")
چکیده
مقاله «BertRLFuzzer: A BERT and Reinforcement Learning Based Fuzzer» یک ابزار نوآورانه برای کشف آسیب پذیریهای امنیتی در برنامههای وب معرفی میکند که براساس ترکیب مدل زبانی BERT و یادگیری تقویتی (RL) طراحی شده است. عملکرد BertRLFuzzer به این صورت است که با دریافت فهرستی از ورودیهای اولیه (seed inputs)، عملیات جهش (mutation) را بر روی آنها انجام میدهد بهگونهای که هم با دستور زبان (grammar) سازگار باشد و هم باعث تحریک حمله شود، تا بردارهای حمله کاندید تولید کند. بینش کلیدی BertRLFuzzer، استفاده ترکیبی از دو مفهوم یادگیری ماشین است. اولی استفاده از یادگیری نیمهنظارتشده همراه با مدلهای زبانی (مانند BERT) است که به BertRLFuzzer امکان میدهد بخشهای مرتبط گرامری برنامه هدف و الگوهای حمله را بیاموزد، بدون اینکه کاربر نیاز داشته باشد آنها را صریحاً مشخص کند. دومی استفاده از یادگیری تقویتی است که مدل BERT را بهعنوان یک عامل (agent) بهکار میگیرد تا فازر را در یادگیری مؤثر عملگرهای جهشِ همراستا با دستور زبان و تحریککننده حمله هدایت کند. حلقه بازخورد هدایتشده توسط RL به BertRLFuzzer اجازه میدهد فضای بردارهای حمله را بهطور خودکار جستجو کند و ضعفهای برنامه هدف را بدون نیاز به ساخت داده برچسبخورده آموزشی، بهرهبرداری (exploit) نماید. افزون بر این، این دو ویژگی در کنار هم باعث میشوند BertRLFuzzer قابل توسعه باشد؛ یعنی کاربر میتواند BertRLFuzzer را بهصورت خودکار (بدون اصلاح صریح فازر یا ارائه دستور زبان) برای انواع مختلف برنامههای هدف و بردارهای حمله توسعه دهد.
محققان به منظور سنجش اثربخشی BertRLFuzzer، آن را در برابر مجموعاً ۱۳ فازر جعبه سیاه و جعبه سفید آزمایش و بررسی کردهاند: ۷ فازر جعبه سیاه مبتنی بر یادگیری ماشین (DeepSQLi, DeepFuzz, DQN fuzzer، نسخههای اصلاحشده DeepXSS, DeepFix, GRU-PPO, Multi-head DQN)، ۳ فازر سازگار با گرامر (BIOFuzz, SQLMap, baseline mutator)، یک فازر جعبه سفید ( Ardilla)، یک تغییردهنده تصادفی و یک فازر تصادفی، بر روی مجموعهای از ۹ وبسایت هدف آزمایش شده است. محققان شاهد بهبود قابل توجهی از نظر زمان تا اولین حمله (۵۴٪ کمتر از نزدیکترین ابزار رقابتی)، زمان برای یافتن تمام آسیبپذیریها (۴۰–۶۰٪ کمتر از نزدیکترین ابزار رقابتی)، و نرخ حمله (۴.۴٪ بردار حمله تولیدشده بیشتر نسبت به نزدیکترین ابزار رقابتی) بودهاند. نتایج آزمایشهای آنها حاکی از آن است که ترکیب مدل BERT و یادگیری مبتنی بر RL، میتواند BertRLFuzzer را به یک فازر مؤثر، تطبیقپذیر، آسان برای استفاده، خودکار و قابل توسعه تبدیل کند.
مقدمه
در چند دهه اخیر، رشد چشمگیری در تعداد و پیچیدگی برنامههای تحت وب مشاهده شده است که در کنار آن، میزان و تنوع آسیب پذیریهای امنیتی نیز بهطور قابلتوجهی افزایش یافته است، از جمله حملات شناختهشدهای نظیر SQL Injection، XSS و CSRF. پژوهشگران در واکنش به این چالش، مجموعهای از ابزارهای فازینگ پیشرفته را توسعه دادهاند که بسته به روش تحلیل، از فازرهای مبتنی بر جهش تصادفی (مانند AFL گوگل)، تا فازرهای جعبهسیاه سازگار با گرامر[1] و حتی فازرهای جعبهسفید مبتنی بر SMT solver ها (مانند Ardilla) را دربرمیگیرند.
یک مسئله رایج برای توسعهدهندگان این است که فازِرها اغلب باید از گرامر یا دستور زبان ورودی آگاه باشند، بهویژه هنگام فازینگ برنامههایی که گرامر ورودیشان پیچیده است. تعریف صریح دستور زبان و بهروزرسانی آن برای هر کلاس جدید از آسیب پذیری، وقتگیر و مستعد خطا میباشد. علاوه بر این، ابزارهای فازر کنونی به سختی میتوانند بدون ایجاد تغییر دستی به انواع جدید آسیب پذیریها گسترش یابند. بهعبارتدیگر، طراحی فازرهای فعلی معمولاً خودکار و قابلگسترش نیست و نیاز به مداخله انسانی دارد.
توسعه فازِرهای آگاه از دستور زبان، فرآیندی زمانبر و پرخطا میباشد؛ زیرا توسعهدهندگان فازِر باید صریحاً دستور زبان ورودیِ برنامه هدف را فراهم کنند و خودِ فازِر را بر اساس آن تغییر یا توسعه دهند. این مسئله زمانی که بخواهند فازِر را برای برنامههای مختلف مجددا هدفگیری کنند، بسیار دشوار خواهد بود.
مشکل دیگری که وجود دارد این است که حتی اگر برای یک برنامه مشخص، فازِرِ آگاه از دستور زبان در اختیار داشته باشیم، ممکن است هرگاه کلاسهای جدیدی از آسیب پذیریها کشف شوند، نیاز به تغییر فازِر نیز پدید آید. برای مثال، فازِری که برای کشف آسیب پذیری SQL Injection در یک برنامه وب طراحی شده باشد، در تشخیص آسیبپذیریهای XSS کارآمد نخواهد بود. به عبارت سادهتر، فازِرهای امروزی بهراحتی قابل توسعه بهمنظور پشتیبانی گرامر-محور از کلاسهای جدیدِ برنامهها و آسیب پذیریها نیستند. به بیان ساده تر ساده، فازرهای امروزی بهگونهای طراحی نشدهاند که بتوان آنها را بهراحتی و بهشکل آگاه از دستور زبان (grammar-aware) برای کلاسهای جدیدی از برنامهها و آسیبپذیریها گسترش داد.
بیان مسئله
بهطور دقیقتر، مسئلهای که در این مقاله به آن پرداخته شده است، ایجاد یک فازر برای برنامههای وب است که بهعنوان ورودی، یک برنامه هدف و مجموعهای از ورودیهای اولیه (seed inputs) را دریافت میکند و بهعنوان خروجی یک عملگر جهش (mutation operator) تولید مینماید که این ورودیها را به بردار حمله برای برنامه مشخص تبدیل میکند — بهصورتی که قابل توسعه، منطبق با دستور زبان (grammar-adherent) و کاملاً خودکار باشد.
در واقع فازر میبایست ویژگیهای زیر را داشته باشد:
- نخست، سیستم باید قابل توسعه باشد؛ یعنی کاربر بتواند آن را با حداقل تلاش انسانی و یا بدون تلاش (مثلاً از طریق یادگیری از دادهها) برای انواع مختلف بردارهای حمله و برنامههای هدف توسعه دهد.
- دوم، باید مطابق با گرامر باشد؛ یعنی رشتههای خروجی تولیدشده توسط فازر باید با دقت بالا مطابق گرامر ورودی برنامه هدف باشند، بدون اینکه از کاربر خواسته شود گرامر ورودی برنامه هدف را ارائه دهد.
- سوم، فازر باید کاملاً خودکار باشد؛ یعنی عملیات جهش جدید را بدون ارائه دادهء برچسبگذاری شده و بدون اینکه انسان کد فازر را تغییر دهد، بیاموزد یا تولید کند (توجه: بهتعریف، فازرهای نگارششده توسط انسان که مطابق گرامر هستند، بهطور خودکار عملیات جهش جدید را نمیآموزند).
- چهارم، فازر باید کارا و مؤثر باشد؛ یعنی زمان تا اولین حمله باید کم باشد (کارایی) و نرخ حمله نسبت به ابزارهای پیشرفته دیگر بالاتر باشد (اثربخشی).
یادگیری ماشین برای فازینگ
در سالهای اخیر، شاهد روند رو به رشدی از تقویت تکنیکهای فازینگ سنتی برنامههای وب با روشهای یادگیری ماشین ML بودهایم که طیف وسیعی از روشهای آموزش ML را در بر میگیرد — از یادگیری نظارتشده (Liu, Li, and Chen 2020) تا روشهای یادگیری تقویتی (RL) (Böttinger, Godefroid, and Singh 2018). فازرهای مبتنی بر ML نسبت به فازرهای غیر ML چند مزیت مهم دارند. برای مثال، روشهای فازینگ مبتنی بر RL سازگار هستند، یعنی میتوان آنها را بهسادگی تنظیم کرد تا انواع مختلفی از بردارهای حمله را کاوش کنند و خود را با گونههای متفاوتی از برنامههای هدف وفق دهند (Scott et al. 2021). مزیت دیگر این است که فازرهای مبتنی بر ML میتوانند الگوهای پیچیده بردارهای حمله را بیاموزند که ممکن است برای انسان سختتشخیص باشند و دشوار باشد آنها را بهصورت ثابت در فازر غیر ML کدنویسی کرد. از سوی دیگر، فازرهای مبتنی بر ML که بر یادگیری نظارتشده تکیه دارند معایبی نیز دارند؛ مثلاً ممکن است برای شناسایی دقیق الگوهایی که قابلیت تبدیلشدن به عملگرهای جهش را دارند، به مجموعهٔ بزرگی از دادههای آموزشی برچسبخورده از بردارهای حمله نیاز داشته باشند. در نهایت، مشکل سنتیِ سازگار ساختن عملگرهای جهش با گرامر، همچنان در مورد فازرهای جهش مبتنی بر ML ارائهشده تاکنون وجود دارد. بسته به نوع برنامه هدف و پیچیدگی گرامرهای ورودی آنها، تعیین چنین گرامرهایی میتواند پرهزینه، مستعد خطا و زمانبر باشد. ترجیح این است که فازرها از روی دادهها که شامل گرامر برنامه هدف و الگوهای بردار حملهای که احتمال موفقیتشان بیشتر است، بیاموزند.
مروری کوتاه بر BertRLFuzzer
پژوهشگران به منظور پاسخ به این چالشها، BertRLFuzzer را معرفی کردند، یک فازر مبتنی بر BERT (مخفف «نمایش رمزگذار دوجهتی از تبدیلکنندهها»، بخشی از ابزارهای قدرتمند پردازش زبان طبیعی مانند ChatGPT (OpenAI 2023)) و فازر مبتنی بر (RL). برخلاف فازرهای سنتی مبتنی بر ML و غیر ML، BertRLFuzzer تمامی ویژگیهای ذکرشده را داراست؛ یعنی این ابزار خودکار، قابل توسعه، منطبق با گرامر است و همانطور که نتایج آزمایشهای پژوهشگران نشان میدهند، کارا و مؤثر نیز میباشد.
ورودی و خروجی BertRLFuzzer:
ابزار BertRLFuzzer ، یک برنامه قربانی و لیستی از ورودیهای seed با پایبندی به گرامر را از یک مولد seed به عنوان ورودی دریافت میکند این ورودیها نمونههایی از یک کلاس شناختهشده از آسیبپذیریها هستند) و بهعنوان خروجی یک بردار حمله جدید ارائه میدهد که هدف آن آشکار کردن آسیب پذیریهای امنیتی قبلاً ناشناخته در برنامه هدف است.
