")
فازینگ (Fuzzing) یک تکنیک تست نرمافزار است که بدون نیاز به آگاهی از ساختار داخلی برنامه، فضای ورودیهای آن را بهصورت سریع و خودکار کاوش میکند. بنابراین، توسعهدهندگان معمولاً از فازینگ به عنوان بخشی از فرایند یکپارچهسازی آزمون در طول چرخهٔ توسعهٔ نرمافزار استفاده میکنند. با این حال، همین ماهیت جعبه سیاه (black-box) و خودکار بودن فازینگ باعث میشود این روش برای مهاجمانی که به دنبال کشف آسیبپذیریهای روز-صفر (zero-day) هستند نیز جذاب باشد.
برای حل این مشکل، ما یک رویکرد کاهندهٔ جدید به نام فازیسازی (FUZZIFICATION) را پیشنهاد میکنیم که به توسعهدهندگان کمک میکند نرمافزارهای منتشرشده بهصورت باینریمحور (binary-only) را در برابر مهاجمانی که قادر به استفاده از پیشرفتهترین تکنیکهای فازینگ هستند محافظت کنند. این رویکرد با در نظر گرفتن یک محدودیت کارایی (performance budget) طراحی شده و هدف آن این است که فرایند فازینگ مهاجمان تا حد امکان دشوار و کُند شود. ما سه تکنیک فازیسازی (FUZZIFICATION) را ارائه میدهیم:
- SpeedBump – با بزرگنمایی زمان اجرای برنامه، باعث میشود اجرای مورد استفاده در فازینگ نسبت به اجرای عادی تا صدها برابر کُندتر شود.
- BranchTrap – با پنهانسازی مسیرها و آلودهسازی نقشههای پوشش (coverage maps)، در منطق بازخورد فازر اختلال ایجاد میکند.
- AntiHybrid – با ایجاد مانع در تحلیل آلودگی داده (taint analysis) و اجرای نمادین (symbolic execution)، کارایی روشهای هیبریدی تحلیل برنامه را کاهش میدهد.
هر یک از این تکنیکها با رویکردی دفاعی و مبتنی بر بهترین تلاش (best-effort) طراحی شدهاند تا عبور مهاجمان از مکانیزمهای FUZZIFICATION تا حد امکان دشوار شود.
ارزیابی ما بر روی فازرهای محبوب و برنامههای کاربردی واقعی نشان میدهد که فازیسازی (FUZZIFICATION) بهطور مؤثری تعداد مسیرهای کشف شده را تا ۷۰.۳٪ کاهش میدهد و تعداد خرابیهای (crash) شناساییشده در باینریهای واقعی را ۹۳.۰٪ کم میکند. همچنین، در مجموعهدادهٔ LAVA-M تعداد باگهای شناسایی شده را ۶۷.۵٪ کاهش میدهد، آن هم در حالی که سربار اجرایی در محدودهٔ تعیینشده توسط کاربر برای بارهای کاری رایج حفظ میشود.
ما همچنین میزان مقاومت (robustness) تکنیکهای FUZZIFICATION را در برابر روشهای تحلیل مهاجمان بررسی میکنیم. در نهایت، سیستم FUZZIFICATION را بهصورت متنباز (open source) منتشر کردهایم تا زمینهای برای پژوهشهای آینده فراهم شود.
1. مقدمه
فازینگ (Fuzzing) یک تکنیک آزمون نرمافزار است که هدف آن کشف خودکار باگهای نرمافزاری است. در این روش، برنامه بهطور مداوم با ورودیهای تصادفی اجرا میشود و رفتارهایی که نشاندهندهٔ وجود باگ هستند مانند کرش (crash) یا قفل شدن برنامه (hang) بررسی میشوند.
امروزه فازینگ به یک روش استاندارد برای شناسایی مشکلات امنیتی در نرمافزارهای پیچیده و مدرن تبدیل شده است [40، 72، 37، 25، 23، 18، 9]. پژوهشهای اخیر نیز ابزارهای فازینگ کارآمد متعددی توسعه دادهاند [57، 52، 29، 34، 6، 64] و موفق به کشف تعداد زیادی آسیب پذیری امنیتی شدهاند [51, 72, 59 , 26 , 10].
