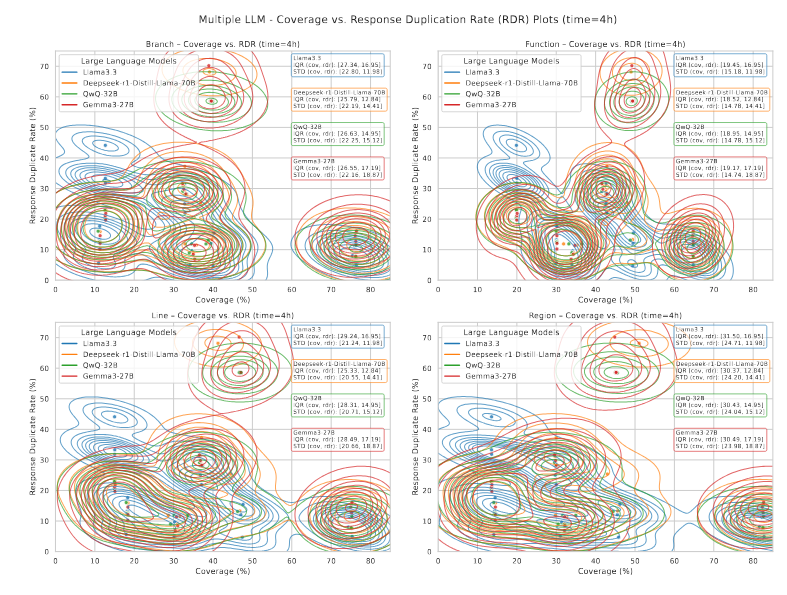
فراتر از صحت نحوی و پایداری تبدیل، تنوع جهشهای تولیدشده توسط LLM نقش حیاتی در فازینگ مؤثر دارد. خروجیهای تکراری یا مشابه LLM ممکن است تنوع جهشها را کاهش دهند و حتی در صورت صحت نحوی، قابلیت کاوش مسیرهای کد را محدود کنند.
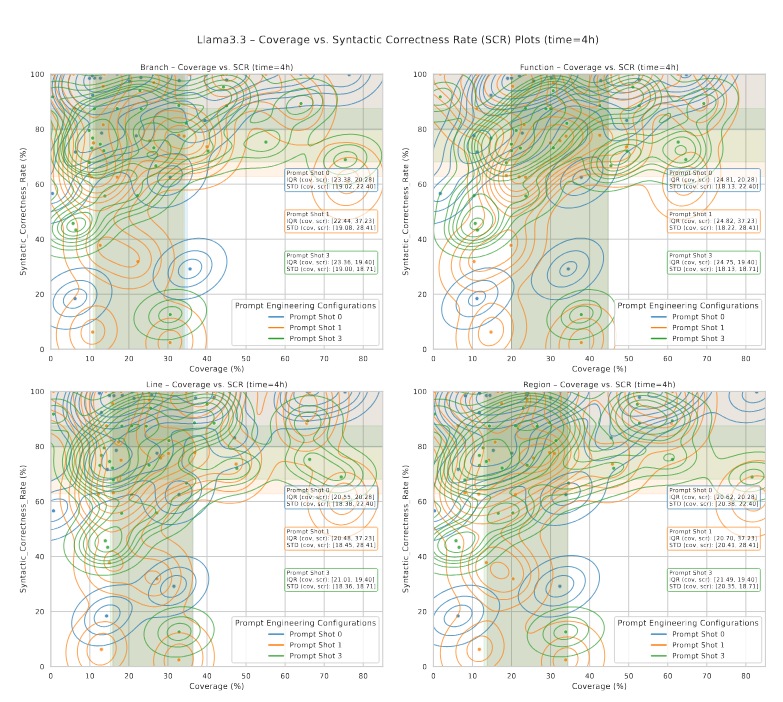
برای بررسی این عامل، شکلهای 13 و 14 نمودارهای پراکندگی (scatter) و برآورد چگالی هستهای (KDE) را نشان میدهند که نسبت تکرار پاسخ (RDR) را با پوشش نهایی کد در میان shotهای مختلف پرامپت و بازههای زمانی مختلف مرتبط میسازند؛ رنگها در نمودارها متناظر با shotهای پرامپت هستند.
نمودارها نشان میدهند که RDR پایینتر معمولاً با پوشش کد بالاتر مرتبط است، که حاکی از آن است که تنوع بیشتر پاسخها فازینگ مؤثرتری را ترویج میکند؛ در حالیکه RDRهای بالاتر در پوشش پایینتر تجمع مییابند و نشان میدهند که پاسخهای تکراری تولید ورودیهای جدید را محدود میکنند. این روند در بازهی فازینگ چهارساعته واضحتر است.
نمودارهای KDE این تفسیر را تقویت میکنند: پرامپتهای Three-shot به طور کلی پاسخهای تکراری بیشتری تولید میکنند، در ابتدا پوشش گستردهتر و چگالی بالاتر در مناطق با تکرار پایین دارند، اما در اجراهای طولانیتر به پوشش محدودتر و RDR بالاتر منتقل میشوند.
