
جون لی، بودونگ ژائو و چائو ژنگ*
چکیده
آسیب پذیریهای امنیتی یکی از علل اصلی تهدیدات سایبری میباشند. پژوهشگران برای کشف و رفع این آسیب پذیریها، روشهای مختلفی را پیشنهاد دادهاند که در این میان، فازینگ به عنوان یکی از پرکاربردترین تکنیکها شناخته میشود. در سالهای اخیر، راه حلهای فازینگ، مانند AFL، پیشرفتهای چشمگیری در کشف آسیب پذیریها داشتهاند. این مقاله به خلاصهای از پیشرفتهای اخیر میپردازد، تحلیل میکند که چگونه این پیشرفتها فرآیند فازینگ را بهبود میبخشند و به آینده کار در زمینه فازینگ توجه میکند.
ابتدا دلایل محبوبیت فازینگ را با مقایسه تکنیکهای مختلف کشف آسیب پذیری تحلیل میکنیم. سپس راه حلهای فازینگ را ارائه میدهیم و به تفصیل یکی از رایجترین انواع فازینگ یعنی فازینگ مبتنی بر پوشش (coverage-based fuzzing) را مورد بررسی قرار میدهیم. در ادامه تکنیکهای دیگری که میتوانند فرآیند فازینگ را هوشمندتر و کارآمدتر سازند، معرفی میکنیم. سرانجام، برخی از کاربردهای فازینگ را نشان میدهیم و روندهای جدید فازینگ و جهتگیریهای بالقوه آینده را مورد بحث قرار میدهیم.
کلیدواژهها:
کشف آسیب پذیری، امنیت نرم افزار، فازینگ، فازینگ مبتنی بر پوشش
مقدمه
آسیب پذیریها به یک علت اصلی تهدیدات علیه امنیت فضای سایبر تبدیل شدهاند. طبق تعریف در (RFC 2828 شایری 2000)، آسیب پذیری یک نقص یا ضعف در طراحی، پیادهسازی یا عملیات و مدیریت یک سیستم است که میتواند مورد سو استفاده قرار گیرد تا سیاستهای امنیتی سیستم را نقض کند.
حمله به آسیب پذیریها، به ویژه آسیب پذیریهای روز صفر (zero-day vulnerabilities) ، میتواند منجر به خسارات جدی شود. حمله باجافزار WannaCry ویکیپدیا و حمله باجافزاری WannaCry 2017 که در ماه مه 2017 رخ داد و از یک آسیب پذیری در پروتکل Server Message Block (SMB) سوءاستفاده کرد، گزارش شده است که در یک روز، بیش از 230,000 کامپیوتر در بیش از 150 کشور را آلوده کرده است. این حمله باعث بروز مشکلات جدی در مدیریت بحران و خسارات هنگفتی به صنایع مختلف مانند مالی، انرژی و درمان پزشکی شده است.
با توجه به خسارات جدی ناشی از آسیب پذیریها، تلاشهای زیادی به تکنیکهای کشف آسیب پذیری در نرمافزارها و سیستمهای اطلاعاتی اختصاص یافته است. تکنیکهایی از جمله تحلیل استاتیک، تحلیل دینامیک، اجرای نمادین و فازینگ (لیو و همکاران 2012) پیشنهاد شدهاند. فازینگ نسبت به سایر تکنیکها، نیاز به دانش کمی درباره اهداف دارد و به راحتی میتواند به برنامههای بزرگ مقیاسپذیر تبدیل شود، به همین دلیل به محبوبترین راه حل کشف آسیب پذیری، به ویژه در صنعت، تبدیل شده است.
مفهوم فازینگ برای اولین بار در دهه 1990 مطرح شد (وو و همکاران 2010). اگرچه این مفهوم در طول دههها توسعه ثابت باقی مانده است، اما نحوه اجرای فازینگ به طور قابل توجهی تکامل یافته است. از سوی دیگر، سالها تجربه نشان میدهد که فازینگ معمو لا در مراحل اولیه، نقصهای ساده در فساد حافظه را پیدا میکند و به نظر میرسد که تنها بخش بسیار کوچکی از کد هدف را پوشش میدهد. علاوه بر این، تصادفی بودن و عدم جهتگیری فازینگ منجر به کارایی پایین در شناسایی باگها میشود. به همین دلیل، راه حلهای متعددی برای بهبود اثربخشی و کارآیی فازینگ پیشنهاد شده است.
ترکیب حالت فازینگ مبتنی بر بازخورد و الگوریتمهای ژنتیک یک چهارچوب فازینگ انعطافپذیرتر و سفارشیسازی شده را ارائه میدهد و فرآیند فازینگ را هوشمندتر و کارآمدتر میسازد. با معرفی AFL ، فازینگ مبتنی بر بازخورد، به ویژه فازینگ هدایت شده توسط پوشش، پیشرفتهای چشمگیری داشته است. بسیاری از راه حلها یا بهبودهای مؤثر الهام گرفته از AFL، به تازگی پیشنهاد شدهاند. فازینگ اکنون با چند سال پیش خود بسیار متفاوت است. از این رو، جمعبندی کارهای اخیر در زمینه فازینگ و بررسی آینده پژوهشها ضروری است.
ما در این مقاله، سعی داریم وضعیت روز فازینگ را خلاصه کنیم و نشان دهیم که چگونه این تکنیکها به بهبود اثربخشی و کارآیی کشف آسیب پذیریها کمک میکنند. همچنین نشان میدهیم که چگونه تکنیکهای سنتی میتوانند به بهبود اثربخشی و کارآیی فازینگ کمک کنند و فازرها را هوشمندتر سازند. سپس، مروری بر نحوه شناسایی آسیب پذیریهای مختلف اهداف، از جمله برنامههای نرم افزاری فرمت فایل، هستهها و پروتکلها ارائه میدهیم. در نهایت، سعی داریم تا روندهای جدید توسعه تکنیک فازینگ را بیان کنیم.
بقیه مقاله به شرح زیر سازماندهی شده است: بخش “زمینه”، دانش زمینهای در مورد تکنیکهای کشف آسیب پذیری را ارائه میدهد. بخش “فازینگ “، مقدمهای دقیق بر فازینگ، شامل مفاهیم بنیادی و چالشهای کلیدی فازینگ را ارائه میدهد. در بخش “فازینگ مبتنی بر پوشش”، فازینگ مبتنی بر پوشش و کارهای مرتبط به روز را معرفی میکنیم. در بخش “تکنیکهای ادغام شده در فازینگ”، خلاصهای از این که چگونه تکنیکهای دیگر میتوانند به بهبود فازینگ کمک کنند را ارائه میدهیم و بخش “فازینگ در برابر برنامههای مختلف” چندین کاربرد فازینگ را معرفی میکند. در بخش “روندهای جدید فازینگ”، ما به بحث و جمعبندی روندهای احتمالی جدید فازینگ میپردازیم و در نهایت، مقاله خود را در بخش “نتیجهگیری” به پایان میرسانیم.
زمینه
در این بخش، مقدمهای مختصر درباره تکنیکهای سنتی کشف آسیب پذیری ارائه میدهیم، از جمله: تحلیل استاتیک، تحلیل دینامیک، تحلیل ردیابی (taint analysis)، اجرای نمادین و فازینگ. سپس مزایا و معایب هر تکنیک را خلاصه میکنیم.
تحلیل استاتیک
تحلیل استاتیک، تحلیلی از برنامهها است که بدون اجرای واقعی برنامهها انجام میشود (ویچمن و همکاران 1995). به جای اینکه روی کد منبع کار شود، تحلیل استاتیک اغلب بر روی کد منبع و گاهی اوقات بر روی کد شیء نیز انجام میشود. با تحلیل ویژگیهای واژهای، نحوی، معنایی و تحلیل جریان دادهها، بررسی مدلها، تحلیل استاتیک میتواند باگهای پنهان را شناسایی کند. مزیت تحلیل استاتیک سرعت بالای تشخیص آن است. یک تحلیلگر میتواند به سرعت کد هدف را با ابزار تحلیل استاتیک بررسی کند و عملیات را به موقع انجام دهد. با این حال، تحلیل استاتیک در عمل دارای نرخ خطای بالایی است. به دلیل کمبود مدلهای ساده برای تشخیص آسیب پذیری، ابزارهای تحلیل استاتیک مستعد تولید تعداد زیادی مثبت کاذب هستند. بنابراین شناسایی نتایج تحلیل استاتیک هنوز کار دشواری باقی میماند.
تحلیل دینامیک
در مقابل تحلیل استاتیک، در تحلیل دینامیک برنامهها، یک تحلیلگر نیاز دارد تا برنامه هدف را در سیستمهای واقعی یا شبیهسازها اجرا کند (ویکیپدیا 2017). با نظارت بر وضعیتهای در حال اجرا و تحلیل دانش زمان اجرا، ابزارهای تحلیل دینامیک میتوانند باگهای برنامه را به دقت شناسایی کنند. مزیت تحلیل دینامیک، دقت بالای آن است، در حالی که معایب زیر نیز وجود دارد. اول، اشکالزدایی، تحلیل و اجرای برنامههای هدف در تحلیل دینامیک نیاز به دخالت انسانی زیادی دارد و منجر به کارایی پایین میشود. علاوه بر این، دخالت انسانی نیاز به مهارتهای فنی قوی تحلیلگران دارد. به طور خلاصه، تحلیل دینامیک دارای معایب مربوط به کندی است.
سرعت، کارآیی پایین، نیازمندیهای بالا به سطح فنی آزمایشکنندگان، مقیاسپذیری ضعیف و دشواری در اجرای تستهای بزرگ مقیاس از معایب تحلیل دینامیک است.
اجرای نمادین
اجراهای نمادین (کینگ 1976) یک تکنیک دیگر برای کشف آسیب پذیری است که به شدت امیدوارکننده تلقی میشود. با نمادین کردن ورودیهای برنامه، اجرای نمادین مجموعهای از محدودیتها را برای هر مسیر اجرایی حفظ میکند. پس از اجرا، از حل کنندههای محدودیت برای حل این محدودیتها و تعیین اینکه کدام ورودیها باعث اجرای برنامه میشوند، استفاده میگردد. به طور فنی، اجرای نمادین میتواند هر مسیر اجرایی در یک برنامه را پوشش دهد و در تست برنامههای کوچک نتایج خوبی نشان داده است، اما محدودیتهای زیادی نیز دارد. اول، مشکل انفجار مسیر (path explosion) وجود دارد. با بزرگتر شدن مقیاس برنامه، حالات اجرایی به شدت افزایش مییابند که میتواند فراتر از توانایی حل کنندههای محدودیت باشد. اجرای نمادین انتخابی به عنوان یک راه حل موقت پیشنهاد شده است. دوم ،تعاملات محیطی. در اجرای نمادین، وقتی که اجرای برنامه هدف با اجزای خارج از محیطهای اجرای نمادین تعامل دارد، مانند تماسهای سیستمی و پردازش سیگنالها، ممکن است مشکلات همخوانی بروز کند. کارهای قبلی نشان دادهاند که اجرای نمادین هنوز هم برای مقیاسپذیری در برنامههای بزرگ دشوار است (بومه و همکاران 2017).
