
امنیت مرورگرهای وب، به عنوان بخش حیاتی زیرساخت دسترسی به اینترنت، توجه زیادی را به خود جلب کرده است. روشهای فعلی برای شناسایی نقاط ضعف مرورگرها بیشتر بر بررسی کد و تست واحد اجزای مختلف متکی هستند. در این میان، روش تست نفوذ (Fuzzing) به عنوان یک تکنیک مؤثر برای کشف آسیب پذیریها مطرح شده است. با این حال، استفاده از این روش برای تست امنیت مرورگرها چالشهای زیادی دارد. تلاشهای اخیر در زمینهی کشف آسیب پذیری مرورگرها بیشتر بر روی موتور تجزیهکننده کد تمرکز داشتهاند و راهحلهای کمی برای موتور رندر ارائه شده است. همچنین، روش “جهش هدایت شده با پوشش کد” که بسیار مهم است، در ابزارهای تست نفوذ فعلی به اندازهی کافی مورد توجه قرار نگرفته است. در این مقاله، ما یک چارچوب تست نفوذ به نام DFL را معرفی میکنیم که از روش “جهش هدایت شده با پوشش کد” استفاده میکند و بر پایه ابزارهای Freedom و AFL ساخته شده است. این چارچوب با بازطراحی مولدهای متن بر اساس قواعد زبان DOM، کارایی تولید نمونههای تست را بهبود میبخشد. علاوه بر این، روشهایی برای تبدیل دادهها به فرمت باینری و برعکس (سریالسازی و غیرسریالسازی) توسعه داده شده است تا امکان ایجاد تغییرات در متن مولدها و تبدیل آسان بین نمونههای باینری و درخت DOM اصلی فراهم شود. نتایج آزمایشها نشان میدهد که DFL در مقایسه با سه چارچوب تست نفوذ رایج برای DOM در آخرین نسخهی هسته Chromium، توانسته است ۱.۵ تا ۳ برابر آسیب پذیری بیشتری را در مدت زمان کوتاهی پیدا کند. این تحقیق، مسیرهای احتمالی برای تحقیقات بیشتر در زمینه امنیت موتور رندر مرورگر، به ویژه در زمینه تولید نمونههای تست و هدایت مسیر تست را مشخص میکند.
۱. مقدمه
مرورگرها از اصلیترین برنامههایی هستند که کاربران برای دسترسی به اینترنت از آنها استفاده میکنند. عملکرد اصلی یک مرورگر شامل یک موتور رندر، یک تجزیهکننده HTML و یک موتور جاوااسکریپت (JS) است [۱]. موتور رندر، بخش اعظم قابلیتهای مرورگر را پیادهسازی میکند و معمولاً به عنوان هستهی مرورگر (مانند Chromium/Blink) شناخته میشود. این موتور، میزبان برخی از آسیب پذیریهای باینری بسیار ظریف و پیچیده است [۲] که تهدیدهای جدی برای امنیت و حریم خصوصی کاربران ایجاد میکند [۳-۵]. کشف و رفع این آسیب پذیریها در موتورهای رندر میتواند به طور مؤثر از حملات امنیتی که مرورگرها را هدف قرار میدهند، جلوگیری کند و امنیت کاربران را تا حد زیادی بهبود بخشد [۶]. به همین دلیل، امنیت موتور رندر به یکی از موضوعات تحقیقاتی پرطرفدار در جامعهی علمی تبدیل شده است.
امروزه، عمدتاً دو روش برای مقابله با آسیب پذیریهای مرورگر وجود دارد: بررسی کد (ممیزی کد) و تشخیص نرم افزاری. بررسی کد شامل بررسی دستی کد منبع و بررسی خودکار با استفاده از ابزارهای تحلیل کد است [۷، ۸]. با این حال، به دلیل حجم بسیار زیاد کد مرورگرها، بررسی دستی کد نیازمند تلاش و زمان قابل توجهی است و به نیروی انسانی قابل توجهی نیاز دارد.
تشخیص کد نیازمند ایجاد عبارات جستجوی کارآمد است و به شدت به تجربه و دانش تحلیلگران وابسته است. تشخیص نرم افزاری شامل تستهای عملکردی و امنیتی است و سه روش اصلی تست وجود دارد: جعبه سفید، جعبه سیاه و جعبه خاکستری. تست نفوذ (Fuzzing) مؤثرترین تکنیک تست برای تست امنیت است و بیشترین آسیب پذیریهای امنیتی در سالهای اخیر توسط این روش کشف شدهاند. اثربخشی تست نفوذ به شدت به کیفیت نمونههای ورودی و بازخورد مسیر اجرا از هدف مورد آزمایش بستگی دارد. بنابراین، تولید نمونههای با کیفیت بالا برای هدف تست با یک مکانیزم بازخورد کارآمد برای تست امنیت مرورگر بسیار مهم است.
در حال حاضر، اهداف تست نفوذ مرورگرها بیشتر موتورهای جاوااسکریپت هستند [۹-۱۸] و روشهای بسیار کمی برای تست نفوذ موتور رندر وجود دارد. اگرچه AFL [۱۹] میتواند نمونههای تست برای بررسی مسیر موتور رندر تولید کند، اما تولید همه نمونهها به این روش با توجه به حجم وسیع قواعد زبان HTML غیرعملی است. ورودیهای نامعتبر میتوانند بررسیهای اعتبارسنجی موتور رندر را فعال کنند و باعث توقف مرورگر پس از تشخیص خطاهای نحوی شوند. این امر مانع از بررسی مسیرهای عمیقتر کد میشود و از هدف اصلی تست منحرف میشود [۲۰]. بنابراین، بررسی کد [۷] و تست واحد جزء [۷، ۲۱-۲۴] همچنان روشهای اصلی برای کشف آسیب پذیریهای مرورگرها هستند. تا جایی که ما میدانیم، کارهای بسیار کمی با استفاده از روشهای تست نفوذ (fuzzing) به طور خاص برای امنیت موتور رندر انجام شده است [۲۵-۲۷]، مانند FreeDom [۲۸] و DOMato [۲۹ ].
FreeDom رویکردی برای تولید سند آگاه از زمینه ارائه میدهد. در حالی که ایدهی تست نفوذ هدایت شده با پوشش کد تا حدی در آن پیادهسازی شده، تأثیر بسیار کمی بر کشف باگهای مرورگر داشته است. برای انجام تست امنیتی موتور رندر، ما چهار چالش فنی اصلی را شناسایی کردهایم: اولاً، هیچ چارچوب تست نفوذی به طور خاص برای موتور رندر طراحی نشده است. ثانیاً، عملیات در موتور رندر از مجموعهای دقیق از قوانین نحوی پیروی میکنند و کمبود مولدهای نمونهای که از قواعد DOM پیروی کنند، وجود دارد. ساختار نمونههای تست HTML کاملاً با سایر سناریوهای تست نفوذ (مانند TEE [۳۰]) متفاوت است. یک مولد نمونهی تخصصی باید برای سناریوهای تست موتور رندر طراحی شود. ثالثاً، تکنیکهای تست نفوذ هدایت شده با پوشش کد، نتایج خوبی در شناسایی آسیب پذیریهای هستههای سیستم عامل [۳۱-۳۳] به دست آوردهاند، اما این تکنیک به ندرت در چارچوبهای تست نفوذ موتور رندر استفاده شده است. در نهایت، چارچوبهای تست نفوذ رایج (مانند AFL [۱۹]) معمولاً نمونهها را به صورت تصادفی تولید میکنند که در تولید موارد تست HTML معتبر که از قوانین نحوی خاصی پیروی میکنند، ناکارآمد است.
برای رفع چالشهای فوق، این مقاله بر مطالعهی اصول تجزیهی DOM در موتور رندر تمرکز میکند و یک چارچوب “حلقهی فازی مدل شیء سند” (DFL) را به طور خاص برای موتور رندر پیشنهاد میکند. ابتدا، ما از چارچوب تست نفوذ AFL [۱۹] استفاده میکنیم و ایدههای مولد نمونهی DOM از FreeDom [۲۸] را با آن ادغام میکنیم. دوم، یک “مولد نمایش میانی جامع HTML” (HIRG) برای ساخت نمونههای HTML بر اساس قواعد DOM طراحی شده است. سوم، روش هدایت پوشش AFL و سرویس fork در DFL به عنوان توابع ابزار دقیق در نظر گرفته میشوند که هنگام اجرای نمونهها، بازخورد در مورد اطلاعات پوشش مسیر ارائه میدهند. در نهایت، از یک الگوریتم ذخیرهسازی موقت (cache) برای بهینهسازی سرعت فراخوانیهای API جاوااسکریپت استفاده میشود و مجموعهای از الگوریتمهای سریالسازی و غیرسریالسازی برای ذخیره و تبدیل نمونههای HTML طراحی شدهاند.
DFL با روشهای تست نفوذ موتور رندر موجود متفاوت است، زیرا ما بر کارایی و کیفیت تولید نمونه در عین تضمین اثربخشی چارچوب تست نفوذ تمرکز میکنیم. در عین حال، تولید نمونه با AFL ادغام میشود تا یک چارچوب تست کامل را تشکیل دهد. آزمایشهایی برای مقایسهی DFL با ابزارهای تست نفوذ DOM موجود با استفاده از آخرین نسخهی Chromium انجام میشود. نتایج تجربی نشان میدهد که DFL میتواند آسیب پذیریهای بیشتری را در موتور رندر کشف کند، از جمله آسیب پذیریهایی که توسط چارچوبهای مقایسهای مانند FreeDom شناسایی نشدهاند. یکی از آسیب پذیریهای تازه کشف شده توسط گوگل تأیید شده است. آزمایشها نشان میدهد که DFL چالشهای ساخت نمونه و جمعآوری پوشش را حل میکند و به نتایج بهتری برای تست موتورهای رندر دست مییابد.
به طور خلاصه، مشارکتهای اصلی ما به شرح زیر است:
- یک چارچوب تست نفوذ هدایتشده با پوشش کد به نام DFL برای موتور رندر پیشنهاد شده است. این چارچوب بر پایهی AFL ساخته شده تا به طور خاص موتور رندر در مرورگر را تست کند. مجموعهای از استراتژیها برای بهبود عملکرد تست نفوذ پیشنهاد شده است.
- یک مولد نمونهی HTML با ترکیب ایدهی تولید نمونهی مبتنی بر الگو و تولید ویژگی آگاه از زمینه طراحی شده است.
- یک ماژول پوشش کد پیادهسازی
در بخش ۲ شرح داده میشود. انگیزههای توسعهی DFL در بخش ۳ توضیح داده شده است. در بخش ۴، طراحی و پیادهسازی DFL را به صورت مفصل ارائه میکنیم. در بخش ۵، ارزیابی عملکرد DFL را انجام میدهیم. بخش ۶ به محدودیتهای DFL و کارهای آینده در زمینهی تست نفوذ موتور رندر در مرورگرها میپردازد.
۲. پیشزمینه
در این بخش، ابتدا به امنیت DOM میپردازیم، سپس تکنیکهای ساخت دادههای اولیه (seed) و انواع رایج آسیب پذیریها در مرورگرها را بررسی میکنیم. در نهایت، بحث مفصلی در مورد روش رایج کشف آسیب پذیری، یعنی تست نفوذ (fuzzing)، که در حال حاضر در این زمینه استفاده میشود، ارائه میدهیم.
۲.۱. امنیت DOM
مدل شیء سند (DOM) یک رابط برنامهنویسی برای زبانهای اسکریپتنویسی (مانند جاوااسکریپت) برای دستکاری صفحات HTML است. این مدل، محتوای یک صفحه HTML را با استفاده از یک ساختار درختی سازماندهی میکند و مستقل از پلتفرمها و زبانها است. در انتهای هر شاخهی درخت، یک گره وجود دارد که شامل لیستی از ویژگیها است. هر گره در درخت با یک کنترلکنندهی رویداد مرتبط است. با دستکاری ویژگیهای گرهها، محتوا و ظاهر سند قابل تغییر است و در نتیجه، اجرای منطق پردازش برنامه آغاز میشود. درخت DOM توسط موتور رندر، پردازش و به صفحات HTML تبدیل میشود.
انعطافپذیری ساختار DOM به طراح صفحه امکان مانور میدهد. در عین حال، این موضوع به مهاجمان نیز کمک میکند تا نمونههای DOM با روشهای مختلف حمله، مانند DOM Clobbering [۳۴]، حملات بدون اسکریپت [۳۵]، DOM-XSS [۳۶] و تولید نمونههای XS-Leaks [۳۷] را ایجاد کنند. ساخت نمونههای مخرب برای مهاجمان آسانتر میشود که این موضوع یک منبع مهم برای خرابی مرورگرها است. در عین حال، فرصتهایی را نیز برای ایجاد تغییرات در موارد تست در تست نفوذ فراهم میکند. ارسال نمونههای DOM سالم یا مخرب به مرورگر، یک روش رایج در بین محققان امنیتی برای انجام تستهای امنیتی است. در این مقاله، ما تکنیکهای ساخت نمونههای DOM را بررسی میکنیم که با روشهای فعلی کشف آسیب پذیری ترکیب شدهاند تا امنیت موتور رندر را بررسی کنیم.