این مشاهدات نشان میدهند که افزایش تعداد shotهای پرامپت میتواند تنها زمانی ورودیهای جهشیافته مؤثر تولید کند که تکرار پاسخهای LLM همچنان پایین باقی بماند.
4.3 آزمایش مقایسه چند LLM
این آزمایش کارایی نسبی چند مدل پیشرفتهی LLM را تحت استراتژیهای جهش ما ارزیابی میکند و بدینترتیب به پرسشهای پژوهشی R3 و R4 پاسخ میدهد. بر اساس نتایج بخش 4.2، ما شش بنچمارک با واریانس بالای پوشش کد و همچنین LLMهای Llama3.3 [23]، Deepseek-r1-Distill-Llama-70B [24]، QwQ-32B [26] و Gemma3-27B [25] را برای این آزمایش انتخاب کردیم. از آنجایی که Llama3.3 قبلاً در این بنچمارکها در آزمایشهای پیشین ارزیابی شده بود، اجرای آن کنار گذاشته شد اما بهعنوان مرجع نگه داشته شد.
تنظیمات آزمایش مشابه آزمایش بخش 4.2 بود. هر LLM در یک جلسه فازینگ تازه ارزیابی شد، بهصورت مستقل در Ollama بارگذاری گردید و در تمام شش بنچمارک، سه shot پرامپت و دو بازه زمانی مورد آزمایش قرار گرفت. پس از هر اجرا، پوشش نهایی کد ثبت شد. بر اساس این دادهها، جدول 3 تعداد دفعاتی که هر LLM بیشترین پوشش کد را در بازههای زمانی مختلف بهدست آورده است، خلاصه میکند. نتایج نشان میدهند که Llama3.3 بهطور مداوم در اجراهای کوتاه (مثلاً یکساعته) عملکرد بهتری نسبت به سایر مدلها دارد، در حالیکه Deepseek-r1-Distill-Llama-70B عمدتاً در اجراهای چهارساعته بهترین عملکرد را نشان میدهد.
علاوه بر این، جدول 4 درصد بهبود (CIP) فازر هدایتشده توسط بهترین LLM نسبت به خط پایه AFL++ را برای هر shot پرامپت، بر اساس پوشش شاخه، گزارش میکند. در میان شش بنچمارک ارزیابیشده برای پوشش شاخه با پرامپتهای -shot3، چهار بنچمارک CIP مثبت در اجراهای یکساعته نشان میدهند که فازرهای هدایتشده توسط LLM عموماً در اجراهای کوتاه از خط پایه AFL++ عملکرد بهتری دارند، اگرچه این روند همیشه در اجراهای طولانیتر برقرار نیست.
برای تعیین اینکه کدام LLM بهطور کلی بهترین عملکرد را دارد و پاسخ به پرسش پژوهشی R4، در ادامه کیفیت پاسخ مدلها را از نظر صحت نحوی (SCR) و تنوع پاسخها (RDR) تحلیل میکنیم. ابتدا معیارهای SCR و RDR برای هر LLM در تمام سه shot پرامپت ارزیابی شدند، سپس پوشش کد برای تمام LLMهای منتخب در مقابل این معیارها ترسیم شد.
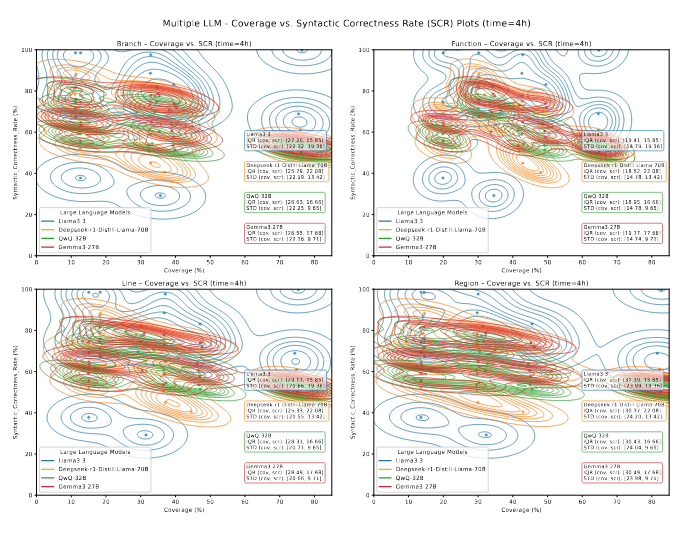
شکلهای 15 و 16 رابطه بین پوشش کد و SCR را در میان LLMها و shotهای پرامپت به تصویر میکشند؛ و شکلهای 17 و 18 همبستگی بین پوشش کد و RDR را نشان میدهند.
