
این مقاله به بررسی ادغام تکنیکهای اجرای نمادین (Symbolic Execution) و فازینگ (Fuzzing) برای افزایش تشخیص آسیبپذیریهای نرمافزاری میپردازد. با افزایش پیچیدگی سیستمهای نرمافزاری و تهدیدات امنیتی مرتبط، روشهای سنتی اغلب در کشف آسیبپذیریهای عمیق، ناکارآمد هستند. این مطالعه با ترکیب دامنه وسیع آزمایش فازینگ توسط ابزارهایی مانند LibFuzzer، با تحلیل مسیر دقیق اجرای نمادین از طریق ابزارهایی مانند KLEE، قصد دارد رویکردی قویتر برای تشخیص آسیبپذیری ایجاد کند. این تحقیق شامل اعمال این تکنیکها به سیستم پایگاه داده SQLite، یک موتور پایگاه داده پرکاربرد، است. ادغام این ابزارها از طریق یک مجموعه آزمایشی با طراحی دقیق آزمایش میشود و اثربخشی هر روش در شناسایی انواع مختلف آسیبپذیریها را تجزیه و تحلیل میکند. نتایج نشان میدهد که در حالی که LibFuzzer در تشخیص سریع مسائل سطحی برتری دارد، KLEE بینش عمیقتری در مورد آسیبپذیریهای پیچیده و شرطی ارائه میدهد. یافتهها نشان میدهد که یک رویکرد یکپارچه میتواند امنیت و قابلیت اطمینان سیستمهای نرمافزاری را به طور قابل توجهی افزایش دهد. این کار با ارائه یک روششناسی سیستماتیک برای ترکیب فازینگ و اجرای نمادین، برجسته کردن نقاط قوت مکمل آنها و نشان دادن کاربرد عملی آنها در سناریوهای تست نرمافزار در دنیای واقعی، به حوزه امنیت نرمافزار کمک میکند.
کلمات کلیدی: اجرای نمادین، تکنیکهای فازینگ، آسیبپذیریهای نرمافزار، KLEE، LibFuzzer، سیستم پایگاه داده SQLite، تشخیص آسیبپذیری، امنیت نرمافزار
فصل ۱
حوزه توسعه نرمافزار به طور مداوم در حال تکامل است و چشمانداز رو به گسترشی از چالشها، به ویژه در حوزه امنیت نرمافزار را به همراه دارد. با پیشرفت فناوریها و پیچیدهتر شدن سیستمهای نرمافزاری، خطر آسیبپذیریها در این سیستمها افزایش مییابد و تهدیدات قابل توجهی را برای امنیت دادهها، یکپارچگی سیستم و اعتماد کاربر ایجاد میکند. در این زمینه، تشخیص و کاهش آسیبپذیریهای نرمافزاری به عنوان حوزههای حیاتی، تمرکز برای محققان، توسعهدهندگان و متخصصان امنیت سایبری پدیدار میشود. با توجه به اهمیت حیاتی امنیت نرمافزار در طیف وسیعی از صنایع، از امور مالی گرفته تا مراقبتهای بهداشتی، نیاز مبرمی به روشهای مؤثرتر تشخیص آسیبپذیری وجود دارد. این آسیبپذیری رو به افزایش در سیستمهای نرمافزاری، بر ضرورت استراتژیهای قوی تشخیص و کاهش آسیبپذیری تأکید میکند.
با پیشرفت مداوم فناوری، پیچیدگی سیستمهای نرمافزاری به صورت تصاعدی افزایش مییابد و چالشهای جدیدی را برای متخصصان امنیت ایجاد میکند. برنامههای مدرن اغلب به معماریهای پیچیده، وابستگیهای شخص ثالث و اکوسیستمهای به هم پیوسته متکی هستند که تضمین اقدامات امنیتی را دشوارتر میکند. علاوه بر این، ظهور هوش مصنوعی (Artificial intelligence) و یادگیری ماشین (Machine Learning) مسیرهای حمله جدیدی را معرفی میکند، به طوری که دشمنان از تکنیکهای بیشتری برای فرار از شناسایی و سوءاستفاده از آسیبپذیریها استفاده میکنند. در پاسخ به این تهدیدات در حال تکامل، جامعه امنیت سایبری تلاشهای خود را برای افزایش شیوههای امنیتی نرمافزار و توسعه راهحلهای نوآورانه تشدید کرده است. منابع، دستورالعملها و بهترین شیوهها توسط ابتکاراتی مانند پروژه امنیت برنامههای وب باز (OWASP) Opend و آژانس امنیت سایبری و زیرساخت (CISA) [Cybnd] برای توانمندسازی دفاع سازمانها ارائه میشوند. با وجود این اقدامات پیشگیرانه، چشمانداز امنیت سایبری همچنان پویا و چالشبرانگیز است و نیاز به سازگاری و هوشیاری مداوم دارد. همانطور که سازمانها برای محافظت از داراییهای دیجیتال خود و حفظ اعتماد کاربران تلاش میکنند، ضرورت اقدامات امنیتی قوی نرمافزار به طور فزایندهای آشکار میشود. با تقویت همکاری، سرمایهگذاری در فناوریهای نوآورانه و اولویت دادن به امنیت در طول چرخه عمر توسعه نرمافزار، ذینفعان میتوانند خطرات را کاهش داده و سیستمهای انعطافپذیری بسازند که قادر به مقاومت در برابر تهدیدات مدرن باشند.
برای مقابله با این چالشها، ادغام فازینگ و تکنیکهای اجرای نمادین، یک راهحل امیدوارکننده ارائه میدهد. فازینگ، با دامنه وسیع آزمایش خود، رویکردی گسترده برای کشف آسیبپذیریها ارائه میدهد، در حالی که اجرای نمادین، تحلیل عمیقتری از نقصهای امنیتی بالقوه ارائه میدهد. این پایاننامه به بررسی همافزایی این دو رویکرد، با تأکید ویژه بر ابزارهای LibFuzzer [LLV] و KLEE [KLE23] میپردازد.
با بررسی این ادغام، هدف این مطالعه، پیشبرد حوزه تشخیص آسیبپذیری نرمافزار و در نتیجه کمک به افزایش امنیت و قابلیت اطمینان نرمافزار است. هدف، ایجاد محیطی امنتر در سیستمهای نرمافزاری است، که در آن آسیبپذیریها نه تنها شناسایی میشوند، بلکه به گونهای مورد توجه قرار میگیرند که یکپارچگی کلی سیستم و اعتماد کاربر را تقویت کنند، که یک جنبه حیاتی در دنیای وابسته به فناوری است.
1.1 مروری بر راهحلهای موجود
تلاش برای شناسایی و کاهش آسیبپذیریهای نرمافزار، مداوم بوده است که با پیشرفتهای قابل توجه در روشهای تشخیص مشخص شده است. از نظر تاریخی، تشخیص آسیبپذیری به شدت به بازرسی و آزمایش دستی متکی بود، و توسعهدهندگان پایگاههای کد را برای یافتن خطاها و آسیبپذیریها بررسی میکردند. اگرچه تا حدی مؤثر بود، اما این رویکرد پر زحمت، مستعد خطا و گاهی اوقات برای تشخیص نقصهای امنیتی پیچیده ناکافی بود. تشخیص آسیبپذیریهای نرمافزاری از طریق روشهای مختلفی تکامل یافته است که هر کدام نقاط قوت و محدودیتهای خود را دارند. بررسی دستی کد، یکی از اولین تکنیکها، شامل بررسی دقیق کد توسط توسعهدهندگان برای شناسایی خطاها میشود. این روش، اگرچه کامل است، اما به طور قابل توجهی زمانبر و مستعد خطای انسانی است. این روش به شدت به تخصص و توجه به جزئیات بررسیکننده متکی است و شناسایی مداوم همه آسیبپذیریها را چالشبرانگیز میکند [BB13]. ظهور ابزارهای خودکار، تشخیص آسیبپذیری را متحول کرد و رویکردهای سیستماتیکتر و مقیاسپذیرتری را ممکن ساخت. یکی از اولین تکنیکهای خودکار، تحلیل ایستا بود که شامل تجزیه و تحلیل کد منبع یا فایلهای باینری بدون اجرای نرمافزار میشود. ابزارهای تحلیل استاتیک، مانند lint [Joh78] و Coverity [Syn24]، به عنوان داراییهای ارزشمندی در شناسایی خطاهای رایج برنامهنویسی، نشت حافظه و آسیبپذیریهای امنیتی بالقوه ظاهر شدند. با این حال، ابزارهای تحلیل استاتیک به دلیل ناتوانی در تشخیص آسیبپذیریهای خاص زمان اجرا محدود هستند و اغلب نتایج مثبت کاذب ایجاد میکنند که منجر به چالشهایی در اولویتبندی و رسیدگی به مسائل میشود [Git24]. ابزارهای تحلیل استاتیک خودکار با تجزیه و تحلیل کد بدون اجرای آن، جایگزینی ارائه میدهند. این ابزارها کد منبع، کد بایت یا فایلهای باینری برنامه را برای شناسایی آسیبپذیریهای بالقوه اسکن میکنند. آنها یک رویکرد سیستماتیک ارائه میدهند و میتوانند محل دقیق آسیبپذیریها را مشخص کنند و شناسایی آسانتر را تسهیل کنند.
رفع اشکال. با این حال، تحلیل استاتیک اغلب نتایج مثبت کاذب ایجاد میکند و نمیتواند آسیبپذیریهایی را که فقط در زمان اجرای نرمافزار ظاهر میشوند، شناسایی کند و اثربخشی آن را در سناریوهای خاصی محدود میکند [BBMZ16]. تکنیکهای تحلیل پویا، از جمله آزمایش زمان اجرا و فازینگ، به عنوان رویکردهای مکمل تحلیل استاتیک ظهور کردند. آزمایش زمان اجرا شامل اجرای نرمافزار با ورودیهای مختلف برای مشاهده رفتار آن و کشف آسیبپذیریها است. فازینگ، نوعی تحلیل پویا، در تولید ورودیهای متنوع و افشای رفتارهای غیرمنتظره مؤثر است. ظهور ابزارهایی مانند American Fuzzy Lop (AFL) [Zal16] و hongg-fuzz [Swi24] فازینگ را متحول کرد و کمپینهای فازینگ خودکار و هدایتشده را قادر ساخت که میتوانند آسیبپذیریهای قبلاً کشف نشده را کشف کنند [Aut24]. تحلیل پویا، از جمله تکنیکهای فازینگ سنتی، با آزمایش نرمافزار در حین اجرا، برخی از این محدودیتها را برطرف میکند. این روش در کشف اشکالاتی که فقط در زمان اجرا آشکار میشوند، مانند خطاهای زمان اجرا و مشکلات دسترسی، مهارت دارد. فازینگ، به طور خاص،
شامل اجرای نرمافزار با ورودیهای مختلف برای شناسایی آسیبپذیریها است. در حالی که تحلیل پویا، ارزیابی عملی از امنیت برنامهها ارائه میدهد، ممکن است درک عمیقی از خطوط خاص کد که در آنها آسیبپذیری وجود دارد، ارائه ندهد. علاوه بر این، این کار فقط زمانی قابل انجام است که برنامه در حالت قابل اجرا باشد، که آن را برای مراحل اولیه چرخه عمر توسعه نرمافزار کمتر مناسب میکند [LMS+19].
با وجود اثربخشی تکنیکهای تحلیل پویا، آنها ذاتاً به دلیل ناتوانی در کاوش همه مسیرهای اجرایی ممکن در یک برنامه محدود هستند. این محدودیت باعث ایجاد اجرای نمادین شد، تکنیکی که ورودیهای برنامه را به صورت نمادین بررسی میکند و به طور سیستماتیک همه مسیرهای اجرایی ممکن را کاوش میکند. ابزارهای اجرای نمادین، مانند SAGE [GLM08] و KLEE [KLE23]، در شناسایی رفتارهای پیچیده برنامه و کشف آسیبپذیریهایی که ممکن است توسط سایر روشها کشف نشده باقی بمانند، برتری دارند.
در سالهای اخیر، ادغام چندین تکنیک تشخیص آسیبپذیری با توجه به اینکه سازمانها به دنبال راهحلهای جامعتر و مؤثرتر هستند، مورد توجه قرار گرفته است. علیرغم اثربخشی این روشها در زمینههای خاص، آنها اغلب در کشف آسیبپذیریهای پیچیده و عمیقاً نهفته در سیستمهای نرمافزاری، عملکرد ضعیفی دارند. رویکردهای ترکیبی، مانند ترکیب تحلیل استاتیک با فازیسازی یا اجرای نمادین با تحلیل پویا، با هدف بهرهگیری از نقاط قوت هر تکنیک و در عین حال کاهش محدودیتهای مربوط به آنها انجام میشوند. این رویکردهای یکپارچه، درک عمیقتری از آسیبپذیریهای نرمافزاری ارائه میدهند و اثربخشی کلی تلاشهای تشخیص را افزایش میدهند. این امر میتواند به طور بالقوه راهحل جامعتری برای تشخیص آسیبپذیری ارائه دهد و هم به آسیبپذیریهای سطحی و هم به آسیبپذیریهای ریشهدار در سیستمهای نرمافزاری پیچیده بپردازد.
۱.۲ چالشها و محدودیتهای راهحلهای موجود
در حالی که روشهای تشخیص آسیبپذیری موجود گامهای قابل توجهی در بهبود امنیت نرمافزار برداشتهاند، اما بدون چالشها و محدودیتهای خود نیستند. این چالشها از پیچیدگیهای ذاتی سیستمهای نرمافزاری مدرن، ماهیت پویای تهدیدات سایبری و محدودیتهای تکنیکهای تشخیص فعلی ناشی میشوند.
۱. بررسی دستی کد:
(الف) زمانبر: بررسی دستی کد نیازمند کار زیاد و زمانبر است و نیاز به توسعهدهندگان ماهر دارد تا کدبیسها را خط به خط با دقت بررسی کنند. این فرآیند برای پروژههای بزرگ یا کدبیسهایی که به سرعت در حال تکامل هستند، به طور فزایندهای غیرعملی میشود.
(ب) خطای ذهنی و انسانی: اثربخشی بررسی دستی کد به شدت به تخصص و توجه به جزئیات بررسیکنندگان بستگی دارد. خطای انسانی، تعصب و تفاسیر متفاوت میتواند منجر به از دست رفتن آسیبپذیریها یا مثبت کاذب شود.
۲. تحلیل استاتیک:
(الف) مثبت کاذب: ابزارهای تحلیل استاتیک اغلب مثبت کاذب ایجاد میکنند و بخشهایی از کد را که آسیبپذیر نیستند، به عنوان آسیبپذیر علامتگذاری میکنند. این امر توسعهدهندگان را با هشدارهای نامربوط مواجه میکند و اولویتبندی و رسیدگی به مسائل امنیتی واقعی را چالشبرانگیز میکند.
(ب) دامنه محدود: ابزارهای تحلیل استاتیک در درجه اول بر شناسایی آسیبپذیریهای نحوی یا ساختاری در کدبیس تمرکز دارند. آنها ممکن است آسیبپذیریهای خاص زمان اجرا یا نقصهای امنیتی ایجاد شده توسط کتابخانهها یا وابستگیهای شخص ثالث را نادیده بگیرند.
3. تحلیل پویا (شامل فازینگ سنتی):
(الف) محدودیتهای کاوش مسیر: تکنیکهای تحلیل پویا، مانند فازینگ سنتی، به دلیل ناتوانی در کاوش تمام مسیرهای اجرایی ممکن در یک برنامه محدود هستند. این ممکن است منجر به پوشش (Coverage) تست سطحی شود و مسیرهای کد خاصی را کاوش نشده و آسیبپذیریها را کشف نشده باقی بگذارد.
(ب) سربار اجرا: تحلیل پویا سربار زمان اجرا را متحمل میشود و بر عملکرد و مقیاسپذیری فرآیند تست تأثیر میگذارد. با افزایش پیچیدگی سیستمهای نرمافزاری، سربار مرتبط با تحلیل پویا بیشتر میشود و مانع اثربخشی آن میشود.
4. مقیاسپذیری و پوشش:
(الف) مسائل مقیاسپذیری: با افزایش اندازه و پیچیدگی سیستمهای نرمافزاری، روشهای سنتی تشخیص آسیبپذیری برای همگام شدن با این تغییرات با مشکل مواجه میشوند. حجم کد، همراه با وابستگیهای متقابل پیچیده، چالشهایی را در تجزیه و تحلیل و آزمایش جامع کل پایگاه کد ایجاد میکند.
(ب) شکافهای پوشش (Coverage Gaps): تکنیکهای موجود ممکن است شکافهای پوشش را نشان دهند و نتوانند مسیرهای کد خاص یا موارد حاشیهای را به طور کافی بررسی کنند. این امر باعث میشود آسیبپذیریها در مناطق آزمایش نشده نرمافزار پنهان شوند و آنها را مستعد سوءاستفاده توسط دشمنان کند.
۵. سازگاری با تهدیدات نوظهور:
(الف) چشمانداز تهدید در حال تکامل: تهدیدات سایبری دائماً در حال تکامل هستند و دشمنان تکنیکهای پیچیدهای را برای فرار از تشخیص و سوءاستفاده از آسیبپذیریها ابداع میکنند. روشهای تشخیص موجود ممکن است برای سازگاری با بردارهای حمله جدید یا تهدیدات امنیتی نوظهور با مشکل مواجه شوند و سازمانها را در معرض سوءاستفاده قرار دهند. با توجه به این چالشها، نیاز به رویکردهای پیشرفتهتر و یکپارچهتر برای تشخیص آسیبپذیری رو به افزایش است. با پرداختن به محدودیتهای راهحلهای موجود و استفاده از تکنیکهای مکمل، ذینفعان میتوانند توانایی خود را در شناسایی، کاهش و اصلاح مؤثر آسیبپذیریهای نرمافزاری افزایش دهند.
1.3 ابزارهای فازینگ
فازینگ، یک تکنیک تست خودکار نرمافزار، به دلیل اثربخشی خود در کشف آسیبپذیریهای نرمافزاری، به طور گسترده مورد توجه قرار گرفته است. این روش شامل بمباران یک برنامه نرمافزاری با انبوهی از دادههای تصادفی یا «فاز» برای تحریک خرابیها است.
در میان ابزارهای این حوزه، LibFuzzer [LLV] به ویژه قابل توجه است. LibFuzzer که به عنوان بخشی از پروژه LLVM [LLV24] توسعه یافته است، یک فازر هدایتشده با پوشش است که به دلیل تولید کارآمد موارد آزمایشی و ظرفیت خود در ارائه اطلاعات پوشش دقیق مشهور است. این اطلاعات برای شناسایی آسیبپذیریهای بالقوه در سیستمهای نرمافزاری بسیار مهم است. ادغام LibFuzzer با زیرساخت کامپایلر LLVM، اثربخشی آن را افزایش میدهد و امکان آزمایش جامع سیستمهای نرمافزاری پیچیده را با سهولت نسبی فراهم میکند [LLV]. با وجود اثربخشی آن، LibFuzzer بدون محدودیت نیست. اگرچه در آشکارسازی انواع آسیبپذیریها، بهویژه آنهایی که توسط ورودیهای غیرمنتظره ایجاد میشوند، مهارت دارد، اما ممکن است تمام مسیرهای پیچیده درون یک سیستم نرمافزاری را بهطور کامل بررسی نکند. در نتیجه، برخی از اشکالات عمیقاً تودرتو یا مشروط ممکن است از تشخیص فرار کنند. این شکاف در قابلیت آن، اهمیت تکمیل LibFuzzer با سایر تکنیکها، مانند اجرای نمادین، را برجسته میکند. اجرای نمادین میتواند بهطور سیستماتیک مسیرهای مختلف برنامه را بررسی کند و در نتیجه به کشف آسیبپذیریهایی که در غیر این صورت ممکن است در ساختارهای کد پیچیده پنهان بمانند، کمک کند. ترکیب قابلیتهای فازینگ LibFuzzer با تحلیل کامل مسیر ارائه شده توسط اجرای نمادین، رویکردی جامعتر برای تشخیص آسیبپذیری ارائه میدهد که بهطور بالقوه منجر به سیستمهای نرمافزاری امنتر و قویتر میشود [CS13].
۱.۴ اجرای نمادین (Symbolic Execution)
اجرای نمادین نشاندهنده پیشرفت قابل توجهی در زمینه تست نرمافزار است و رویکردی پیچیدهتر در مقایسه با روشهای سنتی ارائه میدهد. این تکنیک، با در نظر گرفتن ورودیها به عنوان متغیرهای نمادین، مسیرهای اجرایی بالقوه را در یک برنامه تجزیه و تحلیل میکند. ماهیت اجرای نمادین در توانایی آن در کاوش سیستماتیک مسیرهای مختلف برنامه نهفته است و از این طریق آسیبپذیریهایی را که ممکن است تحت شرایط خاص ایجاد شوند، شناسایی میکند. یکی از نقاط قوت کلیدی این روش، دقت آن در کاوش مسیرهایی است که معمولاً توسط تکنیکهای تست مرسوم، مانند فازینگ، نادیده گرفته میشوند [ CD+18].
int f() {
y = read();
z = y * 2;
if (z == 12) {
fail();
} else {
printf("OK");
}
}
شکل ۱.۱ نحوه کاوش مسیر برنامه را هنگامی که ورودی نمادین است، به صورت تصویری نشان میدهد [Sto23]. در لیست ۱.۱ داده شده، تابع ورودی y را به صورت نمادین میخواند، به این معنی که y میتواند هر مقدار صحیحی را بپذیرد. عبارت z = y * 2 سپس z را به یک عبارت نمادین تبدیل میکند. 2 * y هنگامی که شرط if (z == 12) رخ میدهد، اجرای نمادین هر دو مسیر ممکن را کاوش میکند: یکی که در آن شرط درست است و دیگری که در آن نادرست است. در مسیر true، اگر 2 * y == 12 باشد، حل برای y، y = 6 را میدهد که منجر به اجرای fail()r میشود که یک مسیر خطا را نشان میدهد.
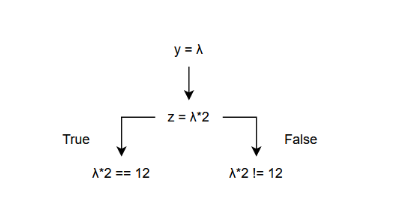
در مسیر نادرست، که در آن 2 * y != 12 است، برنامه با printf(“OK”); عبارت “OK” را چاپ میکند. با بررسی سیستماتیک این مسیرها، اجرای نمادین تضمین میکند که تمام سناریوهای اجرایی ممکن بررسی میشوند، در نتیجه اشکالات بالقوه شناسایی میشوند و آزمایش جامع برنامه تضمین میشود.
KLEE به عنوان ابزاری قابل توجه در حوزه اجرای نمادین [CN21] ظاهر میشود. این ابزار در ساخت مدلهای انتزاعی از حالتهای بالقوه یک برنامه عالی عمل میکند و در نتیجه تجزیه و تحلیل دقیق و جزئی را تسهیل میکند. رویکرد KLEE جامع است و طیف گستردهای از مسیرهای اجرایی بالقوه را پوشش میدهد و آسیبپذیریهایی را که ممکن است از طریق روشهای سنتی آزمایش آشکار نشوند، کشف میکند. ادغام KLEE در فرآیند فازینگ، به ویژه با ابزاری مانند LibFuzzer، نشاندهنده پیشرفت قابل توجهی در آزمایش نرمافزار است. این ترکیب از نقاط قوت هر دو ابزار بهره میبرد: تجزیه و تحلیل روشمند KLEE از مسیرهای پیچیده و تولید سریع ورودی LibFuzzer، ترکیب بین KLEE و LibFuzzer منجر به رویکردی کاملتر و کارآمدتر در تشخیص آسیبپذیری میشود.
این رویکرد یکپارچه، پوشش جامعی را تضمین میکند و امکان تشخیص اشکالات سطحی و آسیبپذیریهای عمیقتر را فراهم میکند.
1.5 اهمیت LibFuzzer و KLEE
LibFuzzer و KLEE دو ابزار برجسته در حوزه تشخیص آسیبپذیری هستند که هر کدام قابلیتهای منحصر به فردی را ارائه میدهند که به اثربخشی کلی شیوههای امنیتی نرمافزار کمک میکند. درک اهمیت این ابزارها مستلزم بررسی ویژگیهای کلیدی، نقاط قوت و مزایای خاصی است که آنها برای تلاشهای تشخیص آسیبپذیری به ارمغان میآورند.
- LibFuzzer:
(الف) فازینگ هدایتشده با پوشش: LibFuzzer به خاطر رویکرد فازینگ هدایتشده با پوشش خود مشهور است که بر حداکثر کردن پوشش کد در طول آزمایش تمرکز دارد. با تولید و جهش مکرر موارد آزمایشی بر اساس بازخورد پوشش، LibFuzzer به طور موثر مسیرهای کد مختلف را بررسی میکند و احتمال کشف آسیبپذیریها را افزایش میدهد.
تولید کارآمد موارد آزمایشی: LibFuzzer در تولید موارد آزمایشی متنوع و مؤثر، با استفاده از تکنیکهای فازینگ مبتنی بر جهش برای تولید ورودیهایی که رفتارهای غیرمنتظره و موارد مرزی را در نرمافزار آشکار میکنند، عالی است.
(ب) ادغام با زیرساخت LLVM: به عنوان بخشی از پروژه LLVM، LibFuzzer از ادغام یکپارچه با زیرساخت کامپایلر LLVM بهره میبرد و امکان آزمایش جامع سیستمهای نرمافزاری پیچیده را با سهولت نسبی فراهم میکند.
این ادغام، اثربخشی و قابلیت همکاری آن را با سایر ابزارها و چارچوبهای مبتنی بر LLVM افزایش میدهد.
- KLEE:
(الف) قابلیتهای اجرای نمادین: KLEE از اجرای نمادین برای بررسی سیستماتیک مسیرهای برنامه و شناسایی آسیبپذیریهای بالقوه استفاده میکند. KLEE با برخورد نمادین با ورودیها، مسیرهای اجرایی مختلف را تجزیه و تحلیل میکند و موارد آزمایشی تولید میکند که طیف وسیعی از شرایط و موارد مرزی را پوشش میدهند.
(ب) تجزیه و تحلیل دقیق مسیر: موتور اجرای نمادین KLEE بینش دقیقی از رفتارهای برنامه ارائه میدهد و امکان تجزیه و تحلیل دقیق مسیر و شناسایی آسیبپذیریهای شرطی را که ممکن است در روشهای سنتی آزمایش پنهان بمانند، فراهم میکند.
(ج) تجزیه و تحلیل مبتنی بر مدل: KLEE مدلهای انتزاعی از حالتهای برنامه و مسیرهای اجرایی را میسازد و تجزیه و تحلیل کامل و دقیق سیستمهای نرمافزاری پیچیده را تسهیل میکند. این رویکرد مبتنی بر مدل، توانایی آن را در تشخیص اشکالات ظریف و آسیبپذیریهای امنیتی افزایش میدهد.
- تأثیر در دنیای واقعی:
(الف) داستانهای موفقیت و مطالعات موردی متعدد، تأثیر LibFuzzer و KLEE را در دنیای واقعی در کشف آسیبپذیریهای امنیتی حیاتی و افزایش تابآوری سیستمهای نرمافزاری نشان میدهد. از شناسایی اشکالات خرابی حافظه گرفته تا کشف نقصهای منطقی پیچیده، این ابزارها نقش محوری در ایمنسازی برنامههای نرمافزاری در حوزههای مختلف داشتهاند. به طور خلاصه، LibFuzzer و KLEE ابزارهای ضروری در متخصصان امنیت سایبری هستند که قابلیتهای پیشرفتهای را برای تشخیص و تحلیل آسیبپذیری ارائه میدهند. اهمیت آنها در توانایی آنها در کشف طیف گستردهای از آسیبپذیریها، از خطاهای ساده حافظه گرفته تا نقصهای منطقی پیچیده، نهفته است و در نتیجه به امنیت و قابلیت اطمینان کلی سیستمهای نرمافزاری کمک میکند.