۲.۲. امنیت موتور رندر
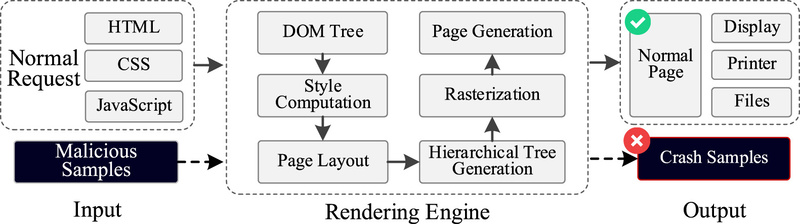
طبق آماری که در [۱] ارائه شده، ۶۷.۴٪ از آسیب پذیریهای مرورگر وب در موتور رندر کشف میشوند. موتور رندر مسئول تفسیر محتوای نمونه HTML، از جمله ساختار، طرحبندی و رفتار تعاملی صفحهی وب است و صفحهی وب رندر شده را به عنوان خروجی ارائه میدهد. روند کاری موتور رندر در شکل ۱ نشان داده شده است.
تحقیقات زیادی نشان داده است که اثربخشی تست نفوذ تا حد زیادی به کیفیت نمونههای ورودی بستگی دارد. با توجه به ویژگیهای هدف تست، با ساخت و وارد کردن نمونههای بالقوه مخرب، میتوان تا حد زیادی آسیب پذیریها را فعال کرد. بنابراین، شرط اصلی برای فعال کردن آسیب پذیریهای موتور رندر، ساخت نمونههای HTML مخرب است [۴۱]. در این کار، ما با ساخت نمونههایی که به طور خاص برای آسیب پذیریهای موتور رندر یا بررسی مسیرهای اجرای مختلف طراحی شدهاند، تست نفوذ را به انجام رساندهایم.
جدول 1. مقایسه Frameworkهای Fuzzing مرورگرها
Framework | Year | Coverage Guidance | Sample Serialization | Elemental Coverage | Context-sensitive | Sample Generation Method | Sample Test Method | Framework Integrity | Development Languages |
Wadi [44] | 2016 | ✗ | ✗ | Incomplete | ✗ | Template | S | ✗ | JavaScript |
DOMato [29] | 2017 | – | ✗ | Incomplete | ✗ | Template | S | ✗ | Python |
FreeDom [28] | 2020 | ✓ | ✓ | Near Complete | ✓ | Syntax | S | ✗ | Python |
DFL | 2024 | ✓ | ✓ | Complete | ✓ | Syntax and Template | F | ✓ | C++ |
توضیحات جدول:
* برخی از نتایج مورد استفاده در ستون Development Languages برای مقایسه در جدول از Favocado [10]، SAGE [38] و کد منبع چارچوبهای مربوطه گرفته شدهاند.
* در ستون Sample Test Method، کاراکتر S به معنای نیمهخودکار یا دستی و کاراکتر F به معنای خودکار (با استفاده از ماژول ForkServer) میباشد.
* ستون Framework Integrity : آیا Framework میتواند تست خودکار مرورگر را بعد از جمعآوری داده و تولید نمونه انجام دهد؟
آسیب پذیری عددی: هنگامی که مرورگر محتوای HTML را تجزیه میکند، برخی از فیلدهای داده از نوع عدد صحیح ممکن است به عنوان اندیس آرایهها یا طول آنها استفاده شوند. در طول فرآیند رندر، احتمالاً هیچ بررسی برای خارج از محدودهی اندیس یا سرریز عدد صحیح برای این فیلدها وجود ندارد. تولید نمونههای مخرب برای این نوع آسیب پذیریها نیازمند استفاده از یک مولد اعداد صحیح هوشمندانه است که در آن، مقادیر مرزی اعداد تولید شده اهمیت بیشتری دارند. برای انواع دادهی ممیز شناور نیز رویکرد مشابهی برای افزایش احتمال وقوع مقادیر مرزی و مقادیر خاص اتخاذ میشود.
آسیب پذیری Heap: انواع مختلفی از آسیب پذیریهای Heap در هستههای سیستم عامل وجود دارد و این نوع آسیب پذیریها در موتور رندر نیز دیده میشوند، مانند “استفاده پس از آزادسازی ” (UAF). در طول فرآیند تجزیهی نمونههای HTML، مرورگر ممکن است مقدار قابل توجهی از حافظهی Heap را تخصیص یا آزاد کند. ممکن است مواردی پیش بیاید که یک حافظهی Heap که قبلاً آزاد شده، به اشتباه دوباره آزاد شود یا حافظهی آزاد شده به صورت ناخواسته دوباره مورد استفاده قرار گیرد. این نوع آسیب پذیریها اغلب در APIهای جاوااسکریپت رخ میدهند.
آسیب پذیری منطقی: انواع مختلفی از خطاهای منطقی میتوانند در سناریوهای مختلف مانند هستههای سیستم عامل، برنامههای وب، برنامههای دسکتاپ و سیستمهای کنترل صنعتی وجود داشته باشند. مرورگرها نیز از این قاعده مستثنی نیستند. برنامهنویسان ممکن است به دلیل اجرای نادرست توابع خاص یا طراحی منطقی ضعیف الگوریتمها، ناخواسته آسیب پذیریهای پنهان را ایجاد کنند. این خطاها ممکن است منجر به خرابی سیستم شوند یا توسط اقدامات مخرب مورد سوء استفاده قرار گیرند.
۲.۳. تست نفوذ (Fuzzing)
تست نفوذ یک روش کارآمد و مؤثر برای تست خودکار نرم افزار است. AFL و Syzkaller دو چارچوب تست نفوذ محبوب هستند که امروزه مورد استفاده قرار میگیرند. فرآیند اصلی تست نفوذ با تولید تصادفی تعداد زیادی دادهی اولیه (seed) شروع میشود. این دادهها شامل اسناد HTML با کدهای CSS و جاوااسکریپت برای موتور رندر هستند. این دادهها اغلب فیلتر و تغییر داده میشوند تا نمونههای تست با کیفیت بالا در یک چارچوب تست نفوذ تولید شوند. سپس، نمونههای تست برای اجرا به برنامهی هدف داده میشوند و به طور همزمان وضعیت اجرای برنامه نیز بررسی میشود. پس از شناسایی یک رویداد خرابی، احتمال زیادی وجود دارد که برنامه دارای آسیب پذیری باشد. در نهایت، نمونههایی که باعث خرابی میشوند برای تجزیه و تحلیل بیشتر و شناسایی آسیب پذیری توسط محققان ذخیره میشوند.
تست نفوذ به طور فزایندهای مورد توجه دانشگاه و صنعت قرار گرفته و به نتایج قابل توجهی در کشف آسیب پذیریها دست یافته است.
سه روش اصلی برای تست نفوذ وجود دارد: تست نفوذ جعبه سفید، تست نفوذ جعبه سیاه و تست نفوذ جعبه خاکستری. تست نفوذ جعبه سفید در مواردی استفاده میشود که کد منبع برنامهی هدف مشخص باشد. به دلیل مشکلاتی مانند “انفجار مسیر”، معمولاً در تستهای سبکوزن استفاده میشود. تست نفوذ جعبه سیاه فقط بر ورودیها و خروجیهای برنامهی هدف تمرکز دارد و ساختارهای داخلی آن در نظر گرفته نمیشوند. تست نفوذ جعبه خاکستری یک روش تست بین تست نفوذ جعبه سفید و جعبه سیاه است که در آن تستکننده مقدار کمی از اطلاعات داخلی در مورد برنامهی هدف (مانند کد منبع، ساختار یا اطلاعات اجرا) را در اختیار دارد و اغلب در مرحلهی تست یکپارچهسازی نرم افزار استفاده میشود. برخلاف تست جعبه سفید، این تکنیک در طول فرآیند تست، با محدودیتهای مختلفی مواجه است.
Percentage | Effective Sample# | Sample# | Generator |
69.80% | 349 | 500 | Wadi |
41.40% | 207 | 500 | FreeDom |
10.40% | 52 | 500 | DOMato |
این روش اغلب برای جمعآوری اطلاعات مربوط به پوشش شاخههای کد در طول اجرای برنامهی هدف، به تکنیکهای ابزار دقیق متکی است و از این اطلاعات برای هدایت فرآیند تست نفوذ استفاده میشود [۵۰]. یک نمونهی شاخص، چارچوب تست نفوذ AFL است که در سال ۲۰۱۳ منتشر شد [۱۹].
۳. انگیزه
در سالهای اخیر، ابزارهای زیادی برای تولید نمونه برای تست امنیت مرورگر (مانند FreeDom [۲۸]، DOMato [۲۹]، Wadi [۴۴]) معرفی شدهاند (که در جدول ۱ نشان داده شده است). با این حال، به دلیل کد پیچیدهی مرورگر و فضای ورودی بسیار بزرگ، چالشهایی همچنان وجود دارد که باعث میشود عملکرد ابزار نتواند تمام منطق موجود در بخش پشتی مرورگر را پوشش دهد. نمونههای تولید شده به سختی میتوانند به طور کامل قواعد زبان HTML را پوشش دهند و چارچوبهای منتشر شده به ندرت از تکنیکهای پیشرفتهی بازخورد هدایتشده با پوشش در حوزهی تست نفوذ استفاده میکنند و این امر باعث ناکارآمدی کشف آسیب پذیریها میشود (شکل ۱۰ را ببینید). برای مقابله با این چالشها، ما یک چارچوب جدید به نام DFL را با سه انگیزهی اصلی طراحی میکنیم: بهینهسازی مولد قواعد نحوی، معرفی تکنیک پوشش و بهبود کارایی تست نفوذ که در زیر توضیح داده شدهاند.
مولد قواعد نحوی: همانطور که میدانیم، استفادهی مستقیم از AFL اصلی [۱۹] برای تست نفوذ مرورگر دشوار است، زیرا نمیتواند نمونههای HTML تولید کند که کاملاً با قواعد نحوی رندر مطابقت داشته باشند. چارچوبهای پیشرفتهی تست نفوذ مرورگر عمدتاً از گرامرهای مستقل از متن (CFG) (نیمه) دستنویس (مانند DOMato [۲۹]، Minerva [۲۶]، SAGE [۳۸]) و رکوردهای زمینه (مانند FreeDom [۲۸]) برای تولید ورودیهای ساختاریافته استفاده میکنند. این رویکردها تا حد زیادی کیفیت نحوی نمونهها را بهبود بخشیدهاند، اما کیفیت خود نمونهها را تضمین نمیکنند. با یک مطالعهی تجربی، متوجه شدیم که این مولدها هنوز جای زیادی برای بهبود دارند (جدول ۲ را ببینید). نمونههای با کیفیت بالا میتوانند آسیب پذیریهای عمیق را فعال کنند و دو روش اصلی ساخت وجود دارد: یادگیری ماشین و جمعآوری دستی قوانین. روشهای یادگیری ماشین [۵۳، ۵۴] به مجموعهدادههای بزرگ و منابع محاسباتی زیادی متکی هستند و خروجیهای تولید شده قابل تفسیر و تنظیم نیستند. خلاصهنویسی دستی قوانین نحوی (مانند [FreeDom [۲۸) در کنترل دقیق ساختار و معنای کد تولید شده خوب است، اما به دلیل پیچیدگی و گستردگی فضای ورودی مرورگر، برآورده کردن نیاز به تولید قواعد نحوی پیچیده دشوار است. در این کار، DFL با طراحی مولدهای خاص زبان که ایدههای تولید مبتنی بر الگو و مبتنی بر گرامر را ترکیب میکند، به مشکل تولید نمونههای با کیفیت بالا میپردازد.
چارچوب تست نفوذ هدایت شده با پوشش: این ایده به طور گسترده در تست امنیت هستهی سیستم عامل استفاده میشود [۳۰، ۳۲، ۵۵] و با نتایج بسیار موفقیتآمیز در سناریوهای مختلف تست نفوذ اعمال شده است. به عنوان مثال، در چارچوبهای TriforceAFL و kAFL، اضافه کردن بازخورد پوشش ردیابی Intel PT به kAFL منجر به بهبود ۴۰ برابری شد.
در کارایی تست نسبت به TriforceAFL [۳۲، ۵۶] بهبود ۴۰ برابری ایجاد شد. با این حال، موارد نمایشی کمی از استفاده از پوشش کد برای بهبود کارایی تست نفوذ موتور رندر در سناریوهای تست امنیت مرورگر وجود دارد. FreeDom پیشرفته، روش جهش هدایت شده با پوشش را پیادهسازی میکند، اما این روش تأثیر بسیار کمی بر بهبود اثربخشی کشف باگها دارد و پوشش بلوکهای اصلی کد حداکثر ۲.۶۲٪ قبل و بعد از استفاده از این تکنیک افزایش یافته است [۲۸، ۵۷]. ما در DFL، از ایدهی ابزار دقیق AFL برای قرار دادن توابع جمعآوری پوشش در طول کامپایل مرورگر استفاده میکنیم (شکل ۲ را ببینید) و بازخورد مربوط به مسیر بررسی شده در طول اجرای نمونه را برای بهینهسازی تولید نمونههای جدید و بهبود کارایی تست نفوذ در اختیار چارچوب قرار میدهیم.