متأسفانه، تکنیکهای پیشرفتهٔ فازینگ میتوانند توسط مهاجمان مخرب نیز برای کشف آسیبپذیریهای روز-صفر (zero-day) مورد استفاده قرار گیرند. مطالعات اخیر [61، 58] نشان میدهند که مهاجمان در یافتن آسیبپذیریها عمدتاً ابزارهای فازینگ را نسبت به روشهای دیگر (مانند مهندسی معکوس) ترجیح میدهند. برای مثال، یک نظرسنجی از متخصصان امنیت اطلاعات [28] نشان میدهد که تکنیکهای فازینگ 4.83 برابر بیشتر از تحلیل ایستا یا بررسی دستی، باگ کشف میکنند.
بنابراین، توسعهدهندگان ممکن است بخواهند برای محصولات خود از تکنیکهای ضد فازینگ (anti-fuzzing) استفاده کنند تا تلاشهای فازینگ مهاجمان را مختل کنند؛ مفهومی مشابه استفاده از مبهمسازی (obfuscation) برای تضعیف فرایند مهندسی معکوس [12، 13].
در این مقاله، ما یک جهت جدید از محافظت باینری به نام فازیسازی (FUZZIFICATION) را پیشنهاد میکنیم که مانع از یافتن مؤثر اشکالات توسط مهاجمان میشود. به طور خاص، مهاجمان ممکن است هنوز بتوانند اشکالات را از باینری محافظت شده توسط فازیسازی پیدا کنند. بنابراین، توسعهدهندگان یا سایر طرفهای مورد اعتماد که به باینری اصلی دسترسی دارند، میتوانند پیش از آنکه مهاجمان بهطور گسترده از آسیبپذیریها سوءاستفاده کنند، باگهای برنامه را شناسایی کرده و وصلههای اصلاحی (patches) تولید کنند. یک تکنیک فازیسازی مؤثر باید سه ویژگی زیر را فعال کند. اول، باید برای جلوگیری از ابزارهای فازینگ موجود مؤثر باشد و اشکالات کمتری را در یک زمان ثابت پیدا کند. دوم، برنامه محافظت شده باید همچنان در استفاده عادی به طور مؤثر اجرا شود. سوم، کد حفاظتی نباید به راحتی توسط تکنیکهای تحلیل ساده از فایل باینری محافظت شده شناسایی یا حذف شود.
هیچیک از تکنیکهای موجود نمیتوانند هر سه هدف ذکرشده را بهطور همزمان برآورده کنند. نخست، تکنیکهای مبهمسازی نرمافزار (software obfuscation) که با تصادفیسازی نمایش باینری مانع تحلیل ایستای برنامه میشوند، در نگاه اول برای مقابله با فازینگ مؤثر به نظر میرسند [12، 13]. با این حال، مشاهده میکنیم که این روشها از دو جهت با الزامات FUZZIFICATION فاصله دارند.
اول اینکه مبهمسازی سربار اجرایی غیرقابلقبولی در اجرای عادی برنامه ایجاد میکند. همانطور که در شکل 1 (a) نشان داده شده است، مبهمسازی هنگام استفاده از UPX [60] حداقل باعث کندی 1.7 برابری اجرا میشود و هنگام استفاده از LLVM-obfuscator [33] این کاهش کارایی میتواند تا ۲۵ برابر برسد.