1.6 انگیزه و اهمیت
انگیزه برای ادغام ابزارهای فازینگ مانند LibFuzzer با ابزارهای اجرای نمادین مانند KLEE از پیچیدگی فزاینده سیستمهای نرمافزاری و آسیبپذیریهای امنیتی مربوطه ناشی میشود. روشهای سنتی تشخیص آسیبپذیری اغلب در کشف کامل آسیبپذیریهای پنهان و پیچیده، کم میآورند. فازینگ، اگرچه در آزمایش گسترده مؤثر است، اما ممکن است اشکالات عمیقتر را از دست بدهد و اجرای نمادین، اگرچه کامل است، اما میتواند به دلیل مقیاسپذیری و نیازهای محاسباتی آن محدود شود. ادغام این دو رویکرد با هدف بهرهبرداری از نقاط قوت آنها – پوشش گسترده فازینگ و عمق تحلیل ارائه شده توسط اجرای نمادین برای ایجاد یک روش تشخیص آسیبپذیری قویتر و کارآمدتر انجام میشود.
1.6.1 انگیزه
- پیچیدگی سیستمهای نرمافزاری مدرن: سیستمهای نرمافزاری مدرن به طور فزایندهای پیچیده و به کتابخانههای شخص ثالث تبدیل میشوند. این پیچیدگی، شناسایی همه آسیبپذیریهای امنیتی بالقوه را با استفاده از روشهای سنتی تست، چالشبرانگیز میکند.
- محدودیتهای روشهای سنتی: روشهای سنتی تشخیص آسیبپذیری، مانند بررسی دستی کد و تحلیل استاتیک، اغلب در کشف آسیبپذیریهای عمیقاً جاسازی شده، با مشکل مواجه هستند. بررسیهای دستی زمانبر و مستعد خطای انسانی هستند، در حالی که ابزارهای تحلیل استاتیک میتوانند نتایج مثبت کاذب ایجاد کنند و مسائل خاص زمان اجرا را از دست بدهند. فازینگ و اجرای نمادین میتوانند با خودکارسازی فرآیند تست و بررسی کامل مسیرهای اجرای سطحی و عمیق، بر این محدودیتها غلبه کنند.
- مزایای فازینگ: ابزارهای فازینگ مانند LibFuzzer در تولید طیف وسیعی از ورودیهای تصادفی برای تست نرمافزار، برتری دارند. این روش به ویژه در کشف آسیبپذیریهای سطحی و رفتارهای غیرمنتظره ناشی از ورودیهای ناقص مؤثر است. با این حال، فازینگ ممکن است به دلیل ماهیت تصادفی و عدم کاوش سیستماتیک مسیر، اشکالات عمیقتر و شرطی را از دست بدهد.
- . نقاط قوت اجرای نمادین: ابزارهای اجرای نمادین مانند KLEE با برخورد نمادین با ورودیها، رویکردی روشمند برای تشخیص آسیبپذیری ارائه میدهند. بررسی تمام مسیرهای اجرایی ممکن. این دقت به اجرای نمادین اجازه میدهد تا خطاهای منطقی پیچیده و موارد گوشهای را که فازینگ ممکن است از دست بدهد، کشف کند. با این حال، اجرای نمادین میتواند منابع زیادی مصرف کند و ممکن است در پایگاههای کد بزرگ با مقیاسپذیری مشکل داشته باشد.
- نقاط قوت مکمل: انگیزه برای ادغام فازینگ و اجرای نمادین در نقاط قوت مکمل آنها نهفته است. فازینگ پوشش گسترده و تشخیص سریع آسیبپذیری را فراهم میکند، در حالی که اجرای نمادین تجزیه و تحلیل مسیر دقیق و توانایی کشف اشکالات عمیقاً پنهان را ارائه میدهد. با ترکیب این رویکردها، میتوانیم یک روش تشخیص آسیبپذیری جامعتر و کارآمدتر ایجاد کنیم. این ترکیب میتواند با هدف بهرهگیری از قابلیت تست سریع و پوشش گسترده فازینگ و تجزیه و تحلیل مسیر عمیق و دقیق اجرای نمادین باشد.
فازینگ، از طریق ابزارهایی مانند LibFuzzer، به طور مؤثر آسیب پذیریهای ناشی از ورودیهای غیرمنتظره را شناسایی میکند، اما ممکن است منطق نرمافزار را عمیقاً تجزیه و تحلیل نکند. اجرای نمادین، همانطور که توسط KLEE اجرا میشود، این شکاف را با بررسی سیستماتیک مسیرهای پیچیده درون کد، به ویژه مسیرهایی که وابسته به شرایط یا پیچیده هستند، پر میکند. همافزایی این روشها، رویکردی جامعتر و قویتر ارائه میدهد که به طور بالقوه منجر به افزایش قابل توجه در تشخیص و حل آسیبپذیریهای نرمافزاری آشکار و پنهان میشود. این رویکرد یکپارچه نه تنها با هدف افزایش کارایی تشخیص آسیبپذیری، بلکه به توسعه سیستمهای نرمافزاری امنتر و قابل اعتمادتر نیز کمک میکند.
1.6.2 اهمیت
- بهبود تشخیص آسیبپذیری: سهم اصلی این تحقیق، توسعه یک روش سیستماتیک برای مقایسه و ادغام فازینگ و اجرای نمادین برای بهبود تشخیص آسیبپذیری در سیستمهای نرمافزاری است.
- تحلیل جامع: با تجزیه و تحلیل گردش کار ابزارهایی مانند LibFuzzer و KLEE، به تعیین اینکه کدام ابزار پوشش کد بالاتری را ارائه میدهد و هر ابزار چه نوع آسیبپذیریهایی را میتواند تشخیص دهد، کمک میکند. این تحلیل مقایسهای، بینشهای ارزشمندی در مورد نقاط قوت و ضعف هر رویکرد و نحوه ترکیب مؤثر آنها ارائه میدهد.
- امنیت نرمافزار پیشرفته: ادغام فازینگ و اجرای نمادین میتواند با ارائه یک روش قوی برای تشخیص آسیبپذیری، به حوزه امنیت نرمافزار کمک کند. این رویکرد میتواند به توسعهدهندگان و متخصصان امنیتی کمک کند. افراد، آسیبپذیریها را به طور مؤثرتری شناسایی و کاهش میدهند و منجر به سیستمهای نرمافزاری امنتر و قابل اعتمادتر میشوند.
- کاربردهای عملی: یافتههای این تحقیق را میتوان در حوزههای مختلف به کار برد. با افزایش توانایی تشخیص آسیبپذیریهای پیچیده، این تحقیق میتواند به محافظت از دادههای حساس کمک کند و یکپارچگی و قابلیت اطمینان سیستمهای نرمافزاری را تضمین کند.
۱.۷ مشارکت
هدف این پایاننامه بررسی مزایا و محدودیتهای ادغام تکنیکهای اجرای نمادین و فازینگ است. این امر با استفاده ویژه از ابزارهایی مانند KLEE و LibFuzzer نشان داده شده است. مشارکتهای این پایاننامه به شرح زیر است:
۱. تحلیل مقایسهای تکنیکهای تشخیص
یک تحلیل مقایسهای دقیق از عملکرد و اثربخشی KLEE و LibFuzzer ارائه شده است. این تحلیل شامل معیارهایی مانند زمان اولین تشخیص، مصرف منابع و ماهیت آسیبپذیریهای کشف شده است. این مقایسه نقاط قوت مکمل دو ابزار را برجسته میکند: کاوش کامل مسیر KLEE و استراتژیهای تولید ورودی سریع و جهش LibFuzzer
۲. کاربرد در نرمافزارهای دنیای واقعی SQLite
این تحقیق، چارچوب یکپارچه را در SQLite، یک سیستم پایگاه داده تعبیهشده پرکاربرد، اعمال میکند. با پیکربندی و اجرای KLEE و LibFuzzer بر روی پایگاه کد SQLite، این پایاننامه کاربرد عملی و اثربخشی رویکرد یکپارچه در شناسایی آسیبپذیریها در نرمافزارهای دنیای واقعی را نشان میدهد. نتایج، توانایی چارچوب را در تشخیص طیف وسیعی از آسیبپذیریها، از مسائل مربوط به خرابی حافظه گرفته تا خطاهای منطقی پیچیده، نشان میدهد.
۳. بینشهایی در مورد محدودیتهای ابزار و بهبودهای آینده
این تحقیق، محدودیتهای ابزارهای اجرای نمادین و فازینگ فعلی را هنگام اعمال بر سیستمهای نرمافزاری پیچیده شناسایی و مورد بحث قرار میدهد. چالشهای کلیدی مانند مدیریت فراخوانیهای سیستم خارجی، مدیریت محدودیتهای حافظه و دستیابی به کاوش کامل مسیر بررسی میشوند. این پایاننامه بینشهایی در مورد بهبودها و بهینهسازیهای بالقوه برای این ابزارها ارائه میدهد و مسیرهای تحقیقاتی آینده را برای افزایش مقیاسپذیری و کارایی آنها پیشنهاد میدهد.
1.8 پایاننامه
این تحقیق به گونهای ساختار یافته است که به طور جامع ادغام فازینگ و اجرای نمادین در تشخیص آسیبپذیری نرمافزار، به ویژه با تمرکز بر استفاده از LibFuzzer و KLEE را بررسی کند. هسته اصلی پایاننامه، روششناسی ادغام LibFuzzer و KLEE را ارائه میدهد و پس از آن تجزیه و تحلیل گستردهای از نتایج به دست آمده از این رویکرد ارائه میشود. بخش بحث، این نتایج را تفسیر میکند و اثربخشی و کارایی روش یکپارچه را ارزیابی میکند. ساختار این پایاننامه به گونهای طراحی شده است که یک بررسی جامع از ادغام فازینگ و تکنیکهای اجرای نمادین در تشخیص آسیبپذیری نرمافزار ارائه دهد. این پایاننامه در چندین فصل سازماندهی شده است که هر کدام به جنبههای کلیدی تحقیق پرداخته و به درک عمیقتر موضوع کمک میکنند. علاوه بر این، کارهای آینده و پیشرفتهای بالقوه برای ترسیم مسیر تحقیقات مداوم در این زمینه مورد بحث قرار گرفتهاند.
1- مقدمه:
فصل مقدماتی با ارائه مروری بر اهمیت امنیت نرمافزار، چالشهای تشخیص آسیبپذیری و اهمیت روشهای تست نرمافزار مانند فازینگ و تکنیکهای اجرای نمادین، به بررسی میپردازد. این بخش اهداف، انگیزه و ساختار پایاننامه را شرح میدهد.
2- پیشینه:
فصل پیشینه، بررسی جامعی از تحقیقات، روشها و ابزارهای موجود مربوط به تشخیص آسیبپذیری، فازینگ، اجرای نمادین و ادغام آنها ارائه میدهد. این فصل، آثار، پیشرفتهای اخیر و مطالعات موردی قابل توجه در این زمینه را بررسی میکند و پایهای برای فصلهای بعدی فراهم میکند.
3- الزامات تحلیل و آزمایش برای ارزیابی آسیبپذیری SQLite:
این فصل به بررسی تکامل تکنیکهای فازینگ، بررسی قابلیتهای LibFuzzer و تمرکز بر اجرای نمادین میپردازد که اصول، الگوریتمها و کاربردهای تکنیکهای اجرای نمادین را بررسی میکند.
4- روشها و تنظیمات تجربی:
این فصل به بررسی ادغام تکنیکهای فازینگ و اجرای نمادین برای افزایش تشخیص آسیبپذیری میپردازد. تفاوت بین LibFuzzer و KLEE را بررسی میکند. روشهایی را برای ادغام این دو ابزار پیشنهاد میدهد. علاوه بر این، مزایا و چالشهای بالقوه مرتبط با این راهاندازی را ارزیابی میکند.
5- نتایج:
این فصل نتایج ادغام تکنیکهای فازینگ و اجرای نمادین را برای افزایش تشخیص آسیبپذیری ارائه میدهد. این فصل نتایج هر دو ابزار، LibFuzzer و KLEE، را هنگام آزمایش با هرگونه کد آسیبپذیر و همچنین مثال دنیای واقعی ارائه میدهد.
6- بحث و تحلیل:
این فصل به طور انتقادی یافتههای حاصل از خروجی فازینگ و اجرای نمادین را تجزیه و تحلیل میکند، نقاط قوت، محدودیتها و پیامدهای عملی این رویکرد را مورد بحث قرار میدهد و زمینههایی را برای تحقیق و بهبود بیشتر شناسایی میکند.
7- نتیجهگیری:
خلاصه فصل پایانی یافتهها، مشارکتها و پیامدهای کلیدی تحقیق را بررسی میکند. این مقاله به اهمیت ارتقای شیوههای امنیتی نرمافزار میپردازد، مسیرهای آینده را برای تحقیق و توسعه پیشنهاد میدهد و بر اهمیت نوآوری مستمر در روشهای تشخیص آسیبپذیری تأکید میکند.
8- منابع:
بخش منابع، فهرستی جامع از منابع ذکر شده در سراسر پایاننامه، از جمله مقالات دانشگاهی، کتابها، مقالات و منابع آنلاین، ارائه میدهد.
9- پیوستها:
مطالب تکمیلی، مانند قطعه کدها، دادههای تجربی و تحلیلهای اضافی، در پیوستها گنجانده شدهاند تا زمینه و پشتیبانی بیشتری از یافتههای تحقیق ارائه دهند.
با پیروی از این رویکرد ساختاریافته، این پایاننامه قصد دارد کاوشی کامل در مورد ادغام تکنیکهای فازی و اجرای نمادین ارائه دهد و بینشها، روشها و توصیههای ارزشمندی را برای ارتقای شیوههای تشخیص آسیبپذیری نرمافزار ارائه دهد.
فصل 2
در حوزه امنیت سایبری، اهمیت تشخیص آسیبپذیریهای نرمافزار از طریق اجرای نمادین و فازینگ میتواند به بهبود وضعیت برنامه کمک کند. این فصل مروری جامع بر فازینگ و اجرای نمادین، دو تکنیک محوری در امنیت نرمافزار برای شناسایی آسیبپذیریها، ارائه میدهد. این فصل با مقدمهای بر هر دو روش آغاز میشود و نقاط قوت و محدودیتهای هر یک را برجسته میکند. سپس این فصل به اجرای نمادین میپردازد و روششناسی و مزایای آن، از جمله توانایی آن در بررسی مسیرهای اجرای چندگانه و تشخیص طیف وسیعی از خطاها را شرح میدهد. استفاده از ابزارهای اجرای نمادین مانند KLEE بررسی میشود و کاربردهای عملی آنها در تست و تأیید نرمافزار نشان داده میشود.
علاوه بر این، این فصل ابزارهای مختلف اجرای نمادین را پوشش میدهد و ویژگیها و موارد استفاده آنها را مقایسه میکند. فازینگ نیز با تأکید بر LibFuzzer و اثربخشی آن در کشف آسیبپذیریهای نرمافزار، به طور عمیق بررسی میشود. ادغام فازینگ با اجرای نمادین مورد بحث قرار میگیرد و نشان میدهد که چگونه این رویکرد ترکیبی میتواند با ترکیب نقاط قوت هر دو تکنیک، تشخیص آسیبپذیری را افزایش دهد. این فصل از طریق مثالها و مطالعات موردی، پیادهسازی عملی و موفقیت این روشها را در بهبود قابلیت اطمینان و امنیت نرمافزار نشان میدهد.
۲.۱ مقدمهای بر فازینگ و اجرای نمادین
فازینگ و اجرای نمادین (Symbolic Execution) دو تکنیک حیاتی در زمینه امنیت نرمافزار برای شناسایی آسیبپذیریها هستند. فازینگ شامل ارائه طیف گستردهای از ورودیهای تصادفی به برنامه برای افشای نقصهای احتمالی است، در حالی که اجرای نمادین به طور سیستماتیک تمام مسیرهای اجرایی ممکن در یک برنامه را با در نظر گرفتن ورودیها به عنوان مقادیر نمادین بررسی میکند. هر دو تکنیک نقاط قوت و محدودیتهای خود را دارند و هدف از ادغام آنها ترکیب این نقاط قوت برای بهبود اثربخشی تشخیص آسیبپذیری است.
۲.۲ اجرای نمادین
اجرای نمادین روشی کامل برای شناسایی آسیبپذیریها ارائه میدهد. این رویکرد به طور قابل توجهی با آزمایش ورودی تصادفی سنتی متفاوت است. در حالی که ورودیهای تصادفی ممکن است آسیبپذیریهای بالقوه را از دست بدهند، اجرای نمادین چندین مسیر اجرایی را به طور همزمان بررسی میکند و قابلیت بهرهبرداری آنها را ارزیابی میکند. این روش بر روی ورودیهای نمادین محدود شده توسط گزارههای خاص که نشاندهنده طیف وسیعی از مقادیر بالقوه هستند، برخلاف مقادیر خاص و عینی، عمل میکند. این روش با ابزارهای تحلیل استاتیک که اگرچه در شناسایی پیشگیرانه مسائل مفید هستند، اما اغلب نیاز به مداخله متخصص برای تمایز بین خطاهای کاذب و اشکالات واقعی دارند، در تضاد است.
قدرت اجرای نمادین در ظرفیت آن برای تشخیص انواع خطاها، از جمله خطاهای مربوط به صحت عملکردی، که ممکن است فقط از طریق اجرای کد ظاهر شوند، نهفته است. این روش کاربرپسند است و به طور سیستماتیک هر شاخه اجرایی ممکن از یک برنامه را ارزیابی میکند. اجرای نمادین با برخورد به یک شاخه، قابلیت اجرای هر مسیر را بررسی میکند، وضعیت برنامه را برای هر کدام تکرار میکند و این مسیرها را در حین جمعآوری محدودیتهای ورودی دنبال میکند. پس از کشف یک اشکال، از یک اثباتکننده قضیه خودکار برای تولید مقادیر ورودی عینی که این محدودیتها را برآورده میکنند، استفاده میکند. این امر شرایط خاصی را که آسیبپذیریها تحت آن آشکار میشوند، برجسته میکند و اجرای نمادین را به ابزاری مؤثر و در دسترس برای کشف اشکالات در نرمافزار تبدیل میکند.
دهه گذشته شاهد تکامل قابل توجهی در رویکردهای اجرای نمادین بوده است، با برنامههایی که شامل تست نرمافزار، امنیت و تحلیل کد میشوند. این تکامل نه تنها مفاهیم جدیدی را معرفی کرده، بلکه منجر به پیشرفتهای تکنولوژیکی و بهبود راهحلهای موجود نیز شده است. یک نمونه بارز، چالش بزرگ سایبری DARPA در سال ۲۰۱۶ است که سیستمهایی مانند Angr [SWS+16] و Mayhem [Maynd] را به نمایش گذاشت. این سیستمها که برای شناسایی و ترمیم آسیبپذیریها در نرمافزارهای ناشناخته به صورت خودکار طراحی شدهاند، برای جایزهای نزدیک به ۴ میلیون دلار رقابت کردند. این رویداد نمادی از یک گام بزرگ در تجزیه و تحلیل برنامههای خودکار مقیاسپذیر در حوزه امنیت بود. این بررسی شامل برخی از مسائل و چالشهای محوری اجرای نمادین است و اصول طراحی اساسی اجراکنندههای نمادین را برای مخاطبان گسترده شرح میدهد [CS18].
در تکمیل این، مقالاتی وجود دارد که به جزئیات اجرای نمادین میپردازند. این مقالات توضیح میدهند که، مانند روشهای سنتی که در آن یک برنامه ورودیهای معمولی مانند اعداد صحیح را دریافت میکند، اجرای نمادین شامل نمادهایی است که نشان دهنده هر مقدار ممکن هستند. این فرآیند، جدا از ماهیت نمادین مقادیر، مشابه اجرای استاندارد رخ میدهد. چالشهای جذاب هنگام برخورد با دستورات نوع پرش شرطی در طول اجرای نمادین ایجاد میشوند. این مقالات همچنین در مورد سیستم EFFIGY [Cla76]، ابزاری که برنامههای نوشته شده به سبک PL/I پایه را تفسیر میکند، بحث میکنند.
اجرای نمادین را برای آزمایش و اشکالزدایی برنامه ارائه میدهد. EFFIGY شامل ویژگیهای مختلف استاندارد اشکالزدایی، قابلیتهایی برای دستکاری و اثبات ادعاهای مربوط به عبارات نمادین، یک مدیر ساده برای نظارت بر آزمایش برنامه و یک اعتبارسنج برنامه است که همگی به درک عمیقتر و کاربردپذیری اجرای نمادین در زمینههای مختلف کمک میکنند [Cla76].
2.2.1 اجرای نمادین با KLEE
اجرای نمادین، یک تکنیک حیاتی در آزمایش نرمافزار، با KLEE [KLE23]، یک موتور اجرای نمادین که به طور گسترده شناخته شده است، به اوج جدیدی از اثربخشی و تطبیقپذیری میرسد. KLEE با در نظر گرفتن ورودیهای برنامه به عنوان مقادیر نمادین، به جای مقادیر ثابت، فرآیند اجرای نمادین را بهبود میبخشد و به آن اجازه میدهد تا مسیرهای اجرایی متعددی را در یک برنامه بررسی کند. این رویکرد KLEE را قادر میسازد تا طیف وسیعی از اشکالات و آسیبپذیریهای بالقوه را که ممکن است تحت روشهای آزمایش مرسوم کشف نشده باقی بمانند، کشف کند. این امر امکان تجزیه و تحلیل جامع رفتار برنامه را در شرایط مختلف فراهم میکند.
علاوه بر این، KLEE از تکنیکهای حل محدودیت برای تعیین امکانپذیری هر مسیر استفاده میکند و از اثباتکنندههای قضیه خودکار برای تولید ورودیهای ملموس که میتوانند باعث ایجاد اشکالات شوند، استفاده میکند و بینشهای ملموسی در مورد شکستهای احتمالی برنامه ارائه میدهد. انعطافپذیری و طراحی ماژولار آن، KLEE را به ابزاری منتخب در تحقیقات دانشگاهی و کاربردهای صنعتی تبدیل کرده است و توسعه نرمافزارهای قوی و بدون خطا را تسهیل میکند. KLEE با پر کردن شکاف بین تحلیل نظری و کاربرد عملی، به عنوان گواهی بر پیشرفتها در تکنیکهای اجرای نمادین است که قابلیتهای تست و تأیید نرمافزار را پیش میبرد.
Cadar و همکارانش [KLE23] آزمایشهای پوشش گسترده با استفاده از KLEE را بر روی بستههای نرمافزاری مختلف، از جمله COREUTILS، [Fou24] BUSYBOX [ea24] و HISTAR [ZB-WKM06] مورد بحث قرار میدهند. تمرکز اصلی بر اندازهگیری اثربخشی موارد تست تولید شده توسط KLEE از طریق پوشش خط است، یک معیار محافظهکارانه که توسط gcov گزارش شده است. اگرچه پوشش خط با نادیده گرفتن کاوشهای مسیر منحصر به فرد، دقت KLEE را دست کم میگیرد، اما معیاری قابل درک از عمق و وسعت کد آزمایش شده ارائه میدهد و توانایی KLEE را در کشف اشکالات و آسیبپذیریهای قابل توجه در پروژههای نرمافزاری متنوع نشان میدهد. آزمایشهای پوشش شامل اجرای موارد آزمایشی تولید شده توسط KLEE بر روی نسخههای مستقل هر ابزار و اندازهگیری پوشش با gcov بود.
این رویکرد تضمین میکند که اشکالات در KLEE بر نتایج تأثیری نداشته باشند و موارد آزمایشی تولید شده کد ادعا شده را اجرا کنند. نتایج پوشش فقط بر کد ابزار تمرکز دارد و کد کتابخانه را حذف میکند تا از شمارش مجدد و پوشش کمتر از حد شمارش جلوگیری شود. آزمایشها شامل تمام 89 ابزار GNU COREUTILS بود که طیف وسیعی از خطوط کد قابل اجرا (ELOC) را در ابزارها نشان میدهد. KLEE به طور متوسط به پوشش خط 90.9٪ برای هر ابزار (میانگین: 94.7٪) دست یافت، با پوشش کلی در تمام ابزارها 84.5٪.
قطعه کد زیر، برنامهی سادهای است که بررسی همارزی را نشان میدهد. KLEE همارزی کامل را اثبات میکند.
unsigned mod opt(unsigned x, unsigned y) {
if((y & -y) == y)
return x & (y - 1);
else
return x % y;
}
unsigned mod(unsigned x, unsigned y) {
return x % y;
}
int main() {
unsigned x,y;
make symbolic(&x, sizeof(x));
make symbolic(&y, sizeof(y));
assert(mod(x,y) == mod opt(x,y));
return 0;
}
قطعه کد C ارائه شده در لیست 2.1، استفاده از KLEE را برای تأیید همارزی دو پیادهسازی مختلف از عملیات ماژول نشان میدهد. تابع mod_opt یک نسخه بهینه شده از محاسبه ماژول است که بررسی میکند آیا مقسوم علیه y توانی از دو است یا خیر. اگر y توانی از دو باشد، ماژول را با استفاده از یک عملیات بیتی محاسبه میکند که کارآمدتر است. در غیر این صورت، به عملیات ماژول استاندارد x % y برمیگردد. از سوی دیگر، تابع mod، ماژول را مستقیماً با استفاده از عملگر استاندارد x % y محاسبه میکند. تابع اصلی از تابع make_symbolic KLEE برای رفتار با متغیرهای x و y به عنوان نمادین استفاده میکند، به این معنی که آنها میتوانند هر مقدار صحیح بدون علامت ممکن را نشان دهند. سپس دستور assert بررسی میکند که برای همه مقادیر ممکن x و y، خروجیهای mod و mod_opt یکسان باشند. KLEE به صورت نمادین برنامه را اجرا میکند، تمام مسیرهای اجرایی ممکن را بررسی میکند و صحت ادعا را برای تمام مقادیر ورودی تأیید میکند و در نتیجه، برابری کامل دو تابع را هنگامی که مقسوم علیه y صفر نیست، اثبات میکند.
مطالعه جامع کادار و همکارانش [KLE23] قدرت KLEE را در دستیابی به پوشش بالا و یافتن خطاهای صحت عمیق در بستههای نرمافزاری مختلف نشان میدهد، که اغلب از قابلیتهای مجموعههای تست نوشته شده دستی فراتر میرود. نتایج، پتانسیل ابزارهای اجرای نمادین مانند KLEE در بهبود قابلیت اطمینان و امنیت نرمافزار را برجسته میکند.
2.2.2 ابزارهای مختلف اجرای نمادین
چندین ابزار اجرای نمادین وجود دارد که هر کدام نقاط قوت و ضعف خود را دارند.
KLEE یکی از محبوبترین ابزارهای اجرای نمادین است، اما بسته به الزامات خاص وظیفه مورد نظر، ممکن است همیشه بهترین انتخاب نباشد. در اینجا مقایسهای از KLEE با سایر ابزارهای اجرای نمادین و دلایلی که چرا KLEE ممکن است در سناریوهای خاص بهترین در نظر گرفته شود، آورده شده است:
- SAGE: اجرای هدایتشده خودکار مقیاسپذیر: این ابزار بر مقیاسپذیری تمرکز دارد، قادر به تجزیه و تحلیل برنامههای بزرگ و پیچیده است و از اجرای نمادین و تجزیه و تحلیل پویا پشتیبانی میکند. این ابزار برای تجزیه و تحلیل سیستمهای نرمافزاری دنیای واقعی مناسب است. با این حال، توسعه آن ممکن است در مقایسه با ابزارهای دیگر مانند KLEE کمتر فعال باشد و مستندات و پشتیبانی جامعه ممکن است به اندازه [GLM08] گسترده نباشد.