فازینگ
فازینگ (ساتن و همکاران 2007) در حال حاضر پرکاربردترین تکنیک کشف آسیب پذیری است. فازینگ برای اولین بار توسط بارتون میلار در دانشگاه ویسکانسین در دهه 1990 مطرح شد. به طور مفهومی، یک تست فازینگ با تولید ورودیهای عادی و غیرعادی در حجم بالا برای برنامههای هدف آغاز میشود و سعی میشود با تغذیه ورودیهای تولید شده به برنامههای هدف و نظارت بر حالتهای اجرایی، استثناها را شناسایی کند. در مقایسه با سایر تکنیکها، فازینگ به راحتی قابل پیاده سازی است و مقیاسپذیری و قابلیت کاربرد خوبی دارد و میتواند با یا بدون کد منبع انجام شود. علاوه بر این، از آنجایی که تست فازینگ در حین اجرای واقعی انجام میشود، دقت بالایی دارد. همچنین، فازینگ نیاز به دانش کمی از برنامههای هدف دارد و به راحتی میتواند به برنامههای بزرگ مقیاسپذیر تبدیل شود.
با اینکه فازینگ با معایب زیادی مانند کارآیی پایین و پوشش کد پایین روبرو است، اما به دلیل مزایای بیشمارش، فازینگ به مؤثرترین و کارآمدترین تکنیک کشف آسیب پذیری به روز تبدیل شده است. جدول 1 مزایا و معایب تکنیکهای مختلف را نشان میدهد.
Scalability | Accuracy | Easy to start? | Technique |
Relatively good | low | easy | Static analysis |
uncertain | high | hard | Dynamic analysis |
bad | high | hard | Symbolic execution |
good | high | easy | Fuzzing |
در این بخش، سعی داریم دیدگاهی درباره فازینگ ارائه دهیم، شامل دانش زمینهای در مورد تکنیکهای بنیادی و چالشهای موجود در بهبود فازینگ. آنها باید بتوانند شرایط خاصی از جمله استثناها و خطاهای غیرمنتظره را ایجاد کند. این مرحله به عنوان مرحله تولید کیسهای تست شناخته میشود.
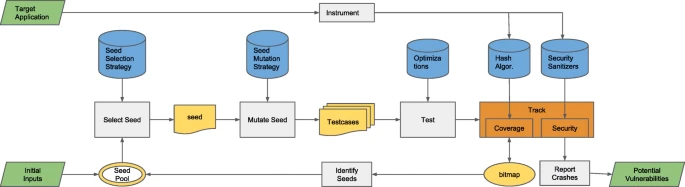
فرآیند کار فازینگ
شکل 1 فرآیندهای اصلی آزمونهای فازینگ سنتی را نشان میدهد. فرآیند کار شامل چهار مرحله اصلی است: مرحله تولید کیسهای تست، مرحله اجرای کیسهای تست، نظارت بر وضعیت اجرایی برنامه و تحلیل استثناها.
یک آزمون فازینگ از تولید مجموعهای از ورودیهای برنامه، یعنی کیسهای تست، آغاز میشود. کیفیت کیسهای تست تولید شده به طور مستقیم بر اثرات آزمون تأثیر میگذارد. ورودیها باید تا حد ممکن با الزامات برنامههای آزمایش شده برای فرمت ورودی سازگار باشند. از سوی دیگر، ورودیها باید به اندازه کافی خراب باشند تا پردازش بر روی آنها بتواند شرایط خاصی از جمله استثناها و خطاهای غیرمنتظره را ایجاد کند.
این ورودیها احتمالا باعث شکست برنامه خواهند شد. بسته به برنامههای هدف، ورودیها میتوانند فایلهایی با فرمتهای مختلف، دادههای ارتباطات شبکه، باینریهای اجرایی با ویژگیهای مشخص و غیره باشند. ایجاد کیسهای تست به اندازه کافی خراب، چالش اصلی برای فازرها است. به طور کلی، دو نوع تولیدکننده در فازرهای به روز استفاده میشود: تولیدکنندههای مبتنی بر تولید و تولیدکنندههای مبتنی بر جهش.
کیسهای تست پس از تولید در مرحله قبلی به برنامههای هدف داده میشوند. فازرها به طور خودکار فرآیند برنامه هدف را شروع و به پایان میرسانند و فرآیند پردازش کیسهای تست برنامههای هدف را کنترل میکنند. تحلیلگران میتوانند قبل از اجرا، نحوه شروع و پایان برنامههای هدف را پیکربندی کنند و پارامترها و متغیرهای محیطی را از پیش تعریف کنند. فرآیند فازینگ معمولا در یک زمانسنج از پیش تعیین شده متوقف میشود، یا اجرای برنامه متوقف میگردد یا کرش میکند.
فازرها در حین اجرای برنامههای هدف، وضعیت اجرای آن را نظارت میکنند و منتظر استثناها و کرشها هستند. روشهای معمول نظارت بر استثنا شامل نظارت بر سیگنالهای سیستمی خاص، کرشها و سایر نقایص است. برای نقایص بدون رفتارهای غیرعادی واضح در برنامه، ابزارهای زیادی میتوانند استفاده شوند، از جمله AddressSanitizer (سرابیانی و همکاران 2012)، DataFlowsanitizer (تیم کلنگ 2017 ،)، ThreadSanitizer (سرابیانی و اسخودجانوف 2009)، LeakSanitizer (تیم کلنگ 2017) و غیره. زمانی که نقایص ثبت میشوند، فازرها کیس تست مربوطه را برای پخش و تحلیل بعدی ذخیره میکنند.
تحلیلگران در مرحله تحلیل، سعی میکنند مکان و علت اصلی نقایص ثبت شده را تعیین کنند. این تحلیل غالبا با کمک اشکالزداها انجام میشود، مانند windbg ،GDB، یا سایر ابزارهای تحلیل باینری، مانند OllyDbg ،IDA Pro و غیره. ابزارهای سازگاری باینری، مانند Pin (لوک و همکاران 2005) نیز میتوانند برای نظارت بر وضعیت دقیق اجرای کیسهای تست جمعآوری شده، مانند اطلاعات مربوط به رشته، دستورها، اطلاعات رجیستر و غیره استفاده شوند. تحلیل کرش به طور خودکار زمینه مهم دیگری از تحقیق است.
انواع فازرها
فازرها میتوانند به طرق مختلفی طبقهبندی شوند. یک فازر میتواند به عنوان فازر مبتنی بر تولید و فازر مبتنی بر جهش (وان اسپراندل 2005) طبقه بندی شود. برای یک فازر مبتنی بر تولید، دانش ورودی برنامه مورد نیاز است. برای آزمایش فرمت فایل، معمولا یک فایل پیکربندی که فرمت فایل را از پیش تعریف میکند، ارائه میشود. کیسهای تست بر اساس فایل پیکربندی تولید میشوند. با داشتن دانش فرمت فایل، کیسهای تست تولید شده توسط فازرهای مبتنی بر تولید قادر به عبور از اعتبارسنجی برنامهها به راحتی هستند و بیشتر به احتمال زیاد میتوانند کد عمیقتر برنامههای هدف را آزمایش کنند. با این حال، بدون وجود مستندات مناسب، تجزیه و تحلیل فرمت فایل کار دشواری است. بنابراین، فازرهای مبتنی بر جهش راهاندازی آسانتری دارند و کاربردیتر هستند و به طور گستردهای توسط فازرهای به روز استفاده میشوند.
فازرهای مبتنی بر جهش به یک مجموعه ورودیهای اولیه معتبر نیاز دارند. کیسهای تست از طریق جهش ورودیهای اولیه و کیسهای تست تولید شده در طول فرآیند فازینگ تولید میشوند. ما فازرهای مبتنی بر تولید و فازرهای مبتنی بر جهش را در جدول 2 مقایسه میکنیم.
با توجه به وابستگی به کد منبع برنامه و درجه تحلیل برنامه، فازرها میتوانند به سه دسته تقسیم شوند: فازرهای جعبه سفید، جعبه خاکستری و جعبه سیاه. فازرهای جعبه سفید فرض میکنند که به کد منبع برنامهها دسترسی دارند، بنابراین اطلاعات بیشتری را میتوان از طریق تحلیل کد منبع و اینکه چگونه کیسهای تست بر وضعیت اجرای برنامه تأثیر میگذارند، جمعآوری کرد. فازرهای جعبه سیاه آزمونهای فازینگ را بدون هیچگونه دانشی از جزئیات داخلی برنامه هدف انجام میدهند. فازرهای جعبه خاکستری نیز بدون کد منبع کار میکنند و اطلاعات داخلی برنامههای هدف را از طریق تحلیل برنامه بهدست میآورند. ما برخی از فازرهای معمول جعبه سفید، جعبه خاکستری و جعبه سیاه را در جدول 3 فهرست میکنیم.
با توجه به استراتژیهای اکتشاف برنامهها، فازرها میتوانند به دو دسته فازینگ هدفدار و فازینگ مبتنی بر پوشش تقسیم شوند. فازر هدفدار، هدف از تولید کیسهای تستی است که کد هدف و مسیرهای هدف برنامهها را پوشش دهد، و فازر مبتنی بر پوشش، هدف از تولید کیسهای تستی است که تا حد امکان کد بیشتری از برنامهها را پوشش دهد. فازرهای هدفدار به یک آزمون سریعتر روی برنامهها انتظار دارند، و فازرهای مبتنی بر پوشش به یک آزمون دقیقتر و شناسایی هر چه بیشتر اشکالات امید دارند. استخراج اطلاعات مسیرهای اجرایی شده برای هر دو فازر هدفدار و فازرهای مبتنی بر پوشش، یک مشکل کلیدی به شمار میرود.
فازرها میتوانند به دو دسته فازرهای سطحی و فازرهای هوشمند بر اساس وجود یا عدم وجود بازخورد بین نظارت بر وضعیت اجرای برنامه و تولید کیسهای تست تقسیم شوند. فازرهای هوشمند، تولید کیسهای تست را بر اساس اطلاعات جمعآوری شده در مورد اینکه چگونه کیسهای تست بر رفتار برنامه تأثیر میگذارند، تنظیم میکنند. برای فازرهای مبتنی بر جهش، اطلاعات بازخورد میتواند برای تعیین اینکه کدام بخش از کیسهای تست باید جهش یابد و نحوه جهش آنها استفاده شود. فازرهای سطحی سرعت آزمون بهتری را به دست میآورند، در حالی که فازرهای هوشمند کیسهای تست بهتری تولید کرده و کارایی بهتری به دست میآورند.