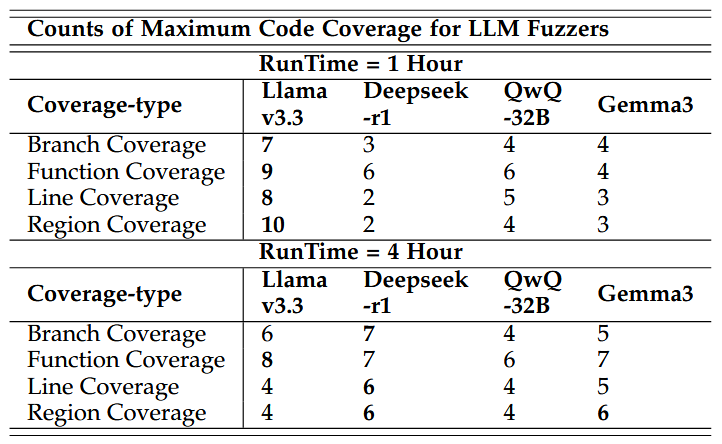
نمودارهای SCR نشان میدهند که همهی مدلها همزمان با بهبود پوشش کد، به صحت نحوی بالاتری دست مییابند. Llama3.3 بهطور مداوم قویترین همبستگی SCR–پوشش را در اجرای یکساعته حفظ میکند و نمودارهای KDE آن در نواحی با SCR بالا و پوشش متوسط تا بالا متمرکز هستند. با این حال، SCR آن هنگامی که مدت فازینگ به چهار ساعت افزایش مییابد کاهش مییابد، که نشان میدهد ثبات قالببندی با گذر زمان ممکن است کاهش یابد و میتواند از محدودیتهای زمانی بهرهمند شود.
Deepseek-r1-Distill-Llama-70B تنوع بالاتری در SCR نشان میدهد، با پراکندگی پوشش کمی باریکتر نسبت به Llama3.3، که حساسیت بیشتری نسبت به نوسانات پاسخها را نشان میدهد. با وجود ناپایداری صحت نحوی در اجراهای طولانیتر، این مدل همچنان پوشش ثابتی را حفظ میکند.
Gemma3-27B در اجراهای یکساعته SCR پایین و توزیعهای پراکنده KDE در میان shotهای مختلف پرامپت و انواع پوشش نشان میدهد، که حاکی از ثبات قالببندی ضعیفتر و پوشش اولیه کمتر امیدوارکننده نسبت به Deepseek است.
QwQ-32B پوشش نسبتاً متعادلی با نوسانات متوسط ارائه میدهد، اما مقادیر پایین SCR آن در اجراهای چهارساعته نشاندهندهی قابلیت محدود قالببندی است.
در نمودارهای RDR، Deepseek-r1-Distill-Llama-70B بهطور مداوم RDR پایینی دارد—بهویژه در فازینگ طولانیمدت. این مدل با وجود تنوع نسبتا بالای SCR، چگالیهای متمرکز با RDR پایین را حفظ میکند که نشان میدهد بهطور مکرر ورودیهای متنوع و با قالببندی خوب تولید میکند و عملکرد پوشش کد پایدار را حفظ میکند.
در مقابل، Gemma3-27B مقادیر پراکندهای از RDR نشان میدهد که تولید پاسخهای تکراری مکرر را القا میکند. Llama3.3 RDR پایین دارد اما با نوسانات پوشش بیشتر نسبت به Deepseek همراه است. QwQ-32B در هر دو شاخص تنوع و پوشش در محدوده متوسط باقی میماند.
4.4 بحث
پس از ارزیابی نتایج تجربی با استفاده از چهار معیار کلیدی پوشش دقیق کد، CIP، SCR و RDRما روندها را تحلیل کردیم تا بررسی کنیم که چگونه صحت نحوی LLM و تنوع پاسخها بر عملکرد فازینگ تأثیر میگذارند. این معیارها بهطور مشترک یک پایه جامع برای پاسخ به پرسشهای پژوهشی ما فراهم میکنند.
بخشهای بعدی یافتههای کلیدی استخراج شده از جداول و نمودارهای نتایج را برجسته میکنند.
4.4.1 مشاهده 1: یافتهها مرتبط با R2
آزمایشهای مهندسی پرامپتLlama3.3 نشان میدهند که افزایش تعداد shotهای پرامپت لزوماً پوشش کد را بهطور مداوم بهبود نمیبخشد. در حالی که برخی بنچمارکها از مثالهای زمینهای اضافی بهره میبرند، سایر بنچمارکها تأثیر کمی یا حتی منفی نشان میدهند. این امر نشان میدهد که پیچیدگی پرامپت بهطور خطی با اثربخشی فازینگ همبستگی ندارد.
در مواردی که پوشش کد بهبود مییابد، مثالهای طولانیتر در پرامپت ممکن است صحت نحوی پاسخهای LLM را افزایش دهند. برعکس، کاهش پوشش در برخی بنچمارکها ممکن است ناشی از افزایش پیشبینیپذیری و کاهش تنوع اکتشافی در خروجیهای LLM باشد. این مبادلهها نیاز به تعادل میان ساختار پرامپت و تنوع مدل را نشان میدهند، که در بحثهای بعدی به طور جامعتر بررسی میشود.
4.4.2 مشاهده 2: یافتهها مرتبط با R3
نتایج CIP نشان میدهند که هیچ یک از LLMها بهطور مداوم در تمامی بنچمارکها و shotهای پرامپت عملکرد بهتری نسبت به خط پایه ++AFL ندارند. در حالی که برخی LLMها در بنچمارکهای خاص از ++AFL پیشی میگیرند، موارد زیادی نیز وجود دارد که LLMها عملکرد ضعیفتری دارند، که نشان میدهد مدلهای پیشرفته فعلی بهطور جهانی بر فازرهای سنتی برتری ندارند.