- angr: این یک چارچوب بسیار ماژولار و قابل تنظیم برای تجزیه و تحلیل دودویی (باینری)، اجرای نمادین و موارد دیگر است. از طیف گستردهای از معماریها و قالبهای فایل پشتیبانی میکند. این ابزار به طور فعال با یک جامعه رو به رشد نگهداری میشود، اما در مقایسه با برخی ابزارهای دیگر، منحنی یادگیری تندتری دارد. برای راهاندازی و پیکربندی به تلاش بیشتری نیاز دارد [SWS+16].
- SymPy: زبان برنامهنویسی نمادین پایتون: این زبان با پایتون نوشته شده است و ادغام آن را با سایر ابزارها و کتابخانههای مبتنی بر پایتون آسان میکند. این زبان قابلیتهای دستکاری نمادین قدرتمندی را ارائه میدهد و برای اجرای نمادین برنامههای پایتون مناسب است. پشتیبانی محدودی برای تجزیه و تحلیل برنامههای نوشته شده به زبانهای دیگر وجود دارد و ممکن است برای وظایف اجرای نمادین در مقیاس بزرگ به اندازه کافی کارآمد نباشد [Tea24].
- S2E: این زبان بر تجزیه و تحلیل دودویی و اجرای نمادین سیستمهای نرمافزاری دنیای واقعی تمرکز دارد و از تجزیه و تحلیل و ابزار دقیق سفارشی پشتیبانی میکند. این زبان افزونههایی برای وظایف مختلف تجزیه و تحلیل ارائه میدهد. با این حال، در مقایسه با برخی ابزارهای دیگر [CKC11]، تنظیمات و پیکربندی پیچیدهتری دارد.
SAGE بر مقیاسپذیری تمرکز دارد و قادر به تجزیه و تحلیل برنامههای بزرگ و پیچیده با پشتیبانی از اجرای نمادین و تجزیه و تحلیل پویا است. این زبان برای سیستمهای نرمافزاری دنیای واقعی مناسب است، اما در مقایسه با ابزارهایی مانند KLEE، توسعه فعال کمتری دارد و مستندات محدودی دارد [19] Angr یک چارچوب ماژولار و قابل تنظیم برای تجزیه و تحلیل دودویی و اجرای نمادین است که از معماریها و فرمتهای فایل مختلف پشتیبانی میکند. این ابزار به طور فعال با یک جامعه رو به رشد نگهداری میشود، اما منحنی یادگیری تندتری دارد و به تلاش بیشتری برای راهاندازی نیاز دارد. SymPy دستکاری نمادین قدرتمندی را برای برنامههای پایتون و ادغام آسان با ابزارهای پایتون ارائه میدهد، اما پشتیبانی محدودی برای زبانهای دیگر دارد و برای کارهای در مقیاس بزرگ کارایی کمتری دارد. S2E بر تجزیه و تحلیل دودویی و اجرای نمادین برای سیستمهای دنیای واقعی تمرکز دارد و از تجزیه و تحلیل و ابزار دقیق سفارشی پشتیبانی میکند، اما در مقایسه با سایر ابزارها، تنظیمات پیچیدهتری دارد.
2.3 فازینگ
در چشمانداز در حال تحول امنیت سایبری، آسیبپذیری نرمافزار همچنان یک مسئله مهم است و چالشهای قابل توجهی را برای کاربران نهایی و ذینفعان صنعت ایجاد میکند. با وجود پیشرفت در روشها و ابزارهای مختلف با هدف کاهش آسیبپذیریهای نرمافزار، سوالاتی در مورد اثربخشی و دامنه جامع آنها وجود دارد. آیا این ابزارها میتوانند به طور کامل آسیبپذیریهای نرمافزار را برطرف کنند و آیا ابزاری جهانی وجود دارد که قادر به تشخیص انواع آسیبپذیریها باشد؟ [AMW17]. فازینگ یک تکنیک تست نرمافزار پویا است که برای کشف آسیبپذیریها و اشکالات با ارائه مقدار زیادی ورودی داده تصادفی به یک برنامه استفاده میشود. این روش به ویژه در شناسایی نقصهای امنیتی، خرابیها و رفتارهای غیرمنتظره در نرمافزارها مؤثر است.
کاربردها. هدف اصلی فازینگ، آشکارسازی نقاط ضعفی است که میتوانند توسط مهاجمان مورد سوءاستفاده قرار گیرند و در نتیجه امنیت و استحکام کلی نرمافزار را افزایش دهند. ابزارهای فازینگ در رویکردها و قابلیتهای خود متفاوت هستند، از مولدهای داده تصادفی ساده گرفته تا ابزارهای پیچیدهای که از مکانیسمهای بازخورد برای بهینهسازی فرآیند تولید ورودی استفاده میکنند.
2.4 فازینگ با LibFuzzer
LibFuzzer به دلیل اثربخشی در کشف آسیبپذیریهای نرمافزار، به طور گسترده در دانشگاه و صنعت مورد استفاده قرار گرفته است. در زیر چندین مثال برجسته از کاربرد و موفقیت آن آورده شده است:
2.4.0.1 مثال 1: OpenSSL
LibFuzzer برای فازینگ کتابخانه OpenSSL، یک جعبه ابزار پرکاربرد برای پیادهسازی پروتکلهای ارتباطی امن، استفاده شد. فرآیند فازینگ چندین آسیبپذیری امنیتی، از جمله سرریز بافر و نشت حافظه را کشف کرد که متعاقباً وصله شدند.این مطالعه دقیق نشان داد که ادغام LibFuzzer با OpenSSL به طور قابل توجهی استحکام و امنیت کتابخانه را بهبود بخشیده است [Ope20].
2.4.0.2 مثال 2: مرورگر Chromium
پروژه مرورگر Chromium که زیربنای گوگل کروم است، از LibFuzzer به طور گسترده برای آزمایش اجزای مختلف استفاده میکند. LibFuzzer به شناسایی آسیبپذیریهای متعدد، مانند اشکالات use-after-free و heap overflow و به امنیت و پایداری کلی مرورگر کمک کرده است. ادغام LibFuzzer با سیستم ادغام مداوم Chromium تضمین میکند که تغییرات جدید کد به طور کامل آزمایش میشوند [Chr19].
Chi at el [TK21] Futag را معرفی کرد، یک مولد هدف فاز خودکار که برای بهبود آزمایش فاز برای کتابخانههای نرمافزاری طراحی شده است. این رویکرد از تجزیه و تحلیل استاتیک برای جمعآوری اطلاعات در مورد کد منبع، از جمله تعاریف نوع داده، وابستگیها و تعاریف تابع استفاده میکند. کتابخانهها ماژولار بودن را افزایش داده و هزینههای توسعه را کاهش میدهند، اما برای اطمینان از امنیت و صحت، نیاز به آزمایش کامل دارند. چرخه حیات توسعه امنیت مایکروسافت MSDL بر فازینگ در طول مرحله تأیید برای آزمایش و تأیید مدلهای تهدید و سطوح حمله تأکید دارد. Futag با تجزیه و تحلیل کد منبع برای جمعآوری اطلاعات لازم برای استفاده صحیح از API، ایجاد اهداف فازینگ را خودکار میکند. Futag با موفقیت آسیبپذیریهایی را در کتابخانههای محبوب مانند libopenssl، libpng، libjson-c و liblxml2 پیدا کرده است.
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
if(Size < sizeof(int) + sizeof(char))
return 0;
uint8_t * pos = (uint8_t *) Data;
int i;
memcpy(&i, pos, sizeof(int);
pos += sizeof(int);
char c;
memcpy(&c, pos, sizeof(char);
pos += sizeof(char);
some_function(i, c);
return 0;
}
کد بالا یک مثال ساده از نحوه استفاده از LibFuzzer برای تست فازی یک تابع را نشان میدهد. تابع LLVMFuzzerTestOneInput به عنوان نقطه ورودی برای فازر تعریف شده است. این تابع یک اشارهگر به آرایهای از بایتها (const uint8_t *Data) و اندازه ۲۱ این آرایه (size_t Size) میگیرد. این تابع ابتدا با مقایسه Size با مجموع اندازههای آنها، بررسی میکند که آیا دادههای ارائه شده به اندازه کافی بزرگ هستند که شامل هر دو نوع داده int و char باشند یا خیر. اگر دادهها کافی نباشند، تابع بلافاصله مقدار را برمیگرداند. در غیر این صورت، تابع به استخراج یک نوع داده int و یک نوع داده char از دادهها میپردازد. تابع memcpy برای کپی کردن بایتها از آرایه داده به ترتیب در متغیرهای i و c استفاده میشود. پس از استخراج مقادیر، تابع some_function(i, c) را فراخوانی میکند و عدد صحیح و کاراکتر استخراج شده را به عنوان آرگومان ارسال میکند. این تنظیمات به LibFuzzer اجازه میدهد تا ورودیهای مختلفی تولید کند و رفتار some_function را با ترکیبات مختلف مقادیر int و char آزمایش کند.
۲.۴.۱ ابزارهای مختلف فازینگ
فازینگ یک تکنیک تست پویای نرمافزار است که برای کشف آسیبپذیریها با ارائه ورودیهای تصادفی یا جهشیافته به یک برنامه استفاده میشود. ابزارهای فازینگ مختلفی توسعه داده شدهاند که هر کدام ویژگیها و نقاط قوت منحصر به فردی دارند تا انواع مختلف آسیبپذیریهای نرمافزاری را به طور مؤثر کشف کنند. این بخش برخی از محبوبترین ابزارهای فازینگ را معرفی میکند و ویژگیها و اثربخشی آنها را برجسته میکند.
- AFL (American Fuzzy Lop) AFL: یکی از محبوبترین و پرکاربردترین ابزارهای فازینگ است. این ابزار از الگوریتمهای ژنتیک برای جهش دادههای ورودی استفاده میکند و در یافتن آسیبپذیریهای متعدد موفق بوده است. راهاندازی و استفاده از AFL نسبتاً آسان است. با این حال، AFL ممکن است با پایگاههای کد پیچیده یا به شدت ابزاربندی شده مشکل داشته باشد و عملکرد آن میتواند هنگام فازینگ برنامههای بزرگ یا پیچیده کاهش یابد [Zal16].
- honggfuzz :honggfuzz یکی دیگر از ابزارهای فازینگ محبوب است که به دلیل سرعت و کاراییاش شناخته شده است. این ابزار از تکنیکهای فازینگ مبتنی بر بازخورد استفاده میکند و از معیارهای پوشش مختلف پشتیبانی میکند. honggfuzz بسیار قابل تنظیم است و میتواند برنامههای پیچیده را به خوبی مدیریت کند. با این حال، مانند AFL، ممکن است با چالشهایی با کد بسیار ابزاربندی شده یا برنامههای هدف پیچیده مواجه شود [Swi24].
- Radamsa :Radamsa کمی با AFL و honggfuzz متفاوت است؛ این یک مولد مورد آزمایشی است نه یک فازر تمام عیار. این ابزار با جهش تصادفی ورودیهای موجود برای تولید موارد آزمایشی جدید کار میکند. Radamsa سبک است و میتواند در چارچوبهای تست موجود ادغام شود. در حالی که برای تولید ورودیهای متنوع مؤثر است، فاقد رویکرد مبتنی بر بازخورد AFL و honggfuzz است [Hel24].
- LibFuzzer :LibFuzzer، بخشی از زیرساخت کامپایلر LLVM، مزایای متعددی نسبت به سایر ابزارهای فازینگ ارائه میدهد. یکی از نقاط قوت کلیدی آن، ادغام آن با پوشش ضدعفونیکننده LLVM ASan، MSan و غیره است که امکان فازینگ هدایتشده با پوشش دقیق را فراهم میکند. LibFuzzer برای فازینگ در حین فرآیند طراحی شده است، که آن را کارآمد میکند و برای فازینگ پایگاههای کد بزرگ و پیچیده مناسب میسازد. ادغام محکم آن با LLVM استفاده از آن را آسان میکند و در جامعه LLVM به خوبی پشتیبانی میشود. علاوه بر این، استراتژیهای جهش LibFuzzer بسیار کارآمد هستند و اغلب میتوانند اشکالات را سریعتر از سایر فازرها پیدا کنند [Ser24].
به طور خلاصه، در حالی که AFL، honggfuzz و Radamsa همگی ابزارهای فازینگ قدرتمندی با مزایای خاص خود هستند، LibFuzzer به دلیل فازینگ هدایتشده با پوشش دقیق، استراتژیهای جهش کارآمد، سهولت ادغام با ضدعفونیکنندههای LLVM و پشتیبانی قوی جامعه، برجسته است. این عوامل آن را به انتخابی عالی برای فازینگ انواع مختلف پروژههای نرمافزاری، به ویژه پروژههایی با پایگاههای کد پیچیده، تبدیل میکند.
۲.۵ فازینگ با اجرای نمادین
فازینگ، که با اجرای یک برنامه با ورودیهای تصادفی، اشکالات را کشف میکند، به دلیل غیرقابل پیشبینی بودن ورودیهای آن، تا حدودی در کاوش مسیرهای مختلف کد محدود است. اجرای نمادین، با در نظر گرفتن ورودیها به عنوان نماد، از لحاظ تئوری پوشش کاملی از کد را به دست میآورد، اما به دلیل تقاضای بالای آن برای منابع، در سناریوهای دنیای واقعی غیرعملی است.
این رویکرد ترکیبی با اجرای نمادین برای ترسیم مسیرهای منحصر به فرد برنامه آغاز میشود و به دنبال آن فازینگ با ورودیهای تصادفی متناسب با این مسیرها انجام میشود.این رویکرد که به ویژه برای برنامههایی با گزارههای مسیر خطی مؤثر است، از یک مدل چندوجهی برای تولید ورودیها استفاده میکند و در نتیجه دامنه آزمایش را گسترش و تعمیق میبخشد. پیادهسازی آن بهبودهای چشمگیری در کارایی نشان داده است و از روشهای قبلی در هر دو زمینه زمان و استفاده از منابع [PKS+12] بهتر عمل میکند. با توجه به ضرورت ابزارهای پیشرفته بررسی نرمافزار، به ویژه با افزایش موارد آسیبپذیریهای خرابی حافظه که امنیت دادههای حساس را به خطر میاندازند، تقاضای فزایندهای برای رویکردهای خودکار وجود دارد. این نیاز با سرمایهگذاری قابل توجه DARPA در رقابتی برای تحریک کشف و وصلهگذاری خودکار آسیبپذیریها برجسته شده است. روشهای فعلی تشخیص باگ مانند تحلیل استاتیک، دینامیک و کانکولیک، علیرغم نقاط قوت منحصر به فرد خود، اغلب در شناسایی باگهای پیچیدهتر دچار مشکل میشوند.
دریلِر [SGS+16]، یک شرکت پیشگام در زمینه سیستمهای ترکیبی، با هدف پرداختن به این شکاف،ابزاری که فازینگ را با اجرای انتخابی کانکولیک ترکیب میکند، معرفی شد. این روش از فازینگ مقرونبهصرفه برای کاوش بخشهای مختلف برنامه استفاده میکند و با اجرای کانکولیک برای پیمایش بررسیهای پیچیده تکمیل میشود و در نتیجه نقاط قوت هر دو روش را هماهنگ میکند. این همافزایی نه تنها معضل انفجار مسیر ذاتی در تحلیل کانکولیک را دور میزند، بلکه بر محدودیتهای فازینگ نیز غلبه میکند. دریلر به طور استراتژیک از اجرای کانکولیک برای کاوش در مسیرهای مشخص شده توسط فازر و برآورده کردن شرایطی که در غیر این صورت با فازینگ به تنهایی غیرقابل دستیابی هستند، استفاده میکند. مهارت آن به ویژه در عملکردش در رویداد مقدماتی چالش بزرگ سایبری DARPA مشهود بود، جایی که با موفقیت تیم پیشرو در شناسایی آسیبپذیریها در همان بازه زمانی [SGS+16] برابری کرد.
کمپوس و همکارانش [CV20] 10 آزمایش ورودی و خروجی برای هر الگوریتم انجام دادند تا مطابقت جریان داده بین کد C و معادل Verilog آن را تأیید کنند. نتایج نشان داد که کد Verilog تولید شده توسط LegUp بسیار نزدیک به برنامه اصلی C است. این تطابق نزدیک به طور مداوم در تمام آزمایشها مشاهده شد که نشان دهنده سنتز سطح بالای قابل اعتماد (HLS) است. مقایسه میانگین زمان اجرا، افزایش قابل توجهی را برای کدهای Verilog تولید شده در مقایسه با برنامههای اولیه C نشان داد. این افزایش عملکرد نشان میدهد که ابزارهای HLS مانند LegUp پیادهسازیهای سختافزاری کارآمدی تولید میکنند. محققان پیشنهاد میکنند که در کارهای آینده از KLEE و LibFuzzer برای مقایسه جریان دادهها با سایر ابزارهای HLS موجود در بازار استفاده شود. این به ارزیابی قابلیت استفاده و عملکرد آنها در برنامههای واقعی، مشابه ارزیابی انجام شده با LegUp HLS در این مطالعه [CV20]، کمک خواهد کرد.
2.6 خلاصه
این فصل به تکنیکهای اساسی اجرای نمادین و فازینگ در حوزه امنیت سایبری میپردازد و نقش آنها را در شناسایی و کاهش آسیبپذیریهای نرمافزاری برجسته میکند. این فصل با مقدمهای بنیادی در مورد هر دو روش آغاز میشود، اینکه چگونه هر تکنیک به طور منحصر به فرد در فرآیند تشخیص آسیبپذیری نقش دارد. اجرای نمادین به عنوان یک رویکرد روشمند ارائه میشود که تمام مسیرهای اجرای ممکن یک برنامه را با در نظر گرفتن ورودیها به عنوان مقادیر نمادین بررسی میکند و در نتیجه طیف گستردهای از خطاهای بالقوه را کشف میکند. این فصل به تفصیل توضیح میدهد که چگونه ابزارهایی مانند KLEE با فراهم کردن امکان تجزیه و تحلیل و تأیید جامع برنامه، به ویژه از طریق اثبات خودکار قضیه و حل محدودیت، این فرآیند را تسهیل میکنند.
همچنین ابزارهای مختلف اجرای نمادین را مقایسه میکند و ویژگیهای خاص و زمینههای کاربردی آنها را مورد بحث قرار میدهد تا درکی از نقاط قوت و ضعف آنها ارائه دهد. سپس فازینگ وجود دارد، تکنیکی که با بمباران نرمافزار با انبوهی از ورودیهای تصادفی، آسیبپذیریها را شناسایی میکند. این فصل بر اثربخشی ابزارهایی مانند LibFuzzer تأکید میکند که با LLVM برای بهینهسازی تولید ورودی و تشخیص اشکالات ظریف، از نزدیک ادغام میشود. این فصل از طریق مثالهای مفصلی، مانند کاربرد LibFuzzer در آزمایش کتابخانه OpenSSL و مرورگر Chromium، مزایا و موفقیتهای عملی فازینگ را در سناریوهای دنیای واقعی نشان میدهد. بخش قابل توجهی از این فصل به بررسی ادغام اجرای نمادین با فازینگ اختصاص داده شده است و یک رویکرد ترکیبی را تشکیل میدهد که از نقاط قوت بهره میبرد.
هر دو تکنیک این روش با اجرای نمادین برای ترسیم مسیرهای منحصر به فرد برنامه آغاز میشود و با ورودیهای فازینگ هدفمند ادامه مییابد و در نتیجه دامنه و عمق تشخیص آسیبپذیری را افزایش میدهد. این فصل به توسعه Driller اشاره میکند، ابزاری که این روش ترکیبی را با ترکیب فازینگ مقرون به صرفه با اجرای انتخابی concolic نشان میدهد و اثربخشی آن را در چالشهای امنیتی در مقیاس بزرگ مانند چالش بزرگ سایبری DARPA نشان میدهد.
این فصل با تأکید بر نیاز حیاتی به ابزارهای تست نرمافزار پیشرفته و خودکار در مواجهه با تهدیدات امنیتی فزاینده به پایان میرسد. این فصل پیامدهای گستردهتر این تکنیکها را برای قابلیت اطمینان و امنیت نرمافزار مورد بحث قرار میدهد و از نوآوری و ادغام مداوم اجرای نمادین و فازینگ برای پرداختن به چشمانداز در حال تحول آسیبپذیریهای امنیت سایبری حمایت میکند.
در اصل، این فصل بررسی کاملی از اجرای نمادین و فازینگ ارائه میدهد و اهمیت آنها را در شیوههای مدرن امنیت نرمافزار و پتانسیل آنها برای پیشرفتهای آینده در این زمینه برجسته میکند.
فصل 3:
الزامات تحلیل و آزمایش برای ارزیابی آسیبپذیری
SQLite یک موتور پایگاه داده تعبیهشده است که به طور گسترده مورد استفاده قرار میگیرد. با توجه به ماهیت حیاتی یکپارچگی دادهها و امنیت در سیستمهای پایگاه داده، آزمایش جامع برای کشف آسیبپذیریهای بالقوه ضروری است. این مطالعه بر تجزیه و تحلیل چشمانداز آسیبپذیری در SQLite، به ویژه با هدف قرار دادن SQLite-amalgamation- 3450100 release [sqlnd] که به طور گسترده استفاده میشود، تمرکز دارد. استحکام و امنیت در نرمافزار پایگاه داده بسیار مهم هستند، زیرا آسیبپذیریها میتوانند منجر به مشکلات یکپارچگی دادهها، انکار سرویس یا حتی پتانسیل اجرای کد از راه دور شوند. این فصل دامنه آسیبپذیریهای بررسی شده را تعریف میکند و الزامات ابزارهای آزمایش اصلی این تحقیق را تشریح میکند.
3.1 KLEE و معماری آن
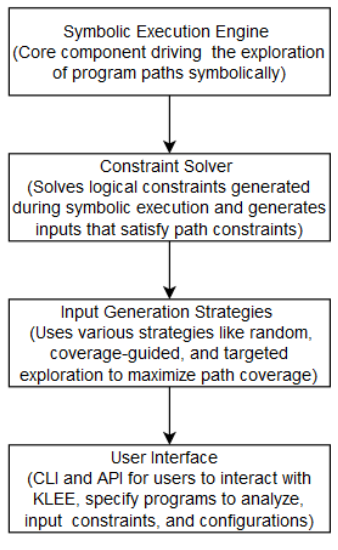
KLEE به طور گسترده برای تولید خودکار موارد آزمون و یافتن اشکال استفاده میشود. این پایاننامه مروری بر اجزای کلیدی آن، از جمله موتور اجرای نمادین، حلکننده (Solver) محدودیت، استراتژیهای تولید ورودی و رابط کاربری برای تعامل کاربر ارائه میدهد. علاوه بر این، معماری KLEE امکان سفارشیسازی گسترده و ادغام با سایر ابزارها را فراهم میکند و قابلیتها و کاربردپذیری آن را در حوزههای مختلف افزایش میدهد.
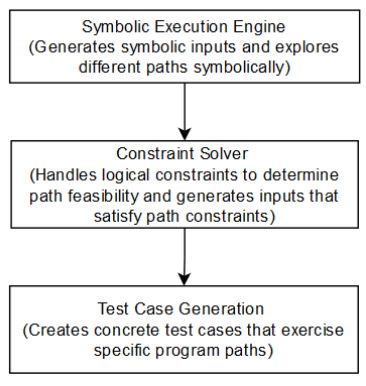
شکل 3.1 گردش کار اجرای نمادین در تست نرمافزار را نشان میدهد که شامل سه جزء کلیدی است: موتور اجرای نمادین، حلکننده محدودیتها و تولید مورد آزمایشی. موتور اجرای نمادین فرآیند را با تولید ورودیهای نمادین به جای مقادیر خاص آغاز میکند و مسیرهای مختلف اجرای برنامه را به صورت نمادین بررسی میکند. این رویکرد به موتور اجازه میدهد تا شرایط و شاخههای متعددی را در کد در نظر بگیرد. سپس حلکننده محدودیتها کنترل را به دست میگیرد و محدودیتهای منطقی ایجاد شده توسط اجرای نمادین را مدیریت میکند. با حل این محدودیتها، امکانپذیری هر مسیر را تعیین میکند و مقادیر ورودی مشخصی را تولید میکند که آنها را برآورده میکند و تضمین میکند که فقط مسیرهای امکانپذیر آزمایش میشوند. در نهایت، جزء تولید مورد آزمایشی از این ورودیهای مشخص برای ایجاد موارد آزمایشی خاصی استفاده میکند که مسیرهای برنامه شناسایی شده را آزمایش میکنند. این رویکرد سیستماتیک با پوشش سناریوهای اجرایی متنوع در نرمافزار، تست کامل را تضمین میکند.
۳.۱.۱ موتور اجرای نمادین
موتور اجرای نمادین، جزء اصلی KLEE را تشکیل میدهد و کاوش مسیرهای برنامه را به صورت نمادین هدایت میکند. این موتور به جای اجرای دستورالعملها با مقادیر مشخص، بر اساس نمایشهای نمادین متغیرهای برنامه عمل میکند. با پیشرفت اجرا، مقادیر نمادین متغیرها را ردیابی میکند و هر زمان که با عبارات شرطی مواجه میشود، مسیر اجرا را منشعب میکند. با کاوش مسیرهای مختلف به صورت نمادین، موتور قصد دارد اشکالات و آسیبپذیریهای برنامه را کشف کند.
int main() {
int a, b;
// Mark inputs as symbolic
klee_make_symbolic(&a, sizeof(a), "a");
klee_make_symbolic(&b, sizeof(b), "b");
return simple_function(a, b);
}
در قطعه کد بالا، خود برنامه خروجی سنتی مانند دستور print تولید نمیکند؛ در عوض، به عنوان ورودی برای KLEE جهت اجرای نمادین عمل میکند. KLEE برنامه را دریافت کرده و با در نظر گرفتن تمام مقادیر ممکن برای متغیرهای نمادین a و b، آن را تجزیه و تحلیل میکند. از طریق این فرآیند، KLEE تمام مسیرهای اجرایی را که برنامه میتواند بر اساس ترکیبات مختلف این مقادیر نمادین طی کند، بررسی میکند. هنگامی که KLEE این برنامه را اجرا میکند، مجموعهای از موارد آزمایشی تولید میکند که هر کدام مربوط به یک مسیر اجرایی منحصر به فرد در تابع simple_function(a, b) هستند. این موارد آزمایشی شامل مقادیر خاصی برای a و b هستند که باعث میشوند برنامه مسیرهای مختلفی را دنبال کند. KLEE این موارد آزمایشی را خروجی میدهد که میتوانند برای درک رفتار برنامه در شرایط مختلف و کشف بالقوه اشکالات، آسیبپذیریها یا رفتارهای غیرمنتظره استفاده شوند.