چرا از مدل BERT استفاده کنیم؟
همانطور که پیشتر اشاره شد، شناساندن گرامر به فازرها بهصورت سنتی فرآیندی پرهزینه و نیازمند نیروی کار بوده است، بهویژه هنگام هدفگیری مجدد فازرها برای برنامهها و الگوهای بردار حمله مختلف. خوشبختانه، ظهور مدلهای زبانی (LM) در سالهای اخیر فرصت بسیار خوبی برای حل این مسئله چند دههای در اختیار ما قرار داده است. دلیل این امر این است که ثابت شده مدلهای زبانی بدون نیاز به مشخصکردن صریح گرامرها، ظرفیت شگفتآوری برای یادگیری گرامر زبانهای برنامهنویسی — تنها از روی بخشهایی از کد — دارند. بر اساس این مشاهدات، بینش کلیدی در کار ما این است که یک فازر تقویتشده با مدل زبانی میتواند بهصورت خودکار گرامرِ (قابلتوجهِ) برنامه هدف و بردارهای حمله را از دادهها (یعنی مجموعهای از بردارهای حمله یا ورودیهای اولیه که مطابق گرامر هستند) بیاموزد. این رویکرد، پتانسیل رفع یکی از مشکلات عمدهای را دارد که توسعهدهندگان فازر طی دههها با آن مواجه بودهاند.
چرا از یادگیری تقویتی (RL) در فازینگ استفاده کنیم؟
توجه داشته باشید که صرفاً یادگیری گرامر برنامهء هدف (قربانی)، کافی نیست چرا که ممکن است هیچ آسیبپذیریِ جدیدی را در آن برنامه آشکار نکند. در مقابل، فازر باید ورودیهای اولیه را بهگونهای جهش دهد که احتمالاً آسیبپذیریهای تازهای را در برنامه هدف آشکار سازد. این یک مسئله دشوار جستوجو در فضای نمایی بزرگی از ورودیهای برنامه هدف است. به عنوان مثال، یک رویکرد سادهانگارانه، اصلاح ورودی اولیه به شیوهای مطابق با دستور زبان، با تمام ترکیبات ممکن از یک الگوی بردار حمله است؛ اما چنین رویکردی دچار انفجار ترکیبی میشود.
یک رویکرد بهتر، استفاده از تکنیکهای جستجوی اکتشافی، مانند ادبیات یادگیری تقویتی RL است که هدف آن، تمرکز مؤثر بر آسیب پذیریهای برنامه قربانی است. به طور خلاصه، مزیت یک تکنیک یادگیری تقویتی RL که به درستی طراحی شده باشد این است که اغلب میتواند یک الگوی بردار حمله را که مختص یک برنامه قربانی مشخص است، کشف کرده و یاد بگیرد و این کار را به طور کارآمد و کاملاً خودکار انجام دهد. بر اساس این اصل کلی، BertRLFuzzer دارای یک عامل حالتدار RL است که یک عملگر جهش (یعنی دنبالهای از عملیات که یک ورودی مناسب و مطابق گرامر را دریافت کرده و آن را برای برنامه هدف به یک بردار حمله تبدیل میکند) را یاد میگیرد. از آنجایی که این یادگیری از طریق بازخورد از برنامه قربانی مشخص (که ممکن است حاوی پاککنندههای عبارات منظم برای محافظت از برنامه باشد) رخ میدهد، BERTRLFUSZER قادر است نقاط ضعف موجود در برنامه مذکور را، در صورت وجود، پیدا کند. عملگرهای جهشی که از طریق یادگیری تقویتیRLدر BERTRLFuzzer آموخته میشوند، آن را قادر میسازند تا به طور خودکار فضایی از بردارهای حمله را به روشی اکتشافی و مختص به برنامه قربانی، بدون هیچ گونه دخالت انسانی، کاوش کند و BERTRLFuzzer را به صورت خودکار اجرا کند.
ادغام BERT و یادگیری تقویتی (RL) در BertRLFuzzer:
در BertRLFuzzer، یک مدل BERT از پیشآموزشدیده (آموزشدیده روی ورودیهای اولیه برنامه هدف، و بدینترتیب قادر به یادگیری گرامر آن برنامه و الگوهای حمله) بهعنوان عامل در یک حلقه یادگیری تقویتی (RL) که با برنامه هدف در تعامل است، عمل میکند. این حلقه RL به نوبه خود به BertRLFuzzer امکان میدهد تا دقیقاً آن گونه جهشها را پیدا کند که احتمالاً بهطور زیادی میتوانند آسیبپذیریهای امنیتی در برنامه هدف را افشا کنند.
قابلیتِ مدلهای BERT در یادگیری نمایشِ گرامرها همچنین این امکان را به BertRLFuzzer میدهد که بهسادگی قابلتوسعه باشد؛ یعنی با مجموعهدادهای مناسب از ورودیهای اولیه بدون برچسب، کاربر میتواند مدل BERT را دوباره آموزش دهد تا یک کلاس جدید از عملگرهای جهش برای یک برنامه هدف مشخص تولید کند. سپس حلقه RL این مدل از پیشآموزشدیده BERT را با استفاده از برنامه هدف، عملگرهای جهش و مکانیزم پاداش بهصورت دقیقتر تنظیم میکند تا با جستجو در فضای ورودیها، یک کلاس جدید از بردارهای حمله را برای آن برنامه تولید نماید. نکته جذاب این رویکرد آن است که کاربر نیازی به رمزگذاری یا تعریف صریح گرامر الگوهای حمله ندارد — تمام این امور بهصورت خودکار با بهکارگیری مدل BERT و یک حلقه RL طراحیشده مناسب انجام میشود.
استفاده از یادگیری تقویتی برای شبیهسازی رفتار یک مهاجم تطبیقی اکنون بهطور گستردهای پذیرفته شده است. با این حال، تا جایی که ما میدانیم، بهکارگیری مدل BERT بهعنوان یک عامل در حلقه RL داخل یک فازر نوآورانه است. این انتخاب تضمین میکند که عامل RL فازر ما بر اساس نحو و معناهای آموختهشده — درست مانند یک هکر — قضاوتهای مناسبی انجام دهد (و در نتیجه فضای جستوجو را تقلیل دهد)، بهجای آنکه جهشهای تصادفی پیشنهاد کند که ممکن است تضمینکننده سازگاری رشتههای خروجی با گرامر نباشند.
پژوهشگران به منظور ارزیابی صحیح شایستگی علمی ایدههای خود، یک مقایسه تجربی گسترده و کامل از BERTRLFUSZER با ۱۳ فازر دیگر مبتنی بر جعبه سیاه، جعبه سفید، مبتنیبر ML و غیر‑ML بر روی یک معیار گزینشی از ۹ برنامه وب قربانی که اندازه آنها از چند صد تا ۱۶ هزار خط کد متغیر است، انجام دادند. آنها از طریق سوالات تحقیقاتی خود، نشان دادند که BERTRLFUSZER تمام ویژگیهای مورد نیاز از یک فازر مبتنی بر یادگیری ماشینی مدرن، مؤثر، کارآمد، مطابق با دستور زبان، قابل توسعه و خودکار را دارا میباشد.
مشارکتها
- پژوهشگران BertRLFuzzer را معرفی کردند؛ یک فازر جدید برای برنامههای وب مبتنی بر BERT و یادگیری تقویتی که ویژگیهای زیر را داراست: خودکار (عملگرهای جهش را بدون کمک انسانی میآموزد)، قابلتوسعه (قابل بسط به کلاسهای جدیدی از آسیبپذیریها و برنامههای هدف)، منطبق با گرامر (بردارهای حمله خروجی با دقت بالا مطابق گرامر برنامههای هدف هستند)، مؤثر (توانایی کشف تعداد بیشتری از آسیبپذیریهای امنیتی نسبت به ابزارهای پیشرفته رقیب) و کارا (زمان تا اولین حمله کم است). پژوهشگران مدعی هستند در زمان نگارش مقاله، هیچ فازر مبتنی بر یادگیری ماشین دیگری از معماری BERT و الگوریتم مبتنی بر RL برای حل مسئله فوقالذکر استفاده نمیکند.
- پژوهشگران یک ارزیابی تجربی گسترده از BertRLFuzzer را به انجام رساندند و آن را در برابر مجموعاً ۱۳ فازر جعبه سیاه و جعبه سفید مقایسه کردند: ۷ فازر جعبه سیاه مبتنی بر یادگیری ماشین (DeepSQLi، DeepFuzz، فازر DQN، نسخههای اصلاحشده DeepXSS، DeepFix، GRU-PPO، DQN)، ۳ فازر پایبند به گرامر (BIOFuzz، SQLMap، تغییردهنده خط پایه)، یک فازر جعبه سفید Ardilla، یک تغییردهنده تصادفی پایه و یک فازر تصادفی پایه. آنها اثربخشی و کارایی BertRLFuzzer را روی یک بنچمارک شامل ۹ وبسایت هدف تا سقف ۱۶ هزار خط کد اعتبارسنجی کردند. در مجموعهای از وبسایتهای بنچمارک دنیای واقعی، بهبود قابل توجهی از نظر زمان اولین حمله (۵۴٪ کمتر از نزدیکترین ابزار رقیب)، زمان یافتن همه آسیبپذیریها (۴۰-۶۰٪ کمتر از نزدیکترین ابزار رقیب) و نرخ آسیبپذیریهای یافت شده (۴.۴٪ بیشتر از نزدیکترین ابزار رقیب) در انواع وبسایتهای معیار دنیای واقعی مشاهده گردید.
پیشزمینه
مدلهای ترنسفورمر و BERT:
مدلهای مبتنی بر ترنسفورمر (مبدل) از اجزای کلیدی در مدلهای بسیار موفق پردازش زبان طبیعی (NLP) بهشمار میروند، مانند GPT-3 (Brown et al. 2020)، ChatGPT (OpenAI 2023) و PALM از گوگل (Chowdhery et al. 2022). در سالهای اخیر، این مدلها با موفقیت در حوزه زبانهای برنامهنویسی رسمی نیز بهکار گرفته شدهاند، از جمله در زمینه ترجمه کد، تولید یا سنتز کد، درک کد و تحلیل معنایی آن.
مدلهای BERT (مخفف Bidirectional Encoder Representations from Transformers) بر پایه معماری ترنسفورمر ساخته شدهاند. مدلهای BERT رشتههای متنی را که از یک الفبای محدود تشکیل شدهاند بهعنوان ورودی دریافت کرده و آنها را به یک نمایش برداریشده تبدیل میکنند (به منظور دریافت جزئیات بیشتر، خواننده میتواند به مقاله Bommasani و همکاران (Bommasani et al. 2021) برای مرور جامعی از مدلهای BERT مراجعه کند، و همچنین به منابع اصلی Devlin et al. (2018) و Liu et al. (2019b) رجوع نماید).
یادگیری تقویتی (Reinforcement Learning – RL):
در حوزه یادگیری تقویتی و الگوریتم بهینهسازی سیاست مجاور (Proximal Policy Optimization – PPO) منابع گستردهای وجود دارد، و برای مطالعه بیشتر میتوان به کتاب Sutton و Barto (2018) مراجعه کرد. شبکه Q عمیق (DQN) یک الگوریتم یادگیری تقویتی حالتمند است که از شبکههای عصبی عمیق برای تقریب تابع مقدار Q یعنی پاداش بلندمدت مورد انتظار بهینه استفاده میکند و امکان تخمین اقدام بهینه برای انجام در یک حالت معین را فراهم میکند.PPO روشهای مبتنی بر ارزش و مبتنی بر سیاست را برای بهینهسازی سیاستها با استفاده از یک رویکرد بهینهسازی منطقه اعتماد برای بهروزرسانی آنها به سمت اقدامات بهتر، ترکیب میکند. Multi-Arm Bandit (MAB) یک الگوریتم یادگیری تقویتی بدون حالت است که شامل ایجاد تعادل بین کاوش گزینههای مختلف (بازوها) با بهرهبرداری از گزینههای شناخته شده و با پاداش بالا به منظور به حداکثر رساندن پاداش تجمعی در طول زمان است.