چالشهای کلیدی در فازینگ
فازرهای سنتی معمولا در عمل از یک استراتژی فازینگ مبتنی بر تصادف استفاده میکنند. محدودیتهای تحلیل برنامه فازرهای مبتنی بر جهش به یک مجموعه ورودیهای اولیه معتبر نیاز دارند. کیسهای تست از طریق جهش ورودیهای اولیه و کیسهای تست تولید شده در طول فرآیند فازینگ تولید میشوند. ما فازرهای مبتنی بر تولید و فازرهای مبتنی بر جهش را در جدول 2 مقایسه میکنیم.
جدول 2. مقایسه فازرهای مبتنی بر تولید و فازرهای مبتنی بر جهش
Ability to Pass Validation | Coverage | Prior Knowledge | Esay to Start? | |
Strong | High | Needed, hard to acquire | Hard | Generation Based |
Weak | Low, affected by initial inputs | Not Needed | Easy | Mutation Based |
جدول 3. فازرهای جعبه سفید، جعبه خاکستری و جعبه سیاه رایج
Black Box Fuzzers | Gray Box Fuzzers | White Box Fuzzers | |
Spike (Bowne 2015), Sulley (Amini 2017), Peach (PeachTech 2017) | Generation Based | ||
Sage (Godefroid et al. 2012), Libfuzzer (libfuzzer 2017) | AFL (Zalewski 2017a), Driller (Stephens et al. 2016), Vuzzer (Rawat et al. 2017), TaintScope (Wang et al. 2010), Mayhem (Cha et al. 2012) | Miller (Takanen et al. 2008) | Mutation Based |
چالش نحوه جهش ورودیهای اولیه. استراتژی تولید مبتنی بر جهش به طور گستردهای توسط فازرهای پیشرفته به دلیل سهولت و تنظیم آسان استفاده میشود. با این حال، چالش کلیدی این است که چگونه جهش ایجاد و کیسهای تستی تولید کنیم که قادر به پوشش مسیرهای بیشتری از برنامه باشند و آسانتر اشکالات را تحریک کنند (یانگ و همکاران 2007). به طور خاص، فازرهای مبتنی بر جهش نیاز به پاسخ به دو سوال هنگام انجام جهش دارند: (1) کجا جهش ایجاد کنیم، و (2) چگونه جهش ایجاد کنیم. جهش فقط در چند موقعیت کلیدی میتواند بر جریان کنترل اجرای برنامه تأثیرگذار باشد. بنابراین، چگونگی شناسایی این موقعیتهای کلیدی در کیسهای تست، اهمیت زیادی دارد. علاوه بر این، نحوه جهش فازرها در موقعیتهای کلیدی یک مشکل کلیدی دیگر است، یعنی چگونه میتوانیم مقداری را تعیین کنیم که بتواند آزمایش را به مسیرهای جالب برنامهها هدایت کند. به طور خلاصه، جهش کور در کیسهای تست منجر به هدررفت شدید منابع آزمایش میشود و یک استراتژی جهش بهتر میتواند به طور چشمگیری کارایی فازینگ را بهبود بخشد.
چالش پوشش کم کد. پوشش بالاتر کد نشان دهنده پوشش بیشتر وضعیتهای اجرایی برنامه و آزمایش جامعتری است. کارهای قبلی ثابت کردهاند که پوشش بهتر منجر به افزایش احتمال پیدا کردن اشکالات میشود. با این حال، بیشتر کیسهای تست فقط مسیرهای مشابهی را پوشش میدهند، در حالی که بیشتر کد قابل دسترسی نیست. در نتیجه، دستیابی به پوشش بالا تنها از طریق تولید مقادیر زیادی از کیسهای تست و صرف منابع آزمایش، انتخاب عاقلانهای نیست. فازرهای مبتنی بر پوشش تلاش میکنند این مشکل را با کمک تکنیکهای تحلیل برنامه، مانند ابزارسازی برنامه، حل کنند. ما جزئیات این موضوع را در بخش بعدی معرفی خواهیم کرد.
چالش عبور از اعتبارسنجی. برنامهها معمولا قبل از تجزیه و پردازش ورودیها، اعتبار آنها را بررسی میکنند. اعتبارسنجی به عنوان یک محافظ برای برنامهها عمل میکند و در منابع محاسباتی صرفه جویی کرده و برنامه را در برابر ورودیهای نامعتبر و آسیبهای ناشی از ورودیهای بدخواهانه محافظت میکند. ورودیهای نامعتبر معمولا نادیده گرفته شده یا دور ریخته میشوند.
اعداد جادویی، رشتههای جادویی، بررسی شماره نسخه و checksumها از جمله اعتبارسنجیهای متداولی هستند که در برنامهها استفاده میشوند. کیسهای تست تولید شده توسط فازرهای جعبه سیاه و جعبه خاکستری به خاطر استراتژی تولید کور، سختتر میتوانند از اعتبارسنجی عبور کنند که منجر به کارایی پایین فازینگ میشود. بنابراین، چگونگی عبور از اعتبارسنجی یک چالش کلیدی دیگر است.
روشهای مختلفی به عنوان تدابیر مقابله با این چالشها پیشنهاد شدهاند و تکنیکهای سنتی، مانند ابزارسازی برنامه و تحلیل آلودگی و همچنین تکنیکهای جدیدی، مانند RNN و LSTM (گودفروید و همکاران 2017 ، راجپال و همکاران 2017) در این زمینه مطرح هستند. اینکه چگونه این تکنیکها میتوانند به چالشها پاسخ دهند در بخش “تکنیکهای ادغام شده در فازینگ “مورد بحث قرار خواهد گرفت.
فازینگ مبتنی بر پوشش
استراتژی فازینگ مبتنی بر پوشش به طور گستردهای توسط فازرهای پیشرفته استفاده میشود و به طور مؤثری ثابت شده است. برای دستیابی به فازینگ عمیق و جامع برنامه، فازرها باید سعی کنند تا حد امکان به بیشتر وضعیتهای اجرایی برنامه دسترسی پیدا کنند. با این حال، به دلیل عدم قطعیت در رفتارهای برنامه، یک متریک ساده برای وضعیتهای برنامه وجود ندارد. علاوه بر این، یک متریک خوب باید در حین اجرای فرآیند به راحتی قابل تعیین باشد. بنابراین، اندازه گیری پوشش کد تبدیل به یک راه حل تقریبا جایگزین میشود. با استفاده از این طرح، افزایش پوشش کد نمایانگر وضعیتهای جدید برنامه است. علاوه بر این، با استفاده از ابزارسازی داخلی و خارجی، پوشش کد به راحتی قابل اندازه گیری است. با این حال، ما میگوییم که پوشش کد یک اندازه گیری تقریبی است، زیرا در واقع، پوشش ثابت کد نشان دهنده تعداد ثابتی از وضعیتهای برنامه نیست. ممکن است در این متریک، اطلاعاتی از بین برود. ما در این بخش، AFL را به عنوان یک مثال در نظر میگیریم و بر روی فازینگ مبتنی بر پوشش روشنایی میاندازیم.
شمارش پوشش کد
در تحلیل برنامه، برنامه از بلوکهای اساسی تشکیل شده است. بلوکهای اساسی، قطعات کدی هستند که دارای یک نقطه ورودی و خروجی هستند، و دستورات در بلوکهای اساسی به صورت ترتیبی اجرا میشوند و فقط یک بار اجرا میشوند. روشهای پیشرفته در اندازه گیری پوشش کد، بلوکهای اساسی را به عنوان بهترین جزئیات در نظر میگیرند. دلایل این انتخاب شامل این است که (1) بلوکهای اساسی کوچکترین واحدهای منسجم اجرای برنامه هستند، (2) اندازه گیری تابع یا دستور منجر به از دست رفتن یا اضافه کاری اطلاعات میشود، (3) بلوکهای اساسی میتوانند با استفاده از آدرس اولین دستور شناسایی شوند و اطلاعات بلوکهای اساسی به راحتی از طریق ابزارسازی کد استخراج شوند.
در حال حاضر، دو گزینه اندازه گیری اساسی بر اساس بلوکهای اساسی وجود دارد، یکی شمارش ساده بلوکهای اساسی اجرایی و دیگری شمارش انتقالات بلوکهای اساسی. در روش دوم، برنامهها به عنوان یک گراف تفسیر میشوند و رئوس برای نمایش بلوکهای اساسی و لبهها برای نمایش انتقالات بین آنها استفاده میگردند.
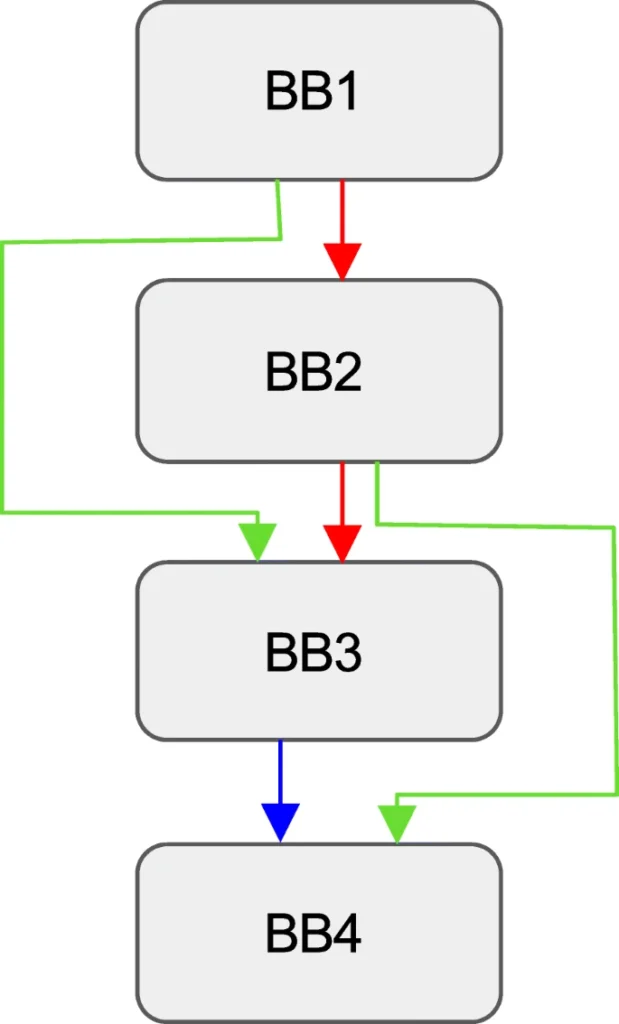
انتقال بین بلوکهای اساسی با استفاده از لبهها نمایش داده میشود. روش دوم لبهها را ثبت میکند در حالی که روش اول رئوس را ثبت میکند. در حالی که آزمایش نشان میدهد که شمارش ساده بلوکهای اساسی اجرایی منجر به از دست دادن اطلاعات جدی میشود. همانطور که در شکل 2 نشان داده شده است، چنانچه مسیر برنامه BB4 ،BB3 ،BB2 ،BB1 ابتدا اجرا شود و سپس مسیر BB4 ،BB2 ،BB1 در حین اجرا مواجه شود، اطلاعات لبه جدید BB4 ،BB2 از دست خواهد رفت.