کارایی تست نفوذ: تجزیه و تحلیل تطبیقی عملکرد برنامههای توسعه داده شده در زبانهای برنامهنویسی رایج نشان میدهد که ++C به عملکرد بسیار بالایی دست مییابد [۵۸، ۵۹]. برنامههای نوشته شده با پایتون و جاوااسکریپت به ترتیب ۸.۰۱ و ۲۹.۵ برابر کندتر از برنامههای ++C هستند. بیشتر ابزارهای تست نفوذ مرورگر فعلی با پایتون [۲۴، ۲۸، ۲۹]، جاوااسکریپت [۴۴] و سایر زبانهای اسکریپتنویسی نوشته شدهاند که باعث کاهش کارایی تست نفوذ میشود. به عنوان مثال، در شرایط سخت افزاری و نرم افزاری یکسان برای تولید چندبارهی ۵۰۰۰ نمونهی تست HTML (۱۰ بار)، FreeDom به طور متوسط ۰.۴۲۸ ثانیه برای هر نمونه زمان مصرف میکند، در حالی که مولد توسعه داده شده با ++C فقط ۰.۲۸۹ ثانیه زمان میبرد. بنابراین، ما از ++C برای پیادهسازی DFL استفاده میکنیم تا کارایی تست نفوذ را به طور قابل توجهی بهبود بخشیم.
۴. طراحی و پیادهسازی
این بخش به طور جامع طراحی و پیادهسازی چارچوب DFL را شامل چهار بخش کلیدی شرح میدهد. ابتدا، بخش ۴.۱ مروری کلی از چارچوب DFL ارائه میدهد. سپس، بخش ۴.۲ طراحی و پیادهسازی چندین زیرمولد را شرح میدهد. بخش ۴.۳ به جزئیات پیچیدگیهای طراحی الگوریتمهای سریالسازی و غیرسریالسازی میپردازد. در نهایت، بخش ۴.۴ بررسی عمیقی از طراحی اجراکننده با توضیحات دقیق در مورد ابزار دقیق، جمعآوری پوشش و نظارت بر حافظه ارائه میدهد.
۴.۱. نمای کلی چارچوب
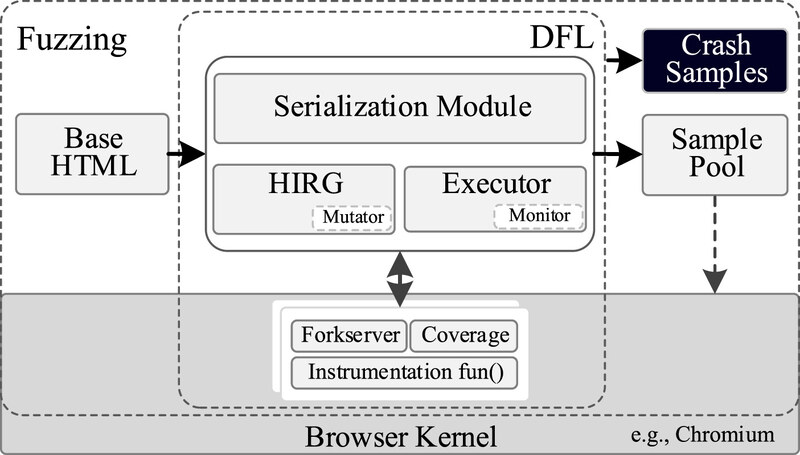
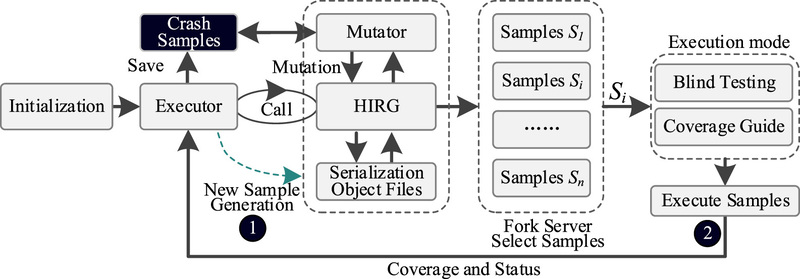
DFL از پنج بخش تشکیل شده است: اجراکننده، مولد HIR، ماژول سریالسازی، ماژول نظارت و ماژول ابزار دقیق. اجراکننده، مرکز تمام ماژولهای DFL است و مسئول اتصال قابلیتهای سایر اجزا است. مولد، نمونههای HTML را با زیرمولدهای مختلف تولید میکند. ماژول سریالسازی مسئول تبدیل بین دو حالت نمونههای تولید شده است: اشیاء در حافظه و فایلها روی دیسک. ماژول نظارت با ماژول ابزار دقیق برای دریافت اطلاعات پوشش و وضعیت برنامهی هدف ارتباط برقرار میکند. در نهایت، ماژول ابزار دقیق، اطلاعات مورد نظر را با ابزار دقیق مرورگر جمعآوری میکند. معماری کلی چارچوب در شکل ۲ نشان داده شده است.
ما نمونههای HTML را از یک فایل HTML پایه (فقط با تگهای اصلی HTML) با استفاده از مولد HIRG تولید میکنیم که به طور مکرر در طول فرآیند تولید فراخوانی میشود. در ابتدا، pool نمونه خالی است و ما به تدریج پس از تست کور، نمونههای HTML معتبر را به pool اضافه میکنیم. اجراکننده نمونههای HTML را میخواند و آنها را برای اجرا به سرور fork ارسال میکند. ماژول نظارت، اطلاعات پوشش نمونهها را هنگام اجرا جمعآوری میکند. نمونهها بر اساس پوشش تغییر داده میشوند تا نمونههای جدید تولید شوند و هنگام وقوع خرابی توسط ماژول سریالسازی ذخیره میشوند. در مقایسه با Freedom که میتواند از هر دو حالت تولید و حالت هدایت شده با پوشش استفاده کند، چارچوب DFL ابتدا تست کور را انجام میدهد و سپس تستهای بعدی را بر اساس نمونههای معتبر ترکیب شده با پوشش انجام میدهد.
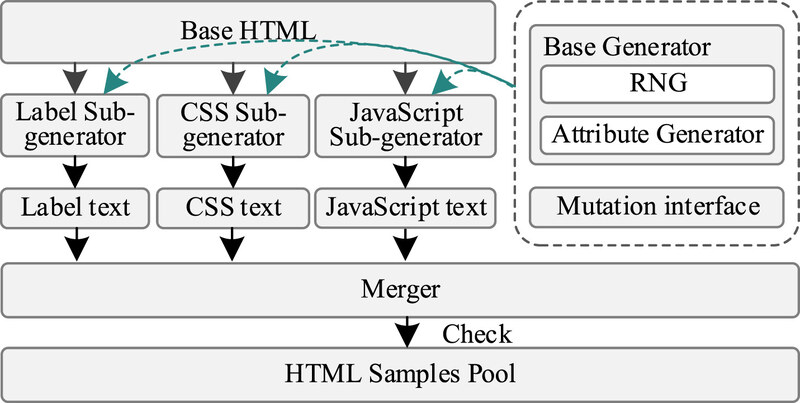
۴.۲. مولد HIR
ورودی نمونهی HTML توسط مرورگر عمدتاً از DOM اولیه، CSS و JS تشکیل شده است. بنابراین، مولد HIR در چارچوب DFL با سه زیرمولد برای Label،CSS و JS به همراه یک مولد پایه طراحی شده است. گرههای شیء Label که توسط زیرمولد label تولید میشوند، به درخت DOM اضافه میشوند، در حالی که متنهای تولید شده توسط زیرمولدهای CSS و JS به ترتیب در تگهای <style> و <script> قرار میگیرند. این سه زیرمولد به طور مشترک یک درخت نحوی را با زمینه یکسان نگهداری میکنند و زیرمولدهای جداگانه، وضعیت ساخته شدهی درخت فعلی را با یکدیگر به اشتراک میگذارند. در مقایسه با FreeDom، زیرمولدهای مختلف در DFL فایلهای متنی تولید میکنند و سپس از ماژولهای ساخت نمونه بر اساس استانداردهای نحوی DOM برای تکمیل تولید نمونه استفاده میکنند. در فرآیند تصادفیسازی، اعداد تصادفی از مولد پایه میآیند و دادههای ویژگیهای مختلف از مولد ویژگی میآیند. روند کاری مولد HIRG در شکل ۳ نشان داده شده است.
۴.۲.۱. مولد پایه
مولد پایه مسئول تولید اعداد تصادفی و ویژگیهایی است که برای تولید متن زیرمولدهای label ،CSS و JS استفاده میشوند.
مولد عدد تصادفی: در زبانهای برنامهنویسی رایج، توابع تصادفی (مانند تابع rand در C) معمولاً از محاسبات ریاضی و یک مقدار اولیه (seed) برای تولید اعداد شبه تصادفی استفاده میکنند. با این حال، این توابع یک دورهی تناوب محدود دارند که پس از آن، توالی اعداد تولید شده تکرار میشود و در نتیجه، میزان تصادفی بودن نتایج کاهش مییابد. ما توابع تصادفی در زبانهای برنامهنویسی رایج را با اندازهگیری و در نظر گرفتن نویزهای عملیاتی (مانند فعالیتهای ماوس، صفحهکلید و سایر دستگاهها) بهبود میدهیم.
مولد ویژگی: شیء ویژگی در یک متن HTML از یک جفت “نام” و “مقدار” تشکیل شده است. مقدار میتواند یک عدد طبیعی، یک رشته با علامت درصد یا انواع دادهی دیگر باشد. ما رابطهایی برای هر نوع داده طراحی میکنیم تا تنوع ویژگیها را افزایش دهیم. برای هر رابط، تابع تولید مقدار ویژگی مربوطه را به طور جداگانه طراحی میکنیم و سپس یک جدول نگاشت سراسری برای نام-مقدار ایجاد میکنیم.
۴.۲.۲. زیرمولد Label
زیرمولد Label گرههای Label دلخواه را به درخت DOM اضافه میکند که جزء اصلی HTML است. هر گره Label شامل یک تگ (نام Label)، تعدادی ویژگی و گرههای Label فرزند است و یک جدول نگاشت (به عنوان مثال، label_table) بین این سه ایجاد میکند. ما تمام نامهای Label را به عنوان کلید (Key) جدول نگاشت جمعآوری میکنیم تا مقادیر کاندید را برای متغیرهای تگ (به عنوان مثال، name) فراهم کنیم. در عین حال، از کلید جدول نگاشت برای محدود کردن محدودهی مقادیر ویژگیهای Label استفاده میکنیم. برای نمایش روابط پیچیدهی نگاشت ویژگیهای Label، کلاسهایی (به عنوان مثال، Element) را طراحی میکنیم و یک اشارهگر به والد (parent pointer) برای اشاره به والد گرهی فعلی اضافه میکنیم.
هنگام تولید تگ، مقدار صحیح برگشتی توسط RNG (مولد اعداد تصادفی) برای انتخاب مقدار کاندید از جدول Label استفاده میشود. هنگام تولید ویژگیها، جدول تگ-ویژگی جستجو میشود تا لیستی از ویژگیهای تگ مربوطه به دست آید و مقادیر ویژگیها به صورت تصادفی انتخاب میشوند. علاوه بر این، هر گره میتواند به صورت تصادفی یک گره فرزند را برای اطمینان از تصادفی بودن ساختار، درج کند. فرآیند اصلی تولید متن یک گرهی Label در الگوریتم ۱ نشان داده شده است.

۴.۲.۳. زیرمولد CSS
قواعد نحوی CSS شامل یک نام انتخابگر و ویژگیهای مختلف در یک درخت چند جملهای با ارتفاع ۱ است. روشهای مختلفی برای نمایش یک انتخابگر وجود دارد. فرآیند تولید از توابع تصادفی برای تولید نام تعداد زیادی انتخابگر و ویژگی CSS استفاده میکند که به یک شیء گره در درخت DOM تبدیل میشوند. هنگام تولید نامهای انتخابگر، زیرمولد CSS، محدودهی انتخاب تصادفی نامها را به لیستی از اشیاء محدود میکند (اشیاء موجود در درخت DOM بر اساس قواعد نحوی جمعآوری میشوند). کلاس والد CSS_Selector در زیرمولد فرزند CSS برای مدیریت تمام اشیاء انتخابگر طراحی شده است. زیرکلاس آن برای طراحی سازندهها برای تمام نامهای انتخابگر طراحی شده و نامهای سازنده را به عنوان یک جدول سراسری که بر اساس نام انتخابگر اندیسگذاری شده، ذخیره میکند. جدول سراسری یک نگاشت بین سازنده و دادههای ویژگی ایجاد میکند که مقادیر به صورت تصادفی انتخاب شده توسط نام انتخابگر محدود شدهاند. در نهایت، تابع عضو، شیء انتخابگر را نمونهسازی میکند تا متن CSS مطابق با قواعد نحوی CSS تولید کند.