علاوه بر این، KLEE ممکن است گزارشهایی را تولید کند که جزئیات مسیرهای طی شده، شرایط منتهی به آن مسیرها و هرگونه خطا یا ادعایی را که در طول اجرا با آن مواجه میشود، شرح دهد. اجرای نمادین به KLEE اجازه میدهد تا با در نظر گرفتن ورودیها به عنوان مقادیر نمادین، تعداد زیادی از مسیرهای اجرا را به طور سیستماتیک بررسی کند. این تکنیک به ویژه در شناسایی موارد مرزی و آسیبپذیریهایی که ممکن است توسط روشهای سنتی آزمایش از دست بروند، مؤثر است. این فرآیند را میتوان در شکل 5.4 مشاهده کرد.
int main() {
char query[256];
klee_make_symbolic(&query, sizeof(query), "query");
sqlite3 *db;
sqlite3_open(":memory:", &db);
sqlite3_exec(db, query, NULL, NULL, NULL);
sqlite3_close(db);
return 0;
}
قطعه کد بالا، استفاده از متغیرهای نمادین در KLEE را در یک زمینه SQLite نشان میدهد. برنامه با گنجاندن هدرهای لازم برای KLEE و SQLite شروع میشود. در تابع اصلی، یک پرسوجوی آرایه کاراکتری با اندازه ۲۵۶ تعریف و با استفاده از klee_make_symbolic به عنوان نمادین علامتگذاری میشود. این بدان معناست که KLEE با پرسوجو به عنوان متغیری رفتار میکند که میتواند هر مقداری را در محدوده اندازه خود بپذیرد. سپس برنامه یک پایگاه داده SQLite در حافظه را باز میکند، پرسوجوی نمادین SQL ذخیره شده در پرسوجو را با استفاده از sqlite3_exec اجرا میکند و در نهایت پایگاه داده را میبندد. هنگامی که KLEE این برنامه را اجرا میکند، پرسوجوهای SQL مختلفی را برای پرسوجو ایجاد میکند و مسیرهای اجرایی مختلف ناشی از این پرسوجوها را بررسی میکند. KLEE مجموعهای از موارد آزمایشی را خروجی میدهد که هر کدام مربوط به یک مسیر اجرایی منحصر به فرد هستند و به شناسایی مشکلات بالقوه مانند آسیبپذیریهای تزریق SQL و سایر رفتارهای غیرمنتظره در اجرای پرسوجوی SQLite کمک میکنند. این فرآیند به آزمایش کامل پاسخ برنامه به طیف وسیعی از پرسوجوهای ورودی کمک میکند.
3.1.2 حل کننده محدودیت (Constraint Solver)
حلکننده محدودیت با حل محدودیتهای منطقی ایجاد شده در طول اجرای نمادین، نقش مهمی در عملکرد KLEE ایفا میکند. این محدودیتها از شرایط انشعاب و سایر محدودیتهای برنامه که در طول کاوش مسیر با آنها مواجه میشویم، ناشی میشوند. حلکننده با حل رضایتبخش محدودیتهای مرتبط با یک مسیر مشخص، امکانسنجی آن را تعیین میکند. علاوه بر این، ورودیهایی تولید میکند که محدودیتهای مسیر را برآورده میکنند و KLEE را قادر میسازد تا موارد آزمایشی مشخصی را تولید کند که مسیرهای برنامه خاصی را اعمال میکنند.
KLEE با چندین حلکننده محدودیت، مانند STP و Z3، ادغام میشود تا محدودیتهای منطقی را به طور موثر مدیریت کند. عملکرد حلکننده بسیار مهم است زیرا مستقیماً بر سرعت و مقیاسپذیری فرآیند اجرای نمادین تأثیر میگذارد.
۳.۱.۳ استراتژیهای تولید ورودی
KLEE از استراتژیهای مختلف تولید ورودی برای کاوش کارآمد مسیرهای برنامه استفاده میکند. این استراتژیها شامل کاوش تصادفی، کاوش هدایتشده با پوشش و کاوش هدفمند است. کاوش تصادفی شامل انتخاب تصادفی مسیرها برای کاوش است، در حالی که کاوش هدایتشده با پوشش، مسیرهایی را که پوشش کد را افزایش میدهند، اولویتبندی میکند. کاوش هدفمند بر ویژگیهای خاص برنامه یا شرایط مورد نظر، مانند کد مدیریت خطا یا عملیات حساس به امنیت تمرکز دارد. با ترکیب این استراتژیها، KLEE قصد دارد پوشش مسیر را به حداکثر برساند و اشکالات و آسیبپذیریهای بالقوه را به طور مؤثر کشف کند.
#include
int main() {
char query[256];
klee_make_symbolic(&query, sizeof(query), ’query’);
if (strstr(query, ’DROP␣TABLE’) != NULL) {
klee_assert(0 && ’Potential␣SQL␣injection␣detected’);
}
sqlite3 *db;
sqlite3_open(’:memory:’, &db);
sqlite3_exec(db, query, NULL, NULL, NULL);
sqlite3_close(db);
return 0;
}
قطعه کد ارائه شده در لیست ۴.۱، استفاده از کاوش هدفمند در KLEE را برای تشخیص آسیبپذیریهای بالقوه تزریق SQL نشان میدهد. این برنامه شامل هدرهای لازم برای KLEE، عملیات رشتهای و SQLite است. در تابع اصلی، یک پرسوجوی آرایهای کاراکتری با اندازه ۲۵۶ تعریف و با استفاده از klee_make_symbolic به عنوان نمادین علامتگذاری میشود. سپس برنامه بررسی میکند که آیا پرسوجوی نمادین حاوی رشته “DROP TABLE” است یا خیر. اگر این شرط برآورده شود، klee_assert برای علامتگذاری یک آسیبپذیری بالقوه تزریق SQL فعال میشود. برنامه به باز کردن یک پایگاه داده SQLite در حافظه، اجرای پرسوجوی نمادین و بستن پایگاه داده ادامه میدهد. هنگامی که KLEE این برنامه را اجرا میکند، به طور سیستماتیک مقادیر ورودی مختلفی را برای پرسوجو تولید میکند و مسیرهای اجرا را بررسی میکند. اگر هر ورودی تولید شده حاوی “DROP TABLE” باشد، KLEE آن را تشخیص داده و عملیات ادعا را آغاز میکند و آسیبپذیری را برجسته میکند. این کاوش هدفمند به شناسایی و رسیدگی به مسائل امنیتی خاص در کد کمک میکند.
3.1.4 رابط کاربری
KLEE رابطی را برای کاربران فراهم میکند تا با ابزار تعامل داشته باشند و برنامهای را که باید تجزیه و تحلیل شود، به همراه هرگونه محدودیت یا پیکربندی ورودی، مشخص کنند. کاربران میتوانند از طریق رابط خط فرمان یا از طریق API با KLEE تعامل داشته باشند. در حالی که KLEE در درجه اول از برنامههای نوشته شده به زبانهای C و ++C پشتیبانی میکند، افزونهها و سازگاریهایی برای سایر زبانهای برنامهنویسی وجود دارد. این رابط کاربری به کاربران امکان میدهد پارامترهای تجزیه و تحلیل را سفارشی کنند، محدودیتهای ورودی را مشخص کنند و نتایج تجزیه و تحلیل را به طور موثر تفسیر کنند.
انعطافپذیری و توسعهپذیری KLEE آن را برای طیف وسیعی از برنامهها، از تحقیقات دانشگاهی گرفته تا موارد استفاده صنعتی، مناسب میکند. این ابزار با موفقیت در حوزههای مختلف، از جمله آزمایش امنیتی، تأیید نرمافزار و تولید خودکار تست، به کار گرفته شده است. بخشهای زیر نمونههایی از برنامههای دنیای واقعی و مطالعات موردی را ارائه میدهند که اثربخشی KLEE را نشان میدهند.
3.1.5 ادغام با سایر ابزارها
KLEE میتواند با سایر ابزارها و چارچوبها ادغام شود تا قابلیتهای آن افزایش یابد. برای مثال، KLEE میتواند با AddressSanitizer (ASan) و MemorySanitizer (MSan) کار کند تا انواع بیشتری از خطاهای حافظه را در طول اجرای نمادین تشخیص دهد. ASan میتواند به تشخیص خطاهای سرریز بافر پشته، سرریز بافر پشته و استفاده پس از آزادسازی کمک کند، در حالی که MSan میتواند استفاده از حافظه مقداردهی اولیه نشده را تشخیص دهد.
3.1.6 مطالعات موردی و کاربردها
KLEE در برنامههای مختلف دنیای واقعی برای کشف اشکالات بحرانی و بهبود قابلیت اطمینان نرمافزار استفاده شده است. به عنوان مثال، KLEE برای تجزیه و تحلیل GNU Coreutils، مجموعهای از ابزارهای اساسی دستکاری فایل، پوسته و متن، مورد استفاده قرار گرفت. این تجزیه و تحلیل اشکالات متعددی را نشان داد که بسیاری از آنها سالها وجود داشتند [CDE08]. یکی دیگر از کاربردهای قابل توجه KLEE در حوزه آزمایش پروتکل شبکه است، جایی که برای یافتن آسیبپذیریهای امنیتی در پروتکلهای پرکاربرد [CDE08] استفاده شده است. این مطالعات موردی، پتانسیل KLEE را برای بهبود کیفیت و امنیت نرمافزار با ارائه قابلیتهای آزمایش کامل و خودکار برجسته میکند.
۳.۲ LibFuzzer و معماری آن
LibFuzzer یک ابزار فازینگ با هدایت پوشش است که به عنوان بخشی از پروژه LLVM ماشین مجازی سطح پایین توسعه داده شده است. این ابزار از یک رویکرد تست تصادفی هدایتشده برای کشف کارآمد اشکالات و آسیبپذیریها در نرمافزار با تولید دادههای ورودی که پوشش کد را به حداکثر میرساند، استفاده میکند. LibFuzzer به گونهای طراحی شده است که بسیار کارآمد باشد و آن را برای فازینگ در مقیاس بزرگ در انواع مختلف پروژههای نرمافزاری مناسب میسازد.
int LLVMFuzzerTestOneInput(const uint8_t*Data, size_t Size) {
DoSomething(Data, Size);
return 0;
}
قطعه کد ارائه شده در بالا، ساختار اساسی یک تابع هدف فازینگ برای LibFuzzer را نشان میدهد، ابزاری که برای آزمایش نرمافزار با تولید ورودیهای تصادفی طراحی شده است. تابع LLVMFuzzerTestOneInput یک نقطه ورود استاندارد است که توسط LibFuzzer استفاده میشود و دو پارامتر میگیرد: یک اشارهگر به بافر داده Data و اندازه آن Size در داخل تابع، تابع DoSomething با این پارامترها فراخوانی میشود که نشاندهنده کدی است که باید آزمایش شود. تابع مقدار 0 را برمیگرداند که نشاندهنده اجرای موفقیتآمیز است. LibFuzzer با تولید ورودیهای تصادفی و نیمهتصادفی متعدد و ارسال آنها به LLVMFuzzerTestOneInput برای بررسی مسیرهای مختلف اجرا و موارد مرزی در DoSomething عمل میکند. این فرآیند به شناسایی اشکالات، خرابیها و آسیبپذیریهای امنیتی بالقوه کمک میکند. LibFuzzer با تغییر مداوم ورودیها برای به حداکثر رساندن پوشش کد، آزمایش کامل کد هدف را تضمین میکند و آن را به ابزاری مؤثر برای آزمایش قوی نرمافزار و ارزیابی امنیتی تبدیل میکند.
۳.۲.۱ مقداردهی اولیه (Initialization)
پس از مقداردهی اولیه، LibFuzzer فایل باینری هدف را بارگذاری کرده و چارچوب ابزار دقیق خود را مقداردهی اولیه میکند. این چارچوب با آمادهسازی دادههای ورودی و سایر پیکربندیهای لازم، محیط را برای فازینگ آماده میکند. چارچوب ابزار دقیق به LibFuzzer اجازه میدهد تا بخشهایی از کد را که در طول هر اجرا اجرا میشوند، نظارت کند، که برای رویکرد هدایتشده توسط پوشش آن ضروری است.
قطعه کد ارائه شده در لیست ۳.۵ ساختار اساسی یک تابع هدف Lib-Fuzzer در زبان C را نشان میدهد که برای آزمایش تابع process_string با تولید ورودیهای تصادفی طراحی شده است. این شامل هدرهای استاندارد برای مدیریت حافظه و عملیات رشتهای و یک هدر سفارشی برای تابع process_string است. تابع LLVMFuzzerTestOneInput برای دریافت یک بافر داده و اندازه آن به عنوان ورودی تعریف شده است. در داخل این تابع، یک بافر برای نگهداری دادههای ورودی به علاوه یک پایانه تهی اختصاص داده میشود. اگر تخصیص حافظه با شکست مواجه شود، تابع خارج میشود. دادههای ورودی در این بافر کپی میشوند که سپس به null-terminated تبدیل میشود تا یک رشته C معتبر تشکیل دهد.
#include
int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
char *buf = (char *)malloc(Size + 1);
if (buf == NULL) {
return 0;
}
memcpy(buf, Data, Size);
buf[Size] = ’\0’;
// Call the function to be fuzzed.
process_string(buf);
return 0;
}
تابع process_string با این بافر فراخوانی میشود تا فازی شود و پس از اجرای تابع، حافظه اختصاص داده شده آزاد میشود تا از نشت حافظه جلوگیری شود. LibFuzzer این تابع را بارها و بارها با ورودیهای مختلف فراخوانی میکند و به طور سیستماتیک مسیرهای مختلف اجرا در process_string را بررسی میکند تا اشکالات یا آسیبپذیریهای بالقوه را کشف کند.
3.2.2 استراتژیهای جهش (Mutation Strategies)
LibFuzzer از استراتژیهای جهش (mutation) مختلفی برای تولید دادههای ورودی استفاده میکند. این استراتژیها شامل جهشهای ساده مانند bit flips، byte swaps و additions و همچنین جهشهای پیچیدهتر مانند dictionary-based mutation و mutation seeds هستند. این استراتژیها به تولید طیف گستردهای از ورودیها کمک میکنند که میتوانند انواع مختلف اشکالات را کشف کنند.
- Bit flips: بیتها را به طور تصادفی در دادههای ورودی معکوس میکنند.
- Byte swaps: بایتها را در دادههای ورودی جابجا میکنند.
- additions: اضافه کردن مقادیر تصادفی به بایتها در دادههای ورودی.
- جهش مبتنی بر دیکشنری: استفاده از یک دیکشنری از ورودیهای شناختهشده برای جهش دادههای ورودی.
- بذرهای جهش: استفاده از بذرهایی که قبلاً رفتار جالبی را ایجاد کردهاند برای تولید ورودیهای جدید.
3.2.3 فازینگ مبتنی بر بازخورد
LibFuzzer از یک رویکرد مبتنی بر بازخورد برای هدایت فرآیند فازینگ استفاده میکند. این روش به طور مداوم پوشش کد را در حین اجرا رصد میکند و ورودیهایی را که منجر به مسیرهای کد بررسی نشده میشوند، اولویتبندی میکند. این حلقه بازخورد با تمرکز بر مناطقی از کد که کمتر پوشش داده شدهاند، به حداکثر رساندن کارایی فازینگ کمک میکند و در نتیجه احتمال کشف اشکالات جدید را افزایش میدهد.
3.2.4 ادغام پاک کنندهها (Sanitizers Integration)
LibFuzzer به طور یکپارچه با پاک کننده (Sanitizer)های LLVM مانند AddressSanitizer (ASan)، MemorySanitizer (MSan) و UndefinedBehaviorSanitizer (UBSan) ادغام میشود. این ادغام LibFuzzer را قادر میسازد تا خطاهای حافظه، رقابتهای داده و رفتارهای تعریف نشده در برنامه هدف را در طول فازینگ تشخیص دهد. این پاککنندهها بررسیهای اضافی ارائه میدهند و به شناسایی آسیبپذیریهایی که ممکن است تنها با فازینگ شناسایی نشوند، کمک میکنند.
- AddressSanitizer (ASan): اشکالات خرابی حافظه مانند سرریز بافر و خطاهای استفاده پس از آزادسازی را تشخیص میدهد.
- MemorySanitizer (MSan): خواندنهای حافظه مقداردهی اولیه نشده را تشخیص میدهد.
- UndefinedBehaviorSanitizer (UBSan): رفتارهای تعریف نشده در کد را تشخیص میدهد.
۳.۲.۵ فازینگ موازی
LibFuzzer از فازینگ موازی پشتیبانی میکند و به چندین نمونه از فازینگ اجازه میدهد تا به طور همزمان روی هستههای CPU یا ماشینهای مختلف اجرا شوند. این موازیسازی، مقیاسپذیری فازینگ را افزایش میدهد و کشف اشکال را در پایگاههای کد بزرگ تسریع میکند. با توزیع حجم کار، فازینگ موازی میتواند زمان مورد نیاز برای دستیابی به پوشش بالا و کشف اشکالات بحرانی را به میزان قابل توجهی کاهش دهد.
۳.۲.۶ مدیریت خرابی
LibFuzzer به طور خودکار خرابیها و استثنائات ایجاد شده توسط برنامه هدف را در حین فازینگ تشخیص میدهد. این ابزار گزارشهای خرابی، از جمله ردپاهای پشته و دادههای ورودی که باعث خرابی شدهاند را ثبت میکند و اشکالزدایی و اولویتبندی آسیبپذیریهای کشف شده را تسهیل میکند.
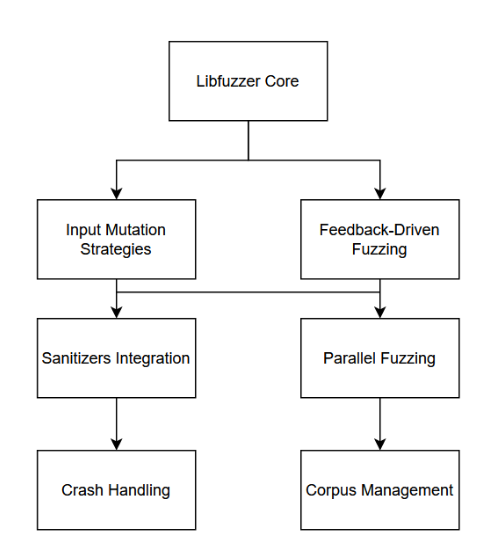
۳.۲.۷ مدیریت مجموعه دادهها
LibFuzzer مجموعهای از دادههای ورودی را که در راهاندازی مسیرهای کد جالب یا کشف اشکالات موفق بودهاند، نگهداری میکند. این مجموعه دادهها را به صورت پویا در طول فازینگ بهروزرسانی میکند و ورودیهای جدیدی را اضافه میکند که به افزایش پوشش کد یا کشف اشکالات کمک میکنند. این مجموعه دادهها به عنوان یک منبع ارزشمند برای آزمایش رگرسیون عمل میکند و تضمین میکند که اشکالات کشف شده قبلی دوباره رخ نمیدهند.
۳.۲.۸ بهینهسازی عملکرد
LibFuzzer برای عملکرد بهینه شده است و از تکنیکهایی مانند فازینگ در حین فرآیند، ساختارهای داده کارآمد برای ردیابی پوشش و به حداقل رساندن سربارهای مرتبط با ابزار دقیق استفاده میکند. این فرآیند در شکل ۳.۳ نشان داده شده است. این بهینهسازیها تضمین میکنند که فازر میتواند کمپینهای فازینگ در مقیاس بزرگ را با حداقل سربار منابع مدیریت کند.
۳.۳ مثال: آزمایش مدیریت تزریق SQL در SQLite
برای نشان دادن کاربرد KLEE و LibFuzzer، این بخش مثالی را ارائه میدهد که بر آزمایش مدیریت آسیبپذیریهای تزریق SQL (یا SQL Injection) توسط SQLite متمرکز است.
3.3.1 مثال KLEE
با استفاده از KLEE، آزمایشی را برای بررسی آسیبپذیریهای بالقوه تزریق SQL در مدیریت پرسوجوی SQLite راهاندازی میکنیم.
قطعه کد ارائه شده در لیست 3.6، یک آزمایش KLEE را نشان میدهد که برای تشخیص آسیبپذیریهای تزریق SQL در SQLite طراحی شده است. این برنامه شامل هدرهای لازم است و با باز کردن یک پایگاه داده SQLite در حافظه با استفاده از sqlite3_open شروع میشود. اگر پایگاه داده باز نشود، یک پیام خطا چاپ میشود و برنامه خارج میشود. در مرحله بعد، یک آرایه کاراکتری sql با اندازه 512 با استفاده از klee_make_symbolic اعلان و به عنوان نمادین علامتگذاری میشود و به KLEE اجازه میدهد تا با آن به عنوان متغیری رفتار کند که میتواند هر مقداری را در محدوده اندازه خود بپذیرد. سپس آرایه به null ختم میشود تا اطمینان حاصل شود که یک رشته C معتبر تشکیل میدهد.
عبارت نمادین SQL ذخیره شده در sql با استفاده از sqlite3_exec اجرا میشود و نتیجه اجرا برای خطاها بررسی میشود. اگر خطایی رخ دهد، یک پیام خطا چاپ میکند و حافظه پیام خطا را آزاد میکند. اگر SQL با موفقیت اجرا شود، یک پیام موفقیت چاپ میکند. در نهایت، پایگاه داده بسته میشود و برنامه خارج میشود. هنگامی که KLEE این برنامه را اجرا میکند، ورودیهای SQL مختلفی را برای بررسی مسیرهای مختلف اجرا تولید میکند و به طور بالقوه با تجزیه و تحلیل نحوه تعامل sql نمادین با پایگاه داده SQLite، آسیبپذیریهای تزریق SQL را کشف میکند.
3.3.2 مثال LibFuzzer
LibFuzzer برای فازی کردن اجرای پرس و جو SQLite برای کشف آسیبپذیریهای تزریق SQL استفاده میشود. قطعه کد ارائه شده در لیست 3.7 فازی کردن موتور پایگاه داده SQLite را با استفاده از LibFuzzer نشان میدهد. تابع LLVMFuzzerTestOneInput به عنوان نقطه ورود LibFuzzer عمل میکند که کد را با ورودیهای مختلف آزمایش میکند. این تابع با باز کردن یک پایگاه داده SQLite در حافظه با استفاده از sqlite3_open شروع میشود. اگر پایگاه داده باز نشود، تابع مقدار ۰ را برمیگرداند. دادههای ورودی، که به عنوان Data با اندازه Size ارسال میشوند، سپس در یک بافر پویا کپی میشوند و اطمینان حاصل میشود که برای تشکیل یک دستور SQL معتبر، null-terminated هستند. دستور SQL با استفاده از sqlite3_exec اجرا میشود و در صورت بروز خطا، هرگونه پیام خطای حاصل آزاد میشود. در نهایت، بافر اختصاص داده شده آزاد میشود و پایگاه داده بسته میشود. این تنظیمات به LibFuzzer اجازه میدهد تا به طور سیستماتیک ورودیهای مختلف را به موتور SQLite بدهد، استحکام آن را آزمایش کند و با اجرای طیف گستردهای از دستورات SQL، آسیبپذیریها یا خرابیهای احتمالی را کشف کند.
تست KLEE برای SQL injection در SQLite:
#include
int main() {
sqlite3 *db;
char *errMsg = 0;
int rc;
// Open an in-memory database
rc = sqlite3_open(":memory:", &db);
if (rc != SQLITE_OK) {
fprintf(stderr, "Cannot␣open␣database\n");
sqlite3_close(db);
return 0;
}
// Make multiple inputs symbolic to cover more paths
char sql[512];
klee_make_symbolic(sql, sizeof(sql), "sql");
// Ensure input is null-terminated
sql[sizeof(sql) - 1] = ’\0’;
// Execute SQL statement
rc = sqlite3_exec(db, sql, 0, 0, &errMsg);
if (rc != SQLITE_OK) {
fprintf(stderr, "SQL␣error:␣%s\n", errMsg);
sqlite3_free(errMsg);
} else {
printf("Executed␣SQL␣successfully\n");
}
// Clean up
sqlite3_close(db);
return 0;
}
فازینگ SQLite توسط LibFuzzer:
#include
#include
#include
// Fuzzing entry point
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
sqlite3 *db;
char *errMsg = 0;
int rc;
// Open an in-memory database
rc = sqlite3_open(":memory:", &db);
if (rc != SQLITE_OK) {
return 0;
}
// Ensure input is null-terminated
char *sql = (char *)malloc(Size + 1);
if (!sql) {
sqlite3_close(db);
return 0;
}
memcpy(sql, Data, Size);
sql[Size] = ’\0’;
// Execute SQL statement
rc = sqlite3_exec(db, sql, 0, 0, &errMsg);
if (rc != SQLITE_OK) {
sqlite3_free(errMsg);
}
// Clean up
free(sql);
sqlite3_close(db);
return 0;
}
۳.۳.۳ الزامات برای کاربرد مؤثر
برای به حداکثر رساندن پتانسیل KLEE و LibFuzzer در تست SQLite، الزامات زیر در نظر گرفته میشوند:
۱. ابزار دقیق: در حالت ایدهآل، SQLite باید با ابزاری کامپایل شود که بینش دقیقی از وضعیت داخلی و جریان اجرای آن ارائه دهد. این امر میتواند قابلیتهای تحلیل KLEE و LibFuzzer را افزایش دهد.
۲. مهار تست هدفمند: توسعه یک مهار تست که به طور خاص APIها و قابلیتهای مرتبط SQLite را به کار میگیرد، بسیار مهم است. این امر به هدایت ابزارها به سمت مناطقی از کد که احتمال بیشتری برای وجود آسیبپذیری دارند، کمک میکند.
۳. تکرارپذیری: تنظیمات تست باید به طور دقیق مستندسازی شود تا از توانایی تولید مجدد هرگونه خطای کشف شده اطمینان حاصل شود. این امر برای اشکالزدایی، تحلیل و تلاشهای کاهش خطرات احتمالی ضروری است.
۳.۳.۴ معیارهای موفقیت
موفقیت این ارزیابی با موارد زیر تعیین خواهد شد:
۱. تنوع خطا: توانایی KLEE و LibFuzzer در کشف انواع خطاهای منحصر به فرد در SQLite، که قابلیتهای مکمل آنها را برجسته میکند.
۲. عمق خطا: میزانی که اجرای نمادین KLEE بینشهایی در مورد علل ریشهای خطاها ارائه میدهد، فراتر از شناسایی سادهی خرابیهای ایجاد شده توسط LibFuzzer
۳. تولید مورد آزمون: پتانسیل هر دو ابزار برای تولید نمونههای ورودی ملموس که به طور تکرارپذیر خطاهای کشف شده را فعال میکنند و به اشکالزدایی و تجزیه و تحلیل کمک میکنند.
۳.۴ خلاصه
این فصل الزامات تجزیه و تحلیل و کشف آسیبپذیریها در موتور پایگاه داده SQLite را با تمرکز بر نسخه SQLite-amalgamation-3450100 تشریح میکند. این فصل با تأکید بر اهمیت حیاتی یکپارچگی دادهها و امنیت در سیستمهای پایگاه داده، بر ضرورت آزمایش جامع برای جلوگیری از مشکلات یکپارچگی دادهها، انکار سرویس یا اجرای کد از راه دور احتمالی تأکید میکند. دامنه آسیبپذیریهای بررسی شده تعریف شده و الزامات ابزارهای تست مرکزی، KLEE و LibFuzzer، تشریح شدهاند.
KLEE، ابزاری برای تولید خودکار موارد تست و یافتن اشکال، به تفصیل شرح داده شده است، از جمله اجزای کلیدی آن: موتور اجرای نمادین، حلکننده محدودیت، استراتژیهای تولید ورودی و رابط کاربری. موتور اجرای نمادین به دلیل تواناییاش در کاوش مسیرهای برنامه به صورت نمادین، که امکان کشف اشکالات و آسیبپذیریها را با در نظر گرفتن تمام مقادیر ممکن متغیرهای برنامه فراهم میکند، برجسته شده است. مثالهایی، اعلان متغیر نمادین در KLEE و کاربرد آن در یک زمینه SQLite را نشان میدهند و نشان میدهند که چگونه KLEE میتواند پرسوجوهای SQL مختلفی را برای کاوش مسیرهای مختلف اجرا تولید کند. نقش حلکنندهی محدودیت بسیار مهم است، زیرا محدودیتهای منطقی ایجاد شده در طول اجرای نمادین را حل میکند تا امکانسنجی مسیرها را تعیین کند و ورودیهایی تولید کند که این محدودیتها را برآورده کنند. KLEE از استراتژیهای متنوع تولید ورودی، از جمله کاوش تصادفی، کاوش هدایتشده با پوشش و کاوش هدفمند، برای به حداکثر رساندن پوشش مسیر و کشف مؤثر اشکالات بالقوه استفاده میکند.