AFL اولین کسی است که روش اندازه گیری لبه را به فازینگ مبتنی بر پوشش معرفی کرده است. ما AFL را به عنوان یک مثال در نظر میگیریم و نشان میدهیم که چگونه فازرهای مبتنی بر پوشش در طول فرآیند فازینگ اطلاعات پوشش را به دست میآورند. AFL اطلاعات پوشش را از طریق ابزارسازی سبک برنامه به دست میآورد. بسته به اینکه آیا کد منبع ارائه شده است یا خیر، AFL دو حالت ابزارسازی را ارائه میدهد: ابزارسازی در زمان کامپایل و ابزارسازی خارجی. در حالت ابزارسازی در زمان کامپایل، AFL هر دو حالت gcc و llvm را ارائه میدهد، که بسته به کامپایلری که استفاده میشود، قطعه کد را هنگام تولید باینری ابزارسازی میکند. در حالت خارجی، AFL حالت qemu را ارائه میدهد که در آن، قطعه کد هنگام تبدیل بلوکهای اساسی به بلوکهای TCG ابزارسازی میشود. لیست 1 یک طرح از قطعه کد ابزارسازی شده را نشان میدهد (زالفسکی 2017 b).
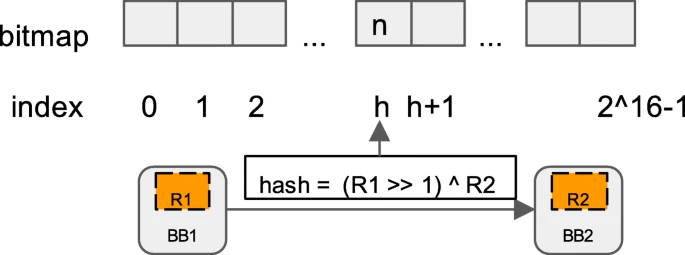
در ابزارسازی، یک شناسه تصادفی، یعنی متغیر cur_location در بلوکهای اساسی ابزارسازی میشود. متغیر shared_mem آرایهای از حافظه مشترک 64 کیلوبایتی است که هر بایت آن به یک ضربه از یک لبه خاص BB_dst ،BB_src نقشهبرداری شده است. زمانی که یک انتقال بلوک اساسی اتفاق میفتد، یک شماره هش محاسبه میشود و مقدار بایت مربوطه در آرایه bitmap بهروزرسانی میشود. شکل 3 نقشهبرداری هش و bitmap را نمایش میدهد.
;cur_location = <COMPILE_TIME_RANDOM>
; shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1
لیست 1. ابزارسازی AFL
فرآیند کاری فازینگ مبتنی بر پوشش: الگوریتم 1 فرآیند کاری کلی یک فازر مبتنی بر پوشش را نشان میدهد. آزمایش از ورودیهای اولیه داده شده آغاز میگردد. اگر مجموعه ورودی اولیه داده نشده باشد، فازر یکی را خود ایجاد میکند. در حلقه اصلی فازینگ، فازر به طور مکرر یک ورودی جالب را برای جهشهای بعدی و تولید کیسهای تست انتخاب میکند. برنامه هدف به اجرای کیسهای تستی که تولید شدهاند، تحت نظارت فازر هدایت میشود. کیسهای تستی که منجر به کرش میشوند جمعآوری شده و سایر کیسهای جالب به استخر ورودیها اضافه میشوند. برای فازینگ مبتنی بر پوشش، کیسهای تستی که به لبههای جدید جریان کنترل میرسند، بهعنوان جالب تلقی میشوند. حلقه اصلی فازینگ در یک زمان مشخص شده از پیش یا یک سیگنال قطع متوقف میگردد.
در طول فرآیند فازینگ، فازرها از روشهای مختلف برای پیگیری اجرا استفاده میکنند. اساسا، فازرها برای دو هدف، پوشش کد و نقضهای امنیتی، پیگیری اجرا را انجام میدهند. اطلاعات پوشش کد برای دنبال کردن یک کاوش دقیق از وضعیت برنامه استفاده میشود و پیگیری نقضهای امنیتی برای پیدا کردن بهتر اشکالات است. همانطور که در زیرمجموعههای قبلی جزئیات داده شده، AFL پوشش کد را از طریق ابزارسازی کد و bitmap AFL پیگیری میکند.

پیگیری نقضهای امنیتی میتواند با کمک تعداد زیادی از سمزداییکنندهها انجام شود، مانند AddressSanitizer (سربریان و همکاران 2012)، ThreadSanitizer (سربریان و اسخیصد جانوف 2009)، LeakSanitizer (تیم کلنگ b 2017) و غیره.
شکل 4 فرآیند کاری AFL ، یک فازر مبتنی بر پوشش بسیار نماینده را نشان میدهد. برنامه هدف قبل از اجرا برای جمعآوری پوشش ابزارسازی میشود.
همانطور که قبلا ذکر شد، AFL از هر دو حالت ابزارسازی در زمان کامپایل و ابزارسازی خارجی پشتیبانی میکند، به صورتی که شامل حالتهای gcc/llvm و qemu است. همچنین باید ورودیهای اولیه ارائه شود. در حلقه اصلی فازینگ، (1) فازر یک ورودی دلخواه از استخر ورودیها با توجه به استراتژی انتخاب ورودیها انتخاب میکند و AFL ورودیهایی را که سریعتر و کوچکتر هستند، ترجیح میدهد. (2) فایلهای ورودی با توجه به استراتژی جهش تغییر داده میشوند و تعدادی کیس تست تولید میشوند. AFL در حال حاضر از برخی تغییرات تصادفی و روشهای ترکیب کیس تست شامل معکوسسازی بیتهای متوالی استفاده میکند.
کیسهای تست با طولها و گامهای متفاوت، جمع و تفریق متوالی اعداد کوچک و وارد کردن متوالی اعداد جالب شناخته شده مانند 0، 1، INT_MAX و غیره (زالفسکی b 2017) (3) اجرا میشوند و اجرا تحت پیگیری قرار دارد. اطلاعات پوشش جمعآوری میشود تا کیسهای تست جالب را که به لبههای جدید جریان کنترل میرسند، تعیین کند. کیسهای تست جالب به استخر ورودیها برای دور بعدی اضافه میشوند.
سؤالات کلیدی
معرفی قبلی نشان میدهد که سوالات زیادی باید حل شوند تا فازینگ مبتنی بر پوشش به طور مؤثر و کارآمد انجام گیرد. اکتشافات زیادی در این زمینه انجام شده است. ما برخی از جدیدترین کارها را در این زیرشاخه جمعبندی و فهرست میکنیم، همانطور که در جدول 4 نشان داده شده است.
A. چگونه ورودیهای اولیه را به دست آوریم؟
اکثر فازرهای مبتنی بر پوشش از استراتژی تولید کیس تست مبتنی بر جهش استفاده میکنند که به شدت به کیفیت ورودیهای اولیه وابسته است. ورودیهای اولیه خوب میتوانند به طور قابل توجهی کارایی و اثربخشی فازینگ را بهبود بخشند. به طور خاص (1) ارائه ورودیهای اولیه با فرمت مناسب میتواند زمانهای CPU زیادی را که در ساخت آن صرف میشود، صرفه جویی کند، (2) ورودیهای اولیه مناسب میتوانند نیازهای فرمتهای فایل پیچیده را برآورده کنند که در مرحله جهش سخت است حدس زد، (3) جهش بر اساس ورودیهای اولیه با فرمت مناسب احتمال بیشتری دارد که کیسهای تستی تولید کند که بتوانند به مسیرهای عمیقتر و دشوارتر دسترسی پیدا کنند، (4) ورودیهای اولیه خوب میتوانند در چندین آزمون دوباره استفاده شوند.
روشهای رایج جمع آوری ورودیهای اولیه شامل استفاده از بنچمارکهای استاندارد، جستجودر وب میشوند. برنامههای متن باز معمولا با یک بنچمارک استاندارد منتشر میشوند که برای تست پروژهها به طور رایگان قابل استفاده است. این بنچمارک ارائه شده بر اساس ویژگیها و عملکردهای برنامهها ساخته شده است که طبیعی است که یک مجموعه خوب از ورودیهای اولیه را بسازد. با توجه به تنوع ورودیهای برنامه هدف، جستجو از اینترنت سادهترین روش است. شما میتوانید به راحتی فایلهایی با فرمتهای خاص را دانلود کنید. علاوه بر این، برای برخی از فرمتهای فایل معمولی، پروژههای آزمایشی زیادی در شبکه وجود دارد که مجموعه دادههای آزمایشی رایگان را ارائه میدهند. همچنین، استفاده از نمونههای POC موجود نیز ایده خوبی است. با این حال، تعداد زیاد ورودیهای اولیه باعث هدر رفتن زمان در اولین اجرای آزمایشی میشود، بنابراین نگرانی دیگری به وجود میآید: چگونه ابتدا مجموعه ورودیها را استفاده کنیم. AFL ابزاری را ارائه میدهد که حداقل مجموعهای از ورودیها را استخراج میکند که همان پوشش کد را دست مییابد.
B. چگونه کیسهای تست تولید کنیم؟
کیفیت کیسهای تست یکی از عوامل مهمی است که بر کارایی و اثربخشی تست فازینگ تأثیر میگذارد. اولا، کیسهای تست خوب میتوانند وضعیتهای بیشتری از اجرای برنامه را اکتشاف کرده و کد بیشتری را در زمان کمتری پوشش دهند. علاوه بر این، کیسهای تست خوب میتوانند موقعیتهای آسیبپذیر بالقوه را هدف قرار دهند و کشف سریعتر اشکالات برنامه را به ارمغان آورند. از این رو، اینکه چگونه کیسهای تست خوبی بر مبنای ورودیهای اولیه تولید کنیم، یک نگرانی مهم است.
راوات و همکاران (2017)، Vuzzer را پیشنهاد کردند که یک فازر خاکستری آگاه از برنامه است که با تجزیه و تحلیل استاتیک و دینامیک ترکیب میشود.