در میان مدلها، Llama3.3 قویترین همبستگی مستقیم بین صحت نحوی و پوشش کد را نشان میدهد و بهترین عملکرد را در مراحل اولیه فازینگ ارائه میکند. در حالی که Deepseek-r1-Distill-Llama-70B نسبت به تنوع پاسخ حساسیت بالایی دارد، بهطور مداوم ورودیهای جهشیافته با قالببندی پایدار تولید میکند و در آزمایشهای فازینگ بلندمدت بهترین عملکرد را دارد.
Gemma3-27B و QwQ-32B در اجراهای طولانیتر عملکرد متوسطی دارند—Gemma3 ثبات بیشتری ارائه میدهد و QwQ ثبات قالببندی ضعیفتری دارد—که آنها را به گزینههای مناسبی برای خط پایه میانرده و ارزیابی نتایج پیشبینیپذیر تبدیل میکند.
بهطور کلی، Llama3.3 و Deepseek-r1-Distill-Llama-70B کاندیداهای قوی برای تحقیقات بیشتر هستند: Llama3.3 برای فازینگ در مراحل اولیه با نوسان خطای کم، و Deepseek برای کاوش آسیبپذیریهای بلندمدت.
4.4.3 مشاهده 3: تأثیر صحت نحوی (Syntactic Correctness) بر پوشش کد (Code Coverage)
هم در مقایسه چند LLM و هم در آزمایشهای مهندسی پرامپت Llama3.3، رابطه بین پوشش کد و صحت نحوی LLM (یعنی SCR) بررسی شد. نتایج نشان میدهند که پوشش کد بالاتر معمولاً با مقادیر بالاتر SCR همراه است، در حالی که افزایش shotهای پرامپت مقادیر SCR را تثبیت کرده و ممکن است پوشش را بهبود بخشد. این امر نشان میدهد که صحت نحوی بهتر، ورودیهای جهشیافته قابلاستفادهتر و کاوش مسیرهای بیشتری را امکانپذیر میکند.
با این حال، این اثر یک الگوی آستانهای (threshold) دارد: پس از یک نقطه مشخص، بهبود بیشتر در SCR منجر به افزایش بیشتر پوشش کد نمیشود و در نمودارهای رابطه SCR–پوشش، یک الگوی «L» شکل ایجاد میکند.
این یافتهها نشان میدهند که اگرچه صحت نحوی ضروری است، اما بهتنهایی برای بهبود مداوم کارایی فازینگ کافی نیست و نیاز به در نظر گرفتن عوامل اضافی برای ارتقای عملکرد فازینگ وجود دارد.
4.4.4 مشاهده 4: تأثیر تنوع پاسخ بر پوشش کد
تنوع پاسخهای LLM، که با RDR اندازهگیری میشود، یکی دیگر از عوامل کلیدی مؤثر بر اثربخشی فازینگ است. نمودارهای رابطه RDR–پوشش نشاندهندهی یک رابطه معکوس بین RDR و پوشش کد هستند: RDR پایینتر معمولاً با پوشش بالاتر همراه است، که نشان میدهد تنوع بیشتر جهشها باعث تولید موارد آزمایشی مؤثرتر میشود.
افزایش shotهای پرامپت در اجرای یکساعته تمایل دارد مقادیر RDR را افزایش دهد، زیرا ممکن است LLM خروجیهای تعیینشدهتری تولید کند. در اجراهای چهارساعته، RDR در میان shotهای پرامپت بسیار متغیر است، در حالی که پوشش نسبتاً پایدار باقی میماند، که نشان میدهد مثالهای زمینهای اضافی میتوانند تکرار را افزایش دهند بدون آنکه پوشش بهبود یابد.
این مشاهدات یک مبادله احتمالی را برجسته میکنند: مهندسی پرامپت میتواند صحت نحوی را بهبود بخشد اما تنوع پاسخ را کاهش دهد. بنابراین، تعادل بین صحت نحوی و تنوع پاسخ برای بهینهسازی عملکرد فازینگ هدایتشده توسط LLM ضروری است.
4.4.5 مشاهده 5: تأثیرات اضافی در نتایج فازینگ
تحلیل لاگها نشان میدهد که تقریباً 35٪ از درخواستهای LLM با استفاده از Ollama با خطای timeout مواجه شدند، بهویژه زمانی که پرامپتها طولانیتر یا تعداد shotها بیشتر بود. این رفتار timeout تحویل مداوم جهشهای تولیدشده توسط LLM را در زمان واقعی محدود میکند و تعداد جهشهای مؤثر در طول فازینگ را کاهش میدهد.
اگرچه سیستم ما از استراتژیهای جهش پیشفرض ++AFL برای ادامه عملیات زمانی که LLM پاسخ نمیدهد استفاده میکند، این امر میتواند منجر به تولید مسیرهای کمتر نوآورانه شده و مزایای هدایتشده توسط LLM را کاهش دهد. این یافتهها اهمیت پاسخگویی و پایداری LLM را در راهکار ما برجسته میکنند.