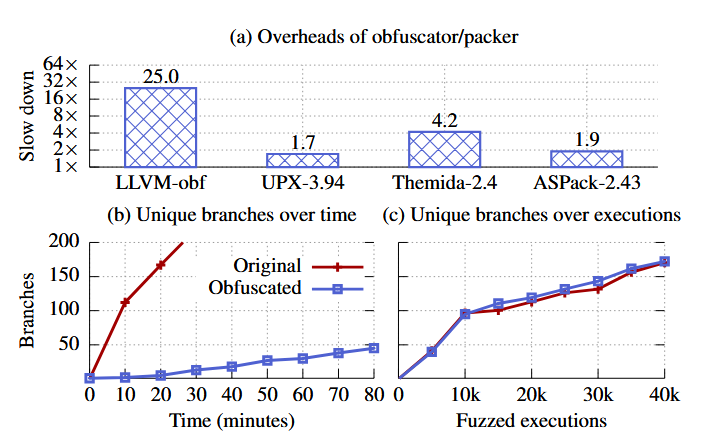
دوم اینکه مبهمسازی نمیتواند بهطور مؤثر فرایند اکتشاف مسیرها (path exploration) توسط فازر را مختل کند. اگرچه این روش میتواند هر اجرای فازینگ را کندتر کند (شکل 1 (b))، اما تعداد مسیرهای کشفشده در هر اجرا تقریباً مشابه فازینگ روی باینری اصلی باقی میماند (شکل 1 (c)). بنابراین، مبهمسازی گزینهٔ ایدهآلی برای FUZZIFICATION محسوب نمیشود.
دومین رویکرد، تنوعبخشی نرمافزار (software diversification) است که ساختار و رابطهای برنامه هدف را تغییر میدهد تا نسخههای متنوعی از آن توزیع شود [35، 3، 53، 50]. برای مثال، تکنیک N-version software [3] میتواند بهرهبرداری از آسیبپذیریها را کاهش دهد، زیرا مهاجمان معمولاً به شناخت دقیق وضعیتهای برنامه وابسته هستند. با این حال، تنوعبخشی نرمافزار قادر به پنهانسازی آسیبپذیری اصلی از تحلیل مهاجم نیست؛ بنابراین، این روش نیز رویکرد مناسبی برای FUZZIFICATION به شمار نمیآید.
در این مقاله، ما سه تکنیک فازیسازی را پیشنهاد میکنیم تا توسعهدهندگان بتوانند برنامههای خود را در برابر تلاشهای فازینگ مخرب محافظت کنند: SpeedBump، BranchTrap و AntiHybrid.
- SpeedBump با هدف کند کردن اجرای برنامه در هنگام فازینگ طراحی شده است. این روش با تزریق تأخیر در مسیرهای سرد یا کم اجرا شده (cold paths) – مسیرهایی که در اجرای عادی بهندرت طی میشوند اما در اجرای فازینگ زیاد پیمایش میشوند – زمان اجرای فازینگ را افزایش میدهد.
- BranchTrap تعداد زیادی پرش (jump) وابسته به ورودی را به برنامه اضافه میکند، بهطوریکه هر تغییر کوچک در ورودی باعث تغییر قابلتوجه مسیر اجرا شود. این کار باعث میشود فازرهای مبتنی بر پوشش (coverage-based fuzzers) منابع خود را صرف مسیرهای تزریقشده و بدون باگ کنند، نه مسیرهای واقعی برنامه.
- AntiHybrid با هدف مقابله با روشهای فازینگ هیبریدی طراحی شده است؛ روشهایی که فازینگ سنتی را با تحلیل آلودگی پویا (dynamic taint analysis) و اجرای نمادین (symbolic execution) ترکیب میکنند. این تکنیک تلاش میکند کارایی چنین تحلیلهایی را مختل کند.
ما مکانیزمهای دفاعی را برای جلوگیری از شناسایی یا حذف تکنیکها از فایلهای باینری محافظت شده توسط مهاجمان توسعه میدهیم. برای SpeedBump، به جای فراخوانی تابع sleep، عملیات فشرده CPU را به صورت تصادفی به مسیرهای سرد (cold paths) تزریق میکنیم و وابستگیهای جریان کنترل و جریان داده را بین کد تزریق شده و کد اصلی ایجاد میکنیم. ما از کد باینری موجود برای تحقق BranchTrap استفاده مجدد میکنیم تا از شناسایی شاخههای تزریق شده توسط مهاجم جلوگیری شود.