جهش ورودیهای اولیه شامل دو سؤال کلیدی است: کجا باید جهش انجام شود و چه مقداری برای جهش استفاده کنیم. به طور خاص، Vuzzer مقادیر فوری، مقادیر جادویی و سایر رشتههای مشخصه را استخراج میکند که کنترل جریان را از طریق تحلیل استاتیک قبل از حلقه اصلی فازینگ تحت تأثیر قرار میدهد. در حین اجرای برنامه، Vuzzer از تکنیک تحلیل آلودگی دینامیک برای جمعآوری اطلاعاتی که بر شاخههای کنترل جریان تأثیر میگذارد، شامل مقدار خاص و جابجایی مربوطه استفاده میکند.
جدول 4. مقایسه تکنیکهای مختلف
Initial inputs get | Inputs mutation | Seed selection | Testing efficiency |
Standard benchmarks; | Vuzzer (Rawat et al. 2017)
| AFLFast (Bohme et al. 2017)
| Forkserver
|
Crawling from Internet;
| Skyfire (Wang et al. 2017)
| Vuzzer | Intel PT (Schumilo et al. 2017)
|
POC samples; | Learn & Fuzz (Godefroid et al. 2017) Faster Fuzzing (Nichols et al. 2017) Work (Rajpal et al. 2017) | AFLGO (2017) QTEP (Wang et al. 2017) SlowFuzz (Petsios et al. 2017) | (Icamtuf 2014) Work (Xu et al. 2017) |
با جهش توسط مقادیر جمعآوری شده و جهش در مکانهای شناسایی شده، Vuzzer میتواند کیسهای تستی تولید کند که احتمالا به شرایط قضاوت شاخه برسند و اعتبارسنجی مقادیر جادویی را پاس کنند. با این حال، Vuzzer هنوز نمیتواند سایر انواع اعتبارسنجیها در برنامهها مانند checksum مبتنی بر هش را پاس کند. علاوه بر این، ابزار Vuzzer، تحلیل آلودگی و حلقه اصلی فازینگ آن بر اساس Pin (لوک و همکاران 2005) پیاده سازی شده است که در مقایسه با AFL سرعت تست نسبتا کندی دارد.
وانگ و همکاران (2017)، یک راه حل تولید ورودی مبتنی بر داده به نام Skyfire را پیشنهاد کردند. Skyfire یک گرامر حساس به زمینه احتمالاتی (PCSG) را از ورودیهای جستجو شده یاد میگیرد و از دانش آموخته شده در تولید ورودیهای ساختار یافته خوب استفاده میکند. آزمایش نشان میدهد که کیسهای تست تولید شده توسط Skyfire کد بیشتری را نسبت به آنهایی که توسط AFL تولید شدهاند پوشش میدهند و اشکالات بیشتری پیدا میکنند. این کار همچنین ثابت میکند که کیفیت کیسهای تست یک عامل مهم است که بر کارایی و اثربخشی فازینگ تأثیر میگذارد.
با توسعه و استفاده گسترده از تکنیکهای یادگیری ماشین، برخی از تحقیقات تلاش کردهاند از تکنیکهای یادگیری ماشین برای کمک به تولید کیسهای تست استفاده کنند. گودفروید و همکاران (2017) از مایکروسافت ریسرچ از تکنیکهای یادگیری ماشین مبتنی بر شبکه عصبی برای تولید خودکار کیسهای تست استفاده میکنند. آنها به طور خاص، ابتدا فرمت ورودی را از یک دسته ورودی معتبر از طریق تکنیکهای یادگیری ماشین یاد میگیرند و سپس از دانش آموخته شده برای هدایت تولید کیسهای تست استفاده میکنند. آنها یک فرآیند فازینگ بر روی تجزیه کننده PDF در مرورگر Edge مایکروسافت ارائه میدهند. اگرچه آزمایش نتیجهای امیدوارکننده ارائه نکرد، این هنوز یک تلاش خوب است.
راجپال و همکاران (2017) از مایکروسافت از شبکههای عصبی برای یادگیری از اکتشافات گذشتۀ فازینگ و پیشبینی اینکه کدام بایت باید در فایلهای ورودی جهش یابد، استفاده میکنند. نیکولز و همکاران (2017) از مدلهای شبکه تقابلی تولید (GAN) برای کمک به راه اندازی مجدد سیستم با فایلهای ورودی نوین استفاده میکنند. آزمایش نشان میدهد که GAN سریعتر و مؤثرتر از LSTM است و به کشف مسیرهای کد بیشتری کمک میکند.
C. چگونه باید ورودی را از استخر انتخاب کرد؟
فازرها به طور مکرر از استخر ورودیها برای جهش در ابتدای هر دور جدید آزمایش در حلقه اصلی فازینگ انتخاب میکنند. نحوه انتخاب ورودی از استخر، مشکل مهم دیگری در فازینگ است. کارهای قبلی ثابت کردهاند که استراتژیهای خوب انتخاب ورودی میتوانند کارایی فازینگ را به طور قابل توجهی بهبود بخشند و به یافتن اشکالات بیشتر و سریعتر کمک کنند (راوات و همکاران 2017؛ بومه و همکاران 2017؛ وانگ و همکاران 2017). با استراتژیهای خوب انتخاب ورودی، فازرها میتوانند: (1) ورودیهایی را که مفیدتر هستند اولویت بندی کنند، شامل پوشش کد بیشتر و احتمال بیشتری در تحریک آسیب پذیریها، (2) هدر رفتن اجرای مکرر مسیرها را کاهش دهند و منابع محاسباتی، (3) انتخاب بهینه ورودیها که کدهای عمیقتر و آسیبپذیرتر را پوشش دهند و به شناسایی آسیبپذیریهای پنهان سریعتر کمک کنند. AFL ورودیهای کوچکتر و سریعتر را ترجیح میدهد تا به سرعت تست بیشتری دست یابد.
بومه و همکاران (2017)، یک فازر خاکستری مبتنی بر پوشش یعنی AFLFast را پیشنهاد کردند. آنها مشاهده کردند که اکثر کیسهای تست بر روی چندین مسیر خاص متمرکز هستند. به عنوان مثال، در یک برنامه پردازش PNG، بیشتر کیسهای تست تولید شده از طریق جهش تصادفی نامعتبر هستند و مسیرهای مدیریت خطا را فعال میکنند. AFLFast مسیرها را به مسیرهای پرت و کم فرکانس تقسیم میکند. AFLFast در طول فرآیند فازینگ، فراوانی مسیرهای اجرا شده را اندازه گیری میکند، ورودیهایی که تعداد کمتری بارها فاز شدهاند را اولویت بندی کرده و انرژی بیشتری به ورودیهایی اختصاص میدهد که مسیرهای کمفراوان را فعال میکند.
راوات و همکاران (2017) تحلیل استاتیک و دینامیک را برای شناسایی مسیرهای عمیقتر و سخت تا دست یابی ترکیب کردند و ورودیهایی که به مسیرهای عمیقتر میرسند را اولویت بندی کردند. استراتژی انتخاب ورودی Vuzzer میتواند به یافتن آسیب پذیریهای پنهان در مسیرهای عمیق کمک کند.
AFLGo (بومه و همکاران 2017) و QTEP (وانگ و همکاران 2017) از یک استراتژی انتخاب هدایت شده استفاده میکنند. AFLGo برخی از کدهای آسیب پذیر را به عنوان مکانهای هدف تعریف میکند و کیسهای تستی را که به مکانهای هدف نزدیکتر هستند به طور بهینه انتخاب میکند. چهار نوع کد آسیب پذیر در مقاله AFLGo ذکر شده است، از جمله patchها، سقوطهای برنامه که اطلاعات ردیابی کافی ندارند، نتایج تأیید شده توسط ابزارهای تحلیل استاتیک و قطعات کد مرتبط با اطلاعات حساس. AFLGo با الگوریتم هدایت شده مناسب، میتواند منابع تست بیشتری را بر روی کدهای جالب اختصاص دهد. QTEP از تحلیل کد استاتیک برای شناسایی کد منبع مستعد خطا استفاده میکند و ورودیهایی را که کدهای معیوب بیشتری را پوشش میدهند، اولویت بندی میکند. هر دو AFLGo و QTEP به شدت به اثربخشی ابزارهای تحلیل استاتیک وابستهاند. با این حال، درصد مثبت کاذب ابزارهای تحلیل استاتیک فعلی هنوز بالا است و نمیتواند تأیید دقیقی را ارائه دهد. ویژگیهای آسیبپذیریهای شناخته شده نیز میتواند در استراتژی انتخاب ورودیها مورد استفاده قرار گیرد. SlowFuzz پتزیوس و همکاران 2017 بر روی آسیب پذیریهای پیچیدگی الگوریتمی تمرکز دارد که معمولا با مصرف بالای منابع محاسباتی همراه است. از این رو SlowFuzz ورودیهایی را که منابع بیشتری مانند زمانهای CPU و حافظه مصرف میکنند، ترجیح میدهد. با این حال، جمعآوری اطلاعات مصرف منابع بار بالایی را به همراه دارد و کارایی فازینگ را کاهش میدهد. به عنوان مثال، SlowFuzz برای جمعآوری زمان ،CPU تعداد دستورالعملهای اجرا شده را شمارش میکند. علاوه بر این، SlowFuzz به دقت بالایی از اطلاعات مصرف منابع نیاز دارد.
D.چگونه میتوان برنامهها را به طور کارآمد تست کرد؟
برنامههای هدف به طور مکرر توسط فازرها در حلقه اصلی فازینگ راهاندازی و خاتمه مییابند. همانطور که میدانیم، برای فازینگ برنامههای کاربری، ایجاد و اتمام فرآیند زمان زیادی از CPU را مصرف میکند. ایجاد و اتمام مکرر فرآیند به شدت میتواند کارایی فازینگ را کاهش دهد.
در نتیجه، کارهای قبلی به انجام بسیاری از بهینه سازیها پرداختهاند. هر دو ویژگیهای سیستم سنتی و ویژگیهای جدید در این بهینه سازیها مورد استفاده قرار گرفتهاند. AFL از روش forkserver استفاده میکند، که یک کلون مشابه از برنامه قبلا بارگذاری شده ایجاد میکند و از این کلون برای هر بار اجرای منفرد استفاده خواهد کرد. علاوه بر این، AFL حالت پایدار (persistent mode) را نیز ارائه میدهد که به جلوگیری از بار اضافی ناشی از ()syscall execve و فرآیند لینکینگ کمک میکند و حالت موازی (parallel mode) که به موازیسازی تست در سیستمهای چند هستهای کمک میکند. فناوری Trace پردازنده اینتل (PT) (جیمز 2013) در فازینگ هسته برای کاهش بار ناشی از ردیابی پوشش استفاده میشود. ژو و همکاران (2017) به حل گلوگاههای عملکردی فازینگ موازی بر روی ماشینهای چند هستهای میپردازند. آنها با طراحی و پیادهسازی سه عملگر جدید سیستم عاملی، نشان میدهند که کار آنها میتواند به طور قابل توجهی فازرهای پیشرفتهای مانند AFL و LibFuzzer را تسریع بخشد.