5. نتیجهگیری و کارهای آینده
ما یک فازر جدید مبتنی بر جهش ارائه کردیم که مدلهای LLM دارای توانایی استدلال آماده را در ++AFL و در قالب معماری میکروسرویسها یکپارچه میکند، و امکان انجام آزمایشهای گسترده و قابل بازتولید را از طریق پلتفرم بنچمارک Fuzzbench گوگل فراهم میآورد. چارچوب ما به چالشهای 1 تا 4 در یکپارچهسازی سیستم و ساختاردهی پرامپت (R1) پاسخ میدهد و یک مطالعه تجربی برای ارزیابی LLMهای متنباز پیشرفته در فازینگ مبتنی بر جهش ارائه میکند.
مطالعه ما بهطور سیستماتیک اثرات مهندسی پرامپت—با استفاده از یادگیری صفر-شات، یک-شات و سه-شات—و همچنین استنتاج LLM بر کیفیت جهشها و کارایی فازینگ را بررسی کرد.
یافتههای کلیدی عبارتند از:
- Shotهای پرامپت (R2): افزایش تعداد shotهای پرامپت بهطور خطی باعث بهبود فازینگ نمیشود. پرامپتهای با shot بالاتر میتوانند صحت نحوی را افزایش دهند، اما ممکن است خروجیهای LLM بیش از حد تعیینشده شوند و تنوع جهشها کاهش یابد. بنابراین، تعادل بین طراحی پرامپت و رفتار مدل برای فازینگ مؤثر هدایتشده توسط LLM حیاتی است.
- عملکرد LLMهای استدلالگر (R3): هیچ یک از LLMهای استدلالگر بهطور مداوم بدون تنظیم یا آموزش اضافی در تولید جهشها از فازرهای سنتی پیشی نمیگیرند. با این حال، 3 و Deepseek-r1-Distill-Llama-70B پتانسیل بالایی برای بهبود اثربخشی جهشها نشان میدهند.
- انتخاب بهترین LLM (R4): Deepseek-r1-Distill-Llama-70B بهترین تعادل را بین تنوع خروجی و صحت نحوی ایجاد میکند و آن را به کاندیدای اصلی برای بهبود کیفیت جهشها و پوشش کد در فازینگ بلندمدت در چارچوب ما تبدیل میکند.
- صحت نحوی در مقابل تنوع پاسخ: فازینگ مؤثر هدایتشده توسط LLM نیازمند تعادل بین صحت نحوی و تنوع پاسخها است. در حالی که SCR پایدار، جهشهای معتبر را تضمین میکند، سطوح بالاتر SCR فراتر از یک آستانه، پوشش کد را افزایش نمیدهند. تنوع پاسخ بهبود یافته، کارایی فازینگ را افزایش میدهد و نشان میدهد که خروجیهای LLM هم با قالببندی مناسب و هم متنوع برای فازینگ هدایتشده توسط LLM ضروری هستند.
- تاخیر پاسخ LLM و Timeoutها: پرامپتهای طولانی یا پیچیده میتوانند باعث تاخیر در پاسخ LLM یا وقوع timeout شوند، که منجر به کاهش تعداد جهشهای مؤثر و محدود شدن مزایای ادغام LLM میگردد. فازینگ مقیاسپذیر نیازمند بهینهسازی پاسخگویی LLM و زیرساختهای استقرار آن است.
با وجود نتایج امیدوارکننده، رویکرد ما دارای پنج محدودیت است:
- جهشها گاهی از قالبهای مورد نیاز منحرف میشوند،
- LLMها پشتیبانی باینری بومی ندارند،
- ورودیهای بزرگ میتوانند از محدودیت توکنها عبور کنند یا timeout ایجاد کنند،
- مقیاس آزمایش بهدلیل محدودیتهای زمانی و منابع محدود بود، و
- Fuzzbench تنها گزارشهای جزئی یک اجرای آزمایشی را نگه میدارد—که تحلیل چند اجرای آزمایشی را محدود میکند.
کارهای آینده شامل بررسی فاینتیون کردن LLMها—با استفاده از بازخورد خودکار جهشها و پیادهسازی از طریق یادگیری تقویتی یا Direct Preference Optimization (DPO)—برای بهبود همزمان صحت نحوی و تنوع جهشها است، تا ورودیهای مؤثرتری برای فازینگ هدایتشده توسط LLM تولید شود.
جهتهای دیگر شامل بهینهسازی خط لوله Fuzzbench و زیرساخت سرویسدهی LLM، بررسی استراتژیهای تقسیم ورودی (input chunking)، و گسترش آزمایشها به مدتهای طولانیتر فازینگ است. این تلاشها با هدف افزایش مقیاسپذیری، پایداری و اثربخشی فازینگ مبتنی بر جهش هدایتشده توسط LLM انجام میشوند.
6. کارهای مرتبط
فازرهای سنتی جعبه خاکستری (Grey-box) بر اساس جهشهای ورودی تصادفی یا مبتنی بر قواعد تجربی (heuristic) برای کشف آسیبپذیریها در برنامههای هدف از طریق تست brute-force عمل میکنند [5]. در حالی که AFL [38] و AFL++ [11] با استفاده از الگوریتمهای تکاملی مبتنی بر بازخورد، کارایی را بهبود بخشیدند، استراتژیهای جهش آنها هنوز سطحی و محدود هستند و کشف آسیبپذیریهای عمیقتر را محدود میکنند.