برای ارزیابی تکنیکهای فازیسازی، آنها را روی مجموعه داده LAVA-M و تعداد نُه برنامه کاربردی دنیای واقعی، از جمله libjpeg، libpng، libtiff، pcre2، readelf، objdump، nm، objcopy و MuPDF اعمال میکنیم. این برنامهها به طور گسترده برای ارزیابی اثربخشی ابزارهای فازیسازی استفاده میشوند [19، 11، 49، 68]. سپس، از چهار فازر محبوب – AFL، HonggFuzz، VUzzer و QSym – برای فازیسازی برنامههای اصلی و برنامههای محافظت شده برای مدت زمان یکسان استفاده میکنیم. به طور متوسط، فازر 14.2 برابر اشکالات بیشتری از فایلهای باینری اصلی و 3.0 برابر اشکالات بیشتری از مجموعه داده LAVAM نسبت به نمونههای «فازیسازی شده» تشخیص میدهند. در عین حال، تکنیکهای فازیسازی ما تعداد کل مسیرهای کشف شده را 70.3٪ کاهش میدهند و بودجه سربار مشخص شده توسط کاربر را حفظ میکنند. این نتیجه نشان میدهد که تکنیکهای فازیسازی ما با موفقیت عملکرد فازیسازی در کشف آسیبپذیری را کاهش میدهند. ما همچنین تحلیلی انجام میدهیم تا نشان دهیم که تکنیکهای تحلیل جریان داده و جریان کنترل نمیتوانند به راحتی تکنیکهای ما را خنثی کنند. در این مقاله، ما دستاوردهای زیر را ارائه میدهیم:
- ابتدا مسیر پژوهشی جدیدی را در زمینهٔ طرحهای ضد فازینگ (anti-fuzzing schemes) معرفی میکنیم که به آن فازیسازی (FUZZIFICATION) گفته میشود.
- ما سه تکنیک فازیسازی را برای کند کردن هر اجرای فاز شده، پنهان کردن پوشش مسیر و خنثی کردن تحلیل آلودگی پویا (dynamic taint-analysis) و اجرای نمادین (symbolic execution) توسعه میدهیم.
- ما تکنیکهای خود را بر روی فازرهای محبوب و معیارهای رایج ارزیابی میکنیم. نتایج ما نشان میدهد که تکنیکهای پیشنهادی مانع این فازرها میشوند و ۹۳٪ اشکالات کمتری از فایلهای باینری دنیای واقعی و ۶۷.۵٪ اشکالات کمتری از مجموعه داده LAVA-M و ۷۰.۳٪ پوشش کمتری را در عین حفظ بودجه سربار مشخص شده توسط کاربر پیدا میکنند. ما کد منبع این پروژه را در آدرس https://github.com/sslab-gatech/fuzzification منتشر خواهیم کرد.
2. پیشینه و مشکل
2.1 تکنیکهای فازینگ
هدف فازینگ، تشخیص خودکار اشکالات برنامه است. برای یک برنامه مشخص، یک فازینگ ابتدا تعداد زیادی ورودی، یا از طریق جهش تصادفی یا از طریق تولید مبتنی بر قالب، ایجاد میکند. سپس، برنامه را با این ورودیها اجرا میکند تا ببیند آیا اجرا، رفتارهای غیرمنتظرهای مانند خرابی یا نتیجه نادرست را نشان میدهد یا خیر. در مقایسه با تجزیه و تحلیل دستی یا تجزیه و تحلیل استاتیک، فازینگ قادر است برنامه را با مرتبه بزرگی بیشتری اجرا کند و بنابراین میتواند حالتهای بیشتری از برنامه را بررسی کند تا احتمال یافتن اشکالات را به حداکثر برساند.
2.1.1 فازینگ با اجرای سریع
یک راه ساده برای بهبود کارایی فازینگ، سریعتر کردن هر اجرا است. تحقیقات فعلی چندین تکنیک اجرای سریع را برجسته میکند، از جمله (1) سیستم و سختافزار سفارشی برای تسریع اجرای فازینگ و (2) فازینگ موازی برای کاهش زمان اجرای مطلق در مقیاس بزرگ کاربران عادی شناسایی شده. در میان این تکنیکها، AFL از سرور fork و حالت persistent برای جلوگیری از ایجاد فرآیند سنگین استفاده میکند و میتواند فازینگ را با ضریب دو یا بیشتر تسریع کند [69]، 70 AFL-PT، kAFL و HonggFuzz از ویژگیهای سختافزاری مانند Intel Process Tracing (PT) و Br استفاده میکنند. از یک مخزن ردیابی (BTS) برای جمعآوری پوشش کد به طور موثر جهت هدایت فازینگ استفاده میکند [66، 55، 23]. اخیراً، ژو و همکارانش اجزای اولیه سیستم عامل جدید، مانند فراخوانیهای سیستم کارآمد، را برای سرعت بخشیدن به فازینگ در ماشینهای چند هستهای طراحی کردهاند [65].