تکنیکهای ترکیب شده در فازینگ
برنامههای مدرن معمولا از ساختارهای داده بسیار پیچیده استفاده میکنند و تجزیه بر روی این ساختارهای داده پیچیده بیشتر احتمال دارد که به آسیب پذیریهایی منجر شود. استراتژیهای فازینگ کور که از روشهای جهش تصادفی استفاده میکنند، منجر به ایجاد تعداد زیادی کیس تست نامعتبر و کارایی پایین فازینگ میشوند. در حال حاضر، فازرهای پیشرفته معمولا از یک استراتژی فازینگ هوشمند استفاده میکنند. فازرهای هوشمند اطلاعات جریان کنترل و جریان داده برنامه را از طریق تکنیکهای تحلیل برنامه جمعآوری کرده و سپس از اطلاعات جمعآوری شده برای بهبود تولید کیسهای تست استفاده میکنند. کیسهای تست تولید شده توسط فازرهای هوشمند هدفمندتر هستند و احتمال بیشتری دارند که نیازهای برنامهها را برای ساختار داده و قضاوت منطقی برآورده کنند. شکل ۵ یک طرح از فازینگ هوشمند را به تصویر میکشد. برای ساخت یک فازر هوشمند، مجموعهای ازتکنیکها در فازینگ ترکیب شده است. همانطور که در بخشهای قبلی ذکر شد، فازینگ در عمل با چالشهای زیادی رو به روست. در این بخش، سعی میکنیم تکنیکهای استفاده شده در کارهای قبلی را خلاصه کنیم و اینکه این تکنیکها چگونه چالشها را در فرآیند فازینگ حل میکنند.
ما تکنیکهای اصلی ترکیب شده در فازینگ را در جدول ۵ خلاصه کردیم. برای هر تکنیک، برخی از کارهای نماینده را در جدول میزنیم. هر دو تکنیکهای سنتی، شامل تحلیل استاتیک تحلیل آلودگی، و اجرای نمادین، و برخی تکنیکهای نسبتا جدید مانند تکنیکهای یادگیری ماشین استفاده میشوند. ما دو مرحله کلیدی در فازینگ، یعنی مرحله تولید کیسهای تست و مرحله اجرای برنامه را انتخاب کرده و خلاصهای از چگونگی بهبود فازینگ توسط تکنیکهای یکپارچه ارائه میدهیم.
تولید کیسهای تست
همانطور که قبلتر ذکر شد، کیسهای تست در فازینگ به روشهای تولید مبتنی بر الگوریتم یا جهش مبتنی بر الگوریتم تولید میشوند. نحوه تولید کیسهای تستی که الزامات ساختار دادههای پیچیده را برآورده کنند و احتمالا به تحریک مسیرهای دشوار برسند، یک چالش کلیدی است. کارهای قبلی پیشنهادات متنوعی را همراه با تکنیکهای مختلف ارائه دادهاند.
مولد در فازینگ مبتنی بر تولید، کیسهای تست را بر اساس دانش فرمت دادههای ورودی تولید میکند. اگرچه برای چندین فرمت فایل رایج، مستندات در دسترس است، اما برای بسیاری دیگر اینطور نیست. به دست آوردن اطلاعات فرمت ورودیها یک مشکل باز دشوار است. از تکنیکهای یادگیری ماشین و روشهای فرمت برای حل این مشکل استفاده میشود. کار (گودفروید و همکاران 2017) از تکنیکهای یادگیری ماشین، به طور خاص، شبکههای عصبی بازگشتی، برای یادگیری گرامر فایلهای ورودی استفاده میکند و در نتیجه از گرامر یادگرفته شده برای تولید کیسهای تستی که فرمت را رعایت میکنند، استفاده میکند. کار (وانگ و همکاران 2017) از روش فرمت استفاده میکند، به طور خاص آنها یک گرامر احتمال محور و حساس به زمینه تعریف کرده و دانش فرمت را استخراج میکنند تا ورودیهای seed با فرمت خوب تولید نمایند.
بیشتر فازرهای پیشرفته از استراتژی فازینگ مبتنی بر جهش استفاده میکنند. کیسهای تست با اصلاح بخشی از ورودیهای seed در فرآیند جهش تولید میشوند. در یک فرآیند فازینگ جهش کور، جهش دهندهها به طور تصادفی بایتهای ورودیهای seed را با مقادیر تصادفی یا چندین مقدار خاص اصلاح میکنند، که ثابت شده است بسیار ناسازگار و ناکارآمد است. بنابراین، نحوه تعیین مکان برای اصلاح و مقداری که در اصلاح استفاده میشود، یک چالش کلیدی دیگر است. در فازینگ مبتنی بر پوشش، بایتهایی که میتوانند بر روی انتقال جریان کنترل تأثیر بگذارند، باید در ابتدا اصلاح شوند. تکنیک تحلیل آلودگی برای ردیابی تأثیر بایتها بر جریان کنترل استفاده میشود تا بایتهای کلیدی ورودیهای seed را در فرآیند جهش شناسایی کند. (راوات و همکاران 2017 ) دانستن مکانهای کلیدی فقط آغاز ماجرا است. طبق نظریه راوات و همکاران (2017)، دانستن مکانهای کلیدی فقط آغاز ماجرا است.

جدول 5. تکنیکهای ادغامشده در فازینگ
Program Execution | Testing Generation | |||
Path Exploration | Guiding | Mutation | Generation | Techniques |
* | * | * | Static analysis | |
* | * | Taint analysis | ||
* | * | * | Instrumentation | |
* | Symbolic execution | |||
* | * | Machin Learning | ||
* | Format Method | |||
به طور معمول، فرآیندها در برخی شاخهها، از جمله اعتبارسنجیها و بررسیها، مسدود میشوند. به عنوان مثال، بایتهای جادویی و سایر مقایسههای مقداری در قضاوتهای شرطی و تکنیکهایی از قبیل مهندسی معکوس و تحلیل آلودگی استفاده میشوند. با اسکن کد باینری و جمعآوری مقادیر فوری از عبارات قضاوت شرطی و استفاده از مقادیر جمعآوری شده به عنوان مقادیر کاندید در فرآیند جهش، فازرها میتوانند برخی از اعتبارسنجیها و بررسیهای کلیدی، مانند بایتهای جادویی و بررسی نسخه را دور بزنند.
راوات و همکاران (2017) تکنیکهای جدیدی مانند تکنیکهای یادگیری ماشین را نیز برای حل چالشهای قدیمی امتحان کردهاند. پژوهشگران مایکروسافت از تکنیکهای یادگیری ماشین مانند شبکههای عصبی عمیق (DNN) برای پیش بینی اینکه کدام بایتها باید تغییر یابند و چه مقداری در تغییر استفاده شوند بر اساس تجربیات قبلی فازینگ، از طریق LSTM استفاده میکنند.
اجرای برنامه
در حلقه اصلی فازینگ، برنامههای هدف به طور مکرر اجرا میشوند. اطلاعات وضعیت اجرای برنامه استخراج و برای بهبود اجرای برنامه استفاده میشود. دو مشکل کلیدی در مرحله اجرا این است که چگونه فرآیند فازینگ را راهنمایی کنیم و چگونه مسیرهای جدید را کشف نماییم. فرآیند فازینگ معمولا به گونهای راهنمایی میشود که کد بیشتری پوشش یابد و اشکالات را سریعتر کشف کند از این رو، اطلاعات اجرای مسیر ضروری است. تکنیکهای ابزارآلات (instrumentation) برای ثبت اجرای مسیر و محاسبه اطلاعات پوشش در فازینگ مبتنی بر پوشش استفاده میشود. بر اساس اینکه آیا کد منبع ارائه شده است یا خیر، از ابزارآلات داخلی و همچنین ابزارآلات خارجی استفاده میشود. برای فازینگ هدایت شده، تکنیکهای تحلیل استاتیک مانند شناسایی الگو برای مشخص و شناسایی کد هدف، که بیشتر آسیب پذیر است، به کار میروند. تکنیکهای تحلیل استاتیک همچنین میتوانند برای جمعآوری اطلاعات جریان کنترل، به عنوان مثال عمق مسیر، استفاده شوند که میتواند به عنوان یک مرجع دیگر در استراتژی راهنمایی مورد استفاده قرار گیرد (راوات و همکاران 2017). اطلاعات اجرای مسیر جمع آوری شده از طریق ابزارآلات میتواند به هدایت فرآیند فازینگ کمک کند. برخی ویژگیهای جدید سیستم و ویژگیهای سخت افزاری نیز در جمع آوری اطلاعات اجرا استفاده میشود. Trace پردازنده اینتل (Intel PT) یک ویژگی جدید است که توسط پردازندههای اینتل ارائه شده و میتواند یک ردگیری دقیق و جزئی از فعالیتها با قابلیتهای راهاندازی و فیلتر کردن ارائه دهد تا به جداسازی ردگیریهایی که اهمیت دارند کمک کند (جیمز 2013). با مزیت سرعت اجرای بالا و عدم وابستگی به کد منبع، Intel PT میتواند برای ردگیری دقیق و کارآمد اجرای برنامه استفاده شود. این ویژگی در فازینگ بر روی هستههای سیستم عامل در KAFL (شومیل و همکاران 2017) استفاده شده و ثابت شده است که به طور قابل توجهی کارآمد میباشد.
یک نگرانی دیگر در اجرای آزمون، کشف مسیرهای جدید است. فازرها نیاز دارند تا قضاوتهای شرطی پیچیدهای را در جریان کنترل برنامهها طی کنند.
تکنیکهای تحلیل برنامه، از جمله تحلیل استاتیک، تحلیل آلودگی و غیره، میتوانند برای شناسایی نقاط مسدودکننده در اجرای برنامه برای حل مسائل بعدی استفاده شوند. تکنیک اجرای نمادین (symbolic execution) در کشف مسیر مزیت طبیعی دارد. با حل مجموعه محدودیتها، تکنیک اجرای نمادین میتواند مقادیری را محاسبه کند که الزامات شرطی خاصی را برآورده کنند.
TaintScope (وانگ و همکاران 2010) از تکنیک اجرای نمادین برای حل اعتبارسنجی checksum که همیشه فرآیند فازینگ را مسدود میکند استفاده میکند. Driller (استیونز و همکاران 2016) از اجرای همنماد (concolic execution) برای دور زدن قضاوت شرطی و پیدا کردن اشکالات عمیقتر استفاده میکند.