رابط کاربری KLEE انعطافپذیر و قابل توسعه است و از زبانهای برنامهنویسی مختلف و ادغام با ابزارهای دیگر مانند پاککنندههای LLVM برای تشخیص خطاهای حافظه پشتیبانی میکند. کاربردهای واقعی KLEE، مانند استفاده از آن در تجزیه و تحلیل GNU Coreutils و پروتکلهای شبکه، نشان دادن اثربخشی آن در یافتن اشکالات بحرانی و بهبود قابلیت اطمینان نرمافزار، مورد بحث قرار گرفته است. این فصل همچنین جزئیات LibFuzzer، یک ابزار فازینگ هدایتشده با پوشش که دادههای ورودی را برای به حداکثر رساندن پوشش کد و کشف اشکالات تولید میکند، شرح میدهد. ساختار اساسی تابع هدف LibFuzzer توضیح داده شده است و نشان میدهد که چگونه LibFuzzer به طور سیستماتیک ورودیها را تولید و تغییر میدهد تا مسیرهای مختلف اجرا را بررسی کرده و اشکالات یا خرابیهای احتمالی را شناسایی کند.
فرآیند مقداردهی اولیه LibFuzzer، استراتژیهای جهش، رویکرد فازینگ مبتنی بر بازخورد، ادغام با پاککنندهها، پشتیبانی از فازینگ موازی، مدیریت خرابی، مدیریت پیکره و بهینهسازی عملکرد، همگی شرح داده شدهاند. این فصل با مثالی که کاربرد KLEE و LibFuzzer را در آزمایش مدیریت آسیبپذیریهای تزریق SQL توسط SQLite نشان میدهد، به پایان میرسد و قطعه کدها و توضیحاتی در مورد چگونگی تولید سیستماتیک ورودیها توسط این ابزارها برای بررسی مسیرهای اجرا و شناسایی آسیبپذیریها ارائه میدهد. الزامات کاربرد مؤثر KLEE و LibFuzzer در آزمایش SQLite، از جمله ابزار دقیق عمیق، مهارهای تست هدفمند و قابلیت تکرارپذیری، در نظر گرفته شده است. معیارهای موفقیت برای این ارزیابی شامل تنوع خطا، عمق خطا و تولید موارد آزمایشی است که بر قابلیتهای مکمل KLEE و LibFuzzer در کشف انواع خطاهای منحصر به فرد و ریشهدار در SQLite تأکید دارد.
3.4.1 چرا KLEE؟
KLEE به دلیل تواناییاش در انجام کاوش جامع مسیر از طریق اجرای نمادین انتخاب شد. این قابلیت به ویژه برای شناسایی موارد مرزی و خطاهای منطقی عمیق که ممکن است به راحتی از طریق روشهای تست مرسوم ایجاد نشوند، مفید است.
3.4.2 چرا LibFuzzer؟
لیبفازر به دلیل کاراییاش در تولید و آزمایش حجم زیادی از ورودیهای تصادفی انتخاب شد، که آن را برای کشف آسیبپذیریهای سطحی مانند سرریز بافر و نشت حافظه ایدهآل میکند. ادغام آن با پاککنندهها، توانایی آن را در شناسایی و تشخیص مشکلات مربوط به حافظه افزایش میدهد.
فصل ۴
روششناسیها و تنظیمات تجربی
این فصل به شرح روششناسیها و تنظیمات تجربی مورد استفاده برای ارزیابی اثربخشی KLEE و LibFuzzer در شناسایی آسیبپذیریها در پایگاه کد SQLite- amalgamation-3450100 میپردازد. بخشهای بعدی جزئیات طراحی و پیکربندی مهار تست، ابزارهای تست و رویههای تحلیل خطا را شرح میدهند.
۴.۱ منطق انتخاب ابزار
KLEE و LibFuzzer به دلیل رویکردهای متمایز و مکمل خود برای کشف آسیبپذیری برای این مطالعه انتخاب شدند. اجرای نمادین KLEE به طور سیستماتیک مسیرهای اجرا را برای کشف اشکالات عمیق بررسی میکند، در حالی که فازینگ هدایتشده توسط پوشش LibFuzzer ورودیهای متنوعی را برای تست استرس و استحکام نرمافزار در برابر ورودیهای غیرمنتظره تولید میکند.
۴.۲ پیکربندی تجربی
۱. سختافزار: پردازنده Intel Core i7، رم ۱۶ گیگابایتی.
۲. نرمافزار: اوبونتو ۲۰.۰۴ LTS .
۳. ابزارها: KLEE نسخه ۲.۳.۰ و LibFuzzer نسخه ۱۱.۰.
۴. پیکربندی: هر دو ابزار با تنظیمات پیشفرض برای اولیه پیکربندی شدهاند.
۵. فلگهای کامپایل:
(الف) برای KLEE: clang -I /path/to/klee/include -emit-llvm -c -g your_program.c -o
your_program.bc
klee your_program.bc
(ب) برای libFuzzer: clang -fsanitize=fuzzer -o fuzz_target your_fuzz_target.c
./fuzz_target
۴.۳ نصب و راهاندازی
مراحل دستورالعملهای دقیق در پیوست برای نصب و پیکربندی KLEE و LibFuzzer ارائه شده است تا از یک محیط آزمایش سازگار و تکرارپذیر اطمینان حاصل شود.
۴.۴ پیکربندی و اجرای ابزار
پیکربندیهای KLEE و LibFuzzer برای بهینهسازی عملکرد آنها و بهرهبرداری از قابلیتهای منحصر به فرد تست آنها تنظیم شدهاند. هر ابزار برای کار در شرایطی پیکربندی شده است که اثربخشی آنها را در کشف آسیبپذیریهای بالقوه به حداکثر میرساند.
۴.۴.۱ پیکربندی KLEE
- استراتژی جستجو: KLEE برای اولویتبندی مسیرهای کد جدید و کشف موارد حاشیهای با کاوش سیستماتیک مقادیر ورودی ممکن و حالتهای پایگاه داده پیکربندی شده است. استراتژی جستجو شامل استفاده از کاوش هدایتشده با پوشش و اولویتبندی مسیر برای اطمینان از کاوش تمام مسیرهای اجرایی ممکن است. این بدان معناست که KLEE بر کاوش مسیرهایی در کد که هنوز اجرا نشدهاند (مسیرهای کد جدید) یا کمتر اجرا میشوند، تمرکز دارد. با انجام این کار، احتمال کشف اشکالات و آسیبپذیریهای پنهانی را که ممکن است از طریق روشهای سنتی تست یافت نشوند، به حداکثر میرساند.
- مدل حافظه: مدل حافظه طوری تنظیم شده است که رفتار تخصیص حافظه پویای SQLite را به دقت منعکس کند و به KLEE اجازه میدهد شرایط عملیاتی دنیای واقعی را با دقت بیشتری شبیهسازی کند. مدل حافظه طوری پیکربندی شده است که بتواند آرایههای نمادین بزرگ و ساختارهای داده پیچیده را به طور مؤثر مدیریت کند. این امر برای مدلسازی دقیق نحوه رفتار نرمافزار تحت شرایط مختلف حافظه و کشف مسائل مربوط به حافظه ضروری است.
۴.۴.۲ کاوش هدایت شده با پوشش در KLEE
کاوش هدایتشده با پوشش، تکنیکی است که توسط KLEE برای کاوش کارآمد مسیرهای اجرای یک برنامه استفاده میشود. هدف اصلی، به حداکثر رساندن پوشش کد است، و تضمین میکند که تمام بخشهای کد به جای اجرای مکرر مسیرهای یکسان، آزمایش میشوند. در اینجا توضیح مفصلی از نحوه کار و دلیل مؤثر بودن آن آمده است:
- ابزار دقیق: قبل از اجرا، KLEE کد را برای جمعآوری اطلاعات پوشش ابزار دقیق میکند. این شامل اصلاح برنامه برای ثبت بخشهایی از کد (مثلاً کدام شاخهها، خطوط یا توابع) است که در طول آزمایش اجرا شدهاند.
- اجرا و ردیابی مسیر: همانطور که KLEE برنامه را با ورودیهای نمادین اجرا میکند، مسیرهای طی شده از طریق کد را ردیابی میکند. هر مسیر با توالی شاخهها و شرایطی که در طول اجرا با آنها مواجه میشویم، تعریف میشود.
- ثبت پوشش: KLEE اطلاعات پوشش را ثبت میکند و مشخص میکند که کدام بخشهای کد اجرا شدهاند. این میتواند شامل اطلاعات در سطوح مختلف جزئیات، مانند خطوط اجرا شده، شاخهها یا فراخوانیهای تابع باشد.
- اولویتبندی مسیرهای کشف نشده: KLEE از اطلاعات پوشش جمعآوریشده برای اولویتبندی مسیرهایی که به مناطق کد قبلاً کشف نشده یا کمتر اجرا شده منجر میشوند، استفاده میکند. این تضمین میکند که بخشهای جدید کد آزمایش میشوند، نه اینکه مسیرهای از قبل آزمایش شده را دوباره بررسی کنیم.
- اکتشافات انتخاب مسیر: KLEE از اکتشافات برای انتخاب مسیرهایی که احتمالاً پوشش کد را افزایش میدهند، استفاده میکند. به عنوان مثال، ممکن است مسیرهایی را اولویتبندی کند که: به شاخهها یا عبارات شرطی جدید برسند. خطوط جدید کد را پوشش دهند. فراخوانیهای تابع جدید را اجرا کنند.
- حل محدودیت: KLEE محدودیتهایی را برای هر مسیر ایجاد و حل میکند تا مقادیر ورودی نمادین را که اجرا را در آن مسیر پیش میبرد، تعیین کند. با انجام این کار، به طور سیستماتیک سناریوهای مختلف اجرا را بررسی میکند.
۴.۴.۳ چرا کاوش هدایت شده توسط پوشش مؤثر است؟
کاوش هدایتشده توسط پوشش، تکنیکی است که در تست نرمافزار برای به حداکثر رساندن پوشش کد با تمرکز بر مسیرهای کاوشنشده یا کمتر اجرا شده استفاده میشود. این رویکرد تضمین میکند که تمام بخشهای کد به طور کامل آزمایش شدهاند، که برای شناسایی اشکالات و آسیبپذیریهای پنهان ضروری است. با استفاده کارآمد از rکاوش هدایتشده بر اساس منابع الکترونیکی به کشف مسائلی که ممکن است توسط روشهای سنتی تست از قلم افتاده باشند، کمک میکند.
در زیر دلایل کلیدی موثر بودن این تکنیک آمده است.
- تست جامع: با اولویتبندی مسیرهای کشفنشده، KLEE تضمین میکند که تمام بخشهای کد تست میشوند. این رویکرد جامع به شناسایی اشکالات و آسیب پذیریهایی که ممکن است در مناطقی از کد که به ندرت اجرا میشوند، قرار داشته باشند، کمک میکند.
- کارایی: تمرکز بر مسیرهای جدید یا کمتر اجرا شده، از تست اضافی کدهایی که به خوبی پوشش داده شدهاند، جلوگیری میکند. این استفاده کارآمد از منابع به KLEE اجازه میدهد تا مجموعه وسیعتری از مسیرهای اجرا را در همان مدت زمان بررسی کند.
- کشف باگ: بسیاری از باگها، به ویژه موارد خاص و شرایط نادر، در بخشهایی از کد قرار دارند که مرتباً اجرا نمیشوند. کاوش مبتنی بر پوشش با اطمینان از آزمایش این نواحی، احتمال کشف این مسائل پنهان را افزایش میدهد.
#include
void test_function(int x, int y) {
if (x > 0) {
if (y > 0) {
// Code block A
} else {
// Code block B
}
} else {
if (y > 0) {
// Code block C
} else {
// Code block D
}
}
}
int main() {
int x, y;
klee_make_symbolic(&x, sizeof(x), "x");
klee_make_symbolic(&y, sizeof(y), "y");
test_function(x, y);
return 0;
}
۴.۴.۴ کاوش گام به گام با هدایت پوشش
مراحل زیر توسط KLEE برای اجرای برنامه در ۴.۱ دنبال میشود.
۱. اجرای اولیه: KLEE با اجرای برنامه با مقادیر نمادین برای x و y شروع میکند. فرض کنید ابتدا مسیری را که در آن x > 0 و y > 0 است، کاوش میکند و به بلوک کد A میرسد.
۲. ثبت پوشش: KLEE ثبت میکند که بلوک کد A اجرا شده است. این نشان میدهد که شاخههای منتهی به بلوکهای کد B، C و D کاوش نشدهاند.
۳. اولویتبندی مسیر: KLEE مسیرهای کاوشی را که هنوز پوشش داده نشدهاند، اولویتبندی میکند. ممکن است در مرحله بعد x > 0 و y <= 0 را امتحان کند که منجر به بلوک کد B میشود و این پوشش را ثبت میکند.
۴. ادامه کاوش: در مرحله بعد، KLEE x <= 0 و y > 0 را بررسی میکند و بلوک کد C را پوشش میدهد. در نهایت، x <= 0 و y <= 0 را بررسی میکند و بلوک کد D را پوشش میدهد.
۵. نتیجه: با استفاده از کاوش هدایتشده توسط پوشش، KLEE تضمین میکند که هر چهار بلوک کد (A، B، C و D) آزمایش شدهاند. اگر هرگونه اشکال یا آسیبپذیری در این بلوکها وجود داشته باشد، KLEE با آزمایش سیستماتیک هر مسیر ممکن، احتمال یافتن آنها را افزایش میدهد.
به طور خلاصه، کاوش هدایتشده توسط پوشش در KLEE تضمین میکند که کل پایگاه کد با اولویتبندی مسیرهایی که منجر به مناطق کد جدید یا کمتر اجرا شده میشوند، آزمایش میشود. این رویکرد سیستماتیک برای کشف اشکالات پنهان و اطمینان از آزمایش جامع نرمافزار ضروری است.
۴.۴.۵ پیکربندی LibFuzzer
LibFuzzer یک ابزار فازینگ هدایتشده توسط پوشش است که برای به حداکثر رساندن پوشش کد و کشف آسیبپذیریهای نرمافزار طراحی شده است. پیکربندی مؤثر LibFuzzer برای بهینهسازی عملکرد آن و تضمین آزمایش جامع ضروری است. این بخش به جزئیات پیکربندیها و استراتژیهای کلیدی مورد استفاده برای افزایش اثربخشی LibFuzzer در تشخیص آسیبپذیریها میپردازد.
- پاک کننده (Sanitizer)ها: Libfuzzer با AddressSanitizer ادغام شده است تا مشکلات خرابی حافظه را که میتواند منجر به آسیبپذیریهای امنیتی شود، شناسایی کند. AddressSanitizer تشخیص دقیقی از خطاهای حافظه، مانند سرریز بافر و خطاهای استفاده پس از آزادسازی، ارائه میدهد. این ادغام برای شناسایی و تشخیص اشکالات ظریف مربوط به حافظه که میتوانند امنیت نرمافزار را به خطر بیندازند، بسیار مهم است.
- استراتژی اجرا: Libfuzzer طوری پیکربندی شده است که به طور مداوم با ورودیهای تنظیمشده پویا بر اساس معیارهای پوشش کد اجرا شود و مسیرهای ناشناخته و نقاط شکست بالقوه را هدف قرار دهد. LibFuzzer از بازخورد پوشش کد برای تغییر ورودیها به گونهای استفاده میکند که کشف مسیرهای اجرایی جدید را به حداکثر برساند. این رویکرد برای اطمینان از اینکه فازر میتواند تا حد امکان سناریوهای مختلف اجرا را بررسی کند، ضروری است.
۴.۴.۶ ادغام پاک کنندهها (Integration of Sanitizers)
در طول فازر، LibFuzzer برنامه هدف را با ورودیهای مختلف اجرا میکند در حالی که Address-Sanitizer عملیات حافظه را رصد میکند. اگر AddressSanitizer خطای حافظه را تشخیص دهد، اجرا را متوقف کرده و گزارش تشخیصی دقیقی ارائه میدهد. این گزارش شامل موارد زیر است:
- نوع خطای حافظه.
- محل دقیق خطا در کد که در آن خطا رخ داده است.
- ردیابی پشته که منجر به خطا شده است.
- زمینه اضافی برای درک شرایطی که خطا تحت آن ایجاد شده است.
۴.۵ پیادهسازی هارنس آزمون (Test Harness)
هارنس تست (Test Harness) یا هارنس آزمون یک جزء حیاتی در تست نرمافزار است زیرا محیطی را برای اجرای تستها تنظیم میکند، ورودیها را مدیریت میکند و تضمین میکند که نتایج به طور دقیق ثبت میشوند.
برای این تحقیق، هارنس تست برای تسهیل اجرای تستها با استفاده از KLEE و LibFuzzer در کتابخانه SQLite طراحی شده است. مراحل تشکیل هارنس تست به شرح زیر است:
قطعه کد ارائه شده در لیست ۴.۲ یک Test Harness است که برای استفاده از KLEE، یک موتور اجرای نمادین، برای آزمایش عملیات SQLite با ورودیهای نمادین طراحی شده است. برنامه با گنجاندن هدرهای لازم برای SQLite، توابع ورودی/خروجی استاندارد و KLEE شروع میشود.
در تابع main، اشارهگرهایی برای پایگاه داده SQLite و یک پیام خطا، همراه با یک عدد صحیح برای کدهای برگشتی، تعریف میکند. سپس برنامه سعی میکند با استفاده از sqlite3_open یک پایگاه داده SQLite در حافظه را باز کند. اگر پایگاه داده باز نشود، یک پیام خطا چاپ میکند و خارج میشود. در مرحله بعد، یک آرایه کاراکتری sql با اندازه ۲۵۶ برای نگهداری یک پرسوجوی SQL تعریف میکند و از klee_make_symbolic برای علامتگذاری آرایه به عنوان نمادین استفاده میکند و به KLEE اجازه میدهد تا با آن به عنوان متغیری رفتار کند که میتواند هر مقداری را در محدودیتهای اندازه خود بپذیرد.
آرایه به null-terminated ختم میشود تا اطمینان حاصل شود که یک رشته C معتبر تشکیل میدهد. سپس برنامه با استفاده از sqlite3_exec، پرسوجوی نمادین SQL را اجرا میکند، خطاها را بررسی میکند و بر اساس نتیجه اجرا، پیام مناسبی را چاپ میکند. اگر خطایی رخ دهد، عبارت “SQL error” را چاپ میکند و حافظه پیام خطا را آزاد میکند؛ در غیر این صورت، عبارت Executed SQL successfully را چاپ میکند. در نهایت، برنامه پایگاه داده SQLite را میبندد و خارج میشود. هنگامی که با KLEE اجرا میشود، این مهار به طور سیستماتیک با تولید ورودیهای مختلف برای آرایه نمادین sql، پرسوجوهای مختلف SQL را بررسی میکند، با هدف به حداکثر رساندن پوشش کد و شناسایی اشکالات یا آسیبپذیریهای احتمالی در مدیریت پرسوجوی SQLite. قطعه کد ارائه شده در 4.3 یک مهار آزمایشی است که برای استفاده با LibFuzzer برای آزمایش عملیات SQLite با ورودیهای مختلف طراحی شده است. برنامه با گنجاندن هدرهای لازم برای مدیریت انواع اعداد صحیح استاندارد، تعاریف اندازه، عملیات حافظه، توابع ورودی/خروجی و توابع پایگاه داده SQLite آغاز میشود.
هارنس (Harness) آزمایشی KLEE:
#include
#include
#include
int main() {
sqlite3 *db;
char *errMsg = 0;
int rc;
// Open an in-memory database
rc = sqlite3_open(":memory:", &db);
if (rc != SQLITE_OK) {
fprintf(stderr, "Cannot␣open␣database\n");
sqlite3_close(db);
return 0;
}
// Make the input symbolic
char sql[256];
klee_make_symbolic(sql, sizeof(sql), "sql");
// Ensure input is null-terminated
sql[sizeof(sql) - 1] = ’\0’;
// Execute SQL statement
rc = sqlite3_exec(db, sql, 0, 0, &errMsg);
if (rc != SQLITE_OK) {
fprintf(stderr, "SQL␣error\n");
sqlite3_free(errMsg);
} else {
printf("Executed␣SQL␣successfully\n");
}
// Clean up
sqlite3_close(db);
return 0;
}
هارنس (Harness) آزمایشی LibFuzzer:
#include
#include
#include
// Main fuzzer function
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size == 0) return 0;
sqlite3 *db;
char *errMsg = 0;
int rc;
// Open an in-memory database
rc = sqlite3_open(":memory:", &db);
if (rc != SQLITE_OK) {
fprintf(stderr, "Cannot␣open␣database\n");
sqlite3_close(db);
return 0;
}
// Ensure input is null-terminated
char *sql = (char *)malloc(size + 1);
memcpy(sql, data, size);
sql[size] = ’\0’;
// Execute SQL statement
rc = sqlite3_exec(db, sql, 0, 0, &errMsg);
if (rc != SQLITE_OK) {
fprintf(stderr, "SQL␣error\n");
sqlite3_free(errMsg);
} else {
printf("Executed␣SQL␣successfully\n");
}
// Clean up
free(sql);
sqlite3_close(db);
return 0;
}
LLVMFuzzerTestOneInput تابع به عنوان نقطه ورود برای LibFuzzer عمل میکند و یک اشارهگر به دادههای ورودی و اندازه آن را به عنوان پارامتر میگیرد. این تابع ابتدا بررسی میکند که آیا اندازه ورودی صفر است یا خیر و در صورت صفر بودن، فوراً آن را برمیگرداند. سپس سعی میکند یک پایگاه داده SQLite در حافظه را با استفاده از sqlite3_open باز کند و اگر این عملیات با شکست مواجه شود، یک پیام خطا چاپ میکند و خارج میشود. در مرحله بعد، حافظه را برای پرسوجوی SQL اختصاص میدهد و با کپی کردن دادهها و افزودن یک کاراکتر تهی، اطمینان حاصل میکند که دادههای ورودی به null-terminated پایان یافته با null ختم میشوند. سپس پرسوجوی SQL با استفاده از sqlite3_exec اجرا میشود و در صورت بروز هرگونه خطا، یک پیام خطا چاپ میشود و حافظه پیام خطا آزاد میشود. اگر پرسوجو با موفقیت اجرا شود، یک پیام موفقیت چاپ میشود. در نهایت، تابع حافظه اختصاص داده شده برای پرسوجوی SQL را آزاد میکند و قبل از بازگشت، پایگاه داده SQLite را میبندد. این مهار به LibFuzzer اجازه میدهد تا طیف وسیعی از ورودیها را به طور سیستماتیک تولید و آزمایش کند، با هدف شناسایی و تشخیص اشکالات یا آسیبپذیریها در مکانیسمهای مدیریت پرسوجوی SQLite. خلاصهای از ایجاد مهار تست در ادامه آمده است.
- مقداردهی اولیه پایگاه داده SQLite:
(الف) راهاندازی: مهار، یک پایگاه داده SQLite درون حافظهای را مقداردهی اولیه میکند.
(ب) دلیل: یک پایگاه داده درون حافظهای، یک محیط کنترلشده و ایزوله را فراهم میکند که برای آزمایش مکرر بدون سربار ورودی/خروجی دیسک ایدهآل است.
- آمادهسازی ورودی:
(الف) KLEE: ورودیها با استفاده از klee_make_symbolic نمادین میشوند و به KLEE اجازه میدهند تا با در نظر گرفتن ورودیها به عنوان متغیرهای نمادین، تمام مسیرهای اجرای ممکن را بررسی کند.
(ب) LibFuzzer: ورودیها تصادفی و جهشیافته میشوند تا طیف وسیعی از ورودیهای بالقوه را پوشش دهند، استفاده در دنیای واقعی را شبیهسازی کرده و آسیبپذیریهایی را که از دادههای غیرمنتظره ناشی میشوند، کشف کنند.
۳. اجرای SQL:
(الف) مرحله مشترک: هر دو مهار شامل کدی برای اجرای دستورات SQL در برابر پایگاه داده SQLite و بررسی خطاها هستند.
(ب) دلیل: این مرحله برای راهاندازی مسیرهای مختلف کد در SQLite بسیار مهم است و تضمین میکند که منطق داخلی پایگاه داده به طور کامل آزمایش شده است.
۴. مدیریت خطا و پاکسازی منابع:
(الف) راهاندازی: مهار، پیامهای خطا را ضبط کرده و منابعی مانند حافظه و اتصالات پایگاه داده را پس از هر آزمایش پاکسازی میکند.
(ب) دلیل: مدیریت صحیح خطا تضمین میکند که محیط آزمایش در چندین اجرا پایدار بماند و پاکسازی منابع از نشت حافظه و سایر مسائلی که میتوانند نتایج را منحرف کنند، جلوگیری میکند.
۴.۶ رویههای تحلیل خطا
تحلیل خطا یک جزء حیاتی از فرآیند ارزیابی آسیبپذیری است. رویههای تحلیل خطاهای شناسایی شده توسط KLEE و LibFuzzer به گونهای طراحی شدهاند که بینش دقیقی در مورد ماهیت و تأثیر هر آسیبپذیری شناسایی شده ارائه دهند.
۴.۶.۱ تحلیل خطای KLEE
KLEE گزارشهای دقیقی در مورد هر مسیر اجرا، از جمله مسیرهایی که منجر به خطا میشوند، ارائه میدهد. تحلیل خطا شامل مراحل زیر است:
۱. کاوش مسیر: مسیرهای کاوش شده توسط KLEE را بررسی کنید تا مسیرهایی را که منجر به خطا میشوند شناسایی کنید. این کار برای درک چگونگی تأثیر مقادیر و شرایط ورودی مختلف بر اجرای برنامه ضروری است.
۲. انواع خطا: خطاها را بر اساس نوع آنها، مانند ارجاعات اشارهگر تهی، دسترسیهای خارج از محدوده و خطاهای ادعا، دستهبندی کنید. دستهبندی خطاها به اولویتبندی رفع مشکلات و درک علل رایج آسیبپذیریها کمک میکند.
۳. اشکالزدایی: از اطلاعات اشکالزدایی KLEE برای ردیابی مسیر اجرا و درک علت اصلی هر خطا استفاده کنید. این مرحله برای تشخیص دقیق و رفع مشکلات اساسی بسیار مهم است.
۴.۶.۲ تحلیل خطای LibFuzzer
LibFuzzer گزارشهای خرابی تولید میکند و دادههای ورودی را برای شناسایی آسیبپذیریها پاکسازی میکند. تحلیل خطا شامل مراحل زیر است:
۱. تحلیل خرابی: گزارشهای خرابی تولید شده توسط LibFuzzer را بررسی کنید تا ورودیهایی را که باعث خرابی برنامه میشوند شناسایی کنید. درک شرایطی که منجر به خرابی میشوند برای بهبود استحکام نرمافزار ضروری است.
۲. گزارشهای پاکسازی: از گزارشهای AddressSanitizer برای درک مشکلات خرابی حافظه، مانند سرریز بافر و خطاهای استفاده پس از آزادسازی استفاده کنید. این گزارشها اطلاعات دقیقی در مورد خطاهای حافظه که میتوانند منجر به آسیبپذیریهای امنیتی شوند، ارائه میدهند.
۳. کمینهسازی ورودی: دادههای ورودی را کمینه کنید تا توالی دقیق بایتهایی که باعث آسیبپذیری میشوند، جدا شوند. این به تعیین علت اصلی مشکل و توسعه راهحلهای هدفمند کمک میکند. ۴.۷ چرا این رویکرد برای SQLite انتخاب شد
۴.۷.۱ تست جامع
توانایی KLEE در کاوش سیستماتیک تمام مسیرهای اجرای ممکن، تضمین میکند که حتی مسیرهای کدی که به ندرت اجرا میشوند نیز آزمایش شوند. این امر به ویژه برای سیستم پیچیدهای مانند SQLite که ممکن است موارد مرزی پیچیده و شرایط منطقی داشته باشد، مهم است. رویکرد جهش و پوشش هدایتشده LibFuzzer امکان آزمایش گسترده تجزیهکننده SQL و موتور اجرا را با مجموعهای متنوع از ورودیها فراهم میکند و آسیبپذیریهایی را که ممکن است از دادههای غیرمنتظره یا ناقص ناشی شوند، کشف میکند.