2.1.2 فازینگ با هدایت مبتنی بر پوشش (Fuzzing with Coverage-guidance)
فازینگ هدایت شده توسط پوشش (Coverage-guided fuzzing)، پوشش کد (code coverage) برای هر اجرای فاز شده را جمعآوری میکند و ورودیهایی را که پوشش جدیدی ایجاد کردهاند در اولویت فازینگ قرار میدهد.
این استراتژی فازینگ بر دو مشاهدهٔ تجربی بنا شده است:
- پوشش مسیر بالاتر نشاندهندهٔ احتمال بیشتر کشف باگها است.
- جهش ورودیهایی که قبلاً مسیر جدیدی فعال کردهاند احتمالاً مسیر جدید دیگری را نیز فعال میکند.
اکثر فازرهای محبوب مانند AFL، Honggfuzz و LibFuzzer از پوشش کد بهعنوان راهنما استفاده میکنند، اگرچه روشهای متفاوتی برای نمایش پوشش و جمعآوری اطلاعات پوشش بهکار میبرند.
نمایش پوشش (Coverage representation). اکثر فازرها از بلوکها یا شاخههای اساسی برای نمایش پوشش کد استفاده میکنند. برای مثال، HonggFuzzer و VUzzerusebasicblock coverage را در نظر میگیرند، در حالی که AFL در عوض پوشش شاخهای را در نظر میگیرد که اطلاعات بیشتری در مورد حالتهای برنامه ارائه میدهد. ابزار Angora [11] پوشش شاخهای (branch coverage) را با پشتهٔ فراخوانی (call stack) ترکیب میکند تا دقت پوشش مسیر را بهبود دهد. با این حال، انتخاب نحوهٔ نمایش پوشش، یک توازن بین دقت پوشش و کارایی است؛ زیرا پوششهای دقیقتر باعث سربار بالاتر در هر اجرا میشوند و کارایی فازینگ را کاهش میدهند.
جمعآوری پوشش (Coverage collection). چنانچه کد منبع در دسترس باشد، فازرها میتوانند برنامه هدف را در طول کامپایل یا مونتاژ، ابزارگذاری (instrument) کنند تا پوشش را در زمان اجرا ثبت نمایند، مانند حالت AFL-LLVM و LibFuzzer. در غیر این صورت، فازرها باید از ابزاربندی دودویی ایستا یا پویا برای دستیابی به هدف مشابه، مانند حالت AFL-QEMUmode[71]، استفاده کنند. همچنین، چندین فازر از ویژگیهای سختافزاری برای جمعآوری پوشش استفاده میکنند [66، 55، 23]. فازرها معمولاً ساختار داده خود را برای ذخیره اطلاعات پوشش حفظ میکنند. برای مثال،AFL و HonggFuzz از یک آرایه با اندازه ثابت استفاده میکنند و VUzzer از یک ساختار داده Set در پایتون برای ذخیره پوشش خود استفاده میکند. با این حال، اندازه ساختار نیز یک توازن میان دقت و عملکرد است. یک حافظه بیش از حد کوچک نمیتواند هر تغییر پوشش را ثبت کند، در حالی که یک حافظه بیش از حد بزرگ سربار قابل توجهی ایجاد میکند. به عنوان مثال، اگر اندازه bitmap از 64 کیلوبایت به 1 مگابایت تغییر کند، عملکرد AFL 30٪ کاهش مییابد [19].