۴.۲.۴. زیرمولد جاوااسکریپت
جاوااسکریپت یک زبان اسکریپتنویسی مهم در ساخت صفحات HTML است و به طور گسترده برای کنترل عناصر، پاسخهای تعاملی و پردازش دادهها در صفحه استفاده میشود. قواعد نحوی HTML برای بسیاری از اشیاء label، برای تعداد زیادی تابع برای کنترل رفتار label طراحی شده است. به منظور جامعتر کردن تستهای نمونهی تولید شده، ما جداول نگاشت تابعی را میسازیم که از سه عنصر تشکیل شدهاند: برچسبها (labels)، توابع و ویژگیها. از جاوااسکریپت برای کپسولهسازی اشیاء گرهی تابعِ برچسبگذاری شده در درخت DOM به توابعی شبیه به فراخوانی API استفاده میشود تا پوشش نمونههای تولید شده افزایش یابد.
Args | Api name | Object | RCT |
arg1, arg2, arg3, … | func | .Obj | =Var x |
ساختار هر خط کد API جاوااسکریپت به سه بخش تقسیم میشود که برای دریافت مقدار برگشتی (متغیر Ret)، نام تابع API و پارامترهای تابع (عبارت “obj.” پیشوند شیء هنگام فراخوانی است) استفاده میشوند. این سه بخش به طور مستقل به عنوان زیرکلاس طراحی میشوند که هر کدام مسئول تولید و اصلاح مقادیر خروجی زیرکلاسها هستند. از طریق تغییر مقادیر پارامترهای ورودی، API میتواند برای کشف آسیبپذیریهای احتمالی آزمایش شود. ساختار کد API جاوااسکریپت در جدول ۳ نشان داده شده است.
متنهای جاوااسکریپت بر اساس اشیایی که از قبل در درخت DOM فعلی وجود دارند، تولید میشوند. با این حال، برای اطمینان از مرتبط بودن اشیاء زمینه، اشیایی که در زمان ساخت قابل انتخاب هستند، شامل اشیاء متغیر Ret (کنترلکنندههای برگشتی) که به تازگی در طول فراخوانی API جاوااسکریپت اضافه شدهاند نیز میشوند. تعداد توابع API از جدول نگاشت بر اساس نام شیء و وزن به دست میآید. وزن بر اساس تعداد توابع API محاسبه میشود و احتمال انتخاب را تعیین میکند.
۴.۲.۵. رابط جهش
ما یک رابط جهش یکپارچه (به عنوان مثال، mutation()) را پیشنهاد میکنیم و سه زیرمولد، نامها و مقادیر ویژگی را از طریق این رابط تغییر میدهند. تابع جهش با توجه به ویژگیهای زیرمولد، روشهای مختلفی دارد و از پنج عملیات: درج، حذف، جایگزینی، ادغام تصادفی اشیاء و تغییر مقادیر شیء برای تکمیل جهش استفاده میکند. جزئیات جهش اشیایی که هر زیرمولد روی آنها عمل میکند کمی متفاوت است. زیرمولد CSS عملیات جهش را با اضافه و کم کردن انتخابگرها و ویژگیها کامل میکند. اشیاء ویژگی برای گرههای HTML (از جمله SVG) میتوانند با انتخاب تصادفی یک ویژگی و یک کلاس از ویژگیها در گره تغییر داده شوند. عملیات ادغام تصادفی با ادغام تمام یا بخشی از ویژگیهای دو شیء گره انجام میشود. هنگامی که زیرمولد یک عملیات جهش را آغاز میکند، رابط جهش، ماژول غیرسریالسازی را برای تبدیل دادههای تست از مولد نمونه به دادههای وضعیت در حافظه فراخوانی میکند و سپس نمونهها را به متن سریال میکند یا هنگام تکمیل جهش آنها را در درخت DOM مینویسد.
۴.۲.۶. ساختار نمونه
سه زیرمولد بر اساس RNG توسعه داده شدند. زیرمولدهای مختلف بر اساس استانداردهای نحوی HTML هستند تا تولید متنهای مربوطه را بدون اتصال مستقیم بین انواع مختلف متن انجام دهند. هر سند HTML از یک درخت نحوی DOM، چند CSS و چند جاوااسکریپت تشکیل شده است. ما دادههای متنی تولید شده توسط این زیرمولدها را به ترتیب در قالب استاندارد سند HTML ادغام میکنیم تا آنها به نمونههای ورودی تبدیل شوند که توسط چارچوب تست نفوذ DFL قابل تشخیص هستند. هنگامی که نمونه ساخته میشود، زیرمولد مربوطه مطابق با شیء گرامر HTML (به عنوان مثال، شیء Label زیرمولد label را فراخوانی میکند) فراخوانی میشود و سپس زیرمولد، رابط جهش را فراخوانی میکند که جهش را با تغییر اطلاعات گرههای label، اطلاعات CSS و ساختار کد جاوااسکریپت کامل میکند و متن تولید شده را برمیگرداند. دادههای متنی تولید شده توسط جهش تضمین میکند که نمونههای HTML مصنوعی دارای ویژگیهای متنوع و احتمالاً آسیبپذیری هستند که الزامات ورودی چارچوب تست نفوذ را برآورده میکنند.
۴.۳. ماژول سریالسازی
ماژول سریالسازی شامل دو روش است: سریالسازی و غیرسریالسازی. آنها تبدیل بین فایل متنی و دادههای درون حافظه درخت DOM مشابه را فعال میکنند. در طول سریالسازی، ماژول درخت شیء را به صورت بالا به پایین پیمایش میکند. دادههای گرههای فرزند و گرههای برگ درخت را با استفاده از نام کلاس به عنوان شاخص، در قالب یک فایل متنی ذخیره میکند. نام کلاس به عنوان راهنما برای الگوریتم غیرسریالسازی عمل میکند.
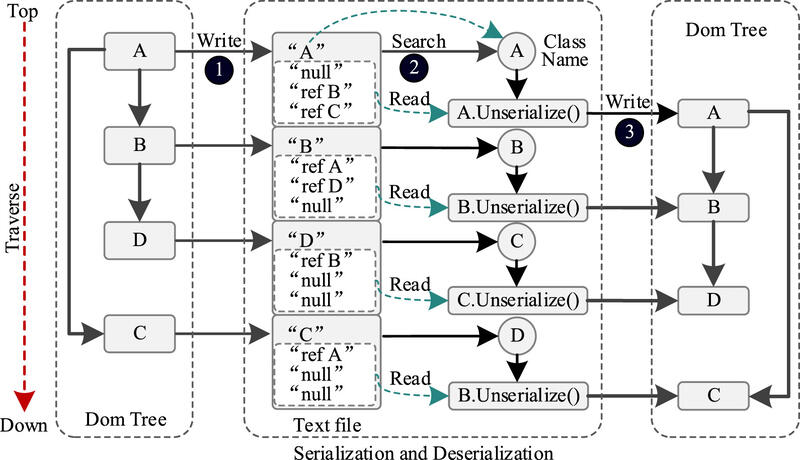
الگوریتم غیرسریالسازی از نام کلاس برای تعیین شیء بعدی و نوع آن برای عملیات استفاده میکند. به طور متوالی دادهها را از جریان فایل سریال شده میخواند و اشیاء را بر این اساس بازیابی میکند. این فرآیند را میتوان به عنوان یک ماشین خودکار قطعی (DFA) در نظر گرفت، جایی که ماشین حالت با یک حالت اولیه خالی شروع میشود و دادهها را به ترتیبی که نوشته شدهاند از جریان فایل میخواند. از هر رشته برای ایجاد شیء مربوطه استفاده میشود. شکل ۴ فرآیند تبدیل سریالسازی را نشان میدهد.
در شکل ۴، درخت DOM و فایل متنی سریال شده به ترتیب در حافظه و روی دیسک ذخیره میشوند. هنگامی که یک درخواست جهش توسط مولد نمونه آغاز میشود، ماژول سریالسازی غیرسریالسازی را روی فایل متنی انجام میدهد و دادههای حاصل را در حافظه بارگذاری میکند. درخت DOM را به یک شیء مولد قابل اجرا توسط تابع جهش بازیابی میکند. پس از غیرسریالسازی، مولد نمونه، رابط جهش mutation() را فراخوانی میکند تا جهشهایی را روی درخت نحوی DOM انجام دهد. به عنوان مثال، هنگامی که برنامه غیرسریالسازی رشته “A” را میخواند، سازنده شیء A را برای ایجاد یک نمونه از شیء A فراخوانی میکند. سپس توابع شیء را برای اختصاص مقادیر به متغیرهای عضو شیء فراخوانی میکند. با ادغام فرآیندهای سریالسازی و غیرسریالسازی با رابط جهش، میتوانیم به طور مؤثر درخت نحوی DOM را جهش دهیم و نمونههای HTML جدید تولید کنیم.
۴.۴. اجراکننده
اجراکنندهی چارچوب DFL به طور مداوم مولد HIR را برای ساخت نمونههای HTML فراخوانی میکند و آنها را برای اجرا به سرور fork ارسال میکند. همچنین وضعیت مرورگر را نظارت میکند و اطلاعات مربوط به پوشش را جمعآوری میکند. گردش کار اجراکننده در شکل ۵ نشان داده شده است.
دو حالت اجرا برای اجراکننده وجود دارد: تست کور و جهش هدایتشده با پوشش که به صورت خودکار به صورت متناوب اجرا میشوند. به طور پیش فرض، تست کور انجام میشود که شامل تولید، تست و ذخیره نمونههای تصادفی است. اگر پوشش پس از مدت زمان مشخصی (به عنوان مثال، آستانه ۶ دقیقه) افزایش نیابد، به حالت جهش هدایتشده با پوشش تغییر میکند. در حالت جهش هدایتشده با پوشش، فرآیند جهش بر اساس یک نمونه خرابی آغاز میشود. در صورت خرابی مرورگر، اجراکننده نمونه تست فعلی 𝑆𝑖 را ذخیره میکند و فرآیند جهش نمونه را آغاز میکند. فرآیند جهش یک نمونه جدید 𝑆′𝑖 را از نمونه خرابی 𝑆𝑖 بر اساس یک الگوریتم ژنتیک تولید میکند. نمونه جدید 𝑆′𝑖 به روشی مشابه اجرا و نظارت میشود. اگر بهروزرسانی پوشش وجود داشته باشد، نمونه جدید 𝑆′𝑖 حفظ میشود، در غیر این صورت، حذف میشود.
۴.۵. نظارت و ارتباطات
ماژولهای نظارت مسئول ارتباط با تابع ابزار دقیق fun() هستند. تابع ابزار دقیق در طول کامپایل به مرورگر تزریق میشود. هدف آن تسهیل اجرای نمونههای تست، نظارت بر وضعیت هسته در طول اجرا و جمعآوری اطلاعات مسیر پوشش نمونهها است.
سرور Fork: ما از سرور Fork از AFL [۱۹] استفاده میکنیم که در عملکرد ارتباطی خود بین اجراکننده و برنامه ابزار دقیق برتری دارد. برنامه fork و کد جمعآوری پوشش به طور همزمان در طول کامپایل به بلوک اصلی برنامه هدف ابزار دقیق میشوند. یک دستور فراخوانی در هر بلوک اصلی برای فراخوانی توابع تجاری برنامه fork درج میشود. قبل از فراخوانی، تنظیم یک متغیر سراسری بررسی میشود. اگر تنظیم نشده باشد (نشان میدهد که سرور Fork در حال اجرا نیست)، تابع تجاری برنامه fork اجرا میشود. در غیر این صورت، بررسی ابزار دقیق فعلی رد میشود. در طول زمان اجرا، هنگامی که سرور Fork دستورات کنترلی را از اجراکننده دریافت میکند، یک فرآیند جدید را با استفاده از دستور fork ایجاد میکند و یک کپی جداگانه ایجاد میکند که حافظه را با فرآیند اصلی به اشتراک میگذارد. این امر زمان پاسخ سریعتری را در صورت عدم وجود عملیات نوشتن داده فراهم میکند. این ویژگی استفاده از fork نیاز به بارگذاری و پیوند پویا برنامه را از بین میبرد و در نتیجه در زمان تجزیه و بارگذاری فایلها صرفهجویی میکند.
جمعآوری پوشش: ویژگی جمعآوری پوشش، کد بازخورد پوشش به نام بلوک کد ابزار دقیق (ICB) را از چارچوب AFL [۱۹] در خود جای داده است. با قرار دادن کد ICB در کد میانی از طریق یک ماژول LLVM Pass سفارشی، به جمعآوری پوشش دست مییابد. کد ICB در ابتدای هر بلوک اصلی قرار میگیرد. در کد خود، ما دو شناسه تعریف میکنیم: یکی نشان دهنده شماره بلوک اصلی فعلی (cBn) و دیگری نشان دهنده شماره بلوک اصلی قبلی در مسیر اجرا (preBn) است. ما یک عدد تصادفی cBn را به عنوان خط اول ICB درج میکنیم. یک عملیات XOR بین cBn و preBn انجام دهید تا اندیس بلوک کد به دست آید. سپس، دادههای پوشش را در موقعیت مربوطه در حافظه مشترک جمعآوری کنید. ما با استفاده از shmat() (از API SHM در لینوکس استفاده میشود) حافظه مشترک ایجاد میکنیم و سپس اجراکننده دادههای حافظه مشترک را با استفاده از shmget() میخواند و از این طریق بازخورد پوشش را از توابع ابزار دقیق بازیابی میکند.