۴.۷.۲ ارتباط عملی
SQLite یک پایگاه داده تعبیهشده پرکاربرد است که آن را به کاندیدای ایدهآلی برای نشان دادن کاربرد عملی ترکیب اجرای نمادین و … تبدیل میکند. و فازینگ. تضمین امنیت و قابلیت اطمینان SQLite پیامدهای قابل توجهی برای بسیاری از برنامههایی که به آن وابسته هستند، دارد. پیچیدگی کدبیس SQLite یک سناریوی تست چالشبرانگیز اما واقعبینانه را فراهم میکند که نقاط قوت KLEE و LibFuzzer را در مدیریت سیستمهای نرمافزاری پیچیده برجسته میکند.
4.7.3 استفاده کارآمد از منابع
استفاده از یک پایگاه داده درون حافظهای، اجرای سریع و جداسازی را تضمین میکند که برای تست مکرر و مدیریت منابع بسیار مهم است. هر دو ابزار تشخیص و گزارش خودکار خطاها را ارائه میدهند و شناسایی و تجزیه و تحلیل کارآمد آسیبپذیریها را تسهیل میکنند.
4.8 چالشها و راهکارهای کاهش
در طول راهاندازی و اجرای آزمایشها، با چالشهای متعددی روبرو شدیم.
پرداختن به این چالشها برای اطمینان از قابلیت اطمینان و اعتبار نتایج ضروری بود.
4.8.1 محدودیتهای حافظه
هم KLEE و هم LibFuzzer به دلیل پیچیدگی کدبیس SQLite با محدودیتهای حافظه مواجه شدند. برای کاهش این مشکل، محدودیتهای حافظه با دقت مدیریت شدند و اجرای تستها برای مدیریت کارآمد آرایههای نمادین بزرگ و ورودیها بهینه شدند.
۴.۸.۲ مدلسازی تابع خارجی
KLEE با مدلسازی توابع خارجی مانند عملیات چندرشتهای مشکل داشت.
این مشکل با اصلاح مهار تست و مدلسازی انتخابی توابع خارجی حیاتی برای بهبود اکتشاف مسیر و دقت، کاهش یافت.
۴.۸.۳ تنگناهای عملکرد
نیازهای محاسباتی بالای اجرای نمادین و فازینگ، نیازمند استراتژیهای بهینهسازی بود. برای KLEE، هرس مسیر و اجرای نمادین انتخابی به کار گرفته شد، در حالی که برای LibFuzzer، اجرای موازی و استراتژیهای جهش ورودی کارآمد استفاده شد.
۴.۹ معیارهای ارزیابی
اثربخشی KLEE و LibFuzzer با استفاده از معیارهای زیر ارزیابی شد:
- پوشش کد: میزان کاوش ابزارها در پایگاه کد، که با درصد مسیرهای کد اجرا شده اندازهگیری میشود.
- تشخیص آسیبپذیری: تعداد و شدت آسیبپذیریهای شناسایی شده توسط هر ابزار.
- سرعت اجرا: نرخی که هر ابزار ورودیها را پردازش کرده و مسیرهای اجرا را کاوش کرده است.
- میزان استفاده از منابع: میزان استفاده از حافظه و پردازنده هر ابزار در حین اجرا.
۴.۱۰ خلاصه
این فصل به تفصیل روشها و تنظیمات آزمایشی مورد استفاده برای ارزیابی اثربخشی KLEE و LibFuzzer در شناسایی آسیبپذیریها در پایگاه کد SQLite- amalgation-3450100 را شرح میدهد. این فصل با منطق انتخاب KLEE و Lib-Fuzzer شروع میشود و بر رویکردهای مکمل آنها برای کشف آسیبپذیری تأکید دارد: کاوش سیستماتیک مسیر KLEE از طریق اجرای نمادین و فازینگ هدایتشده توسط پوشش LibFuzzer برای تست استرس نرمافزار با ورودیهای متنوع. پیکربندی آزمایشی شامل تنظیمات سختافزاری (پردازنده Intel Core i7، ۱۶ گیگابایت رم)، محیط نرمافزار (اوبونتو ۲۰.۰۴ LTS) و نسخههای ابزار (KLEE 2.3.0 و LibFuzzer 11.0) است. مراحل نصب و راهاندازی دقیق برای اطمینان از یک محیط تست سازگار و تکرارپذیر ارائه شده است.
این فصل، پیکربندیهای خاص KLEE و LibFuzzer را برای بهینهسازی عملکرد آنها تشریح میکند. KLEE برای اولویتبندی مسیرهای کد جدید و کشف موارد حاشیهای از طریق کاوش هدایتشده توسط پوشش و اولویتبندی مسیر، شبیهسازی شرایط دنیای واقعی با یک مدل حافظه تنظیمشده، پیکربندی شده است. کاوش هدایتشده توسط پوشش به تفصیل توضیح داده شده است و اثربخشی آن در تضمین تست جامع، بهبود کارایی و افزایش احتمال کشف اشکال برجسته شده است.
پیکربندی LibFuzzer شامل ادغام با AddressSanitizer برای تشخیص مشکلات خرابی حافظه، ارائه تشخیص دقیق خطاهای حافظه مانند سرریز بافر و خطاهای استفاده پس از آزادسازی است. LibFuzzer به طور مداوم با ورودیهای تنظیمشده پویا بر اساس معیارهای پوشش کد اجرا میشود و مسیرهای کشفنشده و نقاط شکست بالقوه را هدف قرار میدهد. این فصل همچنین شامل جزئیات پیادهسازی مهارهای تست برای KLEE و LibFuzzer است. ابزار تست KLEE از ورودیهای نمادین برای کاوش سیستماتیک پرسوجوهای مختلف SQL استفاده میکند، در حالی که ابزار تست LibFuzzer طیف گستردهای از ورودیها را برای شناسایی اشکالات در مکانیسمهای مدیریت پرسوجوی SQLite تولید و آزمایش میکند.
رویههای تحلیل خطا برای هر دو ابزار شرح داده شده است، با تمرکز بر کاوش مسیر، دستهبندی خطا و اشکالزدایی برای KLEE، و تحلیل خرابی، گزارشهای پاکسازی و کمینهسازی ورودی برای LibFuzzer. منطق انتخاب این رویکرد برای SQLite مورد بحث قرار گرفته است، با تأکید بر آزمایش جامع، ارتباط عملی و استفاده کارآمد از منابع. این رویکرد، آزمایش کامل پایگاه کد پیچیده SQLite را تضمین میکند و آن را برای نشان دادن نقاط قوت هر دو ابزار در مدیریت سیستمهای نرمافزاری پیچیده ایدهآل میسازد. این بخش با بحثی در مورد چالشهای پیش آمده در طول آزمایشها و استراتژیهای مورد استفاده برای کاهش آنها، از جمله مدیریت محدودیتهای حافظه، مدلسازی توابع خارجی و پرداختن به گلوگاههای عملکرد، به پایان میرسد. معیارهای ارزیابی برای اثربخشی KLEE و LibFuzzer نیز ارائه شده است، از جمله پوشش ode، تشخیص آسیبپذیری، سرعت اجرا و میزان استفاده از منابع.
فصل ۵
در این فصل، نتایج آزمایش با استفاده از دو ابزار پیشرفته، KLEE و LibFuzzer، برای شناسایی آسیبپذیریها در نرمافزارها ارائه شده است. هر دو ابزار رویکردهای منحصر به فردی برای آزمایش نرمافزار ارائه میدهند. با استفاده از این تکنیکهای مکمل، این پایاننامه قصد دارد به پوشش جامعی دست یابد و آسیبپذیریهای آشکار و پنهان در کد را کشف کند.
۵.۱ انواع آسیبپذیریهای آزمایش شده
این بخش به بررسی برخی از آسیبپذیریهای رایج آزمایششده در برنامههای نرمافزاری میپردازد. این آزمایش ۳ بار انجام شد تا ثبات نتایج بهدستآمده در این فصل بررسی شود.
۵.۱.۱ سرریز بافر (Buffer Overflow)
آسیبپذیریهای سرریز بافر زمانی رخ میدهند که یک برنامه دادههای بیشتری را در یک بافر مینویسد که میتواند آن را نگه دارد و بهطور بالقوه منجر به فساد دادهها، خرابیها یا سوءاستفادههای امنیتی میشود. شناسایی و کاهش این نوع آسیبپذیری بسیار مهم است. فهرست ۵.۱ و ۵.۲ کدی را که برای این مثال آزمایش کردهایم نشان میدهد. توجه داشته باشید که KLEE برای عملکرد مورد آزمایش نیاز به تغییراتی دارد و هر دو نیاز به مهار تست دارند.
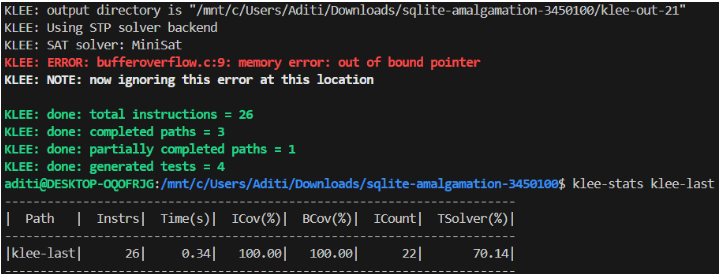
#include
#include
void buffer_overflow() {
char buffer[10];
int index;
klee_make_symbolic(&index, sizeof(index), "index");
if (index >= 0 && index < 20) { // Intentional vulnerability
buffer[index] = ’A’; // Possible overflow
}
}
int main() {
buffer_overflow();
return 0;
}
۵.۱.۱.۱ مثال KLEE
پوشش:
- پوشش دستورالعمل: به ۱۰۰٪ پوشش دستورالعمل و شاخه دست یافت، که نشان میدهد تمام مسیرهای موجود در کد را به طور کامل کاوش کرده است.
۲. تشخیص خطا:
- با موفقیت یک خطای حافظه (اشارهگر خارج از محدوده) را در تابع buffer_overflow شناسایی کرد.
- موارد تست دقیق را در فایلهای *.ktest، با مقادیر نمادین که منجر به خطاهای شناسایی شده میشوند، ارائه داد.
۳. آمار اجرا
- کل دستورالعملها: ۲۶
- مسیرهای تکمیل شده: ۳
- مسیرهای نیمه تکمیل شده: ۱
- تستهای تولید شده: ۴
- پوشش دستورالعمل (ICov%): ۱۰۰.۰۰٪
- پوشش شاخه (BCov%): ۱۰۰.۰۰٪
- تعداد دستورالعمل (ICount): ۲۲
۴. میزان استفاده از حلکننده (Solver Utilization): زمان صرف شده در حلکننده: ۷۰.۱۴٪
۵.۱.۱.۲ مثال LibFuzzer
#include
#include
void buffer_overflow(int index) {
char buffer[10];
if (index >= 0 && index < 20) { // Intentional vulnerability
buffer[index] = ’A’; // Possible overflow
}
}
// Entry point for LibFuzzer.
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size < sizeof(int)) {
return 0;
}
int index;
memcpy(&index, data, sizeof(index));
buffer_overflow(index);
return 0;
}
۱. کارایی فازینگ:
- میلیونها تکرار را با ورودیهای مختلف تولید شده بر اساس مجموعه داده اولیه، به طور مؤثر اجرا کرد.
۲. پوشش:
- در حالی که پوشش دستورالعمل به صراحت نشان داده نشده است، گزارش نشان میدهد که ورودیهای متنوعی بررسی شدهاند.
۳. تشخیص خطا:
- تشخیص خطای قطعهبندی ناشی از سرریز بافر.
۴. بازخورد بلادرنگ:
- گزارش فوری خرابی با ردیابی پشته و جزئیات خطا.
۵.۱.۲ ارجاع به اشارهگر تهی (Null Pointer Dereference)
آسیبپذیریهای ارجاع به اشارهگر تهی زمانی رخ میدهند که یک برنامه سعی میکند از طریق یک اشارهگر تهی، مکانی از حافظه را بخواند یا بنویسد که منجر به خرابی یا رفتار نامشخص میشود.
تشخیص چنین آسیبپذیریهایی برای تضمین پایداری و امنیت برنامه بسیار مهم است. لیست ۵.۳ و ۵.۴ کدی را که برای این مثال آزمایش کردیم نشان میدهد. مثال KLEE از اجرای نمادین برای بررسی تمام مقادیر ممکن برای متغیر «شرط» استفاده میکند، در حالی که
مثال LibFuzzer از فازینگ برای تولید ورودیهای مختلف و آزمایش ارجاع مجدد به اشارهگر تهی استفاده میکند.
5.1.2.1 مثال KLEE
#include
#include
void null_pointer_dereference() {
int *ptr = NULL;
int condition;
klee_make_symbolic(&condition, sizeof(condition), "condition");
if (condition) {
*ptr = 10; // Dereference of NULL pointer
}
}
int main() {
null_pointer_dereference();
return 0;
}
۱. پوشش:
- پوشش دستورالعمل (ICov): ۹۴.۴۴٪
- پوشش شعبه (BCov): ۱۰۰٪
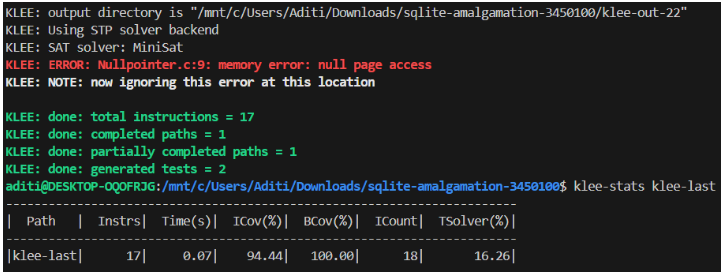
۲. تشخیص خطا:
- خطای ارجاع به اشارهگر تهی (خطای حافظه: دسترسی به صفحه تهی) شناسایی شد.
- خطا با شماره خط و توضیحات دقیق ثبت شد.
۳. آمار اجرا:
- کل دستورالعملها: ۱۷
- مسیرهای تکمیلشده: ۱
- مسیرهای نیمهتکمیلشده: ۱
- آزمایشهای تولیدشده: ۲
۴. میزان استفاده از حلکننده:
- زمان صرفشده در حلکننده: ۱۸.۹۷٪
۵.۱.۲.۲ مثال LibFuzzer
۱. کارایی فازینگ:
- میلیونها تکرار را با ورودیهای مختلف تولیدشده بر اساس مجموعه داده اولیه، بهطور مؤثر اجرا کرد.
۲. پوشش:
- در حالی که پوشش دستورالعمل به صراحت نشان داده نشده است، گزارش نشان میدهد که ورودیهای متنوعی بررسی شدهاند.
۳. تشخیص خطا:
- خطای قطعهبندی ناشی از ارجاع به اشارهگر تهی شناسایی شد
#include
#include
void null_pointer_dereference(int condition) {
int *ptr = NULL;
if (condition) {
*ptr = 10; // Dereference of NULL pointer
}
}
// Entry point for LibFuzzer.
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size < sizeof(int)) {
return 0;
}
int condition = *((const int*)data);
null_pointer_dereference(condition);
return 0;
}
۴. بازخورد بلادرنگ:
- گزارش فوری خرابی با ردیابی پشته و جزئیات خطا.
- ردیابی پشته دقیقی ارائه شده است که محل دقیق خطا را مشخص میکند.
۵.۱.۳ استفاده پس از آزادسازی (Use-After-Free)
آسیبپذیریهای استفاده پس از آزادسازی زمانی رخ میدهند که یک برنامه پس از آزادسازی، همچنان از یک اشارهگر استفاده میکند و به طور بالقوه منجر به تخریب حافظه، خرابی یا سوءاستفادههای امنیتی میشود. فهرست ۵.۵ و ۵.۶ کدی را که برای این مثال آزمایش کردیم نشان میدهد. تشخیص چنین آسیبپذیریهایی برای حفظ پایداری و امنیت برنامه بسیار مهم است. هم KLEE و هم LibFuzzer برای شناسایی و گزارش خطاهای استفاده پس از آزادسازی استفاده شدند و بینشهای ارزشمندی در مورد نقاط قوت مربوطه خود در کشف این مسائل مهم ارائه دادند.
۵.۱.۳.۱ مثال KLEE
#include
#include
void use_after_free() {
int ptr = (int) malloc(sizeof(int));
*ptr = 42;
free(ptr);
int condition;
klee_make_symbolic(&condition, sizeof(condition), "condition");
if (condition) {
*ptr = 10; // Use-after-free
}
}
int main() {
use_after_free();
return 0;
}
۱. پوشش:
- پوشش دستورالعمل (ICov): ۹۶.۰۰٪
- پوشش شعبه (BCov): ۱۰۰.۰۰٪
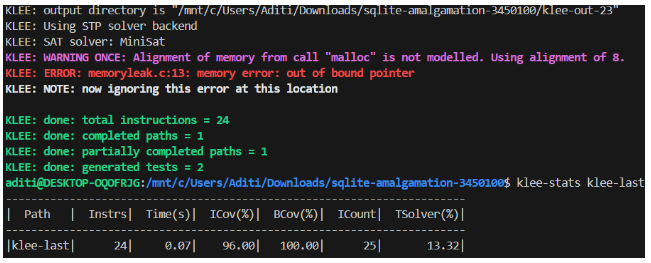
۲. تشخیص خطا:
- یک خطای استفاده پس از آزادسازی (خطای حافظه: اشارهگر خارج از محدوده) شناسایی شد.
- خطا با شماره خط و توضیحات دقیق ثبت شد.
۳. آمار اجرا:
- کل دستورالعملها: ۲۴
- مسیرهای تکمیلشده: ۱
- مسیرهای نیمهتکمیلشده: ۱
- آزمایشهای تولیدشده: ۲
۴. میزان استفاده از حلکننده:
- زمان صرفشده در حلکننده: ۷.۴۷٪
۵.۱.۳.۲ مثال LibFuzzer
۱. کارایی فازینگ:
- میلیونها تکرار را با ورودیهای مختلف تولیدشده بر اساس مجموعه داده اولیه، بهطور مؤثر اجرا کرد.
۲. پوشش:
- در حالی که پوشش دستورالعمل به صراحت نشان داده نشده است، گزارش نشان میدهد که ورودیهای متنوعی بررسی شدهاند.
۳. تشخیص خطا:
- تشخیص خطای قطعهبندی ناشی از خطای استفاده پس از آزادسازی
void use_after_free(int condition) {
int *ptr = (int*) malloc(sizeof(int));
*ptr = 42;
free(ptr);
if (condition) {
*ptr = 10; // Use-after-free
}
}
// The LLVMFuzzerTestOneInput function is the entry point for LibFuzzer.
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size < sizeof(int)) {
return 0;
}
int condition = *((const int*)data);
use_after_free(condition);
return 0;
}
۴. بازخورد بلادرنگ:
- گزارش فوری خرابی با ردیابی پشته و جزئیات خطا.
۵.۱.۴ آسیبپذیری رشته قالببندی (Format String Vulnerability)
آسیبپذیریهای رشته قالببندی زمانی رخ میدهند که یک برنامه به طور نادرست دادههای ورودی را در توابع قالببندی مانند «printf»، «snprintf» و موارد دیگر مدیریت کند. این آسیبپذیریها میتوانند منجر به مشکلات امنیتی جدی مانند اجرای کد دلخواه، خرابی دادهها و خرابیهای برنامه شوند. تشخیص و کاهش آسیبپذیریهای رشته قالببندی برای حفظ امنیت و پایداری برنامههای نرمافزاری بسیار مهم است. این بخش به بررسی نحوه آزمایش آسیبپذیریهای رشته قالببندی با استفاده از KLEE و LibFuzzer میپردازد و روششناسیها و اثربخشی مربوطه آنها را برجسته میکند. درک تفاوتها و نقاط قوت مکمل KLEE و LibFuzzer بینشهای ارزشمندی در مورد استحکام رویکردهای تست نرمافزار ارائه میدهد. فهرست ۵.۷ و ۵.۸ کدی را که برای این مثال آزمایش شده است نشان میدهد.
۵.۱.۴.۱ KLEE
#include
#include
void format_string_vulnerability(char *input) {
char buffer[100];
snprintf(buffer, sizeof(buffer), input); // Format string vulnerability
}
int main() {
char input[100];
klee_make_symbolic(input, sizeof(input), "input");
format_string_vulnerability(input);
return 0;
}
۱. پوشش:
- پوشش دستورالعمل (ICov): ۹۴.۴۴٪
- پوشش شاخه (BCov): ۱۰۰.۰۰٪
۲. تشخیص خطا:
- KLEE خطاهای حافظه خارج از محدوده را در تابع snprintf شناسایی کرد.
- خطاها با شماره خط و توضیحات دقیق ثبت شدند.
۳. آمار اجرا:
- کل دستورالعملها: ۶۷۸۶۳۱۳
- مسیرهای تکمیل شده: ۲۱۸۹
- مسیرهای نیمه تکمیل شده: ۱۵۹۵۷۳
- تستهای تولید شده: ۱۶۱۷۳۱
۴. میزان استفاده از حلکننده:
- زمان صرف شده در حلکننده به دلیل کاوش گسترده مسیر، قابل توجه بود.
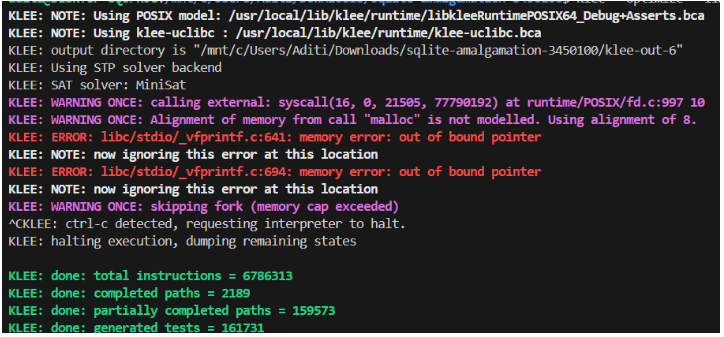
5.1.4.2 LibFuzzer
۱. کارایی فازینگ:
- به طور موثر بیش از ده هزار تکرار را با ورودیهای مختلف تولید شده بر اساس مجموعه داده اولیه اجرا کرد.
۲. پوشش:
- گزارش نشان میدهد که ورودیهای متنوع بررسی شدهاند، پوشش افزایش یافته و مسیرهای اجرایی جدیدی پیدا شده است.
#include
#include
void format_string_vulnerability(char *input) {
char buffer[100];
// Introducing a format string vulnerability
snprintf(buffer, sizeof(buffer), input);
}
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size < 1) {
return 0;
}
char input[100];
if (size < sizeof(input)) {
memcpy(input, data, size);
format_string_vulnerability(input);
}
return 0;
}
۳. تشخیص خطا:
- تشخیص خطای قطعهبندی ناشی از آسیبپذیری رشته قالب.
۴. بازخورد بلادرنگ:
- گزارش فوری خرابی با ردیابی پشته و جزئیات خطا.
۵.۱.۵ مقایسه نتایج
KLEE و LibFuzzer نقاط قوت مختلفی را نشان میدهند که در زمینه تست نرمافزار مکمل یکدیگر هستند. کاوش کامل مسیر KLEE برای تجزیه و تحلیل عمیق امنیتی بسیار ارزشمند است، در حالی که قابلیتهای تشخیص سریع LibFuzzer آن را برای گردشهای کاری یکپارچهسازی مداوم ایدهآل میکند.
۵.۱.۶ پیامدهای دنیای واقعی
یافتهها نشان میدهد که یک رویکرد ترکیبی با استفاده از KLEE و LibFuzzer میتواند یک راهحل قوی برای شناسایی طیف وسیعی از آسیبپذیریها ارائه دهد. این استراتژی ترکیبی از نقاط قوت هر دو ابزار بهره میبرد و پوشش جامع و تشخیص سریعی را ارائه میدهد.
KLEE در کاوش تمام مسیرهای ممکن در کد و شناسایی موارد حاشیهای بسیار مؤثر است، اما به دلیل کاوش جامع مسیر میتواند کندتر باشد. LibFuzzer در یافتن سریع اشکالات از طریق فازینگ کارآمد است و بازخورد بلادرنگ را با گزارشهای خرابی دقیق ارائه میدهد، اما ممکن است برخی از موارد حاشیهای را که اجرای نمادین میتواند تشخیص دهد، از دست بدهد. استفاده از هر دو ابزار به طور همزمان، رویکردی جامع برای آزمایش نرمافزار و تشخیص آسیبپذیری ارائه میدهد و از نقاط قوت اجرای نمادین و فازینگ برای دستیابی به پوشش کامل و تشخیص کارآمد اشکال بهره میبرد.
5.2 تست در SQLite
مشاهدات دقیق برای آزمایشهای sqlite به بخشهایی برای هر ابزار تقسیم شده است که نقاط قوت، ضعف و انواع آسیبپذیریهایی را که به طور مؤثر تشخیص میدهند، برجسته میکند. این مطالعه با نگاهی عمیق به قابلیتها و نتایج KLEE آغاز میشود و به دنبال آن تجزیه و تحلیل عملکرد و یافتههای LibFuzzer ارائه میشود. این مطالعه مقایسهای، بینشهای ارزشمندی در مورد اثربخشی این ابزارها در افزایش امنیت و قابلیت اطمینان نرمافزار ارائه میدهد.
5.2.1 KLEE
KLEE بینش عمیقی در مورد آسیبپذیریهای پیچیدهای که نیاز به تجزیه و تحلیل کامل مسیر دارند، ارائه میدهد و آن را برای آزمایش امنیتی دقیق مناسب میسازد. این ابزار آسیبپذیریهای پیچیده را در مسیرهای چندگانه شناسایی کرد، اما محدودیتهایی در مدیریت اجراهای همزمان نشان داد. این بینشها برای درک نحوه رفتار نرمافزار تحت سناریوهای مختلف اجرا و شناسایی اشکالات ظریفی که ممکن است در طول آزمایشهای سنتی آشکار نشوند، بسیار مهم هستند.
5.2.2 LibFuzzer
قدرت LibFuzzer در کشف سریع طیف وسیعی از آسیبپذیریها نهفته است که آن را برای ادغام در خطوط لوله CI/CD برای بررسیهای منظم کد ایدهآل میکند. این ابزار در تشخیص سریع آسیبپذیریها عالی بود، اما در پوشش عمیق آسیبپذیریهای منطقی پیچیده، اثربخشی کمتری داشت. این امر LibFuzzer را به ویژه برای تضمین قابلیت اطمینان و امنیت مداوم نرمافزار در محیطهای توسعه پویا مفید میکند.
5.3 معیارهای عملکرد
معیارهای عملکرد با تمرکز بر زمان اولین تشخیص و استفاده از منابع در طول آزمایشها جمعآوری شدند.
5.3.1 زمان اولین تشخیص
- KLEE: شروع کندتری در تشخیص اولین نمونه از آسیبپذیریها نشان داد، اما کاوش جامعی در مسیر ارائه داد. این ویژگی برای یافتن اشکالات ریشهدار عمیق که نیاز به تحلیل مسیر گسترده دارند، مفید است.
- LibFuzzer: به دلیل تولید ورودی تهاجمی و استراتژیهای جهش، در شناسایی اولین آسیبپذیریها سریعتر عمل کرد. این قابلیت تشخیص سریع برای شناسایی و رسیدگی سریع به آسیبپذیریهای سطح ضروری است.
5.3.2 مصرف منابع
- KLEE: به دلیل الزامات گسترده کاوش مسیر و مدیریت وضعیت، به طور متوسط حافظه بیشتری مصرف میکرد. این مصرف بالای منابع، در واقع بدهبستانی برای قابلیتهای تحلیل کامل آن است.