فازینگ پس از سالها توسعه، بسیار دقیقتر، انعطاف پذیرتر و هوشمندتر از همیشه شده است. فازینگ مبتنی بر بازخورد یک راه کارآمد برای آزمون هدایت شده ارائه میدهد، تکنیکهای سنتی و جدید نقش حسگرهایی را ایفا میکنند تا در طول اجرای آزمون اطلاعات متنوعی به دست آورند و فازینگ را به طور دقیقی هدایت کنند.
فازینگ برای برنامههای مختلف
فازینگ از زمان ظهورش برای شناسایی آسیبپذیریها در برنامههای بزرگ مورد استفاده قرار گرفته است. با توجه به ویژگیهای مختلف برنامههای هدف، از فازرها و استراتژیهای مختلفی در عمل استفاده میشود. در این بخش، چند نوع برنامه اصلی که مورد فازینگ قرار گرفتهاند را ارائه و خلاصه میکنیم.
فازینگ فرمت فایل
بیشتر برنامهها شامل مدیریت فایل هستند و فازینگ به طور گستردهای در یافتن اشکالات این برنامهها استفاده میشود. تستهای فازینگ میتوانند با فایلهایی که فرمت استاندارد دارند یا ندارند، انجام شوند. رایجترین فایلهای مستندات، تصاویر و فایلهای رسانهای، فایلهایی با فرمت استاندارد هستند. بیشتر تحقیقات در زمینه فازینگ عمدتا بر روی فازینگ فرمت فایل تمرکز دارند و ابزارهای فازینگ بسیاری پیشنهاد شدهاند، مانندAFL ،Peach (PeachTech 2017) پیشرفته و گسترشهای آن (راوات و همکاران 2017؛ بوهمه و همکاران 2017). معرفی قبلی شامل تنوعی از فازرهای فرمت فایل بوده است، و ما دیگر ابزارها را در اینجا تأکید نخواهیم کرد.
یک زیرمجموعه مهم از فازینگ فرمت فایل، فازینگ بر روی مرورگرهای وب است. با پیشرفت مرورگرهای وب، این مرورگرها برای پشتیبانی از عملکردهای بیشتری نسبت به قبل گسترش یافتهاند. نوع فایلهایی که توسط مرورگرها مدیریت میشود از فایلهای سنتی CSS ،HTML و JS به انواع دیگر فایلها، مانند SVG ،PDF و سایر فرمتهای فایلی که توسط افزونههای مرورگر مدیریت میشوند، گسترش یافته است. به طور خاص، مرورگرها صفحات وب را به یک درخت DOM تجزیه میکنند که صفحه وب را به یک درخت شیء سندی تبدیل میکند که در آن با رویدادها و واکنشها در ارتباط است. به خصوص، تجزیه DOM و رندرینگ صفحه در مرورگرها در حال حاضر اهداف فازینگ محبوبی هستند. ابزارهای فازینگ معروف برای مرورگرهای وب شامل Freamwork Grinder (استیونفور 2016) ، COMRaider (زیمز 2013)، BF3 (آلدید 2013) و غیره میباشند.
فازینگ هسته
فازینگ بر روی هستههای سیستم عامل همیشه یک مشکل سخت است که شامل چالشهای زیادی میشود. اول، تفاوت با فازینگ در فضای کاربری، کرشها و قفل شدن در هسته، کل سیستم را به پایین میآورد و نحوه ثبت این کرشها یک مشکل باز است. دوم، مکانیزم مجوز سیستم منجر به یک محیط اجرای نسبتا بسته میشود، با در نظر گرفتن این که فازرها معمولا در حلقه اجرا میشوند و نحوه تعامل با هسته چالشی دیگر است. بهترین روش کنونی برای برقراری ارتباط با هسته، فراخوانی توابع API هسته است. علاوه بر این، هستههایی که بیشتر مورد استفاده قرار میگیرند مانند هسته ویندوز و هسته MacOS، کد منبع بسته هستند و سخت است که با بار اضافی کم ابزارآلات (instrumentation) شوند. با توسعه فازینگ هوشمند، پیشرفتهای جدیدی در فازینگ هسته حاصل شده است.
به طور کلی، هستههای سیستم عامل با فراخوانی تصادفی توابع API هسته با مقادیر پارامتر تصادفی فاز میشوند. بر اساس تمرکز فازرها، فازرهای هسته میتوانند به دو دسته تقسیم شوند: فازرهای مبتنی بر دانش و فازرهای مبتنی بر پوشش.
در فازرهای مبتنی بر دانش، دانش موجود در مورد توابع API هسته در فرآیند فازینگ به کار گرفته میشود. به طور خاص، فازینگ با فراخوانی توابع API هسته با دو چالش اصلی مواجه است: (1) پارامترهای فراخوانی API باید مقادیر تصادفی اما دارای فرمت صحیحی باشند که با مشخصات API مطابقت داشته باشند و (2) ترتیب فراخوانیهای توابع API هسته باید معتبر به نظر برسد (هان و چا 2017). کارهای نمایندگی شامل Trinity (جونز 2010) و IMF (هان و چا 2017 ) میشود. Trinity یک فازر هسته مبتنی بر نوع است. کیسهای تست در Trinity، بر اساس نوع پارامترها تولید میشوند. پارامترهای syscalls بر اساس نوع داده تغییر مییابند. به علاوه، مقادیر خاصی از انتسابها و دامنه مقادیر نیز ارائه میشود تا به تولید کیسهای تست با فرمت صحیح کمک کند. IMF سعی میکند ترتیب درست اجرای API و وابستگی مقادیر بین فراخوانیهای API را بیاموزد و از دانش آموخته شده در تولید کیسهای تست استفاده کند.
فازینگ مبتنی بر پوشش در یافتن اشکالات برنامههای کاربر به موفقیت زیادی دست یافته است. و مردم شروع به اعمال روش فازینگ مبتنی بر پوشش در یافتن آسیب پذیریهای هسته کردهاند. کارهای نمایندگی شامل syzkaller
(ویوکوف 2015)، TriforceAFL (هرتز 2015) و kAFL (Schumilo و همکاران 2017) میشود. Syzkaller هسته را از طریق کامپایل ابزارآلات کرده و آن را بر روی مجموعهای از ماشینهای مجازی QEMU اجرا میکند. در طی فرآیند فازینگ، پوشش و نقضهای امنیتی ردیابی میشوند. TriforceAFL نسخهای اصلاح شده از AFL است که از فازینگ هسته با شبیه سازی کامل سیستم QEMU پشتیبانی میکند.
KAFL از ویژگی جدید سخت افزاری،Intel PT، برای ردیابی پوشش و فقط ردیابی کد هسته استفاده میکند. آزمایش نشان میدهد که KAFL حدود 40 برابر سریعتر از Triforce است و به طور قابل توجهی کارایی را بهبود میبخشد.
فازینگ پروتکلها
در حال حاضر، بسیاری از برنامههای محلی به سرویسهای شبکهای در یک حالت B/S تبدیل شدهاند. خدمات بر روی شبکه پیاده سازی شدهاند و برنامههای کلاینت از طریق پروتکلهای شبکه با سرورها ارتباط برقرار میکنند. آزمایشهای امنیتی بر روی پروتکلهای شبکه، تبدیل به یک نگرانی مهم دیگر شده است. مشکلات امنیتی در پروتکلها میتواند آسیبهای جدیتری نسبت به برنامههای محلی به بار آورد، مانند حمله انکار سرویس، نشت اطلاعات و غیره. فازینگ مشترک با پروتکلها در مقایسه با فازینگ فرمت فایل چالشهای متفاوتی را در بر دارد. اول، خدمات ممکن است پروتکلهای ارتباطی مخصوص به خود را تعریف کنند که تعیین استانداردهای پروتکل را دشوار میسازد. علاوه بر این، حتی برای پروتکلهای مستند با تعریف استاندارد نیز، پیروی از مشخصاتی مانند اسناد RFC هنوز بسیار دشوار است.
فازرهای پروتکل نماینده شامل SPIKE هستند که مجموعهای از ابزارها را فراهم میکند که به کاربران این امکان را میدهد که به سرعت تسترهای فشار پروتکل شبکه را ایجاد کنند. سرژ گوربونو و آرنولد روزنبلوم AutoFuzz (گوربونو و روزنبلوم 2010) را پیشنهاد کردند که با ساخت یک خودکار متناهی (Finite State Automaton) پیاده سازی پروتکل را یاد میگیرد و سپس از دانش آموخته شده برای تولید کیسهای تست استفاده میکند. گرگ بنکس و همکارانش SNOOZE (بنکس و همکاران 2006) را پیشنهاد کردند که با رویکرد فازینگ حالت دار نواقص پروتکل را شناسایی میکند. کار یوری د روتیر (د روتیر و پول 2015) یک روش فازینگ حالت پروتکل پیشنهاد میدهد که وضعیت کار TLS را در یک ماشین حالت توصیف میکند و فرآیند فازینگ را طبق جریان منطقی انجام میدهد. کارهای قبلی به طور کلی از یک روش حالت دار برای مدلسازی فرآیند کار پروتکل استفاده کرده و کیسهای تست را طبق مشخصات پروتکل تولید میکنند.
روندهای جدید فازینگ
به عنوان یک روش خودکار برای شناسایی آسیب پذیریها، فازینگ اثربخشی و کارایی بالای خود را نشان داده است. با این حال، همانطور که در بخشهای قبلی اشاره شد، هنوز چالشهای زیادی وجود دارد که باید حل شوند. در این بخش، یک معرفی مختصر از درک خودمان برای مرجع ارائه میدهیم.
اول، فازینگ هوشمند امکانات بیشتری را برای بهبود فازینگ فراهم میکند. در کارهای قبلی، تحلیلهای استاتیک و دینامیک سنتی در فازینگ ادغام شدهاند تا به بهبود این فرآیند کمک کنند. در حالی که بهبودی در این زمینه حاصل شده، اما محدود است. با جمع آوری اطلاعات از برنامه هدف، اطلاعات اجرایی را از طریق روشهای مختلف جمع آوری کرده و فازینگ هوشمند کنترل بیشتری بر روی فرآیند فازینگ ارائه میدهد و استراتژیهای فازینگ زیادی پیشنهاد شده است. با درک عمیقتری از انواع مختلف آسیب پذیریها و استفاده از ویژگیهای آسیب پذیریها در فازینگ، فازینگ هوشمند میتواند به کشف آسیب پذیریهای پیچیدهتر کمک کند.