نظارت بر حافظه: هدف از نظارت بر حافظه، تشخیص آسیب پذیریهایی است که ممکن است باعث خرابی هسته نشوند. تشخیص این نوع آسیبپذیریها دشوار است زیرا هنگام فعال شدن توسط یک نمونه، هیچ علامت واضحی مانند دسترسیهای خارج از محدودهی آرایه در مقیاس کوچک نشان نمیدهند. برای دستیابی به این هدف، ما ابزار AddressSanitizer (ASan) [۶۰] را در طول فرآیند ابزار دقیق اضافه کردهایم. ASan یک ابزار سریع تشخیص خطای حافظه است که از یک ماژول ابزار دقیق کامپایلر و یک کتابخانه زمان اجرا تشکیل شده است که شامل توابعی مانندmalloc() و free() است. این یک افزونه تشخیص خطای حافظه مبتنی بر LLVM است. در طول کامپایل در برنامه ابزار دقیق میشود تا آسیب پذیریهای حافظه را بررسی کند. میتواند آسیب پذیریهای حافظه مانند سرریز heap، استفاده پس از آزادسازی، سرریز پشته و نشت حافظه را تشخیص دهد. هنگامی که این مشکلات در برنامه رخ میدهند، ASan اجرای برنامه را متوقف میکند و اطلاعات مربوط به محل مشکل و نوع آسیب پذیری را چاپ میکند. سیگنال خاتمه برنامه توسط برنامه نظارت در چارچوب DFL، که به عنوان حالت خرابی شناسایی میشود، دریافت و به اجراکننده ارسال میشود.
Classification | Configuration | Parameters |
Hardware | CPU | Intel(R) Xeon(R) CPU E7-4850 V2, 2.30 GHz, 4 Socket, Supports Intel VT-x |
Memory | ECC DDR3 1600 MHz, 32 GB, 8 Pieces | |
Hard Drive | SATA3 2TB, 2 Pieces | |
Software | Operating system | Ubuntu 21.04 LTS Desktop-amd64, kernel version 5.15.0 |
Browser kernel | Chromium 101.0.4951.8 (Developer build) (64-bit) | |
Compilers | Clang 14.0.0 | |
Fuzzing framework | AFL v2.57b |
در ماژول نظارت بر اجرای فرآیند، یک تایمر با هدف تعیین محدودیت زمانی برای اجرای هر تست نمونه طراحی کردهایم. اگر یک فرآیند نتواند در مدت زمان مشخص شده نتیجهای تولید کند، نشان میدهد که تست فعلی ممکن است نمونهای را با یک حلقه بینهایت یا سایر عملیات بیمعنی اجرا کند. برای صرفهجویی در منابع سیستم، فرآیند تست شده با زمان منقضی شده به اجبار خاتمه مییابد.
۵. آزمایشها
در این بخش، ارزیابی دقیقی از چارچوب ما ارائه شده است. در بخش ۵.۲، سرعت و کیفیت تولید نمونه HTML ارزیابی میشود. علاوه بر این، در بخش ۵.۳، عملکرد چارچوب ما و سایر چارچوبهای فازینگ محبوب، از جمله معیارهای مبتنی بر پوشش، مقایسه میشوند. در نهایت، در بخش ۵.۴، قابلیت کشف خرابی چارچوب ما و آسیبپذیریهای کشف شده گزارش میشوند.
۵.۱. تنظیمات آزمایشی
راهاندازی محیط: DFL بر اساس چارچوب فازینگ AFL پیادهسازی شده است، همانطور که در شکل ۲ نشان داده شده است. این چارچوب بر روی سیستم عامل Ubuntu 21.04 با Clang 14 به عنوان محیط کامپایل توسعه و آزمایش شده است. هدف برای تست، هسته مرورگر ۶۴ بیتی Google Chromium بود. نسخههای هسته مرورگر و چارچوب AFL مورد استفاده در آزمایشها، آخرین نسخههای موجود در زمان نوشتن این سند بودند. جزئیات پیکربندی سخت افزار و نرم افزار در جدول ۴ نشان داده شده است.
چارچوبهای مقایسه شده: ما سه چارچوب مولد یا فازینگ (که در مجموع به عنوان چارچوب شناخته میشوند) را برای مقایسه انتخاب میکنیم که عبارتند از DOMato،Wadi و FreeDom. با این حال، این چارچوبها قابلیتهای قوی تولید نمونه دارند اما قابلیتهای تست، جمعآوری داده و تست خودکار را ارائه نمیدهند. برای رفع این مشکل، ما ماژولهای تولید نمونه سه چارچوب را به عنوان مولدهای مختلف در چارچوب DFL خود قرار دادیم تا مقایسه منصفانه را تضمین کنیم.
معیارهای ارزیابی: ما از سرعت تولید نمونه، اعتبار نمونه، پوشش مسیر و قابلیت کشف خرابی (کیفیت و کمیت) به عنوان معیارهای ارزیابی استفاده میکنیم. سرعت تولید نمونه شمارشی از زمان مصرف شده توسط هر مولد نمونه برای تولید تعداد مشخصی نمونه است و میتواند به طور مؤثر بازده اجزای مولد در چارچوب را منعکس کند. اعتبار نمونه به تعداد نمونههای معتبری اشاره دارد که میتوانند توسط نحو هسته تجزیه شوند و اجرای در طول مسیرهای معتبر را فعال کنند. این نشان دهنده کیفیت نمونههای تولید شده است. پوشش مسیر به تعداد مسیرهای اجرای معتبری اشاره دارد که هدف تحت تست را در واحد زمان پوشش میدهند. پوشش مسیر بالاتر نشان دهنده بررسی مؤثرتر رفتار برنامه است. قابلیت کشف خرابی به تعداد خرابیهایی اشاره دارد که باعث خرابی هدف تحت تست میشوند و خرابیهای با کیفیت بالا نشان دهنده آسیب پذیریهای بالقوه در برنامه هستند.
۵.۲. عملکرد تولید نمونه
۵.۲.۱. سرعت تولید
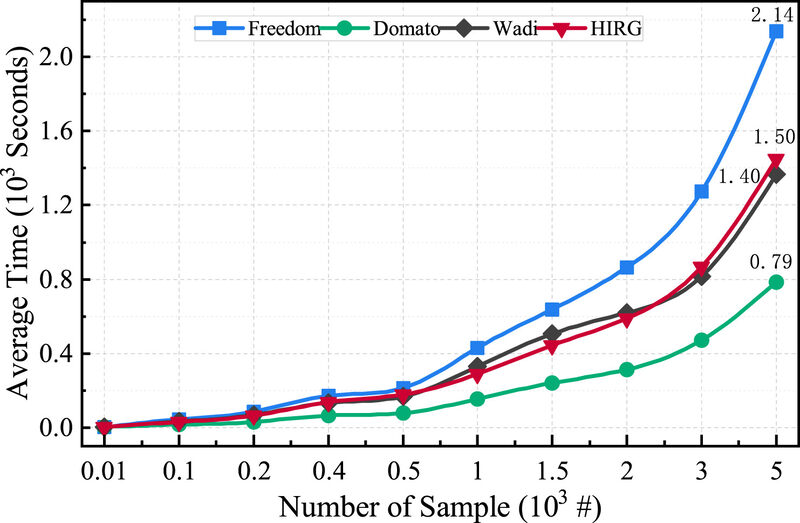
توانایی کشف آسیب پذیری چارچوب فازینگ به بازده سرعت تولید نمونه مولد نمونه بستگی دارد. برای مقایسه سرعت تولید نمونه، ما مولدها را در سه چارچوب محبوب (Domato، Wadi، FreeDOM) و HIRG در DFL خود مقایسه میکنیم. ما زمان صرف شده توسط هر مولد برای تولید تعداد ثابتی نمونه را مقایسه میکنیم. ده دسته درخواست نمونه برای هر مولد ارسال میشود که تعداد نمونهها در هر دسته به ترتیب ۱۰، ۱۰۰، ۲۰۰، ۴۰۰، ۵۰۰، ۱۰۰۰، ۱۵۰۰، ۲۰۰۰، ۳۰۰۰ و ۵۰۰۰ است. زمان صرف شده توسط هر مولد برای تکمیل هر وظیفه دستهای ثبت میشود. هر وظیفه ۱۰ بار تکرار میشود و میانگین زمان گزارش میشود. نتایج زمان تولید نمونه در شکل ۶ نشان داده شده است.
دادههای نشان داده شده در شکل ۶ نشان میدهد که در محدوده تولید ۱۰۰-۵۰۰ نمونه، چهار مولد مصرف زمان مشابهی دارند. با این حال، از تولید ۵۰۰ نمونه شروع میشود، با افزایش مقدار نمونه، تفاوت قابل توجهی در زمان صرف شده وجود دارد. به طور کلی، FreeDom که با استفاده از پایتون توسعه یافته و پتانسیل بهینهسازی قابل توجهی در الگوریتمهای داخلی خود دارد، کمترین سرعت تولید نمونه را دارد. از سوی دیگر، DOMato سریعترین است، اما به عنوان یک مولد نمونه مبتنی بر الگو که نیازی به محاسبات پیچیده ندارد، اصل پیادهسازی آن با سه مولد دیگر متفاوت است و مقایسههای مستقیم را دشوار میکند. هنگام مقایسه مولدهای نمونه بر اساس اصل یکسان، HIRG و Wadi سرعت قابل مقایسهای دارند. HIRG الگوریتم و زبان خود را بهینه کرده است و به سرعتی تقریباً دو برابر سریعتر از FreeDom دست یافته است اما کمی کندتر (۷٪) در مقایسه با DOMato است.
۵.۲.۲. کیفیت نمونه
نمونههایی که میتوانند توسط موتور مرورگر تجزیه شوند، نمونههای معتبر در نظر گرفته میشوند. در فازینگ، انتظار میرود که نرخ بالایی از تولید نمونه معتبر برای افزایش بازده تست برنامه هدف به دست آید. برای ارزیابی اثربخشی تولید نمونه، ما یک آزمایش مقایسهای با استفاده از چهار فازر مختلف انجام دادیم. این آزمایش شامل دستهبندی نمونهها بر اساس کمیت بود: ۱۰، ۱۰۰، ۲۰۰، ۴۰۰، ۵۰۰ و ۱۰۰۰. هر گروه از نمونهها در حالی که وضعیت زمان اجرای موتور مرورگر را نظارت میکردیم، به مرورگر هدف وارد میشد. اعتبار نمونهها با تجزیه و تحلیل اطلاعات خروجی برای نشانگرهای خاص تعیین میشد. در ماژول نظارت در چارچوب DFL، یک فیلد ویژگی به نام “Console” معرفی کردیم. اگر این فیلد ویژگی در پیام گزارش خروجی یافت شود، نمونه ورودی فعلی نامعتبر در نظر گرفته میشود. برعکس، اگر فیلد ویژگی وجود نداشته باشد، نمونه معتبر تلقی میشود. ما آزمایش را ۱۰ بار تکرار میکنیم تا میانگین نتایج را بگیریم و نتایج در شکل ۷ نشان داده شده است.
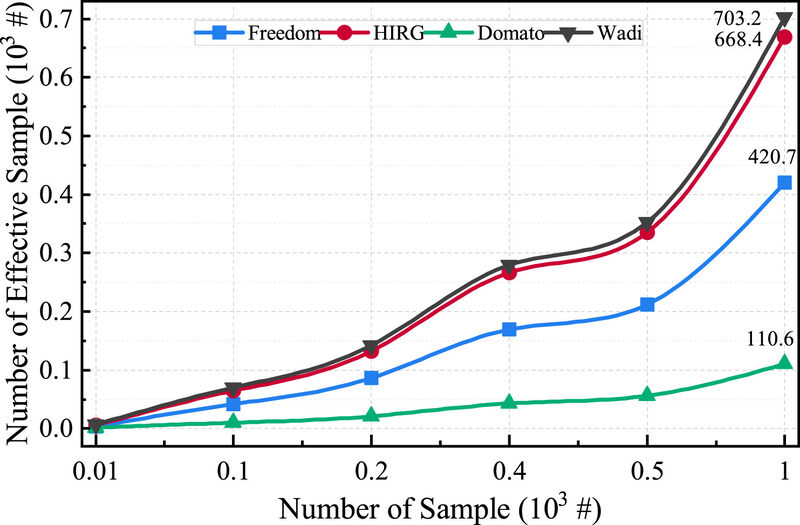
با مقایسه این مولدها، میتوان دید که Wadi و HIRG مزیت قابل توجهی در تولید نمونههای معتبر دارند. تعداد نمونههای معتبر تولید شده توسط HIRG ۱.۶۷ برابر FreeDom بود و عملکرد آن تقریباً با Wadi برابر است (کمتر از ۵٪ تفاوت). اعتبار کمتر نمونههای تولید شده توسط DOMato را میتوان به استفاده آن از یک استراتژی تغییر شکل نسبت داد که روابط متنی در HTML را نادیده میگیرد. Wadi نمونهها را بر اساس یک تکنیک تولیدی پس از مقداردهی اولیه مولد با استفاده از قالبهای نحوی تولید میکند که به آن مزیت جزئی نسبت به HIRG از نظر سرعت و کیفیت تولید میدهد. با این حال،HIRG مزیت زیادی نسبت به Wadi از نظر تعداد خرابیهای منحصر به فرد یافت شده در موتور رندر دارد که ۲۰۰٪ بیشتر از مولد Wadi است (در شکل ۱۰).