- LibFuzzer: به دلیل رویکرد فازینگ کارآمد مبتنی بر جهش، عموماً از حافظه و پردازنده کمتری استفاده میکرد. این کارایی، آن را برای ادغام در محیطهایی با منابع محدود مناسب میسازد.
5.4 کشف آسیبپذیری
- KLEE :KLEE دسترسی به حافظه خارج از محدوده را که ریشه در کتابخانهها دارد، شناسایی کرد که برای جلوگیری از سوءاستفادههای امنیتی بالقوه بسیار مهم است. این یافتهها بر توانایی ابزار در کشف آسیبپذیریهایی که میتوانند برای حملات جدی مورد سوءاستفاده قرار گیرند، تأکید میکنند.
- LibFuzzer :LibFuzzer ارجاعهای اشارهگر تهی را افشا میکرد که میتواند منجر به از کار افتادن برنامه و خطرات امنیتی بالقوه شود. تشخیص چنین آسیبپذیریهایی برای حفظ پایداری و امنیت برنامه ضروری است.
۵.۵ نتایج KLEE
بررسی کامل حاصل از KLEE، همراه با کارایی حلکننده، پتانسیل اجرای نمادین را در کشف مسیرهای اجرای پنهان و آسیبپذیریها در سیستمهای نرمافزاری پیچیده مانند SQLite نشان میدهد. این هشدارها بر نیاز به مهارهای تست پیشرفته که میتوانند وابستگیهای خارجی و زمینههای اجرای موازی را بهتر شبیهسازی کنند، تأکید میکنند.
۵.۵.۱ مقداردهی اولیه ورودیهای نمادین (Symbolic Inputs Initialization)
هنگامی که یک ورودی نمادین ایجاد میشود (مثلاً با استفاده از klee_make_symbolic)، KLEE به طور خودکار این رشتهها را به صورت null-termine خاتمه نمیدهد. این ناحیه حافظه را به عنوان حاوی بایتهای نمادین دلخواه و بدون محدودیت در نظر میگیرد.
۵.۵.۱.۱ مسئولیت هارنس تست (Test Harness)
معمولاً اعمال هرگونه محدودیت دلخواه بر روی ورودیهای نمادین بر عهده شخصی است که هارنس تست (Test Harness) را مینویسد. برای مثال، اگر ورودی نیاز به یک رشته با انتهای تهی داشته باشد، هارنس تست باید صریحاً آخرین کاراکتر بافر نمادین را روی «0» تنظیم کند تا این رفتار را مدلسازی کند. مطابق با فهرست reflst:null.
char s[10];
klee_make_symbolic(s, sizeof(s), "s");
s[sizeof(s) - 1] = ’\0’; // Ensure null termination
۵.۵.۲ مدیریت توسط توابع رشتهای
هنگامی که KLEE برنامهای را اجرا میکند که این رشتههای نمادین را با استفاده از توابع رشتهای استاندارد مانند strcpy، strlen دستکاری میکند، رفتار اجرا میتواند مشکلاتی را آشکار کند:
۱. با خاتمه تهی: توابع مطابق انتظار رفتار میکنند و تا پایانه تهی پردازش میشوند.
۲. بدون خاتمه تهی: توابعی که انتظار رشتههای خاتمه تهی دارند ممکن است منجر به دسترسیهای خارج از محدوده شوند که KLEE قصد شناسایی آن را دارد. KLEE تلاش خواهد کرد تا تمام مسیرهای ممکن را در طول برنامه دنبال کند، از جمله مسیرهایی که ممکن است منجر به عدم خاتمه تهی رشتهها شوند. اگر یک تابع به دلیل عدم وجود پایانه تهی، از اندازه بافر اختصاص داده شده فراتر رود، KLEE باید این را به عنوان یک دسترسی حافظه خارج از محدوده تشخیص دهد.
۵.۵.۳ تشخیص خطاها و رفتارهای نامشخص
KLEE برای شناسایی و گزارش خطاهایی مانند سرریز بافر طراحی شده است که ممکن است در صورت دسترسی یک عملیات رشتهای به حافظه فراتر از محدودیتهای در نظر گرفته شده به دلیل فقدان پایانههای تهی رخ دهد.
۵.۵.۴ کاوش مسیر
در سناریوهایی که رفتار برنامه به این بستگی دارد که آیا یک رشته به تهی بودن یا نبودن ختم میشود، KLEE هر دو مسیر را کاوش میکند: یکی در جایی که رشته به تهی بودن ختم میشود و دیگری در جایی که ختم نمیشود. این کاوش دو مسیره به کشف نحوه رفتار برنامه در شرایط ورودی مختلف کمک میکند.
۵.۶ نتایج فازینگ LibFuzzer
رویکردهای تست فازینگ با استفاده از یک مهار تست سفارشی برای پایگاههای داده SQLite در درجه اول بر اجرای پرسوجوها با ورودیهای فازینگ شده متمرکز بودند. این امر چندین نقطه بحرانی از شکست را آشکار کرد که میتوانستند تحت شرایط خاصی مورد سوءاستفاده قرار گیرند.
۵.۶.۱ کشف آسیبپذیری
تحلیل ترکیبی چندین دسته متمایز از آسیبپذیریها را در SQLite آشکار کرد:
۱. ارجاع به اشارهگر تهی (LibFuzzer): LibFuzzer چندین سناریوی خرابی مربوط به ارجاع به اشارهگر تهی را افشا کرد. ورودیهای ایجادکننده خرابی ارائه شده توسط LibFuzzer، همراه با ردیابیهای پشته بهدستآمده از طریق AddressSanitizer، به یک زنجیره احتمالی از رویدادها اشاره دارند.
۵.۷ یافتههای رویکرد
KLEE در شناسایی یک نقص منطقی ظریف که توسط یک توالی بسیار خاص از عملیات و شرایط ورودی ایجاد شده بود، عالی عمل کرد. برعکس، قدرت LibFuzzer در توانایی آن در تولید سریع ورودیهای متنوع بود که قادر به افشای موارد غیرمنتظره و ایجاد خرابیهای ناشی از فساد وضعیت بودند.


۵.۸ تحلیل مقایسهای
KLEE و LibFuzzer نقاط قوت مختلفی را نشان میدهند که در زمینه تست نرمافزار مکمل یکدیگر هستند. کاوش کامل مسیر KLEE برای تحلیل عمیق امنیتی بسیار ارزشمند است، در حالی که قابلیتهای تشخیص سریع LibFuzzer آن را برای گردشهای کاری یکپارچهسازی مداوم ایدهآل میکند.
۵.۸.۱ پیامدهای دنیای واقعی
یافتهها نشان میدهد که یک رویکرد ترکیبی با استفاده از KLEE و LibFuzzer میتواند یک راهحل قوی برای شناسایی طیف وسیعی از آسیبپذیریها ارائه دهد. این استراتژی ترکیبی از نقاط قوت هر دو ابزار بهره میبرد و پوشش جامع و تشخیص سریعی را ارائه میدهد.
۵.۹ خلاصه
در این فصل، نتایج آزمایش آسیبپذیریهای نرمافزار با استفاده از دو ابزار پیشرفته، KLEE و LibFuzzer، ارائه شده است. هر دو ابزار از رویکردهای متمایزی استفاده میکنند و تکنیکهای مکملی را برای دستیابی به پوشش جامع و کشف آسیبپذیریهای آشکار و پنهان ارائه میدهند. تمرکز اصلی بر آزمایش آسیبپذیریهای رایج، مانند سرریز بافر، ارجاع به اشارهگر تهی، آسیبپذیریهای استفاده پس از آزادسازی و رشته قالببندی است. این آسیبپذیریها در صورت عدم شناسایی و کاهش صحیح میتوانند منجر به سوءاستفادههای امنیتی جدی، خرابیها و فساد دادهها شوند.
KLEE از اجرای نمادین برای بررسی تمام مسیرهای ممکن در کد استفاده میکند. این بررسی کامل با مثالهایی مانند تشخیص سرریز بافر نشان داده میشود، که در آن KLEE به پوشش ۱۰۰٪ دستورالعمل و شاخه دست مییابد. فرآیند اجرای نمادین به KLEE اجازه میدهد تا موارد آزمایشی را ایجاد کند که شامل شرایط مرزی و سناریوهای خطا هستند و گزارشهای دقیق و گزارشهای خطا را ارائه میدهند. به عنوان مثال، در مثال سرریز بافر، KLEE یک خطای حافظه ناشی از دسترسی خارج از محدوده را شناسایی میکند و جزئیات دقیقی در مورد محل خطا و شرایطی که منجر به آن میشود، ارائه میدهد. این قابلیت به ویژه برای شناسایی مسائل ریشهدار که ممکن است از طریق روشهای تست مرسوم آشکار نشوند، مفید است.
در مقابل، LibFuzzer با اجرای سریع تکرارهای متعدد با ورودیهای مختلف تولید شده بر اساس یک مجموعه داده اولیه، استراتژی متفاوتی را به کار میگیرد. این رویکرد فازی در تشخیص آسیبپذیریها و ارائه گزارشهای خرابی در زمان واقعی با ردیابی دقیق پشته کارآمد است. به عنوان مثال، در آزمایش آسیبپذیریهای سرریز بافر، LibFuzzer خطاهای سرریز پشته ناشی از ورودیهایی را که منجر به بازگشت بیش از حد یا تخصیصهای بزرگ پشته میشوند، تشخیص میدهد. این ابزار در تشخیص سریع عالی است و آن را برای ادغام در گردشهای کاری ادغام مداوم ایدهآل میکند. این ابزار بازخورد فوری در مورد خرابیها ارائه میدهد و به توسعهدهندگان کمک میکند تا به سرعت آسیبپذیریها را شناسایی و برطرف کنند. این کارایی با عمق کمی کمتر در کاوش مسیر در مقایسه با KLEE متعادل میشود، اما سرعت تشخیص اولیه آسیبپذیری را به طور قابل توجهی افزایش میدهد.
این فصل همچنین تجزیه و تحلیل دقیقی از آزمایش سیستم پایگاه داده SQLite ارائه میدهد و نقاط قوت و ضعف مربوط به KLEE و LibFuzzer را برجسته میکند. کاوش عمیق مسیر KLEE برای شناسایی آسیبپذیریهای پیچیدهای که نیاز به تجزیه و تحلیل کامل مسیرهای اجرایی متعدد دارند، بسیار ارزشمند است. به عنوان مثال، اجرای نمادین KLEE میتواند نقصهای منطقی ظریفی را که توسط توالیهای خاصی از عملیات و شرایط ورودی ایجاد میشوند، مشخص کند. با این حال، این کاوش جامع مسیر منجر به استفاده بیشتر از حافظه و CPU میشود. از سوی دیگر، قدرت LibFuzzer در توانایی آن در کشف سریع طیف گستردهای از آسیبپذیریها نهفته است که آن را برای تضمین قابلیت اطمینان و امنیت مداوم نرمافزار در محیطهای توسعه پویا مناسب میکند. این ابزار به طور موثر تعداد زیادی از تکرارها را مدیریت میکند و مسائلی مانند ارجاع به اشارهگر تهی و خطاهای استفاده پس از آزادسازی را شناسایی میکند.
معیارهای عملکرد جمعآوریشده در طول مرحله آزمایش، تفاوتهای بین این دو ابزار را برجسته میکند. KLEE به دلیل کاوش جامع مسیر، شروع کندتری در تشخیص اولین نمونه از آسیبپذیریها نشان میدهد که برای یافتن اشکالات ریشهدار که نیاز به تجزیه و تحلیل گسترده دارند، مفید است. این ویژگی، توانایی ابزار را در کشف آسیبپذیریهایی که میتوانند برای حملات جدی مورد سوءاستفاده قرار گیرند، برجسته میکند. در مقابل، LibFuzzer به دلیل استراتژیهای تهاجمی تولید ورودی و جهش، که برای شناسایی و رسیدگی سریع به آسیبپذیریهای سطح ضروری است، در شناسایی اولین آسیبپذیریها سریعتر عمل میکند. تجزیه و تحلیل مصرف منابع نشان میدهد که KLEE به دلیل کاوش گسترده مسیر و الزامات مدیریت وضعیت، به طور متوسط حافظه بیشتری مصرف میکند، در حالی که LibFuzzer به طور کلی استفاده کمتری از حافظه و CPU دارد و آن را برای محیطهایی با منابع محدود مناسبتر میکند.
این با یک تجزیه و تحلیل مقایسهای به پایان میرسد که بر ماهیت مکمل KLEE و LibFuzzer در تست نرمافزار تأکید دارد. کاوش کامل مسیر KLEE و گزارش خطای دقیق آن برای تجزیه و تحلیل عمیق امنیتی بسیار ارزشمند است، در حالی که قابلیتهای تشخیص سریع LibFuzzer آن را برای گردشهای کاری ادغام مداوم ایدهآل میکند. یافتهها نشان میدهد که یک رویکرد ترکیبی با استفاده از هر دو ابزار میتواند یک رویکرد جدید ارائه دهد.
یک راهکار obust برای شناسایی طیف وسیعی از آسیبپذیریها. این استراتژی ترکیبی، نقاط قوت هر دو ابزار را به کار میگیرد و پوشش جامع و تشخیص سریع را ارائه میدهد. با ادغام تکنیکهای اجرای نمادین و فازینگ، توسعهدهندگان میتوانند به پوشش کامل و تشخیص کارآمد اشکال دست یابند و امنیت و قابلیت اطمینان نرمافزار را به طور قابل توجهی افزایش دهند. پیامدهای واقعی این یافتهها، اهمیت اتخاذ یک رویکرد چندوجهی برای آزمایش نرمافزار را برجسته میکند و مکانیسمهای دفاعی قوی را در برابر تهدیدات امنیتی بالقوه تضمین میکند.
فصل 6
بحثها
6.1 مقدمه
این فصل به بررسی یافتههای حاصل از آزمایشها و مقایسه عملکرد KLEE و LibFuzzer در شناسایی آسیبپذیریها در پایگاه کد SQLite میپردازد. این بحث شامل تجزیه و تحلیل معیارهای پوشش، عمق و وسعت آزمایش، زمان اجرا، مزایای یک رویکرد ترکیبی، محدودیتها و کارهای آینده است.
6.2 مقایسه معیارهای پوشش
نتایج پوشش، نقاط قوت و محدودیتهای متمایز هر دو ابزار را نشان میدهد. اجرای نمادین KLEE به پوشش دستورالعمل ۳.۶۵٪ و پوشش شاخه ۲.۴۲٪ دست یافت که در مقایسه با پوشش ناحیه و تابع LibFuzzer از SQLite-amalgamation-3450100 نسبتاً پایین است. این را میتوان به تفاوتهای اساسی در رویکردهای آزمایش این دو ابزار نسبت داد.
۶.۲.۱ KLEE
- نقطه قوت: اجرای نمادین با حل محدودیتها، تمام مسیرهای اجرای ممکن را بررسی میکند که از نظر محاسباتی فشرده است. درصد پوشش پایین نشان میدهد که KLEE مسیرهای منحصر به فردی را بررسی میکند که کمتر در سناریوهای استفاده معمول اجرا میشوند.
- اهمیت: این کاوش عمیق برای کشف اشکالات پنهانی که ممکن است فقط تحت شرایط خاص ظاهر شوند، بسیار مهم است.
۶.۲.۲ LibFuzzer
- نقطه قوت: آزمایش فاز تعداد زیادی ورودی را برای پوشش هرچه بیشتر مسیرهای کد تولید و اجرا میکند. درصد پوشش بالاتر برای نواحی (۳۱.۶۰٪)
و توابع (40.39%) در sqlite3.c اثربخشی LibFuzzer را در پوشش طیف وسیعی از مسیرهای اجرای دنیای واقعی نشان میدهند.
- اهمیت: این وسعت برای تشخیص آسیبپذیریهایی که ممکن است توسط ورودیهای متنوع ایجاد شوند، ضروری است.
6.3 عمق و وسعت آزمایش
6.3.1 KLEE
- کاوش در موارد حاشیهای: توانایی KLEE در کاوش در موارد حاشیهای و کشف اشکالات ظریف با زمان صرف شده در حلکننده محدودیت (56.99%) برجسته میشود. این معیار پیچیدگی مسیرهایی را که KLEE سعی در کاوش آنها دارد، نشان میدهد.
- چالشها: در حالی که KLEE در تجزیه و تحلیل مسیرهای اجرای تکرشتهای برتری دارد، اما در مدیریت اجراهای همزمان محدودیتهایی را نشان داده است که نشاندهنده زمینهای برای بهبود در آینده است.
۶.۳.۲ LibFuzzer
- پوشش بالاتر: رویکرد LibFuzzer منجر به پوشش خط و تابع بالاتر میشود و آن را برای یافتن مشکلات در مسیرهای کد رایجتر مناسبتر میکند.
- تشخیص سریع: LibFuzzer با تولید و آزمایش مداوم ورودیهای جدید، آسیبپذیریها، از جمله ارجاعهای اشارهگر تهی و نشت حافظه را به سرعت شناسایی کرد.
۶.۴ زمان اجرا
۶.۴.۱ KLEE
- زمان اجرا: زمان اجرای KLEE ۵۱۰۰.۸۴ ثانیه یا تقریباً ۱.۴۲ ساعت نشان دهنده زمان صرف شده توسط CPU در طول اجرای نمادین است. زمان واقعی ۲۴ ساعت بود که ماهیت فشرده اجرای نمادین را برجسته میکند.
- استفاده از منابع: این نشان میدهد که عملیات KLEE، به ویژه حل محدودیت، میتواند CPUمحور باشد و از چندین هسته استفاده کند و به طور بالقوه منجر به بار زیاد سیستم در دورههای طولانی شود.
۶.۴.۲ LibFuzzer
- سرعت اجرا: LibFuzzer به دلیل تولید ورودی تهاجمی و استراتژیهای جهش، در شناسایی اولین آسیبپذیریها سریعتر عمل کرد. این قابلیت تشخیص سریع برای شناسایی سریع و رسیدگی به آسیبپذیریهای سطح ضروری است. در نمونههایی از کد آسیبپذیری، گزارشها بلافاصله جمعآوری شدند.
برای آزمایش پوشش در Sqlite، fuzzer به مدت ۲۴ ساعت اجرا شد.
۶.۵ تحلیل مقایسهای نتایج
برای مقایسه نتایج KLEE و LibFuzzer در SQLite تحت معیارهای پوشش، استانداردسازی دادههای گزارششده برای ارزیابی دقیق مهم است. KLEE پوشش دستورالعملها را ۳.۶۵٪ و پوشش شاخهها را ۲.۴۲٪ گزارش میکند، در حالی که LibFuzzer معیارهای پوشش را بر اساس مناطق (۳۱.۶۱٪)، توابع (۴۰.۴۲٪) و خطوط پوشش داده شده (۳۲.۹۵٪) ارائه میدهد. برای تسهیل مقایسه مستقیم، هر دو ابزار باید در حالت ایدهآل پوشش خط را گزارش کنند. تبدیل پوشش دستورالعمل KLEE به پوشش خط، امکان مقایسهی سادهتر با معیارهای پوشش خط LibFuzzer را فراهم میکند.
آمار اجرا برای ایجاد یک مقایسهی منصفانه نیاز به نرمالسازی دارد. KLEE گزارش میدهد که 11,994,490 دستورالعمل با زمان اجرای کل 5100.84 ثانیه اجرا میشود. از سوی دیگر، LibFuzzer بیش از 12,000,000 تکرار و 10 خرابی منحصر به فرد را بدون تعداد دستورالعمل خاص گزارش میدهد. برای مقایسهی این معیارها، لازم است زمانهای اجرا به یک بازه زمانی مشترک نرمالسازی شوند. برای تعیین دقیق میانگین تعداد دستورالعملهای اجرا شده در هر تکرار توسط LibFuzzer، اندازهگیریهای دقیقی با استفاده از یک ابزار تحلیل عملکرد مورد نیاز است. با اندازهگیری کل دستورالعملهای اجرا شده در تعداد مشخصی از تکرارها، میتوان میانگین دستورالعملها در هر تکرار را بدست آورد و از این دادهها برای تخمین کل دستورالعملهای اجرا شده توسط LibFuzzer استفاده کرد. با تراز کردن معیارهای پوشش، دستهبندی آسیبپذیریها به انواع رایج، و نرمالسازی آمار اجرا، میتوان به یک مقایسه استاندارد بین KLEE و LibFuzzer دست یافت که درک واضحتری از عملکرد مربوط به آنها در ارزیابی پایگاه کد SQLite ارائه میدهد.
6.6 محدودیتها
6.6.1 KLEE
در حالی که KLEE ابزاری قدرتمند است، با چالشهای متعددی، به ویژه از نظر مقیاسپذیری و مدیریت سیستمهای نرمافزاری پیچیده، مواجه است. فرآیند حل محدودیت میتواند از نظر محاسباتی پرهزینه باشد و توانایی KLEE را برای مقیاسپذیری در پایگاههای کد بسیار بزرگ محدود کند. علاوه بر این، اثربخشی KLEE میتواند تحت تأثیر وجود فراخوانیهای کتابخانهای خارجی قرار گیرد، که ممکن است در طول اجرای نمادین به طور کامل بررسی نشوند.
6.6.1.1 مسائل مربوط به حافظه و عملکرد
استفاده زیاد از حافظه KLEE و الزامات محاسباتی فشرده آن، چالشهای قابل توجهی را ایجاد میکند. این مسائل را میتوان با بهینهسازی موتور اجرای نمادین و بهبود تکنیکهای مدیریت حافظه کاهش داد. ۶.۶.۱.۲ مدلسازی تابع خارجی ناتوانی در مدلسازی دقیق توابع خارجی و اجراهای همزمان، اثربخشی KLEE را در سناریوهای خاص محدود میکند. پیشرفتهای آینده باید بر مدلسازی بهتر این جنبهها برای بهبود قابلیتهای کلی ابزار متمرکز شوند.
۶.۶.۲ LibFuzzer
LibFuzzer همچنین محدودیتهایی دارد که بر اثربخشی آن در تشخیص جامع آسیبپذیری تأثیر میگذارد.
۶.۶.۲.۱ عمق تحلیل
در حالی که LibFuzzer در تولید طیف گستردهای از ورودیها و دستیابی به پوشش بالا کارآمد است، ممکن است خطاهای منطقی عمیقی را که برای فعال شدن به توالیهای خاصی از ورودیها نیاز دارند، از دست بدهد. برخلاف اجرای نمادین، فازینگ فاقد توانایی کاوش سیستماتیک تمام مسیرهای اجرایی ممکن.
6.6.2.2 انفجار فضای حالت
LibFuzzer میتواند تعداد زیادی ورودی تولید کند که منجر به انفجار فضای حالت میشود که در آن Fuzzer زمان قابل توجهی را روی بخشهای کماهمیتتر کدبیس صرف میکند. این میتواند منجر به کاهش بازده شود که در آن فازینگ اضافی، اشکالات جدید کمتری را به همراه دارد.
6.6.2.3 مدیریت کدهای پیچیده
اثربخشی LibFuzzer میتواند هنگام کار با کدهای بسیار بزرگ و پیچیده محدود شود. ممکن است برای تولید جهشهای معنادار برای ورودیهای بسیار ساختاریافته یا عمیقاً تودرتو با مشکل مواجه شود، که میتواند توانایی آن را در کشف انواع خاصی از آسیبپذیریها کاهش دهد.
۶.۷ کار و بهبودهای آینده
بر اساس یافتهها، چندین زمینه برای کار و بهبودهای بالقوه در آینده شناسایی شده است:
۶.۷.۱ افزایش قابلیتهای ابزار
- تحلیل اجرای همزمان: افزایش توانایی KLEE در مدیریت اجراهای همزمان میتواند اثربخشی آن را در محیطهای چند رشتهای به طور قابل توجهی بهبود بخشد.
- مدیریت حافظه و مدلسازی تابع خارجی: توسعه تکنیکهای مدیریت حافظه بهبود یافته و گسترش قابلیتهای مدلسازی برای مدیریت بهتر فراخوانیهای سیستمی و توابع خارجی میتواند امکان آزمایش کاملتر را فراهم کند. ادغام حلکنندههای پیشرفتهتر یا توسعه الگوریتمهای تخصصی برای مدیریت آرایههای نمادین بزرگ نیز مفید خواهد بود.
۶.۷.۲ توسعه چارچوب یکپارچه
توسعه یک چارچوب آزمایش یکپارچه که از اجرای نمادین و فازینگ بهره میبرد، میتواند فرآیند تشخیص و کاهش آسیبپذیری را ساده کند. این امر دقت اجرای نمادین را با کارایی آزمایش فازینگ ترکیب میکند و یک رویکرد جامع برای آزمایش ارائه میدهد.
۶.۷.۳ طبقهبندی
پیادهسازی سازوکارهای طبقهبندی برای اولویتبندی آسیبپذیریها بر اساس شدت و تأثیر آنها میتواند تلاشهای اصلاحی را بهینه کند. این رویکرد تضمین میکند که مهمترین مسائل به سرعت مورد توجه قرار گیرند.
۶.۷.۴ تکنیکهای بهینهسازی
بررسی بهینهسازیهای خاص اجرای نمادین، مانند اجرای نمادین انتخابی یا روشهای هوشمندانهتر هرس مسیر، میتواند عملکرد و اثربخشی آزمایش سیستمهای پیچیدهای مانند SQLite را بهبود بخشد. این بهینهسازیها به مدیریت نیازهای محاسباتی اجرای نمادین کمک میکنند.
۶.۷.۵ رویکردهای تست ترکیبی
ترکیب اجرای نمادین با سایر روشهای تست، مانند تست فازی یا تست واحد، میتواند رویکردی جامعتر برای آزمایش نرمافزارهای پیچیده ارائه دهد.
بهرهگیری از نقاط قوت هر روش، سناریوهای بیشتری را به طور مؤثر پوشش میدهد و قابلیت اطمینان و استحکام بالاتر نرمافزار را تضمین میکند.
۶.۷.۶ گسترش پوشش تست
تحقیقات بیشتر میتواند راههایی را برای گسترش پوشش تست با توسعه روشهای اکتشافی جدید برای تولید ورودی و کاوش مسیر بررسی کند. این امر به کشف اشکالات و آسیبپذیریهای عمیقتری که ممکن است در استراتژیهای تست فعلی پنهان بمانند، کمک میکند.
۶.۸ پیامدها
نتایج تجربی حاصل از KLEE و LibFuzzer نقاط قوت و محدودیتهای این ابزارها را هنگام اعمال بر روی نرمافزارهای پیچیدهای مانند SQLite برجسته میکند. بینشهای به دست آمده، چندین پیامد برای استراتژیهای توسعه و آزمایش ابزارهای آینده ارائه میدهد:
- بهبود ابزار: افزایش قابلیتهای KLEE و LibFuzzer، به ویژه در مدیریت پایگاههای کد پیچیده و اجراهای همزمان، اثربخشی کلی آنها را بهبود میبخشد.
- چارچوبهای تست یکپارچه: توسعه چارچوبهایی که اجرای نمادین و تست فاز را ترکیب میکنند، میتوانند ارزیابیهای جامعی از آسیبپذیریها ارائه دهند و از نقاط قوت هر دو رویکرد بهره ببرند.
- رویکرد جامع به تست: یک رویکرد ترکیبی که شامل اجرای نمادین، تست فاز و سایر روشها است، میتواند راهحل قویتری برای آزمایش سیستمهای نرمافزاری پیچیده ارائه دهد.
- تمرکز بر آسیبپذیریهای حیاتی: اولویتبندی و طبقهبندی خودکار، اولویتبندی شدیدترین آسیبپذیریها را تضمین میکند و منجر به تلاشهای اصلاحی مؤثرتر میشود.