دوم، تکنیکهای جدید میتوانند به بهبود آسیب پذیری به طرق مختلف کمک کنند. تکنیکهای جدید، مانند یادگیری ماشین و تکنیکهای مربوطه، برای بهبود تولید کیسهای تست در فازینگ استفاده شدهاند. نحوه ترکیب مزایا و ویژگیهای تکنیکهای جدید با فازینگ و چگونگی تبدیل یا تقسیم چالشهای کلیدی در فازینگ به مسائلی که تکنیکهای جدید در آنها مهارت دارند، سوال دیگری است که شایسته بررسی است.
سوم، ویژگیهای جدید سیستم و ویژگیهای سخت افزاری نیز نباید نادیده گرفته شوند. کارهای ویوکوف (2015) و شومیلوا (2017) نشان دادهاند که ویژگیهای جدید سخت افزاری به طرز چشمگیری کارایی فازینگ را بهبود میبخشند و الهام خوبی به ما میدهند.
نتیجه گیری
فازینگ در حال حاضر مؤثرترین و کارآمدترین راه حل برای کشف آسیب پذیریها است. در این مقاله، یک مرور جامع و خلاصهای از فازینگ و پیشرفتهای اخیر آن ارائه دادهایم. اول، فازینگ را با سایر راه حلهای کشف آسیب پذیری مقایسه کردیم و سپس مفاهیم و چالشهای کلیدی فازینگ را معرفی کردیم. به طور ویژه فازینگ مبتنی بر پوشش را که در سالهای اخیر پیشرفتهای زیادی داشته است معرفی کردیم. در نهایت، تکنیکهای ادغام شده با فازینگ، کاربردها و روندهای ممکن جدید فازینگ را خلاصه کردیم.
منابع
Aldeid (2013) Browser fuzzer 3. https://www.aldeid.com/wiki/Bf3. Accessed 25 Dec 2017
Amini P (2017) Sulley fuzzing framework. https://github.com/OpenRCE/sulley. Accessed 25 Dec 2017
Banks G, Cova M, Felmetsger V, Almeroth K, Kemmerer R, Vigna G (2006)
Snooze: toward a stateful network protocol fuzzer. In: International
Conference on Information Security. Springer, Berlin. pp 343–358
Böhme M, Pham V-T, Nguyen M-D, Roychoudhury A (2017) Directed greybox fuzzing. In: Proceeding CCS ’17 Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, New York. pp 2329–2344. https://doi.org/10.1145/3133956.3134020
Böhme M, Pham VT, Roychoudhury A (2017) Coverage-based greybox fuzzing as markov chain. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM. pp 1032–1043
Bowne S (2015) Fuzzing with spike. https://samsclass.info/127/proj/p18-spike. htm. Accessed 25 Dec 2017
Cha SK, Avgerinos T, Rebert A, Brumley D (2012) Unleashing mayhem on
binary code. In: Security and Privacy (SP) 2012 IEEE Symposium on. IEEE,
San Francisco. pp 380–394. https://doi.org/10.1109/SP.2012.31
De Ruiter J, Poll E (2015) Protocol state fuzzing of tls implementations. In:
Proceeding SEC’15 Proceedings of the 24th USENIX Conference on
Security Symposium. USENIX Association, Berkeley. pp 193–206 Godefroid P, Levin MY, Molnar D (2012) Sage: whitebox fuzzing for security testing. Queue 10(1):20
Godefroid P, Peleg H, Singh R (2017) Learn & fuzz: Machine learning for input fuzzing. In: Proceeding ASE 2017 Proceedings of the 32nd IEEE/ACM
International Conference on Automated Software Engineering. IEEE Press, Piscataway. pp 50–59
Gorbunov S, Rosenbloom A (2010) Autofuzz: Automated network protocol fuzzing framework. IJCSNS 10(8):239
Han H, Cha SK (2017) Imf: Inferred model-based fuzzer. In: Proceeding CCS ’17
Proceedings of the 2017 ACM SIGSAC Conference on Computer and
Communications Security. ACM, New York. pp 2345–2358. https://doi.org/3133956.3134103/10.1145
Hertz J (2015) Triforceafl . https://github.com/nccgroup/TriforceAFL. Accessed 25Dec 2017
James R (2013) Processor tracing. https://software.intel.com/en-us/blogs/ /18/09/2013processor-tracing. Accessed 25 Dec 2017
Jones D (2010) trinity. https://github.com/kernelslacker/trinity. Accessed 25 Dec 2017
King JC (1976) Symbolic execution and program testing. Commun ACM
394–385:)7(19 lcamtuf (2014) Fuzzing random programs without execve(). https://lcamtuf. blogspot.jp/2014/10/fuzzing-binaries-without-execve.html. Accessed 25 Dec 2017 libfuzzer (2017) A library for coverage-guided fuzz testing. https://llvm.org/ docs/LibFuzzer.html. Accessed 25 Dec 2017
Liu B, Shi L, Cai Z, Li M (2012) Software vulnerability discovery techniques: A survey. In: Multimedia Information Networking and Security (MINES), 2012
Fourth International Conference on. IEEE, Nanjing. pp 152–156. https://doi. org/10.1109/MINES.2012.202
Luk C-K, Cohn R, Muth R, Patil H, Klauser A, Lowney G, Wallace S, Reddi VJ, Hazelwood K (2005) Pin: building customized program analysis tools with dynamic instrumentation. In: Acm sigplan notices, volume 40. ACM, Chicago. pp 190–200
Nichols N, Raugas M, Jasper R, Hilliard N (2017) Faster fuzzing: Reinitialization with deep neural models. arXiv preprint arXiv:1711.02807
PeachTech (2017) Peach. https://www.peach.tech/. Accessed 25 Dec 2017 Petsios T, Zhao J, Keromytis AD, Jana S (2017) Slowfuzz: Automated domain-independent detection of algorithmic complexity vulnerabilities.
In: Proceeding CCS ’17 Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, New York. pp 2155–2168. https://doi.org/10.1145/3133956.3134073
Rajpal M, Blum W, Singh R (2017) Not all bytes are equal: Neural byte sieve for fuzzing. arXiv preprint arXiv:1711.04596
Rawat S, Jain V, Kumar A, Cojocar L, Giuffrida C, Bos H (2017) Vuzzer: Application-aware evolutionary fuzzing. In: Proceedings of the Network and Distributed System Security Symposium (NDSS). https://www.vusec.net/download/?t=papers/vuzzer_ndss17.pdf
Schumilo S, Aschermann C, Gawlik R, Schinzel S, Holz T (2017) kAFL:
Hardware-assisted feedback fuzzing for OS kernels. In: Kirda E, Ristenpart T
(eds). 26th USENIX Security Symposium, USENIX Security 2017. USENIX
Association, Vancouver. pp 167–182
Serebryany K, Bruening D, Potapenko A, Vyukov D (2012) Addresssanitizer: A fast address sanity checker. In: Proceeding USENIX ATC’12 Proceedings of the 2012 USENIX conference on Annual Technical Conference. USENIX
Association, Berkeley. pp 309–318
Serebryany K, Iskhodzhanov T (2009) Threadsanitizer: data race detection in practice. In: Proceedings of the Workshop on Binary Instrumentation and
Applications. pp 62–71
Shirey RW (2000) Internet security glossary. https://tools.ietf.org/html/rfc2828. Accessed 25 Dec 2017
Stephenfewer (2016) Grinder. https://github.com/stephenfewer/grinder. Accessed 25 Dec 2017
Stephens N, Grosen J, Salls C, Dutcher A, Wang R, Corbetta J, Shoshitaishvili Y,
Kruegel C, Vigna G (2016) Driller: Augmenting fuzzing through selective symbolic execution. In: NDSS, volume 16, San Diego. pp 1–16 Sutton M, Greene A, Amini P (2007) Fuzzing: brute force vulnerability discovery. Pearson Education, Upper Saddle River
Takanen A, Demott JD, Miller C (2008) Fuzzing for software security testing and quality assurance. Artech House
The Clang Team (2017) Dataflowsanitizer. https://clang.llvm.org/docs/
DataFlowSanitizerDesign.html. Accessed 25 Dec 2017
The Clang Team (2017) Leaksanitizer. https://clang.llvm.org/docs/
LeakSanitizer.html. Accessed 25 Dec 2017
Van Sprundel I (2005) Fuzzing: Breaking software in an automated fashion. Decmember 8th
Vyukov D (2015) Syzkaller. https://github.com/google/syzkaller. Accessed 25 Dec 2017
Wang J, Chen B, Wei L, Liu Y (2017) Skyfire: Data-driven seed generation for fuzzing. In: Security and Privacy (SP), 2017 IEEE Symposium on. IEEE, San Jose. https://doi.org/10.1109/SP.2017.23
Wang S, Nam J, Tan L (2017) Qtep: quality-aware test case rioritization. In:
Proceedings of the 2017 11th Joint Meeting on Foundations of oftware
Engineering. ACM, New York. pp 523–534. https://doi.org/10.1145/3106237.3106258
Wang T, Wei T, Gu G, Zou W (2010) Taintscope: A checksum-aware directed fuzzing tool for automatic software vulnerability detection. In: Security and privacy (SP) 2010 IEEE symposium on. IEEE, Berkeley. pp 497–512. https:// doi.org/10.1109/SP.2010.37
Wichmann BA, Canning AA, Clutterbuck DL, Winsborrow LA, Ward NJ, Marsh
DWR (1995) Industrial perspective on static analysis. Softw Eng J 10(2):69–75
Wikipedia, Wannacry ransomware attack (2017). https://en.wikipedia.org/wiki/
WannaCry_ransomware_attack. Accessed 25 Dec 2017
Wikipedia (2017) Dynamic program analysis. https://en.wikipedia.org/wiki/
Dynamic_program_analysis. Accessed 25 Dec 2017
Wu Z-Y, Wang H-C, Sun L-C, Pan Z-L, Liu J-J (2010) Survey of fuzzing. Appl Res Comput 27(3):829–832
Xu W, Kashyap S, Min C, Kim T (2017) Designing new operating primitives to improve fuzzing performance. In: Proceeding CCS ’17 Proceedings of the
2017 ACM SIGSAC Conference on Computer and Communications
Security. ACM, New York. pp 2313–2328. https://doi.org/10.1145/3133956.3134046
Yang Q, Li JJ, Weiss DM (2007) A survey of coverage-based testing tools. The Computer Journal 52(5):589–597
Zalewski, M (2017) American fuzzy lop. http://lcamtuf.coredump.cx/afl/. Accessed 25 Dec 2017
Zalewski M (2017) Afl technical details. http://lcamtuf.coredump.cx/afl/ technical_details.txt. Accessed 25 Dec 2017
Zimmer D (2013) Comraider. http://sandsprite.com/tools.php?id=16. Accessed 25 Dec 2017