۵.۳. ارزیابی پوشش
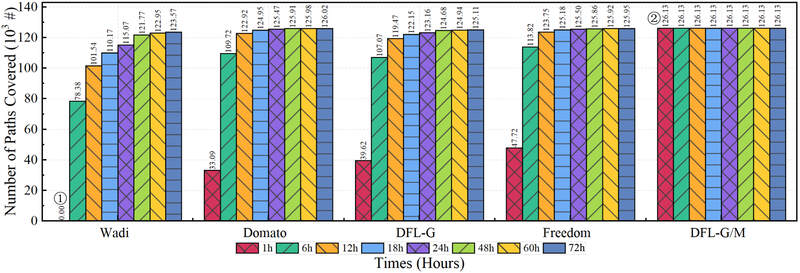
برای ارزیابی عملکرد جمعآوری پوشش چارچوبهای مختلف، تعداد مسیرهای کشف شده توسط هر چارچوب را در مدت زمان کاری مشخص مقایسه کردیم. DFL-G/M نشان دهنده عملکرد کامل تست DFL است، در حالی که DFL-G نشان دهنده حالت بدون هدایت پوشش است. هر چارچوب به ترتیب به مدت ۱، ۶، ۱۲، ۲۴، ۳۶، ۴۸، ۶۰ و ۷۲ ساعت تحت کار قرار گرفت، در حالی که تعداد مسیرهای پوشش در طول زمان اجرای موتور جمعآوری میشد. دادههای مقایسه پوشش در شکل ۸ نشان داده شده است.
در دادههای آزمایشی، مشاهده شد که DFL-G/M تعداد زیادی مسیر (۵۲۴۲۸۶) را فقط در یک ساعت در هسته بررسی کرد و روند نسبتاً پایداری را در فواصل زمانی بعدی حفظ کرد. FreeDom،DFL-G و DOMato برای دستیابی به همان پوشش DFL-G/M به ۱۲ ساعت زمان نیاز داشتند، در حالی که Wadi به ۴۸ ساعت زمان نیاز داشت. از نظر معیارهای پوشش،DFL-G/M بهترین عملکرد را داشت، Wadi عملکرد متوسطی را نشان داد و سه چارچوب دیگر عملکرد مشابهی داشتند. آزمایشها شواهد محکمی ارائه میدهند که تکنیک هدایتشده با پوشش و استراتژی جهش نمونه مورد استفاده در DFL ما میتواند به سرعت مسیرهای بیشتری را بررسی کند و بنابراین پوشش نمونه را بهبود بخشد.
۵.۴. کشف خرابی
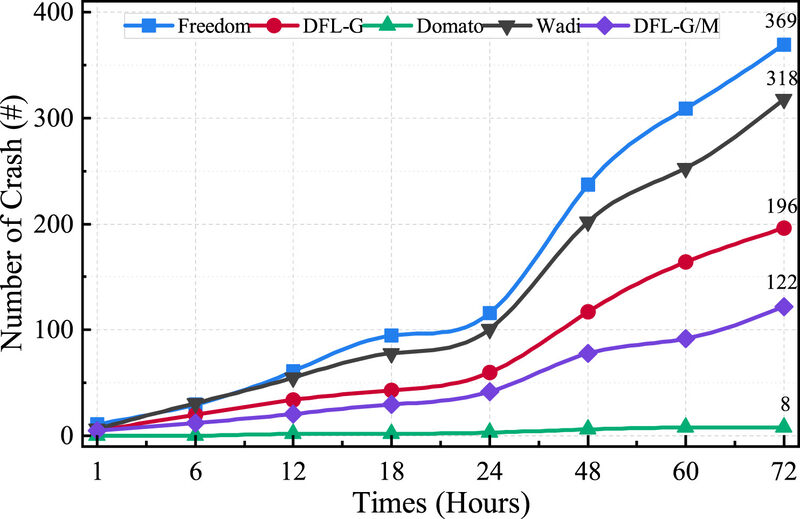
با طراحی تعداد زیادی زیرمولد برای تولید نمونههای هدایت شده توسط اطلاعات پوشش مسیر اجرا، هدف افزایش قابلیت چارچوب DFL برای کشف آسیبپذیریهای موتور رندر تحت تست است. ما به مقایسه اثربخشی تشخیص خرابی بین پنج چارچوب (۵.۳) ادامه میدهیم. هر چارچوب به طور مداوم به مدت ۷۲ ساعت کار میکند و ما دادهها را در هشت نقطه زمانی نمونهبرداری میکنیم: ۱، ۶، ۱۲، ۲۴، ۳۶، ۴۸، ۶۰ و ۷۲ ساعت. در طول زمان اجرا، تعداد خرابیهای هسته مرورگر کشف شده را جمعآوری میکنیم. تعداد خرابیهای شناسایی شده در شکل ۹ نشان داده شده است. نشان میدهد که FreeDom بیشترین تعداد خرابی را ایجاد میکند و پس از آن Wadi و DFL-G قرار دارند، در حالی که DOMato عملکرد نسبتاً ضعیفی از خود نشان میدهد. این آزمایش نشان میدهد که نمونههای تولید شده توسط HIRG میتوانند باعث ایجاد خرابی در هسته مرورگر تست شده شوند و چارچوب DFL با موفقیت حالتهای خرابی اهداف تست را ثبت میکند.
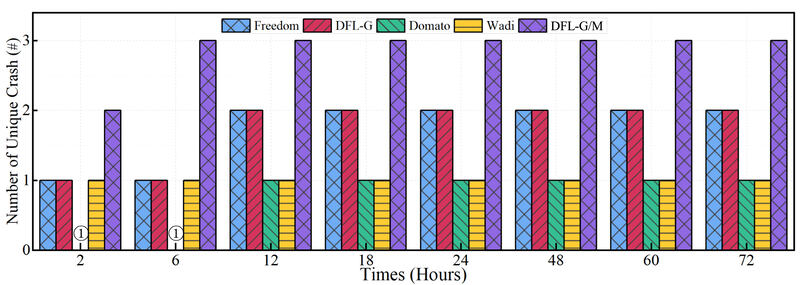
در حالی که چارچوبهای فازینگ میتوانند خرابیها را ثبت کنند، اطلاعات خرابی به تنهایی لزوماً نشان دهنده وجود آسیبپذیری در اهداف تست نیست. اگر خرابیهای ایجاد شده در موتور رندر تابع یا پشته فراخوانی یکسانی داشته باشند، به عنوان یک خرابی یکسان در نظر گرفته میشوند. بنابراین، ما با مقایسه توابع و اطلاعات پشته فراخوانی گزارشهای خرابی، تعداد خرابیهای منحصر به فرد را که ممکن است به عنوان آسیبپذیری در نظر گرفته شوند، بیشتر شمارش میکنیم. نتایج تعداد خرابیهای منحصر به فرد به همراه زمان صرف شده در شکل ۱۰ نشان داده شده است. دیده میشود که Wadi و DOMato نرخ کشف خرابی نسبتاً کمتری (هر کدام یک خرابی) دارند، اما Wadi در مقایسه با DOMato بازده کمی بالاتری در کشف خرابی داشت. FreeDom و DFL-G تعداد برابری از کشف خرابی داشتند. DFL-G/M سریعترین نرخ کشف خرابی را نشان داد و دو خرابی در عرض دو ساعت و سه خرابی در عرض چهار ساعت کشف شد. روش جمعآوری پوشش و ویژگیهای اضافه شده مورد استفاده در چارچوب DFL هم در بازده و هم در تعداد تشخیص خرابی معتبر برتری دارند و قابلیتهای تست برتر DFL-G/M را بیشتر برجسته میکنند. ترکیب تولید نمونه هدایتشده با پوشش، جهش و روشهای تغییر حالت تایمر تا حدی به مشکل چارچوبهای فازینگ که قادر به تنظیم خودکار مسیرهای تشخیص نیستند، پرداخته و در نتیجه قابلیت بررسی را افزایش میدهد.
DFL بر اساس فلسفه طراحی FreeDom ساخته شده است و DFL-G/M میتواند علاوه بر تمام خرابیهای منحصر به فردی که FreeDom میتواند پیدا کند، یک باگ دیگر نیز پیدا کند. مقایسه بین DFL-G/M و آن ثابت میکند که ویژگیهای اضافه شده میتوانند کمیت و کیفیت کشف خرابی را بهبود بخشند. علاوه بر این، ما اطلاعات خرابی تازه کشف شده را برای تأیید به تیم رسمی Google Chrome ارسال کردیم [۶۱]. این امر اثربخشی و مزایای DFL را در کشف آسیب پذیری مرورگر بیشتر تأیید میکند.
۶. بحث
در این بخش، محدودیتهای پیادهسازی DFL و کارهای آیندهای که باید انجام شود را مورد بحث قرار میدهیم.
۶.۱. محدودیتهای پیادهسازی
از نظر پیادهسازی، ما محدودیتهای بالقوه چارچوب را از سه دیدگاه بررسی میکنیم: طراحی، اعتبارسنجی و استفاده.
محدودیتهای طراحی: زیرمولدهای متعددی که در چارچوب DFL طراحی شدهاند، عمدتاً به سمت تولید نمونه برای بیشتر فراخوانیهای API در HTML هستند و پیادهسازی نحو و API خود مفسر JS را برای تولید نمونه هدف قرار نمیدهند. چارچوب، مرورگر را به عنوان یک برنامه بزرگ برای تست در نظر میگیرد و در مقایسه با تست ماژولهای جداگانه، کل فضای تست بسیار وسیع است و بررسی مؤثر مسیرهای برنامه را چالشبرانگیز میکند. مولدهای نمونه طراحی شده در چارچوب ما هنوز به خوبی با AFL جفت نشدهاند و برخی از ویژگیهای عالی AFL هنوز به طور کامل مورد استفاده قرار نگرفتهاند.
محدودیتهای آزمایش: نتایج چندین آزمایش (در بخش ۵) مزایای DFL را نشان میدهد. با این حال،DFL بر اساس هسته Blink تحت معماری X86 ساخته شده است و به نتایج خوبی در تست ماژول DOM این هسته دست یافته است. با این حال، به طور کامل روی سایر هستههای مرورگر و محیطهای معماری دیگر (مانند ARM) ساخته و آزمایش نشده است.
این محدودیت تصدیق شده و در برنامههای ما برای بهبود آینده گنجانده شده است. علاوه بر این، ابزار دقیق و کامپایل برنامههای مرورگر منجر به افزایش اندازه فایل و کندتر شدن زمان راهاندازی میشود که میتواند منابع قابل توجهی را مصرف کند و بازده تست را کاهش دهد.
محدودیتهای استفاده: چارچوب طراحی شده در مقاله با استفاده از ++C در محیط Ubuntu (جدول ۴) توسعه داده شده است. توجه محدودی به وابستگی به سیستم عامل و نسخههای کامپایلر دارد. در صورت نیاز به تغییر به سایر محیطهای سیستم عامل مانند ویندوز، اندروید یا iOS، لطفاً محدودیتهای احتمالی از نظر وابستگیهای کامپایل و زمان اجرا را در نظر بگیرید. علاوه بر این، در طراحی مولدهای نمونه، ما محدودیتهای نحوی مختلفی را برای اطمینان از مطابقت نمونههای تولید شده با دستور زبان HTML تا حد امکان، در نظر گرفتهایم. با این حال، هنگام انجام تحقیق با استفاده از DFL، لازم است تعادلی بین آستانه اثربخشی و بیاثری نمونه برقرار شود. با گنجاندن نمونههایی با قالبهای نحوی غیرمنتظره تا حدی و ترکیب تکنیکهای هدایتشده با پوشش، میتوان پوشش را افزایش داد و شاخههای کد بیشتری را بررسی کرد.
۶.۲. کارهای آینده
ما مولدهای نمونه متعددی را بر اساس این مکانیزم محدود به نحو طراحی کردهایم و اثربخشی آنها در فازینگ از طریق آزمایشها نشان داده شده است. با این حال، هنوز نیاز به تحقیقات بیشتر برای بررسی و پیشرفت این زمینه وجود دارد. چارچوب فازینگ با کیفیت بالا همچنان هدف بعدی ما است.
در حال حاضر، فازینگ موتور رندر ما فقط بر روی اشیاء DOM تمرکز دارد، در حالی که خود مرورگر یک نرمافزار سیستمی پیچیده است. اجزای دیگری در موتور رندر وجود دارند، مانند pdfium، omnibox و mojo rpc که مستعد وقوع باگهای مکرر نیز هستند. بنابراین، هدف ما تجزیه و تحلیل ویژگیهای این ماژولها و طراحی تنوع بیشتری از مولدهای نمونه هدفمند است. این امر پوشش تست را بیشتر افزایش میدهد و توانایی کشف آسیبپذیریهای سطح عمیق را بهبود میبخشد. فازینگ هدایتشده یک شاخه مهم در زمینه فازینگ است. نتایج نشان داده شده در شکلهای ۹ و ۱۰ نشان میدهد که بسیاری از گزارشهای خرابی به یک باگ اشاره دارند که نشان میدهد چارچوب مقدار قابل توجهی تست تکراری را در مسیرهای پوشش داده شده توسط همان ماژول عملکردی انجام داده است. یک استراتژی مدیریت مسیر با طراحی خوب در طول فرآیند تست برای موتور تست مفید است تا از بررسی مسیرهای تکراری جلوگیری کند. هدف تحقیقات بیشتر ما توسعه استراتژیهای مسیر جدید بر اساس اهداف تست و دستیابی به فازینگ هدایتشده توسط مسیر است. علاوه بر این، فرآیند از کشف آسیبپذیری تا رفع آن اغلب زمان قابل توجهی طول میکشد. در این مدت، کاربران با خطرات بیسابقهای روبرو هستند. بنابراین، یک موضوع جالب و ارزشمند برای بررسی بیشتر این است که آیا میتوانیم چارچوبهای محافظتی را بر اساس استراتژیهای مسیر برای مقابله موقت (اجتناب از مسیر) با آسیبپذیریهای تازه کشف شده طراحی کنیم یا خیر.