فازینگ نرمافزار (Software Fuzzing):
فازینگ نرمافزار یکی از حوزههای گسترده، تأثیرگذار و فعال در مهندسی نرمافزار است. این حوزه نقش مهمی در کشف آسیبپذیریهای امنیتی، آزمایش استحکام نرمافزار و بهبود کیفیت کد ایفا میکند. برای آشنایی جامعتر با پیشرفتهای اخیر و طبقهبندی روشهای مختلف فازینگ، خواننده میتواند به مرور جامع Manes و همکاران (2018) مراجعه کند. اصطلاحات و مفاهیمی که در این مقاله برای فازینگ بهکار رفتهاند، همگی مطابق با استانداردهای رایج در این حوزه هستند.
فازینگ منطبق با گرامر، الگوهای حمله، برنامه هدف:
در این مقاله اصطلاحات جدید زیر را معرفی میکنیم. عبارت فازر منطبق با گرامر به برنامهای کامپیوتری اشاره دارد که رشتهای را بهعنوان ورودی گرفته و رشتهای را تولید میکند که با گرامر برنامه هدف با دقت بالا انطباق دارد. توجه کنید که این تعریف غیرِاستاندارد است و هم فازرهای سنتیِ نوشتهشده توسط انسان که خطا ندارند و گرامر را حفظ میکنند را دربر میگیرد و هم فازرهای مبتنیبر ML را که ممکن است با دقت بالا نمایش مناسبی از گرامر برنامه هدف را بیاموزند. عبارت عملگر جهش منطبق با گرامر به برنامهای اطلاق میشود که رشته ورودی را بهگونهای تغییر میدهد که خروجی با دقت بالا مطابق گرامر برنامه هدف باشد. عبارت الگوی حمله به زیر رشتههایی از یک بردار حمله اشاره دارد (مثلاً الگوهای تاتولوژی در SQLi). ما از عبارت برنامه هدف بهعنوان مترادف application-under-test نیز استفاده میکنیم.
یک مورد استفاده جذاب از BERTRLFUSZER
یک مورد استفاده بسیار قوی از ابزار BertRLFuzzer مربوط به توسعهدهندگان برنامههای قربانی (برای مثال، برنامههای وب) است که ورودیهای آنها دارای گرامرهای پیچیده هستند و از سنیتایزرهایی (sanitizers) استفاده میکنند که ممکن است آسیبپذیریهای ناشناخته داشته باشند. در چنین شرایطی، توسعه یا بهروزرسانی فازرهای جهشمحورِ مبتنی بر گرامر که بهصورت دستی نوشته میشوند، میتواند بسیار پرهزینه باشد.
علاوه بر این، ممکن است توسعهدهندگان مجموعهای از ورودیهای نمونه برای یک دسته خاص از آسیبپذیریها را در اختیار داشته باشند، اما این مجموعه آزمایشی معمولاً جامع نیست؛ در نتیجه، ممکن است نمونههای جالب و متفاوتی از بردارهای حمله وجود داشته باشند که سنیتایزرها و/یا خود برنامه در برابر آنها مقاومتی ندارند و توسعهدهندگان از آنها بیاطلاع بمانند.
در سالهای اخیر، فازرهای جهشمحورِ سازگار با گرامر متعددی برای انواع مختلفِ برنامههای هدف و دستههای گوناگونِ آسیبپذیریهای امنیتی توسعه یافتهاند. با این حال، چنین ابزارهایی هر بار که یک کلاس جدید از آسیب پذیریهای امنیتی کشف شود یا هنگامی که برای یک کلاسِ پیشتر دیدهنشده از برنامههای هدف بازاستفاده شوند، نیاز به بازبرنامهریزی توسط انسان دارند. علاوه بر این، برنامههای هدف ممکن است توسط سنیتایزرهای خطاپذیر محافظت شوند که میتوانند به توسعهدهندگان وب احساس کاذب امنیت منتقل کنند. پیدا کردن ضعفها در اینگونه سنیتایزرها اهمیت ویژهای دارد، خصوصا اگر هدف ما بهبود امنیت کلیِ اکوسیستم وب باشد. فازرهای دستنویس باید بر اساس شناخت نقاط ضعفِ یک سنیتایزرِ مشخص تعدیل شوند؛ و هرگاه توسعهدهندگان آن سنیتایزرها را تغییر دهند، ممکن است آسیب پذیریهای جدیدی پدید آید که دوباره نیازمند اصلاحِ فازرهای دستی است. همه این فرآیندها میتواند بسیار وقتگیر و پرهزینه باشد.
یکی از راههای حل مسئلهای که بالاتر توصیف شد، استفاده از یک فازر جهشمحورِ سازگار با گرامر است که خودکار و قابلگسترش (تطبیقی) باشد تا بتواند بهطور خودکار با کلاسهای جدیدِ آسیب پذیری، برنامههای هدفِ جدید و سنیتایزرهای تازه سازگار شود. همچنین بسیار مهم است که این فازر خودکار باشد؛ یعنی بتواند بدون نیاز به دخالت انسانی، یک نمایش/برداشتِ مفید از گرامرِ برنامههای هدف و الگوهای حمله بیاموزد — بدون اینکه انسان مجبور باشد گرامرها یا تشخیصدهندههای الگو (مثلاً عبارات منظم) را صریحاً تعیین کند.
ابزار BertRLFuzzer تمام قابلیتهای لازم برای سناریوی فوق را فراهم میکند (جزییات معماری را ببینید — شکل ۲). BertRLFuzzer برای یک ترکیبِ مشخصِ برنامه قربانی/سنیتایزر، یک نمایشِ مفید از گرامر را میآموزد (مرهون کاربرد مدلهای BERT) و بدین ترتیب عملگرهای جهشسازِ پایبند به گرامر تولید میکند — که به نوبه خود تضمین میکند بردارهای حمله تولیدشده نیز با گرامر سازگاری داشته باشند. حلقه یادگیری تقویتی (RL) این امکان را به ابزار میدهد که نقاط ضعف برنامه قربانی را واکاوی کرده و بهصورت اکتشافی و کارآمد در میان انفجار ترکیبیِ گونههای ممکنِ یک کلاس از بردارهای حمله جستوجو کند تا نمونههایی را بیابد که احتمال موفقیت بالاتری دارند. ترکیبِ مدل BERT و حلقه RL فرایند را بهطور کامل خودکار میسازد. ابزار BERTRLFUSZER نهتنها به تغییراتِ ممکنِ یک کلاس خاص از بردارهای حمله مینگرد، بلکه بهسادگی میتواند — با داشتن مجموعه مناسبی از ورودیهای اولیه برای یادگیری — برای سایر کلاسهای آسیب پذیریهای امنیتی نیز سازگار و توسعه باشد.
مثالی از یک حمله
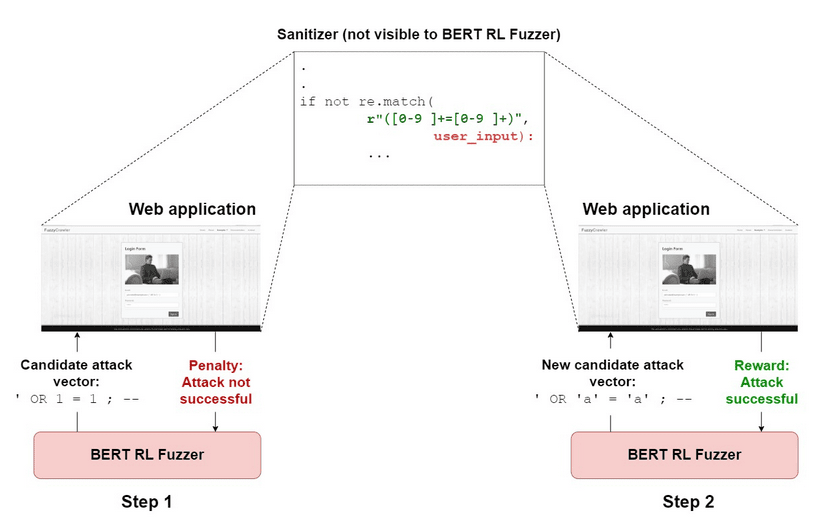
برای روشنتر شدن مطلب، مثال ساده شکل ۱ را در نظر بگیرید. یک وبسایتِ هدف برای وجود آسیب پذیری SQLi مورد بررسی قرار گرفته است. آن وبسایت دارای یک سنیتایزر تعریفشده توسط انسان است که ورودی کاربر را در برابر الگوی تاتولوژی — جایی که دو عدد برای برابری بررسی میشوند — رد میکند. BERTRLFUSZER بیخبر از این پاکسازی یا سنیتایزر در برنامه وب، یک بردار حمله کاندیدا تولید میکند: ’ OR 1 = 1 ; — ، پس از تغییر یک ورودیِ اولیه مشخص، این بردار به محیطِ آزمایشی ارسال میشود. همانطور که انتظار میرود، سنیتایزر آن ورودی را رد میکند و عامل یادگیری تقویتی (RL agent) بهخاطر انتخاب آن عملگر جهش، جریمه دریافت میکند. در گام بعدی، عامل RL یک عملگر جهش متفاوت را امتحان میکند: عبارت 1 = 1 را با ’a’ = ’a’ جایگزین میکند و بردار حمله جدید و سازگار با گرامر را تولید مینماید: ’ OR ’a’ = ’a’ ; — ، این بار، رشته ورودی توانایی عبور از سنیتایزر را دارد و حمله با موفقیت اجرا میشود. قابل ذکر است که BertRLFuzzer هرگز روی ورودیِ اولیه – ’ OR ’a’ = ’a’ ; — آموزش داده نشده بود — این ابزار عبارتِ ’a’ = ’a’ را با استفاده از یک ورودیِ اولیه متفاوت یاد گرفته بود:
(IF (’a’ = ’a’) THEN dbms_lock.sleep(5); ELSE dbms_lock.sleep(0); END IF; END;)
و سپس آن را برای ساختن یک حمله تاتولوژی بهطور سازگار تطبیق داد. به عبارت دیگر، BertRLFuzzer حتی زمانی که ورودیهای اولیه تنها بخشی از گرامر ورودی را پوشش دهند، باز هم عملکرد خوبی دارد. در مثال بالا، ورودیِ اولیه الگوی حمله تاتولوژیِ مبتنی بر رشتهها (مثلاً –;’ OR ’a’ = ’a’) را ندارد و تنها الگوی تاتولوژیِ مبتنی بر اعداد (مثلاً –; OR 1 = 1’) را شامل میشود. با این حال، همانطور که در شکل ۱ نشان داده شد، مدل باز هم قادر است یک حمله تاتولوژی مبتنی بر رشته را بسازد. حلقه RL به مدل اجازه میدهد تا عملیاتهای جهش متفاوت را کاوش کند، و انتخاب ’a’ = ’a’ را انجام میدهد زیرا این توکن در واژنامه مدل BERT موجود است. مزیتِ جستجوی خودکار در فضای الگوهای حمله — در مقایسه با ایجاد تغییر دستی بردارهای حمله توسط انسان — این است که چنین فرایندی شناساییِ نقاط ضعف بالقوهای را آسانتر میکند که یک توسعهدهنده معمولی ممکن است آنها را نادیده بگیرد.