LibFuzzer [39] و SelectFuzz [43] ابزارسازی (instrumentation) را برای پایش پوشش کد بهینه کرده و از بازخورد برای هدایت جهشهای ورودی استفاده میکنند، اما هنوز از استراتژیهای جهش استاتیک و مبتنی بر قواعد استفاده میکنند که با ورودیهایی که نیازمند محدودیتهای نحوی یا معنایی پیچیده هستند مشکل دارند و اغلب ورودیهای نامعتبر یا غیر مؤثر تولید میکنند [44]، [45]. این چالشها کشف باگهای عمیقتر را دشوار میسازد—بهویژه در سیستمهای نرمافزاری مدرن که به دلیل تغییرات مکرر در پیادهسازی، منطق و فرمتهای آنها بهطور مداوم تکامل مییابند [16].
برای غلبه بر این محدودیتها، پژوهشگران به اولویتبندی هوشمند ورودیها و تکنیکهای جهش پیشرفته پرداختهاند [10]، [46]، [47]، که منجر به ادغام یادگیری ماشین و اخیراً LLMها در جریانهای فازینگ شده است. فازرهای تقویتشده با ML مانند V-Fuzz [47] و CTFuzz [10] از شبکههای عصبی یا یادگیری تقویتی برای اولویتبندی ورودیها و هدایت استراتژیهای جهش استفاده میکنند و کارایی بهتری نسبت به جهشهای تصادفی ارائه میدهند.
ظهور LLMها امکان درک معنایی فرمت ورودیها و هدایت جهشها را بیشتر فراهم کرده است، با دو رویکرد اصلی:
- فاینتیون کردن [48] مدل، که LLMها را از طریق آموزش نظارتشده بر ورودیهای خاص حوزه تطبیق میدهد، و
- مهندسی پرامپت [22]، که پرامپتهای ساختاریافته در زمان استنتاج ایجاد میکند بدون نیاز به آموزش مجدد.
با این حال، فاینتیون کردن نیازمند دادههای برچسبخورده است و جهشها را به قواعد موجود محدود میکند و هزینه محاسباتی بالایی دارد. بهعنوان مثال، LLAMAFUZZ [19] در برخی بنچمارکها از AFL++ پیشی میگیرد، اما در تعمیم به برنامهها، فرمتها یا حوزههای جدید با مشکل مواجه میشود.
در مقابل، مهندسی پرامپت سبک و انعطافپذیر است، اما فازرهای فعلی—مانند Fuzz4All [16]، PromptFuzz [17] و CHATAFL [18]—LLMها را بهصورت جعبه سیاه برای تولید ورودی–خروجی بهکار میبرند و بینشی از نحوه ایجاد جهشها ارائه نمیکنند.
LLMهای مجهز به توانایی استدلال یک مسیر امیدوارکننده جدید ارائه میدهند، زیرا فرایند جهش را شفافتر میکنند. برخلاف روشهای صرفاً مبتنی بر پرامپت، LLMهای استدلالگر مانند Llama3 [23]، Deepseek-r1 [24] و Gemma3 [25] توالی منطقی استدلال یا «chain-of-thought» تولید میکنند که توضیح میدهد خروجی نهایی چگونه بهدست آمده است. این قابلیت نهتنها طراحی بهتر پرامپت را ممکن میسازد، بلکه جهشهای تکراری یا نامعتبر را کاهش داده و امکان کاوش مسیرهای عمیقتر را فراهم میکند.
با وجود این پتانسیل، فازینگ هدایتشده توسط استدلال هنوز کمتر بررسی شده است: هیچ کار پیشین بهطور سیستماتیک LLMهای استدلالگر را در اهداف متنوع بنچمارک نکرده و بررسی نکرده است که استراتژیهای shot پرامپت چگونه بر تنوع جهش و صحت نحوی تأثیر میگذارند. با پر کردن این خلا، پژوهش ما LLMهای استدلالگر را با ++AFL در چارچوب FuzzBench یکپارچه میکند و اولین تحلیل تجربی یادگیری با shot پرامپت، تکرار پاسخ و صحت نحوی در فازینگ هدایتشده توسط LLMهای استدلالگر را ارائه میدهد.
7. منابع
[1] P. Mell and T. Grance, “Use of the common vulnerabilities and exposures (cve) vulnerability naming scheme,” National Institute of Standards and Technology, Gaithersburg, MD, Special Publication NIST SP 800-51, 2002, accessed: 2025-06-02.
[2] NIST, “National vulnerability database (nvd),” https://nvd.nist.gov, 2025, accessed: 2025-06-02.
[3] T. Sasi, A. H. Lashkari, R. Lu, P. Xiong, and S. Iqbal, “A comprehensive survey on iot attacks: Taxonomy, detection mechanisms and challenges,” Journal of Information and Intelligence, vol. 2, no. 6, pp. 455– 513, 2024.
[4] L. D. Xu, W. He, and S. Li, “Internet of things in industries: A survey,” IEEE Transactions on Industrial Informatics, vol. 10, no. 4, pp. 2233–2243, November 2014.
[5] M. Sutton, A. Greene, and P. Amini, “What is fuzzing?” in Fuzzing: Brute Force Vulnerability Discovery. Addison-Wesley Professional, 2007, pp. 26–52.