۷. کارهای مرتبط
ممیزی کد و تست نرمافزار دو رویکرد برای کشف آسیبپذیریها در هستههای مرورگر هستند. ممیزی دستی کد یک فرآیند زمانبر و پرزحمت است که اغلب توسط ابزارهایی مانند CodeQL برای کمک به پرسش کد برای کاهش حجم کار ممیزان انجام میشود. تست نرمافزار از تست تصادفی جعبه سیاه به تست جعبه خاکستری بر اساس بازخورد از پوشش مسیر تکامل یافته است. این رویکرد پوشش مسیرهای برنامه توسط نمونهها را افزایش میدهد، تصادفی بودن نمونههای تست را تا حدی کاهش میدهد و نرخ موفقیت تست را بهبود میبخشد.
۷.۱. ممیزی کد
تفاوتهای مشخصی در رویکرد ممیزی کد برای سیستمهای متن باز و سیستمهای متن بسته وجود دارد. برای سیستمهای متن باز، محققان امنیتی میتوانند کد منبع هسته مرورگر متن باز (به عنوان مثال، Chromium، Webkit) را دانلود کنند و از ابزارهای IDE (به عنوان مثال، VS Code) برای خواندن و بررسی کد استفاده کنند. این روش عمدتاً به تجربه ممیزان برای درک منطق کد و کشف دستی آسیبپذیریها از کد منبع متکی است. در مورد هستههای مرورگر متن بسته (به عنوان مثال، Internet Explorer)، محققان امنیتی از ابزارهای جداسازی برای جداسازی فایلهای باینری استفاده میکنند و سپس بر اساس تجربه خود، تماسها با توابع حساس را جستجو میکنند. آنها شبه کد را تجزیه و تحلیل میکنند و با استفاده از یک دیباگر، دیباگ پویا را برای تأیید وجود آسیبپذیریها انجام میدهند. این روش کشف آسیبپذیری مزیت جلوگیری از مثبت کاذب را دارد، اما به مقدار قابل توجهی تلاش دستی نیاز دارد که منجر به یافتههای محدود و بازده پایین میشود. با توسعه تکنیکهای ممیزی کد، ابزارهای ممیزی خودکار ظهور کردهاند که میتوانند زمان قابل توجهی را برای محققان امنیتی صرفهجویی کنند.
CodeQL [۶۲] یک ابزار عالی ممیزی کد خودکار است که توسط GitHub منتشر شده است. کدبیس هدف را اسکن میکند، آسیب پذیریها را شناسایی میکند و پیشنهادات بهبود را ارائه میدهد. کد را به عنوان یک پایگاه داده در نظر میگیرد و ساختارهای کد خاص را با استفاده از یک زبان پرسش مشابه زبان پرسش ساختاریافته (SQL) بازیابی میکند. محققان میتوانند از تجربه کشف آسیب پذیری خود برای ساخت ساختارهای کد خاص به عنوان ورودی برای CodeQL استفاده کنند و بازده و راحتی ممیزی را تا حد زیادی افزایش دهند. محققان تیم امنیتی Chromium شرکت ۳۶۰ روشی را در Black Hat 2021 [۶۴] برای ساخت نمونهها ارائه کردند. آنها با استفاده از ویژگیهای آسیبپذیریهای موجود، نمونههای ورودی با کیفیت بالا را برای کشف انواع خاصتری از آسیبپذیریها میسازند. در سالهای اخیر، محققان ابزارهای ممیزی کد عالی مختلفی مانند Sys [۷] و VCCFinder [۸] را پیشنهاد کردهاند. این روشها این مزیت را دارند که میتوانند انواع خاصتری از آسیب پذیریها را با مثبت کاذب کم شناسایی کنند. با این حال، آنها به سطح بالایی از تخصص از محققان برای ساخت عبارات پرسش CodeQL کارآمد نیاز دارند.
۷.۲. فازینگ مرورگر
در حال حاضر، روشهای فازینگ برای مرورگرها عمدتاً بر روی موتور JS [۹-۱۵] تمرکز دارند و رویکردهای کمتری موتور رندر را هدف قرار میدهند. برای فازینگ موتورهای رندر، دو رویکرد را مورد بحث قرار میدهیم: فازینگ مبتنی بر مولد نمونه و جهش نمونه هدایتشده با پوشش.
مبتنی بر مولد نمونه: این رویکرد به انواع مولدهای هدفمند برای تولید نمونههای تست با کیفیت بالا، مانند DOMato [۲۹]، Dharma [۶۵] و Wadi [۴۴] متکی است. DOMato که توسط گوگل توسعه یافته است، یک مولد نمونه DOM است که از یک زبان توصیف میانی برای تولید چندین نمونه HTML بر اساس قالبها استفاده میکند. این ابزار بیش از ۳۰ آسیب پذیری مرورگر را کشف کرده است. با این حال، نقطه ضعف آن این است که فقط تولید نمونه را ارائه میدهد. نمونههای تولید شده باید با استفاده از ابزارهای دیگر به برنامه هدف وارد شوند. برای الزاماتی که شامل فعال کردن مسیرهای کد عمیقتر هستند، تخصص محققان ضروری است.
روشهای جهش نمونه با بازخورد پوشش: این روشها بر اساس بازخورد پوشش، جهش نمونه را برای کشف مسیرهای کد جدید و بهبود بازده تست هدایت میکنند، مانند FreeDom [۲۸] و RIFF [۶۶] .FreeDom یک روش تولید و جهش نمونه را بر اساس درختهای نحوی DOM اتخاذ میکند و یک طرح فازینگ هدایتشده با پوشش را پیشنهاد میکند. جهش نمونه با انجام تصادفی عملیاتی مانند حذف، درج، جهش ویژگی یا ادغام گره در درخت نحوی به دست میآید. با این حال، در کد منبع باز، فقط بخش تولید نمونه پیادهسازی شده است و تجزیه نمونههای HTML به نمایش داخلی درخت نحوی DOM پیادهسازی نشده است. عملکردهای اجرا و نظارت نیز ارائه نمیشوند و ادغام با سایر چارچوبهای فازینگ برای انجام فازینگ ضروری است.
علاوه بر این، رویکردهای معنایی و مبتنی بر API برای فازینگ مرورگر نیز وجود دارد. مانند Favocado [۱۰] و SaGe [۳۸] راهحلهای فازینگ مرورگر آگاه از معنا هستند که بر بهبود صحت ورودیهای تولید شده خود تمرکز دارند. Favocado اطلاعات معنایی را از کد منبع مرورگر استخراج میکند و آن را در ساختار JSON ذخیره میکند. SaGe معناشناسی را از استانداردهای W3C استخراج میکند و آن را در CFG ذخیره میکند. در مقایسه، JSON نرخ استفاده کمتری دارد. رویکرد CFG تولید ورودیهای ساختاریافته را تسهیل میکند و تا حدی مشکل پوشش کم مرورگر به دلیل ورودیهای تولید شده توسط CFG دستنویس را حل میکند. Minerva [۲۶] پوشش را با رویکردی بهبود میبخشد که نمودارهای تداخل API را تجزیه و تحلیل میکند و از روابط تداخل API برای کاهش فضای جستجو استفاده میکند و در فازینگ API مرورگر، عمدتاً برای سناریوهای کشف خطای حافظه مرورگر موفق بوده است. در مقایسه، این رویکردهای فازینگ بیشتر بر روی موتورهای JS متمرکز هستند، در حالی که DFL در طراحی مولد نمونه و چارچوب تخصص دارد و بر فازینگ برای موتورهای رندر تمرکز دارد.
۸. نتیجهگیری
در این مقاله، ما یک چارچوب فازینگ موتور رندر به نام DFL را با استفاده از زبان برنامهنویسی کارآمد ++C توسعه دادهایم. این چارچوب از تکنیکهای هدایتشده با پوشش برای هدایت تولید و جهش نمونه استفاده میکند که عملکرد تست را به طور قابل توجهی بهبود میبخشد. DFL با یک رویکرد مدولار طراحی شده است و مولد را بر اساس FreeDom دوباره طراحی میکند و برخی از بهترین ویژگیهای AFL را برای خودکارسازی فازینگ مرورگر معرفی میکند. علاوه بر این، DFL مولد HIRG و روش سریالسازی/غیرسریالسازی نمونه را برای غلبه بر مشکل ناتوانی AFL در تولید نمونههایی که با قوانین نحوی HTML مطابقت دارند، معرفی میکند. نتایج آزمایشی نشان میدهد که DFL از سایر چارچوبهای فازینگ موتور رندر موجود از نظر سرعت تولید نمونه، بازده جمعآوری پوشش و قابلیتهای کشف خرابی عملکرد بهتری دارد. علاوه بر این، در مقایسه با چارچوبهای محبوب فازینگ موتور رندر،DFL یک باگ اضافی را در یک بازه زمانی مشخص کشف کرد. این باگ توسط تیم رسمی Google Chrome [۶۱] تأیید شد و تأیید کرد که باگ ایجاد شده از نمونه ارسالی ما یک آسیبپذیری واقعی است. با این وجود، ما انتظار داریم که محققان بیشتری مطالعات بیشتری را بر اساس DFL انجام دهند. هدف ما رفع محدودیتهای آن و افزایش پوشش تست و توانایی کشف آسیب پذیریهای سطح عمیق است. به طور خاص، از نظر ابداع استراتژیهای مدیریت مسیر پوشش، قصد داریم بر طراحی روشهای تحقیق برای فازینگ هدایتشده تمرکز کنیم و تلاشهای تحقیقاتی را در رفع وصلههای ساختگی با هدف آسیب پذیریهای شناخته شده تشدید کنیم.
منابع
[1] A. Barth, C. Jackson, C. Reis, T. Team, et al., The Security Architecture of the Chromium Browser, Stanford University, 2008.
[2] Google, Chromium issues, 2023, https://bugs.chromium.org/p/chromium/issues/list?q=&can=1, Website.
[3] P. Snyder, C. Taylor, C. Kanich, Most websites don’t need to vibrate: A cost-benefit approach to improving browser security, in: Proceedings of the 2017, ACM SIGSAC Conference on Computer and Communications Security, CCS ’17,Association for Computing Machinery, New York, NY, USA, 2017, pp. 179–194.
[4] S. Oesch, S. Ruoti, That was then, this is now: A security evaluation of password generation, storage, and autofill in Browser-Based password managers, in: 29th USENIX Security Symposium (USENIX Security 20), USENIX Association, 2020,pp. 2165–2182.
[5] I. 1132218, Tesla.com: Color options not rendered until window resize when compositesvg is enabled, 2024, https://bugs.chromium.org/p/chromium/issues/detail?id=1132218, Website.
[6] C. Qian, H. Koo, C. Oh, T. Kim, W. Lee, Slimium: Debloating the chromium browser with feature subsetting, in: Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, CCS ’20, Association for Computing Machinery, New York, NY, USA, 2020, pp. 461–476.
[7] F. Brown, D. Stefan, D. Engler, Sys: A Static/Symbolic tool for finding good bugs in good (browser) code, in: 29th USENIX Security Symposium (USENIX Security 20), USENIX Association, 2020, pp. 199–216.
[8] H. Perl, S. Dechand, M. Smith, D. Arp, F. Yamaguchi, K. Rieck, S. Fahl, Y. Acar,VCCFinder: Finding potential vulnerabilities in open-source projects to assist code audits, in: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, CCS ’15, Association for Computing Machinery, New York, NY, USA, 2015, pp. 426–437.
[9] C. Holler, K. Herzig, A. Zeller, Fuzzing with code fragments, in: 21st USENIX Security Symposium (USENIX Security 12), USENIX Association, 2012, pp.445–458.
[10] S.T. Dinh, H. Cho, K. Martin, A. Oest, K. Zeng, A. Kapravelos, G.-J. Ahn, T. Bao, R. Wang, A. Doupé, et al., Favocado: Fuzzing the binding code of JavaScript engines using semantically correct test cases, in: 28th Annual Network and Distributed System Security Symposium, NDSS, February 21-25, 2021, The Internet Society, 2021.
[11] L. Bernhard, T. Scharnowski, M. Schloegel, T. Blazytko, T. Holz, JIT-picking: Dif-ferential fuzzing of JavaScript engines, in: Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS ’22, Association for Computing Machinery, New York, NY, USA, 2022, pp. 351–364.