۶.۹ خلاصه
ارزیابی SQLite با استفاده از KLEE و LibFuzzer بینشهای ارزشمندی در مورد قابلیتها و محدودیتهای این ابزارهای تست ارائه میدهد. در حالی که KLEE کاوش کامل مسیر را از طریق اجرای نمادین ارائه میدهد، مقیاسپذیری آن به دلیل محدودیتهای حافظه و نیاز به مدلسازی بهتر توابع خارجی محدود است. از سوی دیگر، LibFuzzer در تولید مجموعهای متنوع از ورودیها و کشف آسیبپذیریها به طور موثر عالی است، اما ممکن است اشکالات عمیقتری را که برای فعال شدن به توالیهای ورودی خاص نیاز دارند، از دست بدهد. ترکیب این ابزارها در یک چارچوب تست جامع میتواند یک راهحل قوی برای تست سیستمهای نرمافزاری پیچیده مانند SQLite ارائه دهد.
مقایسه بین KLEE و LibFuzzer نقاط قوت مکمل آنها را در تست نرمافزار نشان میدهد. KLEE در کاوش موارد مرزی و مسیرهای اجرای نادر از طریق اجرای نمادین عالی است، در حالی که LibFuzzer پوشش گستردهای از مسیرهای رایج از طریق فازینگ ورودی ارائه میدهد. با استفاده از هر دو ابزار، توسعهدهندگان میتوانند به یک استراتژی تست جامعتر دست یابند و قابلیت اطمینان و استحکام بالاتر نرمافزار را تضمین کنند. اگرچه ممکن است معیارهای پوشش KLEE پایینتر به نظر برسد، اما عمق کاوش مسیر آن، موارد بحرانی را که اغلب توسط روشهای سنتی تست از دست میروند، آشکار میکند. LibFuzzer، با درصد پوشش بالاتر خود، به طور مؤثر نرمافزار را در برابر طیف وسیعی از ورودیها اعتبارسنجی میکند.
نتیجهگیری
این مطالعه اهمیت استفاده از تکنیکهای اجرای نمادین و فازینگ را برای تست جامع سیستمهای نرمافزاری پیچیده نشان میدهد. با ترکیب نقاط قوت KLEE و LibFuzzer، میتوانیم به یک استراتژی تست قویتر و کاملتر دست یابیم و آسیبپذیریهای عمیق و سطحی را کشف کنیم. تحقیقات و توسعههای آینده باید بر افزایش این ابزارها و ادغام آنها در یک چارچوب تست یکپارچه برای بهبود بیشتر قابلیت اطمینان و امنیت نرمافزار تمرکز کنند.
فصل 7
نتیجهگیری
ترکیب اجرای نمادین و فازینگ، نقاط قوت مکملی را در تست نرمافزار ارائه میدهد و هم تجزیه و تحلیل عمیق برنامه و هم پوشش تست گسترده را فراهم میکند. اجرای نمادین، همانطور که از طریق استفاده از KLEE نشان داده شده است، امکان کاوش کامل تمام مسیرهای اجرایی ممکن در یک برنامه را فراهم میکند و خطاهای منطقی پیچیده و آسیبپذیریهای ظریفی را که ممکن است توسط سایر تکنیکهای آزمایش از دست بروند، آشکار میسازد. فازینگ، همانطور که توسط LibFuzzer نشان داده شده است، در تولید سریع مجموعهای متنوع از ورودیها، و آشکارسازی سریع طیف وسیعی از آسیبپذیریها، از جمله نشت حافظه و ارجاع مجدد به اشارهگر تهی، عالی عمل میکند. نتایج این مطالعه، مقایسه بین این دو تکنیک را برای افزایش استحکام کلی سیستمهای نرمافزاری برجسته میکند. با بهرهگیری از نقاط قوت هر دو رویکرد، میتوانیم به یک فرآیند تشخیص آسیبپذیری جامعتر و کارآمدتر دست یابیم. ادغام این رویکردها نه تنها میزان تشخیص آسیبپذیریهای امنیتی بالقوه را بهبود میبخشد، بلکه بینش دقیقی در مورد ماهیت و محل این آسیبپذیریها ارائه میدهد و تشخیص سریعتر و آسانتر را تسهیل میکند.
علاوه بر این، توانایی این ابزارها برای ادغام یکپارچه در محیطهای توسعه نرمافزار موجود، از جمله محیطهای توسعه یکپارچه IDE و خطوط لوله ادغام مداوم/استقرار مداوم CI/CDکاربرد عملی آنها را افزایش میدهد. این امر تضمین میکند که تست امنیتی به بخشی مداوم و خودکار از چرخه عمر توسعه نرمافزار تبدیل میشود و در نتیجه خطر ورود نقصهای امنیتی به سیستمهای تولیدی را کاهش میدهد. با خودکارسازی این تستهای امنیتی، تیمهای توسعه میتوانند کیفیت بالای کد و استانداردهای امنیتی را بدون سربار اضافی قابل توجه حفظ کنند.
7.1 بینشهای کلیدی و تحلیل مقایسهای
ارزیابی SQLite با استفاده از KLEE و LibFuzzer بینشهای ارزشمندی در مورد قابلیتها و محدودیتهای این ابزارهای تست ارائه میدهد:
۷.۱.۱ KLEE
- کاوش کامل مسیر: KLEE کاوش عمیق مسیر را از طریق اجرای نمادین ارائه میدهد و خطاهای منطقی پیچیده و آسیبپذیریهای ظریفی را که ممکن است توسط روشهای سنتی تست از دست بروند، شناسایی میکند. توانایی آن در کاوش سیستماتیک تمام مسیرهای اجرا، پوشش جامعی از موارد بالقوه حاشیهای را تضمین میکند.
- گزارش خطای دقیق KLEE: مقادیر ورودی مشخص و مسیرهای اجرای خاصی را که باعث آسیبپذیریها میشوند، ارائه میدهد و بینشهای ارزشمندی برای اشکالزدایی و وصلهگذاری ارائه میدهد. این سطح از جزئیات به توسعهدهندگان در درک شرایط دقیق وقوع خطاها کمک میکند و منجر به رفع دقیقتر آنها میشود.
- محدودیتها مقیاسپذیری KLEE :به دلیل محدودیتهای حافظه و نیاز به مدلسازی بهتر توابع خارجی محدود است. علاوه بر این، KLEE محدودیتهایی را در مدیریت اجراهای همزمان نشان داد. این چالشها نشاندهنده نیاز به تحقیق و توسعه بیشتر برای افزایش مقیاسپذیری و مدیریت همزمانی KLEE است.
۷.۱.۲ LibFuzzer
- تشخیص سریع آسیبپذیری :LibFuzzer در تولید مجموعهای متنوع از ورودیها، به سرعت طیف وسیعی از آسیبپذیریها، از جمله نشت حافظه و ارجاع مجدد به اشارهگر تهی را آشکار میکند. سرعت و کارایی آن، آن را به ابزاری عالی برای شناسایی و رسیدگی سریع به مسائل امنیتی تبدیل میکند.
- پوشش گسترده تست : LibFuzzer با اعتبارسنجی مؤثر نرمافزار در برابر طیف وسیعی از ورودیها، درصد پوشش بالاتری را به دست میآورد و آن را برای تشخیص آسیبپذیریهای سطح ایدهآل میکند. این طیف گسترده ورودی به اطمینان از آزمایش بسیاری از ورودیهای رایج و غیرمعمول کمک میکند و قابلیت اطمینان کلی نرمافزار را بهبود میبخشد.
- محدودیتها: در حالی که LibFuzzer در تولید ورودیها و کشف آسیبپذیریها کارآمد است، ممکن است اشکالات عمیقتری را که برای فعال شدن به توالیهای ورودی خاص نیاز دارند، از دست بدهد. این محدودیت، اهمیت ترکیب فازینگ با سایر تکنیکها را برای اطمینان از پوشش جامع برجسته میکند. 82
7.2 نقاط قوت مکمل
مقایسه بین KLEE و LibFuzzer نقاط قوت مکمل آنها را در تست نرمافزار آشکار میکند:
- تحلیل عمیق :KLEE در کاوش موارد حاشیهای و مسیرهای اجرای نادر از طریق اجرای نمادین عالی عمل میکند. این قابلیت برای کشف آسیبپذیریهایی که به راحتی از طریق تولید ورودی تصادفی قابل تشخیص نیستند، بسیار مهم است.
- پوشش گسترده LibFuzzer :پوشش گستردهای از مسیرهای مشترک از طریق فازینگ ورودی ارائه میدهد و آن را برای یافتن سریع طیف وسیعی از مسائل مؤثر میسازد. توانایی آن در اجرای میلیونها مورد تست در مدت زمان کوتاه، به اطمینان از اینکه نرمافزار میتواند طیف گستردهای از ورودیها را مدیریت کند، کمک میکند.
- رویکرد ترکیبی: با استفاده از هر دو ابزار، توسعهدهندگان میتوانند به یک استراتژی تست جامعتر دست یابند که قابلیت اطمینان و استحکام بالاتر نرمافزار را تضمین میکند.
نقاط قوت یک ابزار، محدودیتهای ابزار دیگر را جبران میکند و یک رویکرد تست متعادل و کامل ارائه میدهد.
۷.۳ نتیجهگیری و پیامدها
یافتهها نشان میدهد که ادغام اجرای نمادین با فازینگ، یک استراتژی تست قوی و کامل برای سیستمهای نرمافزاری پیچیده مانند SQLite فراهم میکند. استفاده ترکیبی از KLEE و LibFuzzer با کشف آسیبپذیریهای عمیق و سطحی، کیفیت کلی نرمافزار را افزایش میدهد. این رویکرد جامع تضمین میکند که نرمافزار با دقت بیشتری آزمایش میشود و منجر به آسیبپذیریهای کمتری در محیطهای تولید میشود.
در نتیجه، افزودن این تکنیکهای تست پیشرفته به چرخه عمر توسعه نرمافزار، تست امنیتی مداوم و خودکار را تضمین میکند و در نتیجه یک وضعیت امنیتی پیشگیرانه را ارتقا میدهد. با تبدیل تست امنیتی به بخش جداییناپذیر فرآیند توسعه، سازمانها میتوانند آسیبپذیریها را به موقع شناسایی و برطرف کنند و احتمال نقض امنیتی را کاهش دهند.
علاوه بر این، با پیچیدهتر و بههمپیوستهتر شدن سیستمهای نرمافزاری، اهمیت تست امنیتی قوی را نمیتوان نادیده گرفت. چشمانداز در حال تحول تهدیدات امنیت سایبری، بهبود و اصلاح مداوم تکنیکهای تست را ضروری میسازد. با ادامه اصلاح و گسترش این تکنیکها، و با ادغام آنها با سایر روشهای آزمایش، میتوانیم سیستمهای نرمافزاری قویتر و امنتری را توسعه دهیم که قادر به تحمل چشمانداز در حال تحول تهدیدات امنیت سایبری باشند.
پیامدهای عملی این تحقیق به شیوههای توسعه نرمافزار در دنیای واقعی نیز گسترش مییابد. توسعهدهندگان و سازمانها میتوانند از بینشهای بهدستآمده از این مطالعه برای بهبود چارچوبهای آزمایش امنیتی خود استفاده کنند و اطمینان حاصل کنند که نرمافزار آنها در برابر طیف وسیعی از تهدیدات مقاوم است. با اتخاذ یک رویکرد چندوجهی برای آزمایش امنیتی، میتوانیم سیستمهای نرمافزاری امنتر، قابل اعتمادتر و قابل اعتمادتری بسازیم که نیازهای محیط دیجیتال امروزی را برآورده کنند.
8. کتابشناسیها (Bibliography):
1. [AMW17] Eric Amankwah, Stephen McLaughlin, and Dinghao Wu. Evaluating the effectiveness of fuzz testing. International Journal of Computer Applications, 164(9):28–35, 2017.
2. [Aut24] Authors. Fuzzing: a survey. Cybersecurity, 2024. Accessed: 2024-03-19.
3. [BB13] Alberto Bacchelli and Christian Bird. Expectations, outcomes, and challenges of modern code review. In 2013 35th International Conference on Software Engineering (ICSE), pages 712–721. IEEE, 2013.
4. [BBMZ16] Moritz Beller, Radjino Bholanath, Shane McIntosh, and Andy Zaidman. Analyzing the state of static analysis: A large-scale evaluation in opensource software. In 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (SANER), volume 1, pages 470481. IEEE, 2016.
5. [BCD+18] Roberto Baldoni, Emilio Coppa, Daniele Cono D’elia, Camil Demetrescu, and Irene Finocchi. A survey of symbolic execution techniques. ACM Computing Surveys (CSUR), 51(3):1–39, 2018.
6. [CDE08] Cristian Cadar, Daniel Dunbar, and Dawson Engler. KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs. Proceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 209–224, 2008. KLEE was used to analyze the GNU Coreutils, revealing numerous bugs, many of which had been present for years.
7. [Chr19] Chromium Project. Using libfuzzer for continuous integration testing. Chromium Blog, 2019.
8. [CKC11] V. Chipounov, V. Kuznetsov, and G. Candea. S2e: A platform for invivo multi-path analysis of software systems. In Proceedings of the SixteenthInternational Conference on Architectural Support for rogramming Languages and Operating Systems (ASPLOS), pages 265–278, 2011.
9. [Cla76] L. Clarke. A system to generate test data and symbolically execute programs. IEEE Transactions on Software Engineering, 2(3):215–222, 1976.
10. [CN21] Cristian Cadar and Martin Nowack. Klee symbolic execution engine in 2019. International Journal on Software Tools for Technology Transfer, 23:867–870, 2021.
11. [CS13] Cristian Cadar and Koushik Sen. Symbolic execution for software testing: Three decades later. Communications of the ACM, 56(2):82–90, 2013.
12. [CS18] Cristian Cadar and Koushik Sen. Symbolic execution for software testing: Three decades later. Communications of the ACM, 56(2):82–90, 2018.
13. [CV20] Josué Campos and Maria Vieira. Using libfuzzer, klee, and legup to validate hardware designs. 07 2020.
14. [Cybnd] Cybersecurity and Infrastructure Security Agency. Cisa. https://www.cisa.gov/, n.d. https://www.cisa.gov/.
15. [ea24] Erik Andersen et al. BusyBox: The Swiss Army Knife of Embedded Linux, 2024. Accessed: 2024-06-16.
16. [Fou24] Free Software Foundation. GNU Core Utilities, 2024. Accessed: 2024-06-16.
17. [Git24] GitHub Blog. Codeql zero to hero part 1: the fundamentals of static analysis for vulnerability research. 2024. Accessed: 2023-07-19.
18. [GLM08] Patrice Godefroid, Michael Y. Levin, and David Molnar. Automated white box fuzz testing. In Proceedings of the Network and Distributed System Security Symposium (NDSS), pages 151–166, 2008.
19. [Hel24] Aki Helin. Radamsa. https://gitlab.com/akihe/radamsa, 2024. Accessed:2024-05-14.
20. [Joh78] Stephen C. Johnson. Lint, a c program checker. Bell Laboratories, 1978.
21. [KLE23] KLEE. Klee documentation. https://klee.github.io/docs/, 2023.
22. [LLV] LLVM Project. Libfuzzer - a library for coverage-guided fuzz testing. https://llvm.org/docs/LibFuzzer.html. Accessed: 2024-01-21.
23. [LLV24] LLVM Project. The LLVM Compiler Infrastructure, 2024. Available at https://llvm.org/.
24. [LMS+19] Yuancheng Li, Longqiang Ma, Liang Shen, Junfeng Lv, and Pan Zhang. Opensource software security vulnerability detection based on dynamic behavior features. Plos one, 14(8): e0221530, 2019.
25. [Maynd] Mayhem. Mayhem. https://www.forallsecure.com/mayhem, n.d. https://www.forallsecure.com/mayhem.
26. [Ope20] OpenSSL Project. Vulnerabilities found using libfuzzer. OpenSSL Security Blog, 2020.
27. [Opend] Open Web Application Security Project. Owasp. https://owasp.org/, n.d. https://owasp.org/.
28. [PKS+12] Jimmy Pak, Theodore Kern, Fabio Somenzi, Daniel W. Holcomb, Kevin Fu, and Wayne P. Burleson. Hybrid fuzz testing of cots firmware for critical embedded systems. In Proceedings of the International Conference on High Confidence Networked Systems (HiCoNS), pages 79–88, 2012.
29. [Ser24] Kostya Serebryany. Libfuzzer – a library for coverage-guided fuzz testing. https://llvm.org/docs/LibFuzzer.html, 2024. Accessed: 2024-05-14.
30. [SGS+16] N. Stephens, R. Grosen, C. Salls, A. Dutcher, J. Grosen, S. Rawat, P. T. Devanbu, F. Shokri, A. Austin, K. Kushyk, R. Hu, M. Zamani, A. Qadeer, D. Brumley, and J. Davis. Driller: Augmenting fuzzing through selective symbolic execution. In Proceedings of the Network and Distributed System Security Symposium (NDSS), 2016.
31. [sqlnd] SQLite-amalgamation-3450100 r. https://sqlite.org/2023/sqlite-amalgamation-3450100.zip, n.d. https://sqlite.org/2023/sqlite-amalgamation-3450100.zip.
32. [Sto23] Stony Brook Computer Science. Vulnerability discovery. https://www3.cs.stonybrook.edu/~mikepo/CSE509/2023/lectures/CSE509_
33. 2023_lecture_09_fuzzing.pdf, 2023.
34. [Swi24] Robert Swiecki. honggfuzz. https://github.com/google/honggfuzz, 2024. Accessed: 2024-05-14.87
35. [SWS+16] Y. Shoshitaishvili, R. Wang, C. Salls, N. Stephens, M. Polino, A. Dutcher, J. Grosen, S. Feng, C. Hauser, C. Kruegel, and G. Vigna. Sok: (state of) the art of war: Offensive techniques in binary analysis. In IEEE Symposium on Security and Privacy (SP), pages 138–157, 2016.
36. [Syn24] Synopsys, Inc. Coverity Static Analysis, 2024. Available at https://www.synopsys.com/software-integrity/security-testing/static-analysis-sast.html.
37. [Tea24] SymPy Development Team. Sympy: Python library for symbolic mathematics. https://www.sympy.org/, 2024. Accessed: 2024-05-14.
38. [TK21] Chi Thien Tran and Shamil Kurmangaleev. Futag: Automated fuzz target generator for testing software libraries. In 2021 Ivannikov Memorial Workshop (IVMEM), pages 80–85. IEEE, 2021.
39. [Zal16] M. Zalewski. Afl: American fuzzy lop. Fuzzing Project, 2016. Accessed: 2024-05-14.
40. [ZBWKM06] Nickolai Zeldovich, Silas Boyd-Wickizer, Eddie Kohler, and David Mazières. Making information flow explicit in histar. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation (OSDI), pages 263–278, Berkeley, CA, USA, 2006. USENIX Association.
9. ضمایم
9.1 نصب KLEE
KLEE یک ابزار اجرای نمادین است که مستلزم LLVM و Clang است. مراحل زیر فرآیند نصب را مشخص میکنند:
- نصب پیشنیازها: اطمینان حاصل کنید که سیستم شما ملزومات مورد نظر را نصب دارد . این گام برای ارائه کتابخانهها و ابزارهای مورد نیاز برای ساخت کلی و LLVM ضروری است .
sudo apt-get update
sudo apt-get install -y build-essential curl python3 cmake
2. LLVM و Clang را دانلود و نصب کنید. این ابزارها برای کامپایل برنامه و KLEE مورد نیاز میباشند.
git clone https://github.com/llvm/llvm-project.git
cd llvm-project
mkdir build
cd build
cmake -DLLVM_ENABLE_PROJECTS=clang -G "Unix␣Makefiles" ../llvm
make
sudo make install
4. برنامه مورد نظر را توسط KLEE کامپایل کنید:
- اطمینان حاصل نمایید که برنامه مورد نظر توسط C یا ++C نوشته شده است.
- از clang برای کامپایل برنامه توسط ابزار KLEE استفاده کنید.
clang -I /path/to/klee/include -emit-llvm -c -g program.c
# ======= KLEE Dependencies ===========
# This installs packages we need
sudo apt-get update
sudo apt-get -y upgrade
sudo pip3 install lit wllvm
sudo apt-get -y install python3-tabulate
# then
sudo apt-get update
sudo apt-get -y install clang-13 llvm-13 llvm-13-dev llvm-13-tools
# ====== End KLEE Dependencies ==========
# ========== Constraint solver STP ===========
# ==== Dependencies for STP ====
sudo apt-get -y install cmake bison flex libboost-all-dev perl minisat
# === Install STP
git clone https://github.com/stp/stp
cd stp
git submodule init && git submodule update
./scripts/deps/setup-gtest.sh
./scripts/deps/setup-outputcheck.sh
mkdir build
cd build
cmake ..
cmake --build .
sudo cmake --install .
# ========== End Install STP =====
# The following line is needed to run klee with stp
ulimit -s unlimited
# ===== Install Google Test ====
cd ~/Research/klee-home
git clone https://github.com/stp/stp.git
curl -OL https://github.com/google/googletest/archive/release-1.11.0.zip
unzip release-1.11.0.zip
# =================
# Install klee-uclib
#=====================
cd ~/Research/klee-home
git clone https://github.com/klee/klee-uclibc.git
cd klee-uclibc
./configure --make-llvm-lib
# --with-cc path-to-clang-13 --with-llvm-config path-to-llvm-config-13
# In the following -j2 says use 2 cores to build. You can use more if you have them
make -j2
cd ..
# Install clang-13 deb package:
sudo apt-get -y install clang-13 llvm-13 llvm-13-dev llvm-13-tools
############## NOW KLEE ###############
## First KLEE UCLIB ###
git clone https://github.com/klee/klee-uclibc.git
cd klee-uclibc
./configure --make-llvm-lib --with-cc clang-13 --with-llvm-config llvm-config-13
make -j2
cd ..
############
## Now KLEE itself
## We have to be careful it uses the right version of clang everywhere.
git clone https://github.com/klee/klee.git
cd klee
mkdir build
cd build
export LLVM_COMPILER=clang
export LLVM_CC_NAME=clang-13
export LLVM_CXX_NAME=clang++-13
export CC=clang-13
export CXX-clang++-13
cmake -DENABLE_SOLVER_STP=ON -DENABLE_POSIX_RUNTIME=ON CLIBC_PATH=/path/klee-uclib -DENABLE_UNIT_TESTS=ON -DGTEST_SRC_DIR=/path/googletest-release-1.11.0 -DLLVM_DIR=/usr/lib/llvm-13 /path/klee
make -j2
make -j2 systemtests
make -j2 unittests
## My tests passed
sudo make install
/**Test Harness for Klee*/
#include
#include
#include
#include
#include
// Callback function for sqlite3_exec() to display query results
static int callback(void *NotUsed, int argc, char **argv, char ** azColName) {
for (int i = 0; i < argc; i++) {
printf("%s␣=␣%s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
// Function to check SQLite return code and handle errors
void check_sqlite_result(int rc, sqlite3 *db) {
if (rc != SQLITE_OK && rc != SQLITE_DONE) {
printf("SQLite␣error:␣%s\n", sqlite3_errmsg(db));
sqlite3_close(db);
exit(rc);
}
}
int main() {
sqlite3 *db;
char *errMsg = 0;
int rc;
// Initialize a new in-memory database
rc = sqlite3_open(":memory:", &db);
// Create a table
rc = sqlite3_exec(db, "CREATE␣TABLE␣a(b,c);", callback, 0, &errMsg);
// Prepare an INSERT statement
sqlite3_stmt *stmt;
// const char *sqlInsert = "INSERT INTO items (name, quantity) VALUES (?, ?);";
// rc = sqlite3_prepare_v2(db, sqlInsert, -1, &stmt, NULL);
// Create symbolic values for name and quantity
char symbolicName[10];
int symbolicQuantity;
klee_make_symbolic(&symbolicName, sizeof(symbolicName), "symbolicName");
symbolicName[sizeof(symbolicName) - 1] = ’\0’; // Ensure null termination
klee_make_symbolic(&symbolicQuantity, sizeof(symbolicQuantity), "symbolicQuantity");
// Bind symbolic values to the statement
sqlite3_bind_text(stmt, 1, symbolicName, -1, SQLITE_TRANSIENT);
sqlite3_bind_int(stmt, 2, symbolicQuantity);
// Execute the INSERT statement
rc = sqlite3_step(stmt);
// Reset the statement to use it again
sqlite3_reset(stmt);
// Execute a SELECT query to retrieve data
const char *sqlSelect = "SELECT␣c␣FROM␣a␣GROUP␣BY␣c␣HAVING(SELECT␣(sum(b)␣OVER(ORDER␣BY␣b),␣sum(b)␣OVER(PARTITION␣BY␣min(DISTINCT␣c),␣c␣ORDER␣B)));";
rc = sqlite3_exec(db, sqlSelect, callback, 0, &errMsg);
if (rc != SQLITE_OK) {
printf("SQL␣error:␣%s\n", errMsg);
sqlite3_free(errMsg);
}
//close the database
sqlite3_close(db);
return 0;
}
9.2 نصب LibFuzzer
LibFuzzer بخشی از پروژه LLVM است. گام های زیر را جهت نصب LibFuzzer طی کنید. اطمینان حاصل نمایید که یک نسخه سازگار LLVM با سیستم خود را نصب کردهاید.
الزامات نصب: اطمینان حاصل کنید که وابستگیهای مورد نیاز روی سیتم نصب شده است (مانند KLEE).
LLVM و LibFuzzer را دانلود و بیلد کنید.
git clone https://github.com/llvm/llvm-project.git
cd llvm-project
mkdir build
cd build
cmake -DLLVM_ENABLE_PROJECTS="libFuzzer" -G "Unix␣Makefiles" ../llvm
make
sudo make install
برنامه مورد نظر را توسط LibFuzzer کامپایل کنید:
clang -fsanitize=fuzzer,address -o fuzzer fuzzer.c
/**Test harness for libFuzzer*/
#include
#include
#include
// Callback function for sqlite3_exec() to display query results
static int callback(void *NotUsed, int argc, char **argv, char **
azColName) {
for (int i = 0; i < argc; i++) {
printf("%s␣=␣%s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
// Function to check SQLite return code and handle errors
void check_sqlite_result(int rc, sqlite3 *db) {
if (rc != SQLITE_OK && rc != SQLITE_DONE) {
printf("SQLite␣error:␣%s\n", sqlite3_errmsg(db));
sqlite3_close(db);
exit(rc);
}
}
Fuzzing entry point
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size < 4) return 0; // Ensure there’s enough data for at least one int
sqlite3 *db;
char *errMsg = 0;
int rc;
// Initialize a new in-memory database= sqlite3_open(":memory:", &db);
// Create a table
rc = sqlite3_exec(db, "CREATE␣TABLE␣a(b,c);", callback, 0, &errMsg);
// Prepare an INSERT statement
sqlite3_stmt *stmt;
// const char *sqlInsert = "INSERT INTO items (name, quantity)
VALUES (?, ?);";
// if (sqlite3_prepare_v2(db, sqlInsert, -1, &stmt, NULL) !=SQLITE_OK) goto cleanup;
int quantity = *(const int*)data;
data += sizeof(int);
size -= sizeof(int);
sqlite3_bind_text(stmt, 1, (const char*)data, size, SQLITE_TRANSIENT); // Use the remaining data as text
sqlite3_bind_int(stmt, 2, quantity);
// Execute the INSERT statement
sqlite3_step(stmt);
// Reset the statement to use it again
sqlite3_reset(stmt);
// Execute a SELECT query to retrieve data
const char *sqlSelect = "SELECT␣c␣FROM␣a␣GROUP␣BY␣c␣HAVING(SELECT␣(sum(b)␣OVER(ORDER␣BY␣b),␣sum(b)␣OVER(PARTITION␣BY␣min(DISTINCT␣c),␣c␣ORDER␣B)));";
if (sqlite3_exec(db, sqlSelect, callback, 0, &errMsg) != SQLITE_OK){
sqlite3_free(errMsg);
}
sqlite3_finalize(stmt);
cleanup:
// Close the database
sqlite3_close(db);
return 0;
}