BertRLFuzzer
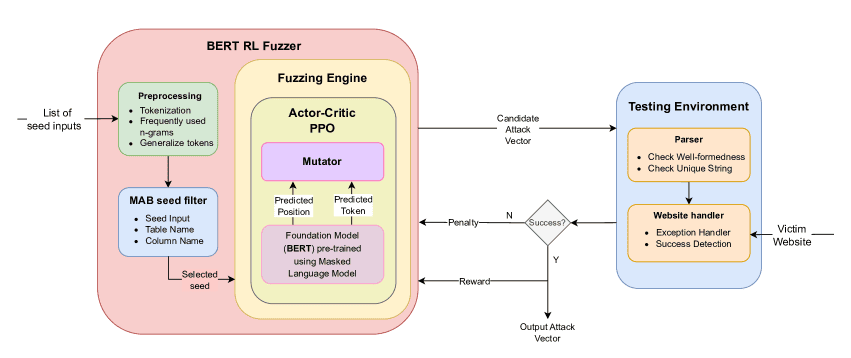
در این بخش، مروری بر رفتار ورودی-خروجی و جزئیات عملکرد داخلی ابزار BertRLFuzzer ارائه شده است (برای مشاهده جزئیات معماری به شکل ۲ مراجعه کنید).
ورودی و خروجی BertRLFuzzer
با فرض داشتن یک برنامه هدف (A) و مجموعهای (S) از ورودیهای اولیه (seed inputs)، BertRLFuzzer برای برنامه هدف (A) یک عملگر جهش که «بهگرامر پایبند» است و همچنین یک بردار حمله متناظر (یعنی همان عملگر، یک ورودی اولیه را به یک بردار حمله تبدیل میکند) تولید میکند. ممکن است یک ورودی اولیه واحد توسط چندین عملگر جهش مختلف که BertRLFuzzer تولید میکنند، چند بار دستخوش جهش گردد تا در نهایت بهعنوان یک بردار حمله شناسایی شود.
فهرست ورودیهای اولیه (seed inputs):
کاربر فهرستی از ورودیهای اولیه را فراهم میکند که این ورودیها باید با دستور زبان مربوطه مطابقت داشته و نمونههایی از یک کلاس شناختهشده از بردارهای حمله باشند (نمونههایی که بهراحتی در منابع عمومی یافت میشوند). ورودیهای اولیه باید نماینده واژگان و گرامرِ آن کلاس از بردارهای حمله باشند — بهعنوان نمونه، اگر مدل هیچگاه حملهای با الگوی UNION را ندیده باشد، نمیتواند خودبهخود یک حمله مبتنی بر UNION تولید کند. الگوهای رایج حمله بهعنوان دادههای پیشآموزشی برای مدل BERT و نیز بهعنوان seed inputs برای BertRLFuzzer بهکار میروند. هدف این است که ابزار بتواند نمایش معناداری از گرامر ورودی و الگوهای حمله بیاموزد و سپس بهطور خودکار بردارهای حمله مناسب و مختص برنامه هدف تولید کند.
برنامه هدف (Victim Application):
برنامه تحت وبی که در حال آزمون میباشد و قرار است برای وجود آسیب پذیریهای امنیتی بررسی گردد. توجه شود که تکنیک یادگیری تقویتیِ بهکار گرفتهشده در BertRLFuzzer به آن امکان میدهد بردارهای حملهای تولید کند که بهصورت ویژه برای یک برنامه/sanitizer خاص مناسب باشند.
بردار حمله (Attack vector):
برای یک برنامه هدف مشخص، بردار حمله به هر رشته ورودی گفته میشود که ممکن است بتواند از آسیب پذیریهای امنیتی آن برنامه سوءاستفاده کند.
جزئیات معماری BertRLFuzzer
پیشپردازش (Preprocessing)
در این مرحله، ابتدا فهرست ورودیهای اولیه (seed inputs) با استفاده از یک توکنایزر (tokenizer) استاندارد NLTK (Group 2022a) بهصورت مناسب توکنبندی میشود. n-gramهای پرکاربرد نیز به فهرست واژگان افزوده میشوند. در نهایت نام جداول و ستونهای SQL با توکنهای کلی شده (generalized tokens) جایگزین میگردند تا از آموزش پیشینِ پر سروصدا جلوگیری شود.
فیلتر ورودیهای اولیه با باندیت چندبازویی (Multi-armed Bandit – MAB Seed Filter)
در این گام از یک عامل MAB با نمونهبرداری تامسون (Thomson sampling) برای انتخاب یک ورودی اولیه از بین ورودیهای پیشپردازششده استفاده میشود. این عامل RL که مستقل از حلقه اصلی RL در BertRLFuzzer است، کمک میکند ابزار در کمینههای محلی گیر نکند — مشکلی که عمومِ فازینگ با آن مواجه است. در طول آموزش، عامل MAB میآموزد کدام ورودی اولیه احتمال تولید بردار حمله موفق بیشتری دارد.
Actor–Critic Proximal Policy Optimization (PPO)
ورودی اولیه منتخب به عامل Actor–Critic PPO در BertRLFuzzer تحویل داده میشود. بهعنوان بلوک ساختاری، عامل Actor–Critic از یک مدل BERT از پیشآموزشدیده استفاده میکند. این مدل BERT توسط مؤلفه RL تنظیم دقیق میشود تا عملگرهای جهش مناسب را طبقهبندی کند.
مدل BERT رشته ورودی توکنشده را به یک نمایش برداری رمزگذاری میکند. میتوان اکشن های عامل را بهصورت یک جفت زیر-عمل تقسیم کرد:
- انتخاب موقعیت در فهرست توکنشده که باید جهش کند (حذف/درج/جایگزینی).
- انتخاب توکن مناسب که باید در آن موقعیت جایگزین شود.
عامل RL، اکشن ها را از توزیعهای احتمالاتی نمونهبرداری میکند. این اکشن به یک جهش دهنده داده میشوند تا یک بردار حمله کاندید تولید شود و به محیط آزمون ارسال گردد. بسته به موفقیت یا عدم موفقیت بردار حمله، به عامل RL پاداش یا مجازات تعلق خواهد گرفت. پارامترهای عامل PPO میزان یادگیری، نرخ تخفیف، و… مطابق با مقاله مبنا تنظیم شده است. با تکرار این چرخه و آموزش مستمر، BERTRLFuzzer عملگرهای جهش مؤثری را برای برنامه مورد آزمون میآموزد و بهبود میبخشد.
محیط آزمایش
پژوهشگران چندین محیط وب مختلف ایجاد میکنیم که شامل صفحات وبی هستند که به انواع مختلف حملات SQLi و XSS آسیب پذیرند. بیشتر صفحات وب همچنین شامل چکهای اعتبارسنجی ورودی و سنیتایزرها (مثلاً با استفاده از عبارات منظم) هستند. این صفحات وب بهعنوان محیطی برای آموزش الگوریتم BertRLFuzzer ما عمل میکنند.
با استفاده از خزندۀ سفارشی خود، صفحات وب را پارس کرده و نقاط تزریق (برای مثال، فیلدهای ورودی کاربر) را استخراج میکنیم. یک کتابخانه آداپتور نیز پیادهسازی شده تا رشته کاندیدای حمله را به محیط آزمایشی ارسال کند. این کتابخانه همچنین مسئول ارسال بازخورد به عامل است — از قبیل اینکه آیا آخرین ورودی آزمایشی منجر به یک حملۀ موفق یا ناموفق شد و آیا رشته ارسالی قابل پارس بوده است یا خیر. برای آشکارسازی آسیب پذیریها و تأیید وجود آنها، از روشهای استانداردِ محققان پیشین (مانند DeepSQLi (Liu, Li, and Chen 2020) و Ardilla (Kieyzun et al. 2009)) استفاده شده و نتایج با بازبینی دستیِ کد تصدیق گشته است.
جزئیات پاداش و جریمه
عاملهای BERT و MAB در BertRLFuzzer در صورت وقوع یک حمله موفقِ SQLi یا XSS از محیط، یک سیگنال پاداش گسسته دریافت میکنند. با این حال این پاداش نادر (sparse) است و اگر تنها به این بازخورد باینری تکیه کنیم، یادگیریِ الگوریتم زمانبر خواهد بود. بنابراین برای موارد ناموفق، جریمههای متفاوت (گسسته) معرفی شده است. پس از اینکه موتور فازینگ، رشته جهشیافتهء جدید را تولید میکند، آن رشته را به یک پارسر (تجزیهگر) میدهد تا بررسی کند آیا عبارت حاصل شده، خوبساخت (well-formed) است یا خیر. اگر نباشد، به عامل بابت آخرین اقداماتش جریمهای تعلق میگیرد. علاوه بر این، برای رسیدن به یک رشته موفق در کمترین تعداد گامِ جهش، اگر رشته پارسر را پاس کند اما آداپتور اعلام کند که حمله موفق نبوده، جریمه کوچکی اعمال میکنیم. در نهایت، برای تشویق کشف خطاهای منحصربهفردتر، جریمهای برای تولید رشتهای که قبلاً مشاهده شده نیز وضع کردیم (قابل ذکر است که میتوانستیم از پارسرهایی استفاده کنیم که خودِ برنامههای قربانی الزاماً دارند — همان کاری که اغلب توسعهدهندگانِ برنامه و کاربران BertRLFuzzer احتمالاً انجام میدهند. تنها دلیلی که ما یک پارسر نوشتیم این بود که نخواستیم برنامه قربانی را تغییر دهیم و بهاینترتیب خطاهای جدیدی معرفی کنیم یا آن را بهنحوی خراب کنیم.)
جمعبندی: نحوه عملکرد BertRLFuzzer
در ابتدا، تولیدکننده ورودیهای اولیه BERTRLFUSZER، نمونهها را از فهرستی از ورودیهای اولیه (که نمونههایی از یک کلاسِ شناختهشده آسیبپذیری هستند) تولید میکند؛ این نمونهها پیشپردازش و توکنایزه میشوند. عامل MAB یک ورودی اولیه را از فهرست فیلتر و انتخاب کرده و آن را به عامل PPO از نوع BERT Actor–Critic که از قبل آموزشدیده شده میفرستد. عامل PPO یک عملگر جهشِ پایبند به گرامر پیشبینی میکند که سپس برای ساخت یک بردار حمله کاندیدا بهکار میرود. این بردار کاندیدا به وبسایتِ هدف در محیطِ آزمایشی ارسال میشود و سیگنال پاداش/جریمه را به عاملهای RL برمیگرداند. زمانِ موفقیت وقتی است که بردار حمله مدعی توانایی راهاندازی حمله روی برنامه هدف را بهطور واقعی داشته باشد. در صورت دریافت پاداش (یا جریمه)، عاملهای RL توزیع احتمال را تعدیل میکنند تا آن عملگر جهش را برای آن حالت ترجیح دهند (یا رد کنند). بردار کاندیدای که قبلاً جهش یافته بود اکنون بهعنوان ورودی برای عامل PPO استفاده میشود تا عملگرهای جهش جدیدی را پیشبینی کند. این حلقه چندین بار تکرار میشود، سپس رشته ورودی فعلی کنار گذاشته شده و یک ورودی جدید از عامل MAB انتخاب میگردد. فرایند فازینگ وقتی متوقف میشود که زمان تعیینشده (timeout) یا تعداد دورهای (epoch) مطلوب سپری شود.