[12] S. Lee, H. Han, S.K. Cha, S. Son, Montage: A neural network language model-guided JavaScript engine fuzzer, in: 29th USENIX Security Symposium (USENIX Security 20), 2020, pp. 2613–2630.
[13] G. Ye, Z. Tang, S.H. Tan, S. Huang, D. Fang, X. Sun, L. Bian, H. Wang, Z.Wang, Automated conformance testing for JavaScript engines via deep compiler fuzzing, in: Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, in: PLDI 2021, Association for Computing Machinery, New York, NY, USA, 2021, pp. 435–450.
[14] H. Han, D. Oh, S.K. Cha, CodeAlchemist: Semantics-aware code generation to find vulnerabilities in JavaScript engines, in: 26th Annual Network and Distributed System Security Symposium, NDSS, The Internet Society, 2019.
[15] W. Blair, A. Mambretti, S. Arshad, M. Weissbacher, W. Robertson, E. Kirda, M.Egele, HotFuzz: Discovering algorithmic denial-of-service vulnerabilities through guided micro-fuzzing, 2020, arXiv preprint arXiv:2002.03416.
[16] J. Wang, B. Chen, L. Wei, Y. Liu, Skyfire: Data-driven seed generation for fuzzing,in: 2017 IEEE Symposium on Security and Privacy, SP, 2017, pp. 579–594.
[17] S. Groß, S. Koch, L. Bernhard, T. Holz, M. Johns, FUZZILLI: Fuzzing for JavaScript JIT compiler vulnerabilities, in: Network and Distributed SystemsSecurity (NDSS) Symposium, San Diego, CA, 2023.
[18] S. Wi, T.T. Nguyen, J. Kim, B. Stock, S. Son, DiffCSP: Finding browser bugs in content security policy enforcement through differential testing, in: 30th Annual Network and Distributed System Security Symposium, NDSS 2023, San Diego, California, USA, February 27 – March 3, 2023, The Internet Society, 2023.
[19] M. Zalewski, AFL, 2023, https://lcamtuf.coredump.cx/afl/, Website.
[20] S. Karamcheti, G. Mann, D. Rosenberg, Adaptive grey-box fuzz-testing with thompson sampling, in: Proceedings of the 11th ACM Workshop on Artificial Intelligence and Security, AISec ’18, Association for Computing Machinery, New York, NY, USA, 2018, pp. 37–47.
[21] A. Oest, Y. Safaei, A. Doupé, G.-J. Ahn, B. Wardman, K. Tyers, PhishFarm: A scalable framework for measuring the effectiveness of evasion techniques against browser phishing blacklists, in: 2019 IEEE Symposium on Security and Privacy, SP, 2019, pp. 1344–1361.
[22] U. Iqbal, S. Englehardt, Z. Shafiq, Fingerprinting the fingerprinters: Learning to detect browser fingerprinting behaviors, in: 2021 IEEE Symposium on Security and Privacy, SP, IEEE, 2021, pp. 1143–1161.
[23] S. Kim, Y.M. Kim, J. Hur, S. Song, G. Lee, B. Lee, {𝐹 𝑢𝑧𝑧𝑂𝑟𝑖𝑔𝑖𝑛}: Detecting {𝑈 𝑋𝑆𝑆} vulnerabilities in browsers through origin fuzzing, in: 31st USENIX Security Symposium (USENIX Security 22), 2022, pp. 1008–1023.
[24] G. Kwong, DOMFuzz, 2023, https://github.com/MozillaSecurity/domfuzz, Web-site.
[25] C. Shou, u.B. Kadron, Q. Su, T. Bultan, CorbFuzz: Checking browser security policies with fuzzing, in: 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), ASE ’21, IEEE Press, 2022, pp. 215–226.
[26] C. Zhou, Q. Zhang, M. Wang, L. Guo, J. Liang, Z. Liu, M. Payer, Y. Jiang, Minerva: Browser API fuzzing with dynamic mod-ref analysis, in: Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, in: ESEC/FSE 2022, Association for Computing Machinery, New York, NY, USA, 2022, pp. 1135–1147.
[27] R. Wang, G. Xu, X. Zeng, X. Li, Z. Feng, TT-XSS: A novel taint tracking based dynamic detection framework for DOM cross-site scripting, J. Parallel Distrib. Comput. 118 (2018) 100–106.
[28] W. Xu, S. Park, T. Kim, FREEDOM: Engineering a state-of-the-art DOM fuzzer,
in: Proceedings of the 2020 ACM SIGSAC Conference on Computer and Commu-
nications Security, CCS ’20, Association for Computing Machinery, New York,
NY, USA, 2020, pp. 971–986.
[29] I. Fratric, A DOM fuzzer, 2023, https://github.com/googleprojectzero/domato, Website.
[30] G. Duan, Y. Fu, B. Zhang, P. Deng, J. Sun, H. Chen, Z. Chen, TEEFuzzer: A fuzzing
framework for trusted execution environments with heuristic seed mutation,
Future Gener. Comput. Syst. 144 (2023) 192–204.
[31] P. Chen, H. Chen, Angora: Efficient fuzzing by principled search, in: 2018 IEEE Symposium on Security and Privacy, SP, 2018, pp. 711–725.
[32] S. Schumilo, C. Aschermann, R. Gawlik, S. Schinzel, T. Holz, kAFL: Hardware-assisted feedback fuzzing for OS kernels, in: 26th USENIX Security Symposium (USENIX Security 17), USENIX Association, Vancouver, BC, 2017, pp. 167–182.
[33] M. Cho, D. An, H. Jin, T. Kwon, BoKASAN: Binary-only kernel address sanitizer for effective kernel fuzzing, in: 32nd USENIX Security Symposium (USENIX Security 23), USENIX Association, Anaheim, CA, 2023, pp. 4985–5002.
[34] S. Khodayari, G. Pellegrino, It’s (DOM) clobbering time: Attack techniques, prevalence, and defenses, in: 2023 IEEE Symposium on Security and Privacy, SP, 2023, pp. 1041–1058.
[35] M. Heiderich, M. Niemietz, F. Schuster, T. Holz, J. Schwenk, Scriptless attacks:
Stealing the pie without touching the sill, in: Proceedings of the 2012 ACM Conference on Computer and Communications Security, CCS ’12, Association for Computing Machinery, New York, NY, USA, 2012, pp. 760–771.
[36] S. Ninawe, R. Wajgi, Detection of DOM-based XSS attack on web application, in: S. Balaji, A. Rocha, Y.-N. Chung (Eds.), Intelligent Communication Technologies
and Virtual Mobile Networks, Springer International Publishing, Cham, 2020, pp.
633–641.
[37] D.T. Noß, L. Knittel, C. Mainka, M. Niemietz, J. Schwenk, Finding all cross-site needles in the DOM stack: A comprehensive methodology for the automatic XS-leak detection in web browsers, in: Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS ’23, Association for Computing Machinery, New York, NY, USA, 2023, pp. 2456–2470.
[38] C. Zhou, Q. Zhang, L. Guo, M. Wang, Y. Jiang, Q. Liao, Z. Wu, S. Li, B. Gu, Towards better semantics exploration for browser fuzzing, Proc. ACM Program. Lang. 7 (OOPSLA2) (2023). Information and Software Technology 177 (2025) 107591 11 G. Duan et al.
[39] H.L. Nguyen, L. Grunske, BEDIVFUZZ: Integrating behavioral diversity into generator-based fuzzing, in: 2022 IEEE/ACM 44th International Conference on Software Engineering, ICSE, 2022, pp. 249–261.
[40] J. Liu, J. Lin, F. Ruffy, C. Tan, J. Li, A. Panda, L. Zhang, NNSmith: Generating diverse and valid test cases for deep learning compilers, in: Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, in: ASPLOS 2023, Association for Computing Machinery, New York, NY, USA, 2023, pp. 530–543.
[41] R. Valotta, Taking browsers fuzzing to the next (DOM) level, 2023, https://deepsec.net/docs/Slides/2012/DeepSec_2012_Rosario_Valotta_\protect\
discretionary{\char\hyphenchar\font}{}{}_Taking_Browsers_Fuzzing_to_the_next_
(DOM)_Level.pdf, Website.
[42] Y. Wang, C. Zhang, Z. Zhao, B. Zhang, X. Gong, W. Zou, MAZE: Towards automated heap feng shui, in: 30th USENIX Security Symposium (USENIX Security 21), USENIX Association, 2021, pp. 1647–1664.
[43] Y. Yu, X. Jia, Y. Liu, Y. Wang, Q. Sang, C. Zhang, P. Su, HTFuzz: Heap operation sequence sensitive fuzzing, in: Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, ASE ’22, Association for Computing Machinery, New York, NY, USA, 2023.
[44] Wadi, 2023, https://github.com/sensepost/wadi, Website.
[45] H. Chen, Y. Mao, X. Wang, D. Zhou, N. Zeldovich, M.F. Kaashoek, Linux kernel vulnerabilities: State-of-the-art defenses and open problems, in: Proceedings of the Second Asia-Pacific Workshop on Systems, APSys ’11, Association for Computing Machinery, New York, NY, USA, 2011.
[46] F. Nabi, J. Yong, X. Tao, A taxonomy of logic attack vulnerabilities in component-based e-commerce system, Int. J. Inf. Secur. Res. 9 (2019) 898–905.
[47] X. Cheng, H. Wang, J. Hua, G. Xu, Y. Sui, DeepWukong: Statically detecting software vulnerabilities using deep graph neural network, ACM Trans. Softw. Eng. Methodol. 30 (3) (2021).
[48] P.H.N. Rajput, C. Doumanidis, M. Maniatakos, ICSPatch: Automated vulnerability localization and non-intrusive hotpatching in industrial control systems using data dependence graphs, in: Proc. 32nd USENIX Secur. Symp, USENIX Association, 2023.
[49] Syzkaller, 2023, https://github.com/google/syzkaller, Website.
[50] V.J. Manès, H. Han, C. Han, S.K. Cha, M. Egele, E.J. Schwartz, M. Woo, The art, science, and engineering of fuzzing: A survey, IEEE Trans. Softw. Eng. 47 (11) (2021) 2312–2331.
[51] P. Godefroid, M.Y. Levin, D. Molnar, SAGE: Whitebox fuzzing for security testing, Commun. ACM 55 (3) (2012) 40–44.
[52] C. Beaman, M. Redbourne, J.D. Mummery, S. Hakak, Fuzzing vulnerability discovery techniques: Survey, challenges and future directions, Comput. Secur.
120 (2022) 102813.
[53] P. Godefroid, H. Peleg, R. Singh, Learn&Fuzz: Machine learning for input fuzzing, in: 2017 32nd IEEE/ACM International Conference on Automated Software Engineering, ASE, 2017, pp. 50–59.
[54] H. Xu, Y. Wang, Z. Jiang, S. Fan, S. Fu, P. Xie, Fuzzing JavaScript engines with a syntax-aware neural program model, Comput. Secur. 144 (2024) 103947.
[55] Z. Lin, Y. Chen, Y. Wu, D. Mu, C. Yu, X. Xing, K. Li, GREBE: Unveiling exploitation potential for linux kernel bugs, in: 2022 IEEE Symposium on Security and Privacy, SP, 2022, pp. 2078–2095.
[56] J. Li, B. Zhao, C. Zhang, Fuzzing: a survey, Cybersecurity 1 (2018) 1–13.
[57] W. Xu, S. Park, T. Kim, FreeDom source code, 2024, https://github.com/sslab-gatech/freedom, Website.
[58] D. Lion, A. Chiu, M. Stumm, D. Yuan, Investigating managed language runtime performance: Why JavaScript and Python are 8x and 29x slower than C++, yet Java and go can be faster? in: 2022 USENIX Annual Technical Conference (USENIX ATC 22), USENIX Association, Carlsbad, CA, 2022, pp. 835–852.
[59] P. Diehl, M. Morris, S.R. Brandt, N. Gupta, H. Kaiser, Benchmarking the parallel 1D heat equation solver in Chapel, Charm++, C++, HPX, Go, Julia, Python, Rust, Swift, and Java, in: Euro-Par 2023: Parallel Processing Workshops, Springer Nature Switzerland, Cham, 2024, pp. 127–138.
[60] Google, AddressSanitizer, 2023, https://github.com/google/sanitizers/wiki/AddressSanitizer, Website.
[61] Haivk007, Security: Heap buffer overflow in mojo message, 2023, https://bugs.chromium.org/p/chromium/issues/detail?id=1321040, Website.
[62] GitHub, CodeQL, 2023, https://codeql.github.com/, Website.
[63] J. Wang, B. Chen, L. Wei, Y. Liu, Superion: Grammar-aware greybox fuzzing, in:2019 IEEE/ACM 41st International Conference on Software Engineering, ICSE,2019, pp. 724–735.
[64] G.G. Rong Jian, Put in one bug and pop out more: An effective way of bug hunting in chrome, 2023, https://www.classcentral.com/course/youtube-put-in-one-bug-and-pop-out-more-an-effective-way-of-bug-hunting-in-chrome-184998, Website.
[65] J. Schwartzentruber, Dharma, 2023, https://github.com/posidron/dharma, Website.
[66] M. Wang, J. Liang, C. Zhou, Y. Jiang, R. Wang, C. Sun, J. Sun, RIFF: Reduced instruction footprint for Coverage-Guided fuzzing, in: 2021