[6] S. Bekrar, C. Bekrar, R. Groz, and L. Mounier, “Finding software vulnerabilities by smart fuzzing,” in 2011 Fourth IEEE International Conference on Software Testing, Verification and Validation, 2011, pp. 427–430.
[7] M. Eceiza, J. L. Flores, and M. Iturbe, “Fuzzing the internet of things: A review on the techniques and challenges for efficient vulnerability discovery in embedded systems,” IEEE Internet of Things Journal, vol. 8, no. 13, pp. 10 390–10 411, 2021.
[8] C. Beaman, M. Redbourne, J. D. Mummery, and S. Hakak, “Fuzzing vulnerability discovery techniques: Survey, challenges and future directions,” Computers & Security, vol. 120, p. 102813, 2022.
[9] K. Alshmrany, M. Aldughaim, A. Bhayat, and L. Cordeiro, “Fusebmc v4: Improving code coverage with smart seeds via bmc, fuzzing and static analysis,” Form. Asp. Comput., vol. 36, no. 2, Jun. 2024.
[10] V.-H. Pham, D. Thi Thu Hien, N. Phuc Chuong, P. Thanh Thai, and P. The Duy, “A coverage-guided fuzzing method for automatic software vulnerability detection using reinforcement learning-enabled multi-level input mutation,” IEEE Access, vol. 12, pp. 129 064–129 080, 2024.
[11] A. Fioraldi, D. Maier, H. Eißfeldt, and M. Heuse, “Afl++: combining incremental steps of fuzzing research,” in Proceedings of the 14th USENIX Conference on Offensive Technologies, ser. WOOT’20. USA: USENIX Association, 2020.
[12] X. Du, A. Chen, B. He, H. Chen, F. Zhang, and Y. Chen, “Afliot: Fuzzing on linux-based iot device with binary-level instrumentation,” Computers & Security, vol. 122, p. 102889, 2022. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S01674048220 02838
[13] A. Touqir, F. Iradat, W. Iqbal et al., “Systematic exploration of fuzzing in iot: Techniques, vulnerabilities, and open challenges,” The Journal of Supercomputing, vol. 81, no. 3, p. 877, 2025, accepted: 30 April 2025; Published: 23 May 2025. [Online]. Available: https://doi.org/10.1007/s11227-025-07371-y
[14] A. Helin, “Efficient fuzzing payload generation for mobile application security testing,” Master’s Thesis, Aalto University, Espoo, Finland, May 2024, master’s Programme in Computer, Communication and Information Sciences, Major in Computer Science, Mcode: SCI3042. [Online]. Available: https://aaltodoc.aalto.fi/items/4fede532-9b54-4902-ba08- 1b1c02391945
[15] S. Kim, M. Liu, J. J. Rhee, Y. Jeon, Y. Kwon, and C. H. Kim, “Drivefuzz: Discovering autonomous driving bugs through driving quality- guided fuzzing,” in Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, 2022, pp. 1753–1767.
[16] C. S. Xia, M. Paltenghi, J. Le Tian, M. Pradel, and L. Zhang, “Fuzz4all: Universal fuzzing with large language models,” in Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, ser. ICSE ’24. Association for Computing Machinery, 2024.
[17] Y. Lyu, Y. Xie, P. Chen, and H. Chen, “Prompt fuzzing for fuzz driver generation,” in Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’24. New York, NY, USA: Association for Computing Machinery, 2024, p. 3793–3807.
[18] R. Meng, M. Mirchev, M. Böhme, and A. Roychoudhury, “Large language model guided protocol fuzzing,” in Proceedings of the 31st Network and Distributed System Security Symposium (NDSS). The Internet Society, 2024.
[19] H. Zhang, Y. Rong, Y. He, and H. Chen, “Llamafuzz: Large language model enhanced greybox fuzzing,” arXiv preprint arXiv:2406.07714, 2024.
[20] J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in Proceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY, USA: Curran Associates Inc., 2022.
[21] J. Metzman, L. Szekeres, L. Simon, R. Sprabery, and A. Arya, “Fuzzbench: an open fuzzer benchmarking platform and service,” in Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ser. ESEC/FSE 2021. New York, NY, USA: Association for Computing Machinery, 2021, p. 1393–1403.
[22] N. Knoth, A. Tolzin, A. Janson, and J. M. Leimeister, “Ai literacy and its implications for prompt engineering strategies,” Computers and Education: Artificial Intelligence, vol. 6, p. 100225, 2024.
[23] A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, Letman, A. Mathur, and J. J. et al., “The llama 3 herd of models,” 2024.
[24] DeepSeek-AI, G. Daya, Y. Dejian, and Z. e. a. Haowei, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,” 2025.
[25] T. Gemma, K. Aishwarya, F. Johan, P. Shreya, V. Nino, and M. e. a. Ramona, “Gemma 3 technical report,” 2025.
[26] Qwen Team, “Qwq-32b: Embracing the power of reinforcement learning,” https://qwenlm.github.io/blog/qwq-32b/, 2025, blog post.