تنظیمات آزمایش
فازرهای رقیب
پژوهشگران، BertRLFuzzer را با مجموعاً ۱۳ فازر جعبهسیاه و جعبهسفید شامل فازرهای مبتنی بر ML و غیرِ ML مورد بررسی و قیاس قرار دارند. فازرهای جهشمحورِ جعبهسیاه مبتنی بر یادگیری ماشین که در این آزمایشها استفاده شدهاند عبارتاند از:
- DeepSQLi – (Liu, Li, and Chen 2020): ورودیهای کاربر (یا یک مورد آزمایشی) را به یک مورد آزمایشی جدید تبدیل میکند که از نظر معنایی مرتبط و بهدلیل تواناییِ یادگیری «دانشِ معنایی» نهفته در حملات SQLi بالقوه پیچیدهتر است. یک شبکه تبدیلکننده توالی-به-توالی روی یک مجموعهداده آموزشی دستنویس و پایبند به گرامر آموزش داده میشود تا عملیاتهای جهش را بازتولید کند و بردارهای حمله مؤثرتری که احتمالاً حمله را برمیانگیزند، تولید نماید.
- DeepFuzz (تعدیلشده) – (Liu et al. 2019a): یک شبکه عصبی بازگشتی (RNN) است که توسط پژوهشگران برای پشتیبانی از حملات SQLi و XSS با استفاده از Deep Q-Network (DQN) اصلاح شده است. این مدل عملگرِ جهش را پیشبینی میکند، یعنی یک دنباله عملیات که یک ورودیِ بنبستِ پیرویکننده از گرامر را گرفته و آن را برای یک برنامه قربانی مشخص به یک بردار حمله تبدیل مینماید.
- فازر DQN – (Zhou et al. 2021; Erdodi, Sommervoll, and Zennaro 2021: یک مدل Q-Network عمیق (Deep Q-Network) که عملگرهای جهش را پیشبینی میکند و این عملگرها برای الگوهای خاصِ حمله طراحیشدهاند.
- DeepXSS (اصلاحشده) – (Fang و همکاران، ۲۰۱۸): برای طبقهبندی XSS با استفاده از شبکههای حافظه کوتاهمدت طولانی (LSTM) طراحی شده است. پژوهشگران آن را اصلاح کردند تا از فازینگ با استفاده از DQN برای پیشبینی عملگر جهش با استفاده مجدد از شبکههای LSTM موجود پشتیبانی کند.
- DeepFix (اصلاحشده) (گوپتا و همکاران، ۲۰۱۷): ابزار DeepFix اصلاح شده است تا از کامپوننت GRU آن بهعنوان یک فازر برای هر دو نوع حمله SQLi و XSS استفاده شود؛ در این نسخه اصلاح شده، از DQN برای پیشبینی عملگرِ جهش استفاده میشود.
- فازر GRU-PPO: یک عامل یادگیری تقویتی (RL) مبتنی بر واحد بازگشتی دروازهای (GRU) همراه با الگوریتم Proximal Policy Optimization (PPO) طراحی و پیادهسازی شد تا عملگرِ جهش (mutation operator) را پیشبینی کند.
- فازر Multi-head DQN: یک عامل DQN مبتنی بر مکانیزم خودتوجهیِ چندسر (Multi-head self-attention) ایجاد شده است تا عملگر جهش (mutation operator) را پیشبینی کند.
فازرهای مختلفِ دستنویسِ سازگار با گرامر که در آنها گرامرِ برنامههای قربانی بهصورت صریح و توسط انسان تعریف شده است و در آزمایشهای ما مورد استفاده قرار گرفتهاند، عبارتاند از:
- BIOFuzz – (Thomé, Gorla, and Zeller 2014): ابزاری مبتنی بر جستوجو که موارد آزمایشی را با استفاده از توابع متناسب مبتنی بر گرامرهای مستقل از متن (context-free grammar) تولید میکند.
- SQLMap – (Group 2022b): از سینتکس ازپیشتعریفشده برای تولیدِ مواردِ آزمایشی استفاده میکند و هیچگونه مؤلفه یادگیری فعال (active learning) ندارد.
- Baseline Grammar Mutator: یک مولد مبتنی بر گرامر همراه با یک جهشگر (mutator) مبتنی بر همان گرامر است که توسط یکی از نویسندگان این مقاله طراحی و پیادهسازی شده است.
علاوه بر این، مقایسهای نیز با یک فازر جعبه سفید محبوب به نام Ardilla انجام شده است که از اجرای نمادین برای یافتن آسیبپذیریهای SQLi و XSS در برنامههای PHP/MySQL استفاده میکند. در نهایت، پژوهشگران دو فازر پایه (baseline) ایجاد کردند: یک جهشگر تصادفی پایه که از یک مولد مبتنی بر گرامرِ نوشتهشده توسط انسان با جهشهای تصادفی بهره میبرد، و یک فازر تصادفی پایه که ورودیهای رشتهایِ تصادفی تولید میکند.
معیارها و محیط محاسباتی
پژوهشگران برای مقایسه منصفانه با DeepSQLi و SQLmap، از همان ۴ بنچمارکی که نویسندگان آنها استفاده کردهاند بهره بردهاند (Liu, Li, and Chen 2020). بهطور مشابه، برای مقایسه با BIOFuzz و Ardilla نیز از همان ۴ بنچمارکی استفاده شده است که نویسندگان آنها گزارش کردهاند (Kieyzun et al. 2009; Thomé, Gorla, and Zeller 2014). برای جزئیات بیشتر در مورد این بنچمارکها به مقالات مرجع مراجعه کنید.
علاوه بر این، یک برنامه وب سفارشی نوشتهشده با PHP و با پایگاهداده پشتیبان MySQL ایجاد شده است و همچنین از فریمورک سبک Flask همراه با موتور پایگاهداده SQLite برای ساخت برنامههای وب کوچک حاوی آسیبپذیریهای SQLi و XSS استفاده شده است. این بنچمارکِ سفارشی شامل باگهای متنوعی است و دربردارنده سنیتایزرهای مبتنی بر عبارتهای منظم (regex) میباشد (ویژگیای که در بسیاری از بنچمارکهای دیگر غایب است).
پژوهشگران آزمایشها و آموزشها را روی یک دستگاه مجهز به پردازنده Intel i7 نسل هشتم 3.20 GHz، 32 گیگابایت حافظه RAM و سیستمعامل Ubuntu 18 (64-bit) به انجام رساندند. برای حذف سوگیری، بهتمامی ابزارهای مبتنی بر یادگیری ماشین همان ورودیهای اولیه (seed inputs) و همان زمان آموزش روی همان سختافزار داده شد. معیارهای مورد استفاده ما به طور گسترده در این زمینه مورد استفاده قرار گرفتهاند تا به عنوان یک شاخص مهم برای یافتن آسیبپذیریهای برنامههای وب و تعیین اثربخشی فازرها عمل کنند. پژوهشگران ابزارهای ذکر شده در بالا را بر اساس معیارهای زیر ارزیابی کردیم:
- زمان تا اولین حمله: زمان بر حسب ثانیه برای خروجی اولین بردار حمله که یک آسیب پذیری را آشکار میکند.
- فیلدهای منحصر به فرد: تعداد فیلدهای منحصر به فرد وبسایت که ابزار در آنها آسیب پذیریها را آشکار کرده است.
- آسیب پذیریهای یافت شده: دستههای مختلف خطاهای آشکار شده، به عنوان مثال، جفتهای منحصر به فرد پارامترهای ورودی و دستورات کوئری برای حملات SQLi . بردارهای حمله با INSERT، UNION یا UPDATE به عنوان دستههای جداگانه شمارش میشوند.
- جریمههای پارسر: نسبتِ تعداد رشتههای کاندید که پارسر آنها را رد کرده است به کلِ رشتههای کاندید تولیدشده.
- نرخ حمله یا نرخ خطا: نسبت تعداد رشتههای کاندید که منجر به حمله شدهاند به تعداد کل رشتههای کاندید تولید شده.
- زمان: زمان(wall-clock) CPU بر حسب ثانیه برای یافتن تمام آسیب پذیریها.
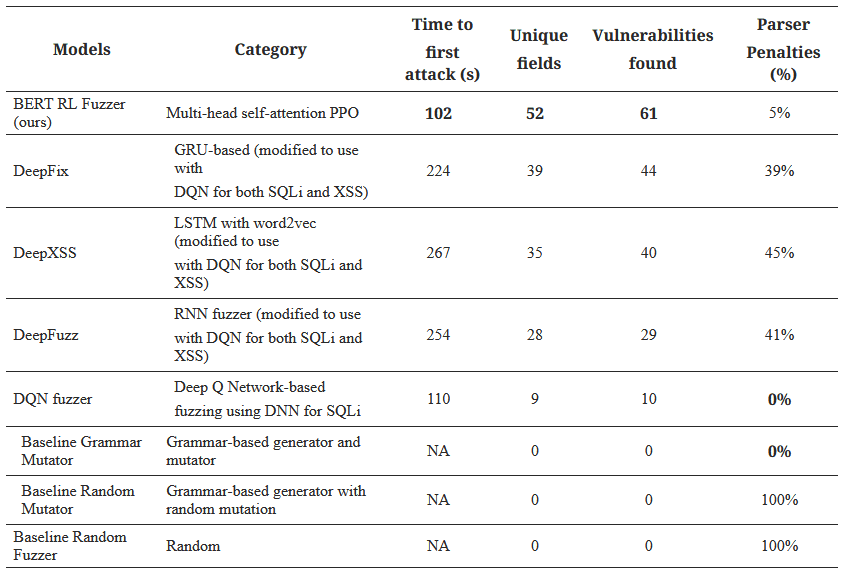
جدول 1: نتایج مقایسه فازرهای مختلف یادگیری ماشینی و غیر یادگیری ماشینی
ارزیابی
ارزیابی تجربیِ BertRLFuzzer بهمنظور پاسخگویی به سوالات پژوهشی زیر انجام شده است:
RQ1 (کارایی و اثربخشی ابزار BertRLFuzzer در برابر فازرهای روز): ابزار BertRLFuzzer نسبت به دیگر فازرهای مبتنی بر ML و غیر ML چه عملکردی دارد (از جمله زمان تا اولین حمله، تعداد فیلدهای یکتا کشفشده، تعداد آسیبپذیریهای پیداشده، نسبتِ جریمههای پارسر و سایر معیارهای مرتبط)؟
RQ2 (مطالعات حذف – Ablation Studies): حذف یا افزودنِ کامپوننت های مختلفِ BertRLFuzzer چه تأثیری بر عملکرد کلی ابزار دارد؟
RQ3 (قابلیت گسترش BertRLFuzzer به دستههای مختلف حمله و برنامههای هدف): ابزار BertRLFuzzer تا چه حد میتواند به سایر انواع حملات و برنامههای قربانی تعمیم یابد و عملکرد موثری را ارائه دهد؟
RQ1 (اثربخشی/کارایی در برابر فازرهای پیشرفته)
پژوهشگران ابزار BertRLFuzzer را در برابر فازرهای مختلف مبتنی بر ML و غیر ML مقایسه کردند و آنها را روی 9 برنامه وب با زمان کل 30 دقیقه برای هر ابزار اجرا نمودند. برای جلوگیری از سوگیری، به همه ابزارهای مبتنی بر یادگیری ماشین ورودی اولیه یکسان و زمان آموزش یکسان روی سختافزار یکسان ارائه شد. برای انجام یک مقایسه منصفانه با همه ابزارهای موجود، مجبور شدند برخی از این ابزارها را اصلاح کنند. آنها ابزارها را از نظر زمان اولین حمله، فیلدهای منحصر به فرد، تعداد آسیب پذیریهای یافت شده و جریمههای تجزیهگر ارزیابی کردند.