2.1.3 فازینگ با رویکردهای هیبریدی
رویکردهای هیبریدی (Hybrid Approaches) برای کمک به حل محدودیتهای فازرهای موجود پیشنهاد شدهاند. نخست، فازرها معمولاً بین نوعهای مختلف بایتهای ورودی تفاوتی قائل نمیشوند (مانند magic number یا length specifier) و در نتیجه ممکن است زمان خود را صرف جهش بایتهای کماهمیت کنند که تأثیری بر جریان کنترل برنامه ندارند. در این موارد، تحلیل آلودگی داده (taint analysis) به شناسایی بایتهایی کمک میکند که برای تعیین شرایط شاخهها استفاده میشوند، مانند VUzzer [52]. با تمرکز روی جهش این بایتها، فازرها میتوانند سریعتر مسیرهای اجرای جدید را پیدا کنند.
دوم، فازرها نمیتوانند بهراحتی شرایط پیچیده، مانند مقایسه با مقدار جادویی (magic value) یا checksum را حل کنند. برخی پژوهشها [57، 67] از اجرای نمادین (symbolic execution) برای رفع این مشکل استفاده میکنند؛ این روش در حل محدودیتهای پیچیده قوی است اما سربار بالایی ایجاد میکند.
2.2 مسئله فازیسازی
توسعهدهندگان برنامه ممکن است بخواهند فرآیند کشف باگها را بهطور کامل کنترل کنند، زیرا هرگونه افشای باگ میتواند منجر به حملات و زیان مالی شود [45]. آنها ترجیح میدهند باگها توسط خودشان یا طرفهای مورد اعتماد شناسایی شوند، نه توسط کاربران مخرب نهایی.
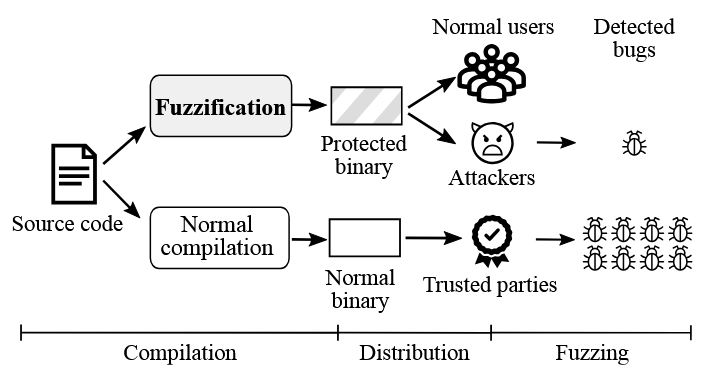
تکنیکهای ضد فازینگ (Anti-fuzzing) میتوانند در این زمینه کمک کنند، بهویژه با کُند کردن تلاشهای فازینگ غیرمنتظره که ممکن است توسط مهاجمان مخرب انجام شود. در شکل ۲، جریان کاری FUZZIFICATION نشان داده شده است. توسعهدهندگان کد خود را در دو نسخه کامپایل میکنند:
- نسخهای که با تکنیکهای FUZZIFICATION کامپایل شده و باینری محافظتشده ایجاد میکند.
- نسخهٔ عادی که به صورت معمولی کامپایل شده و باینری عادی تولید میکند.
سپس توسعهدهندگان باینری محافظت شده را برای عموم، شامل کاربران عادی و مهاجمان مخرب، توزیع میکنند. مهاجمان سعی میکنند با فازینگ روی باینری محافظتشده باگها را پیدا کنند، اما به کمک تکنیکهای FUZZIFICATION، آنها نمیتوانند به سرعت تعداد زیادی باگ کشف کنند.
در همان زمان، توسعهدهندگان باینری عادی را به طرفهای مورد اعتماد توزیع میکنند. این افراد میتوانند با سرعت طبیعی فازینگ، باگهای بیشتری را در زمان مناسب پیدا کنند. بنابراین، توسعهدهندگان با دریافت گزارش باگ از طرفهای مورد اعتماد، قادر خواهند بود پیش از سوءاستفاده گسترده مهاجمان، باگها را رفع کنند.