[27] K. T. Chitty-Venkata, S. Raskar, B. Kale, F. Ferdaus, A. Tanikanti, K. Raffenetti, V. Taylor, M. Emani, and V. Vishwanath, “Llm-inference- bench: Inference benchmarking of large language models on ai accelerators,” in SC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2024, pp. 1362–1379.
[28] S. Meier, “Bringing fuzzing capabilities to the genode framework,” Master’s Thesis, University of Applied Sciences Rapperswil, 2021, accessed: 2025-06-03.
[29] J. Metzman, L. Szekeres, L. Simon, R. Sprabery, and A. Arya, “Fuzzbench: an open fuzzer benchmarking platform and service,” in Proceedings of the 29th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering, 2021, pp. 1393–1403.
[30] D. Eddelbuettel, “A Brief Introduction to Redis,” arXiv e-prints, p. arXiv:2203.06559, Mar. 2022.
[31] A. Gupta, S. Tyagi, N. Panwar, S. Sachdeva, and U. Saxena, “Nosql databases: Critical analysis and comparison,” in 2017 International Conference on Computing and Communication Technologies for Smart Nation (IC3TSN), 2017, pp. 293–299.
[32] F. S. Marcondes, A. Gala, R. Magalhães, F. Perez de Britto, D. Durães, and P. Novais, “Using ollama,” in Natural Language Analytics with Generative Large-Language Models: A Practical Approach with Ollama and Open-Source LLMs. Springer, 2025, pp. 23–35.
[33] Z. Guo, M. Schlichtkrull, and A. Vlachos, “A survey on automated fact- checking,” Transactions of the Association for Computational Linguistics, vol. 10, pp. 178–206, 2022. [Online]. Available: https://doi.org/10.1162/tacl_a_00460
[34] M. Shanahan, K. McDonell, and L. Reynolds, “Role play with large language models,” Nature, vol. 623, no. 7987, pp. 493–498, 2023.
[35] DAIR.AI, “Prompt engineering guide,” https://www.promptingguide.ai, 2023, accessed: 2025-05-30.
[36] H. Dang, K. Benharrak, F. Lehmann, and D. Buschek, “Beyond text generation: Supporting writers with continuous automatic text summaries,” in Proceedings of the ACM Symposium on User Interface Software and Technology (UIST), M. Agrawala, J. O. Wobbrock, E. Adar, and V. Setlur, Eds. ACM, 2022.
[37] K. Serebryany, “OSS-Fuzz - google’s continuous fuzzing service for open source software.” Vancouver, BC: USENIX Association, Aug. 2017.
[38] M. Zalewski, “American fuzzy lop,” https://lcamtuf.coredump.cx/afl/, 2013, accessed: 2025-06-03.
[39] Google, “Libfuzzer – a library for coverage-guided fuzz testing,” https://llvm.org/docs/LibFuzzer.html, 2018, accessed: 2025-05-30.
[40] W.-C. Chao, S.-C. Lin, Y.-H. Chen, C.-W. Tien, and C.-Y. Huang, “Design and implement binary fuzzing based on libfuzzer,” in 2018 IEEE Conference on Dependable and Secure Computing (DSC). IEEE, 2018, pp. 1–2.
[41] A. Fioraldi, D. C. Maier, D. Zhang, and D. Balzarotti, “Libafl: A framework to build modular and reusable fuzzers,” in Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, 2022, pp. 1051–1065.
[42] C. Lyu, M. Zhang, and Y. Zhang, “Automatic generation of syntax- guided test programs,” in 28th USENIX Security Symposium (USENIX Security 19). USENIX Association, 2019.
[43] C. Luo, W. Meng, and P. Li, “Selectfuzz: Efficient directed fuzzing with selective path exploration,” in 2023 IEEE Symposium on Security and Privacy (SP), 2023, pp. 2693–2707.
[44] T. Ji, Z. Wang, Z. Tian, B. Fang, Q. Ruan, H. Wang, and W. Shi, “Aflpro: Direction sensitive fuzzing,” Journal of Information Security and Applications, vol. 54, p. 102497, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S22142126193 05733
[45] V.-H. Pham, D. Thi Thu Hien, N. Phuc Chuong, P. Thanh Thai, and P. The Duy, “A coverage-guided fuzzing method for automatic software vulnerability detection using reinforcement learning-enabled multi-level input mutation,” IEEE Access, vol. 12, pp. 129 064–129 080, 2024.
[46] D. She, K. Pei, D. Epstein, J. Yang, B. Ray, and S. Jana, “Neuzz: Efficient fuzzing with neural program smoothing,” in 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 803–817.
[47] Y. Li, S. Ji, C. Lyu, Y. Chen, J. Chen, Q. Gu, C. Wu, and R. Beyah, “V- fuzz: Vulnerability prediction-assisted evolutionary fuzzing for binary programs,” IEEE Transactions on Cybernetics, vol. 52, no. 5, pp. 3745– 3756, 2022.
[48] N. Ding, Y. Qin, G. Ke, W. Wang, Y. Shen, W. Chen, Z. Gan, X. Liu, J. Gao, and Y. Yang, “Parameter-efficient fine-tuning of large-scale pre- trained language models,” Nature Machine Intelligence, vol. 5, pp. 220–235, March 2023. [Online]. Available: https://doi.org/10.1038/s42256-023- 00626-4