یافتههای پژوهشگران نشان میدهد که BertRLFuzzer در معیارهای «زمان تا اولین حمله»، «فیلدهای منحصر به فرد» و «تعداد آسیب پذیریهای کشفشده» از تمام ابزارهای دیگر جلوتر است (جدول ۱). بهطور مشخص، BertRLFuzzer در معیار «زمان تا اولین حمله»، ۵۴٪ سریعتر از نزدیکترین ابزار رقیب عمل میکند و ۱۷ آسیب پذیری جدید را در ۱۳ فیلد منحصر به فرد جدید کشف کرده است. تنها معیاری که در آن BertRLFuzzer بهترین نیست، «جریمههای پارسر» است؛ در این معیار امتیاز ما ۵٪ است در حالی که فازر جهش سازگار با گرامری که پژوهشگران نوشتهاند امتیاز ۰٪ را دارد. این مسئله قابل انتظار است؛ زیرا در مورد فازرِ دستنویسِ سازگار با گرامر، آنها بهطور صریح گرامر را مشخص کردهاند، در حالی که BertRLFuzzer صرفاً یک نمایش از گرامرِ برنامه قربانی را با دقتِ بالا آموخته است.
علاوه بر این، هرچند فازر جهش سازگار با گرامر، ۰٪ خطای پارسینگ دارد، اما قادر به کشف هیچ آسیب پذیری در برنامه وب نیست. دلیل این امر آن است که فضای ورودیهایی که فازر باید در آن جستوجو کند بسیار وسیع و تقریبی بینهایت است و جستوجوی بدون راهنمایی در چنین محیطهایی در عمل با شکست مواجه میشود. در مقابل، مشاهده میکنیم که BertRLFuzzer قادر است بهصورت اکتشافی بردارهای حمله را تولید کند، بر اساس تعمیم الگوهای مشاهده شده قبلی، و بدین ترتیب فضای جستوجو را به شکل چشمگیری کاهش دهد. شایان ذکر است که توسعهدهندگان وب اغلب به این نوع بردارهای حمله علاقهمندند، جایی که ممکن است برخی الگوهای ساده را مشخص کرده باشند اما ترکیبهای این الگوها که احتمالاً بردارهای حمله نیز هستند را نادیده گرفته باشند.
فازر DQN تنها کاراکترهای فرار (escape characters) را پیشبینی میکند و در دو الگوی مشخصِ حمله که پایبند به گرامر هستند، بهصورت محدود عملهایی مانند افزودن یا حذف نام ستونها را انجام میدهد تا بردارهای حملۀ SQLi تولید کند. بنابراین، هرچند گرامر را حفظ میکند، اما تنها قادر به تولید بردارهای حملۀ سادهای مانند حملاتِ مبتنی بر UNION و تاتولوژی (tautology) است.
مشاهده میکنیم که ابزارهای مبتنی بر گرامرِ غیر ML ناکارآمدند زیرا نمیتوانند «یاد بگیرند» چگونه جهشهایی تولید کنند که بردارهای حمله را برانگیزند و در نتیجه به جستوجوی بدونهدایت (unguided search) متوسل میشوند. فازر مبتنی بر DQN نیز بهراحتی قابلسازگاری نیست، چرا که لازم است الگوهای معمولِ برانگیزاننده حمله (مانند یک رشته عمومیِ مبتنی بر UNION برای SQLi) و عملگرهای جهشِ خاصِ آن حمله را صریحاً تعریف کرد. علاوه بر این، در نبود چنین آسیبپذیریهایی، این ابزار قادر به شناسایی بردارهای حمله جدید نخواهد بود. فازرهای تصادفی بالاترین نسبتِ خطای پارسینگ را دارند و هیچ آسیب پذیری را نشان نمیدهند، زیرا رشتههای تولیدی آنها از گرامر پیروی نمیکنند. سایر فازرهای مبتنی بر یادگیری ماشینی مانند DeepFuzz، DeepXSS و DeepFix نیاز به تلاش دستی برای ساخت یک مجموعهداده برچسبخورده جهت آموزش دارند که باعث میشود تطبیق آنها با حملات جدید بدون دانشپیشینیِ دامنه دشوار باشد. حتی اگر از تکنیکهای RL (مانند DQN) برای حذف نیاز به ساخت مجموعهداده آموزشی برای حملاتِ در دسترسنبودنی استفاده شود، بیشتر رشتههای کاندیدا پس از جهش، آگاه از گرامر نیستند (که با افزایشِ جریمه پارسر نشان داده میشود). این موضوع باعث هدر رفتن زیادی از زمان در گیر شدن با پارسر میشود. در مقابل، ابزار ما خودکار است (بدون دخالت انسانی عملگر جهش را میآموزد)، پایبند به گرامر است (بردارهای حمله خروجی با دقت بالا از گرامرِ برنامه قربانی پیروی میکنند)، مؤثر است (بیشتر از ابزارهای پیشرفته رقیب آسیبپذیری کشف میکند) و کارا است (زمان تا اولین حمله کم است).
RQ2 (مطالعات حذف)
جدول ۲: تأثیر انتخابهای طراحی: مطالعات تخریب
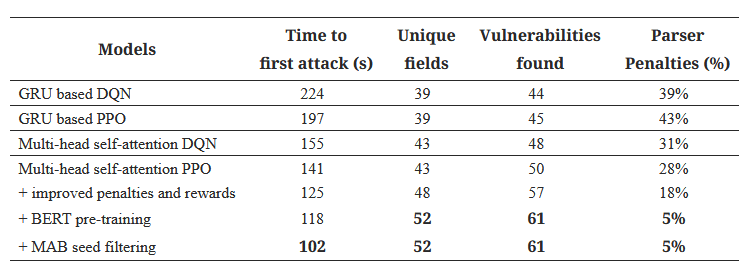
پژوهشگران از همان برنامههای وب مورد استفاده در بالا بهره بردند و یک مطالعه حذف انجام دادند تا مشاهده کنند که چگونه هر کامپوننت نقش اساسی در BERTRLFuzzer ایفا میکند. آنها مشاهده کردند که استفاده از یک مدل توجه بر روی یک مدل GRU مبتنی بر تکرار، منجر به حمله اولیه سریعتر، جریمههای پارسر کمتر و افزایش تشخیص آسیب پذیری میشود (جدول 2). معرفی یک عامل PPO با سیگنالهای پاداش بهبود یافته در حلقه یادگیری تقویتی BERTRLFuzzer، تعداد فیلدهای منحصر به فرد (+5) و آسیب پذیریهای یافت شده (9+) را به طور قابل توجهی افزایش داد. این نتیجه بیانگر آن است که استفاده از یک سیگنال پاداش بهبود یافته به BERTRRL-FUZZER کمک میکند تا فضای جستجو را بهتر کاوش کند. همچنین پیشرفتهای واضحی نسبت به یک شبکه Q عمیق DQN وجود دارد، زیرا PPO میتواند فضاهای عمل بزرگ و پاداشهای پراکنده را مدیریت کند (Schulman و همکاران، 2017). علاوه بر این، استفاده از یک مدل BERT به عنوان یک عامل یادگیری تقویتی منجر به کاهش شدید جریمههای پارسر (-13%) نسبت به یک عامل یادگیری تقویتی معمولی شد. این نتیجه نشان میدهد که استفاده از مدل BERT، BERTRLFuzzer را قادر میسازد تا به طور قابل توجهی نسبت به تکنیکهای مشابه، پایبندی بیشتری به گرامر داشته باشد. همچنین، فیلتر کردن ورودی اولیه با استفاده از یک عامل MAB، زمان اولین حمله را کاهش داد (-13.56٪). همانطور که توسط BanditFuzz (Scott و همکاران، 2021) نیز مشاهده شد، مدلهای یادگیری تقویتی تک عاملی میتوانند در حداقلهای محلی گیر کنند و برای یافتن بردار حمله خروجی، زمان بیشتری صرف نمایند (Saavedra و همکاران، 2019؛ Duchene 2013؛ Gerlich و Prause 2020؛ Man`es، Kim و Cha 2020). بنابراین، استفاده از یک عامل ثانویه سبک وزن به یادگیری اینکه کدام یک از این عوامل به احتمال زیاد منجر به یک حمله موفق میشود، کمک میکند و عملکرد بهتری نسبت به انتخاب قطعی یا تصادفی یک عامل ورودی دارد.
RQ3 (قابلیت توسعه به دستههای مختلف حملات)
پژوهشگران آزمایشهایمان را روی دو مجموعه هشتتایی بنچمارکهای واقعی (هر مجموعه شامل ۴ بنچمارک) مقابل ابزارهای جدید جعبهسیاه و جعبهسفید مقایسه کردند. برای نشاندادن اینکه ابزار آنها بهراحتی قابل تعمیم به طبقات دیگر حمله فراتر از SQLi است، یکی از این مجموعههای بنچمارک واقعی را که شامل آسیب پذیریهای XSS است نیز ارزیابی کردند. قابلیتِ پیشآموزشِ سریع یک مدلِ سازگار با گرامر موجب میشود ابزار بتواند بهسرعت و با کمترین تلاش برای آموزش مجدد، به حملات جدید تعمیم یابد.
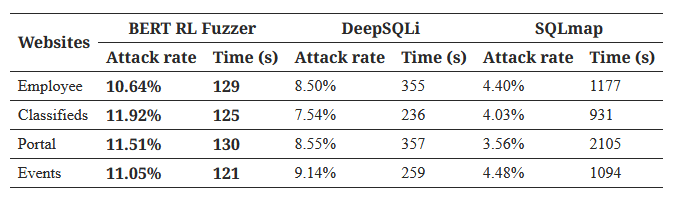
جدول ۳: مقایسهی DeepSQLi و SQLmap در معیارهای دنیای واقعی
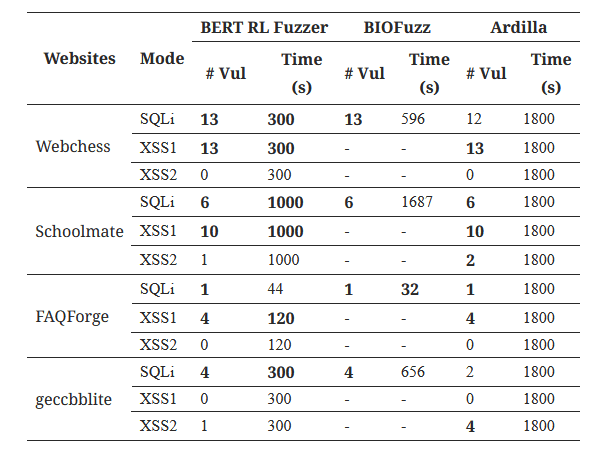
جدول ۴: مقایسه با توجه به معیارهای دنیای واقعی بین BIOFuzz و Ardilla
اولین مجموعه معیارها شامل شش برنامه وب تجاری دنیای واقعی است که به طور گسترده توسط محققان استفاده میشود (Halfond, Orso, and Manolios 2006; Liu, Li, and Chen2020). این برنامههای وب به زبان جاوا نوشته شدهاند و از یک پایگاه داده پشتیبان MySQL استفاده میکنند. پژوهشگران ابزار خود، BERTRL-FUZZER، را با دو رویکرد جعبه سیاه DeepSQLi (Liu, Li, and Chen 2020) و SQLMap (Group 2022b) مقایسه کردند. آنها از نتایج گزارششده توسط DeepSQLi (لیو، لی و چن، 2020) استفاده مجدد نمودند و آزمایشهای خود را انجام دادند و آن را 20 بار با استفاده از همان تنظیمات محاسباتی مورد استفاده توسط DeepSQLi (لیو، لی و چن، 2020) تکرار کردند. پژوهشگران ابزار خود را بر اساس معیارهای مشابه مورد استفاده آنها، یعنی نرخ حمله (یا نرخ خطا) و زمان ساعت CPU ارزیابی کردند. آنها دریافتیم که این ابزار به طور قابل توجهی از هر دو ابزار بهتر عمل میکند و به نرخ خطای بالاتری، 1.91-4.38٪ بیشتر از نزدیکترین ابزار رقیب، در کمتر از نیمی از زمان صرفشده برای کشف تمام آسیب پذیریهای گزارششده توسط نویسندگان ابزار (جدول 3) دست مییابد.
پژوهشگران برای مجموعه دوم معیارها (جدول 4)، ابزار خود را با یک ابزار جعبه سفید محبوب Ardilla (کیزون و همکاران، 2009) و یک ابزار مبتنی بر تست تکاملی جعبه سیاه BIOFuzz (تام، گورلا و زلر، 2014) مقایسه کردند. آنها از همان مطالعات موردی (مجموعه معیار) استفاده شده توسط Ardilla و BIO-Fuzz استفاده نمودند و از نتایج گزارش شده توسط نویسندگان نیز استفاده مجدد کردند، زیرا Ardilla در دسترس عموم نیست و BIOFuzz به شدت قدیمی است. آنها همچنین با استفاده از همان معیارهای مورد استفاده توسط نویسندگان Ardilla، یعنی تعداد آسیب پذیریهای شناسایی شده و زمان اجرا یا زمان انقضا بر حسب ثانیه، ارزیابی را انجام دادند. Ardilla ابزاری نسبتاً قدیمی است و توسط نویسندگان برای تمام مطالعات موردی با زمان انقضای 30 دقیقه اجرا شد. پژوهشگران برای مقایسهای منصفانه با ابزار، از همان تنظیمات آزمایشی BIOFuzz استفاده کردیم. ابزار BERTRLFUSZER میتواند تمام آسیبپذیریهای SQLi و XSS1 (XSS مرتبه اول) گزارش شده توسط نویسندگان را پیدا کند. از آنجایی که BIO-Fuzz فقط از SQLi پشتیبانی میکند، نویسندگان هیچ آسیب پذیری XSS1 یا XSS2 (XSS مرتبه دوم) را گزارش نکردند. ابزار BERTRLFUSZER همچنین سه آسیب پذیری جدید SQLi را پیدا کرد که توسط Ardilla گزارش نشده بودند، اما توسط BIOFuzz گزارش شده بودند. این نشان میدهد که ابزار BERTRLFUSZER میتواند الگوهای حمله متفاوتی را برای آسیب پذیریهای SQLi پیدا کند. از سوی دیگر، BERTRLFUSZER نتوانست چهار آسیب پذیری XSS2 گزارش شده توسط Ardilla را پیدا کند. یافتن حملات XSS مرتبه دوم XSS2 چالش برانگیز است زیرا توالی ورودیها مسئول ایجاد چنین حملهای است. بنابراین، یک فازر جعبه سفید مبتنی بر حلکننده SMT مانند Ardilla میتواند به راحتی این رشتههای آزمایشی را استنباط کند. علاوه بر این، BERTRLFUSZER در همه موارد به طور قابل توجهی سریعتر است (بهبود 40-60٪) به جز یک مورد که ابزار BIOFuzz حمله SQLi را چند ثانیه سریعتر تشخیص میدهد. بنابراین، میتوانیم بگوییم که BERTRLFUSZER به راحتی میتواند به برنامههای قربانی جدید و همچنین کلاس متفاوتی از آسیبپذیریها (مثلاً XSS) گسترش یابد و میتواند به اندازه یک فازر جعبه سفید پیشرفته مانند Ardilla در یافتن آسیبپذیریها در زمان بسیار کمتری مؤثر باشد.
تهدیدات اعتبار
اعتبار ارزیابی تجربی: پژوهشگران ابزار خود را با ۱۳ ابزار پیشرفته دیگر بر روی ۹ بنچمارک بزرگ و واقعی مقایسه کردند که اغلب توسط نویسندگان ابزارهای رقیب نیز استفاده شدهاند (. همچنین از معیارهایی بهره بردند که در این حوزه بهطور گستردهای به کار رفتهاند و بهعنوان شاخص مهمی برای شناسایی آسیب پذیریهای برنامههای وب عمل میکنند. تا آنجا که ما اطلاع داریم، ارزیابی تجربی این پژوهشگران جامعترین و دقیقترین ارزیابی انجامشده برای هر ابزار فازینگ از این نوع است.
یادگیری ساختار معنایی کلی آسیبپذیریهای برنامههای وب: همانطور که قبلاً ذکر شد، مدلهای BERT با دقت بالا، برخی از نمایشهای گرامر ورودیهای خود را یاد میگیرند. البته این بدان معناست که ما انتظار نداریم که مدل ما گرامر را به طور کامل یاد بگیرد. با این اوصاف، مدلهای زبانی مانند BERT با بهرهگیری از مکانیزم توجه، موفقیت تجربی فوقالعادهای در یادگیری دستور زبان پیچیده داشتهاند (واسوانی و همکاران، ۲۰۱۷). برخی از نمونهها شامل ترجمه کد از یک زبان برنامهنویسی به زبان دیگر (لاچاکس و همکاران، ۲۰۲۰؛ ماستروپائولو و همکاران، ۲۰۲۱)، ترکیب برنامه (آلامانیز و ساتون، ۲۰۱۳؛ چن و همکاران، ۲۰۲۱) و درک کد (مو و همکاران، ۲۰۱۶؛ گوئو و همکاران، ۲۰۲۰؛ فنگ و همکاران، ۲۰۲۰) هستند. در تمام این کاربردها، یک مدل یادگیری ماشینی، یک مدل تجربی بسیار دقیق از گرامر یک پیشنیاز است. BERTRLFUSZER کاربرد دیگری از BERT را ارائه میدهد که توانایی آن را در یادگیری یک مدل بسیار دقیق از گرامر پیچیده نشان میدهد. در ارزیابی، مشاهده کردیم که BERTRLFUSZER میتواند تا 95٪ دقیق باشد و تنها توسط فازرهای جهشی دستنویس که به گرامر پایبند هستند، از آن پیشی میگیرد.
توسعهپذیری BERTRLFUSZER: پژوهشگران در این مقاله، ابزار خود را به طور گسترده در دو مورد استفاده متعامد (یعنی SQLi و XSS) ارزیابی کردند. همانطور که در بالا ذکر شد، توانایی مدلهای زبانی، مانند BERT، برای یادگیری بازنماییهای تجربی دقیق از گرامرهای پیچیده و غیر بدیهی (به عنوان مثال، زبانهای برنامهنویسی) نشان میدهد که BERTRLFUSZER را میتوان به راحتی به سایر کلاسهای برنامهها و بردارهای حمله گسترش داد. فرآیند فازینگ BERTRLFuzzer به راحتی قابل تغییر، سفارشیسازی و مانور است. طراح میتواند با ارائه مجموعهای تحت نظارت از مثالهای آموزشی با عملیات جهش خاص که معمولاً برای الگوهای حملهای که طراح میخواهد روی آنها تمرکز کند، شناخته شدهاند، ابزار را تغییر دهد. این الگوهای جهش تعریفشده توسط توسعهدهنده، به عنوان یک مرحله اولیه تنظیم دقیق قبل از شروع حلقه یادگیری تقویتی عمل میکنند و به مدل کمک میکنند تا الگوهای حمله بهتر و سریعتر را یاد بگیرد. به طور دقیقتر، فازینگ را میتوان با جایگزینی ساده ورودیهای اولیه، مدل BERT از پیش آموزشدیده و محیط (برنامه تحت آزمایش) به یک برنامه متفاوت گسترش داد.
کارهای مرتبط
در حوزه فازینگ، یادگیری تقویتی (Reinforcement Learning) انتخابِ محبوبی برای خلق انواع الگوریتمهای فازینگ بوده است، بهویژه در زمینه انتخابِ عملیاتِ جهش. علاوه بر این، مسئله تست نفوذ قبلاً بهصورت مسائل یادگیری تقویتی مدلسازی شده است و از تجریدهای مختلفی برای مسئله استفاده شده است. در روزهای نخست، الگوریتمِ SARSA (State–Action–Reward–State–Action) انتخابِ رایجی برای این کار بود (Becker et al. 2010) و پس از آن Q‑Learning متداول شد (Fang and Yan 2018). با گسترشِ یادگیری عمیق، نسخههای عمیقِ Q‑Learning توسط Böttinger و همکاران برای انتخابِ عملیاتِ جهش بهکار رفتند (Böttinger, Godefroid, and Singh 2018)، و توسط Kuznetsov و همکاران برای تحلیلِ قابلیتِ سوءاستفاده (exploitability analysis) استفاده شد (Kuznetsov et al. 2019). Drozd و همکاران از یک واریانتِ دیگرِ Deep Q‑Learning بهنام Deep Double Q‑Learning بههمراه مدلِ حافظه بلند-کوتاهمدت (LSTM) — که در پردازش زبان طبیعی محبوب است — برای انتخابِ عملیاتِ جهش بهره بردند (Drozd and Wagner 2018). بهطور مشابه، μ4SQLi (Appelt et al. 2014) نیز عملیاتِ جهش را روی ورودیهای اولیه اجرا میکند اما برای مجموعه ثابتی از الگوها طراحی شدهاست. برای مقابله با مسئله بهرهکاوی (exploitation) که اغلب روشهای مبتنی بر RL را گرفتار میکند، برخی کارهای اخیر بر بهرهکاوی در محیطِ سادهشده SQL برای الگوهای حمله و عملگرهای جهشِ مشخص تمرکز کردهاند (Erdodi, Sommervoll, and Zennaro 2021; Verme et al. 2021).
فازرهای عمومی مانند AFL (Zalewski 2015) و PerfFuzz )Lemieux و همکاران 2018) که حول دستکاری رشتههای بیتی ساخته شدهاند، به گرامر پایبند نیستند و از این رو قادر به تولید ورودیهای خوش ساخت برای گرامرهای پیچیده معمول برای برنامههای وب نیستند.
BanditFuzz یک فازر مبتنی بر RL برای بهبود عملکرد حلکنندههای Satisfiability Modulo Theories (SMT) است. با این حال، عامل RL آن (MAB) بدون حالت (stateless) عمل میکند (Vermorel and Mohri 2005)، به این معنی که پاداشها تنها بر اساس عملیاتها یاد گرفته میشوند و از وضعیت جاری (مثلاً رشته اولیه در مثال ما) مستقل هستند. علاوه بر این، برخلاف BertRLFuzzer، BanditFuzz نمیتواند هیچ نمایشی از گرامر برنامههای قربانی بیاموزد، و بنابراین نه پایبند به گرامر است و نه بهراحتی قابل توسعه.
برخلاف رویکردهای فوق در فازینگ مبتنی بر ML/RL و غیرML، ما در BertRLFuzzer از ترکیب مدل BERT بهعنوان عامل RL استفاده کردهایم. این امر موجب میشود ابزار ما پایبند به گرامر، قابل توسعه و خودکار باشد — ویژگیهایی که در فازرهای پیشرفتهٔ دیگر مشاهده نمیشود. علاوه بر این، آزمایشهای گستردهٔ ما روی مجموعه بزرگی از بنچمارکهای واقعی نشان میدهد که ابزار ما از نظر اثربخشی و کارایی نسبت به ابزارهای رقیب برتری دارد.
نتیجهگیری
در این مقاله، BERTRLFuzzer، یک فازر مبتنی بر یادگیری تقویتی RL را معرفی کردیم. BERTRLFuzzer اولین فازر مبتنی بر یادگیری ماشین است که از معماری BERT و الگوریتم مبتنی بر یادگیری تقویتی بدون نیاز به فایل گرامری ساخته شده دستی یا مجموعه دادههای آموزشی برچسبگذاری شده استفاده میکند.
با انجام یک ارزیابی تجربی گسترده، جامع و دقیق در مقایسه با ۱۳ فازر روی ۹ بنچمارک مختلف، نشان میدهیم که BertRLFuzzer خودکار، قابل توسعه، پایبند به گرامر، کارا و مؤثر است. این ابزار برای توسعهدهندگان برنامهها بسیار مفید است، به ویژه زمانی که نوشتن فازرهای جهشمحافظِ گرامری بهصورت دستی زمانبر، مستعد خطا و پرهزینه است.
علاوه بر این، ابزار ما بهویژه در سناریوهایی مؤثر است که توسعهدهندگان برنامه ممکن است سنیتایزرهایی بر اساس بردارهای حمله ساده نوشته باشند و ترکیبهای پیچیده را نادیده گرفته باشند. در مقابل، با داشتن مجموعه داده کافی از بردارهای حمله ساده، BertRLFuzzer قادر است ترکیبهای پیچیده الگوهای حمله را بیاموزد و ضعفهای سنیتایزرها را بهصورت هئوریستیک و کارآمد شناسایی کند.
تا آنجا که ما اطلاع داریم، هیچ فازر مبتنی بر یادگیری ماشین دیگری از معماری BERT و الگوریتم مبتنی بر RL برای حل این مشکل استفاده نمیکند — مشکلی که معمولاً کاربران فازر را مجبور میکند تا ابزارها را برای پایبندی به گرامر برنامههای قربانی اصلاح کنند یا الگوهای بردار حمله را فراهم نمایند، که فرآیندی پیچیده، پرهزینه و مستعد خطا است. همچنین، ما از هیچ فازر دیگری اطلاع نداریم که بدون دخالت انسانی قابل توسعه باشد.
در کارهای آینده، میتوان از جستجوی درختی مونتکارلو (MCTS) (Browne et al. 2012) برای اکتشاف بهتر فضای جستوجو استفاده کرد، مشابه کاری که در موتورهای بازی خودبازیکن محبوب انجام میشود (Silver et al. 2018). علاوه بر این، رویکرد ما میتواند برای ارزیابی انواع مختلف نرمافزارهایی که به ورودیهای ساختاریافته وابستهاند، از جمله ولی نه محدود به کامپایلرها، حلکنندههای SMT و خوانندههای PDF نیز بهکار گرفته شود.
[1] Grammar‑Preserving black‑box fuzzers
منابع
Allamanis and Sutton (2013) Allamanis, M.; and Sutton, C. 2013. Mining source code repositories at massive scale using language modeling. In 2013 10th working conference on mining software repositories (MSR), 207–216. IEEE.
Appelt et al. (2014) Appelt, D.; Nguyen, C. D.; Briand, L. C.; and Alshahwan, N. 2014. Automated testing for SQL injection vulnerabilities: an input mutation approach. In Proceedings of the 2014 International Symposium on Software Testing and Analysis, 259–269.
Becker et al. (2010) Becker, S.; Abdelnur, H.; Engel, T.; et al. 2010. An autonomic testing framework for IPv6 configuration protocols. In IFIP International Conference on Autonomous Infrastructure, Management and Security, 65–76. Springer.
Bommasani et al. (2021) Bommasani, R.; Hudson, D. A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M. S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.
Böttinger, Godefroid, and Singh (2018) Böttinger, K.; Godefroid, P.; and Singh, R. 2018. Deep reinforcement fuzzing. In 2018 IEEE Security and Privacy Workshops (SPW), 116–122. IEEE.
Bozic et al. (2015) Bozic, J.; Garn, B.; Simos, D. E.; and Wotawa, F. 2015. Evaluation of the IPO-family algorithms for test case generation in web security testing. In 2015 IEEE Eighth International Conference on Software Testing, Verification and Validation Workshops (ICSTW), 1–10. IEEE.
Brown et al. (2020) Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901.
Browne et al. (2012) Browne, C. B.; Powley, E.; Whitehouse, D.; Lucas, S. M.; Cowling, P. I.; Rohlfshagen, P.; Tavener, S.; Perez, D.; Samothrakis, S.; and Colton, S. 2012. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 4(1): 1–43.
Chen et al. (2021) Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H. P. d. O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
Chowdhery et al. (2022) Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H. W.; Sutton, C.; Gehrmann, S.; et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
Devlin et al. (2018) Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Drozd and Wagner (2018) Drozd, W.; and Wagner, M. D. 2018. Fuzzergym: A competitive framework for fuzzing and learning. arXiv preprint arXiv:1807.07490.
Duchene (2013) Duchene, F. 2013. Fuzz in the dark: genetic algorithm for black-box fuzzing. In Black-Hat.
Erdodi, Sommervoll, and Zennaro (2021) Erdodi, L.; Sommervoll, Å. Å.; and Zennaro, F. M. 2021. Simulating SQL Injection Vulnerability Exploitation Using Q-Learning Reinforcement Learning Agents. arXiv preprint arXiv:2101.03118.
Fang and Yan (2018) Fang, K.; and Yan, G. 2018. Emulation-instrumented fuzz testing of 4G/LTE android mobile devices guided by reinforcement learning. In European Symposium on Research in Computer Security, 20–40. Springer.
Fang et al. (2018) Fang, Y.; Li, Y.; Liu, L.; and Huang, C. 2018. DeepXSS: Cross site scripting detection based on deep learning. In Proceedings of the 2018 international conference on computing and artificial intelligence, 47–51.
Feng et al. (2020) Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. 2020. Codebert: A pre-trained model for programming and natural languages. arXiv preprint arXiv:2002.08155.
Foundation (2022) Foundation, O. 2022. Open Web Application Security Project (OWASP).
Gerlich and Prause (2020) Gerlich, R.; and Prause, C. R. 2020. Optimizing the parameters of an evolutionary algorithm for fuzzing and test data generation. In 2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), 338–345. IEEE.
Ghanem and Chen (2020) Ghanem, M. C.; and Chen, T. M. 2020. Reinforcement learning for efficient network penetration testing. Information, 11(1): 6.
Group (2022a) Group, N. L. T. 2022a. Natural Language Toolkit.
Group (2022b) Group, S. 2022b. SQLmap.
Guo et al. (2020) Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. 2020. Graphcodebert: Pre-training code representations with data flow. arXiv preprint arXiv:2009.08366.
Gupta et al. (2017) Gupta, R.; Pal, S.; Kanade, A.; and Shevade, S. 2017. Deepfix: Fixing common c language errors by deep learning. In Thirty-First AAAI conference on artificial intelligence.
Halfond, Orso, and Manolios (2006) Halfond, W. G.; Orso, A.; and Manolios, P. 2006. Using positive tainting and syntax-aware evaluation to counter SQL injection attacks. In Proceedings of the 14th ACM SIGSOFT international symposium on Foundations of software engineering, 175–185.
Kieyzun et al. (2009) Kieyzun, A.; Guo, P. J.; Jayaraman, K.; and Ernst, M. D. 2009. Automatic creation of SQL injection and cross-site scripting attacks. In 2009 IEEE 31st international conference on software engineering, 199–209. IEEE.
Kuznetsov et al. (2019) Kuznetsov, A.; Yeromin, Y.; Shapoval, O.; Chernov, K.; Popova, M.; and Serdukov, K. 2019. Automated software vulnerability testing using deep learning methods. In 2019 IEEE 2nd Ukraine Conference on Electrical and Computer Engineering (UKRCON), 837–841. IEEE.
Lachaux et al. (2020) Lachaux, M.-A.; Roziere, B.; Chanussot, L.; and Lample, G. 2020. Unsupervised translation of programming languages. arXiv preprint arXiv:2006.03511.
Lemieux et al. (2018) Lemieux, C.; Padhye, R.; Sen, K.; and Song, D. 2018. Perffuzz: Automatically generating pathological inputs. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, 254–265.
Liu, Li, and Chen (2020) Liu, M.; Li, K.; and Chen, T. 2020. DeepSQLi: Deep semantic learning for testing SQL injection. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, 286–297.
Liu et al. (2019a) Liu, X.; Li, X.; Prajapati, R.; and Wu, D. 2019a. Deepfuzz: Automatic generation of syntax valid c programs for fuzz testing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 1044–1051.
Liu et al. (2019b) Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; and Stoyanov, V. 2019b. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
Manes et al. (2018) Manes, V. J.; Han, H.; Han, C.; Cha, S. K.; Egele, M.; Schwartz, E. J.; and Woo, M. 2018. The art, science, and engineering of fuzzing: A survey. arXiv preprint arXiv:1812.00140.
Manès, Kim, and Cha (2020) Manès, V. J.; Kim, S.; and Cha, S. K. 2020. Ankou: Guiding grey-box fuzzing towards combinatorial difference. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, 1024–1036.
Mastropaolo et al. (2021) Mastropaolo, A.; Scalabrino, S.; Cooper, N.; Palacio, D. N.; Poshyvanyk, D.; Oliveto, R.; and Bavota, G. 2021. Studying the usage of text-to-text transfer transformer to support code-related tasks. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), 336–347. IEEE.
Mnih et al. (2015) Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A. A.; Veness, J.; Bellemare, M. G.; Graves, A.; Riedmiller, M.; Fidjeland, A. K.; Ostrovski, G.; et al. 2015. Human-level control through deep reinforcement learning. nature, 518(7540): 529–533.
Mou et al. (2016) Mou, L.; Li, G.; Zhang, L.; Wang, T.; and Jin, Z. 2016. Convolutional neural networks over tree structures for programming language processing. In Thirtieth AAAI conference on artificial intelligence.
OpenAI (2023) OpenAI. 2023. ChatGPT.
Saavedra et al. (2019) Saavedra, G. J.; Rodhouse, K. N.; Dunlavy, D. M.; and Kegelmeyer, P. W. 2019. A review of machine learning applications in fuzzing. arXiv preprint arXiv:1906.11133.
Sarraute, Buffet, and Hoffmann (2013) Sarraute, C.; Buffet, O.; and Hoffmann, J. 2013. Penetration testing== pomdp solving? arXiv preprint arXiv:1306.4714.
Schulman et al. (2017) Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; and Klimov, O. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
Scott et al. (2021) Scott, J.; Sudula, T.; Rehman, H.; Mora, F.; and Ganesh, V. 2021. Banditfuzz: Fuzzing smt solvers with multi-agent reinforcement learning. In International Symposium on Formal Methods, 103–121. Springer.
Silver et al. (2018) Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. 2018. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419): 1140–1144.
Sutton and Barto (2018) Sutton, R. S.; and Barto, A. G. 2018. Reinforcement learning: An introduction. MIT press.
Thomé, Gorla, and Zeller (2014) Thomé, J.; Gorla, A.; and Zeller, A. 2014. Search-based security testing of web applications. In Proceedings of the 7th International Workshop on Search-Based Software Testing, 5–14.
Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. In Advances in neural information processing systems, 5998–6008.
Verme et al. (2021) Verme, M. D.; Sommervoll, Å. Å.; Erdődi, L.; Totaro, S.; and Zennaro, F. M. 2021. SQL Injections and Reinforcement Learning: An Empirical Evaluation of the Role of Action Structure. In Nordic Conference on Secure IT Systems, 95–113. Springer.
Vermorel and Mohri (2005) Vermorel, J.; and Mohri, M. 2005. Multi-armed bandit algorithms and empirical evaluation. In European conference on machine learning, 437–448. Springer.
Wolf et al. (2019) Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. 2019. Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771.
Zalewski (2015) Zalewski, M. 2015. American Fuzzing Lop.
Zennaro and Erdodi (2020) Zennaro, F. M.; and Erdodi, L. 2020. Modeling penetration testing with reinforcement learning using capture-the-flag challenges and tabular Q-learning. arXiv preprint arXiv:2005.12632.
Zhou et al. (2021) Zhou, S.; Liu, J.; Hou, D.; Zhong, X.; and Zhang, Y. 2021. Autonomous penetration testing based on improved deep q-network. Applied Sciences, 11(19): 8823.