۲.۲.۱ مدل تهدید
ما مهاجمانی را در نظر میگیریم که با انگیزه تلاش میکنند از طریق پیشرفتهترین تکنیکهای فازینگ، آسیبپذیریهای نرمافزار را پیدا کنند، اما با منابع محدود مانند توان محاسباتی مشابه با طرفهای مورد اعتماد. این مهاجمان فقط به باینری محافظت شده توسط فازیسازی دسترسی دارند و از تکنیکهای فازیسازی (FUZZIFICATION) آگاه هستند. آنها میتوانند از روشهای تحلیل باینری آماده (off-the-shelf) برای غیرفعال کردن فازیسازی استفاده کنند. مهاجمانی که به باینری بدون محافظت یا حتی کد منبع برنامه دسترسی دارند (مثل مهاجمان داخلی یا از طریق افشای کد) خارج از محدودهٔ این مطالعه محسوب میشوند.
۲.۲.۲ اهداف طراحی و انتخابها
یک تکنیک فازیسازی (FUZZIFICATION) باید همزمان چهار ویژگی زیر را داشته باشد:
- اثربخش (Effective): باید بتواند تعداد باگهای کشف شده در باینری محافظت شده را نسبت به باینری اصلی بهطور موثر کاهش دهد.
- عمومی (Generic): باید بر اصول پایهای فازینگ تمرکز کند و بهطور کلی برای اکثر فازرها قابل استفاده باشد.
- کارآمد (Efficient): باید سربار اندکی به اجرای عادی برنامه اضافه کند و کارایی آن را به شکل چشمگیر کاهش ندهد.
- مقاوم (Robust): باید در برابر تحلیلهای مهاجمان برای حذف فازیسازی از باینری محافظت شده مقاوم باشد.
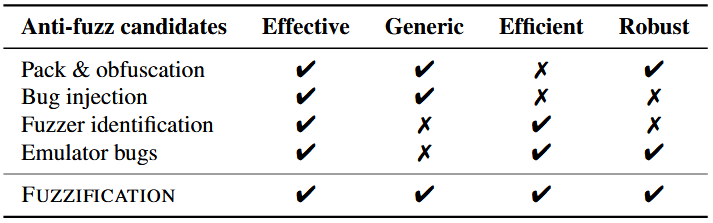
با در نظر گرفتن این اهداف، ما چهار گزینهٔ طراحی برای مقابله با فازینگ مخرب را بررسی میکنیم که در جدول ۱ نشان داده شده است. متأسفانه، هیچیک از روشها قادر به برآورده کردن همهٔ اهداف بهطور همزمان نیستند.
بستهبندی/مبهمسازی (Packing/obfuscation): بستهبندی و مبهمسازی نرمافزار، تکنیکهای پخته و شناختهشدهای علیه مهندسی معکوس هستند و در عین حال عمومی و مقاوم محسوب میشوند. با این حال، این روشها معمولاً سربار اجرایی بالایی به برنامه اضافه میکنند، که علاوه بر اینکه فازینگ را مختل میکند، استفادهٔ کاربران عادی از برنامه را نیز تحت تأثیر قرار میدهد.
تزریق باگ (Bug injection): تزریق قطعات کد دلخواه که باعث کرشهای غیرقابل بهرهبرداری (non-exploitable crashes) میشوند، میتواند سربار اضافی برای مدیریت داخلی برنامه (bookkeeping overhead) ایجاد کند و همچنین تجربهٔ کاربران نهایی را بهطور غیرمنتظره تحت تأثیر قرار دهد [31].
شناسایی فازر (Fuzzer identification): تشخیص فرآیند فازر و تغییر رفتار اجرای برنامه بر اساس آن، بهراحتی قابل دور زدن است (مثلاً با تغییر نام فازر). علاوه بر این، نمیتوان تمام فازرها یا تکنیکهای فازینگ را فهرست و شناسایی کرد.
باگهای شبیهساز (Emulator bugs): فعالسازی (trigger کردن) آسیبپذیریها در ابزارهای ابزاربندی پویا (dynamic instrumentation) میتواند [4،14،39] فرآیند فازینگ را مختل یا متوقف کند [43،44]. با این حال، این روش نیازمند دانش عمیق درباره فازر مشخص است و بنابراین یک راهکار عمومی (generic) محسوب نمیشود.
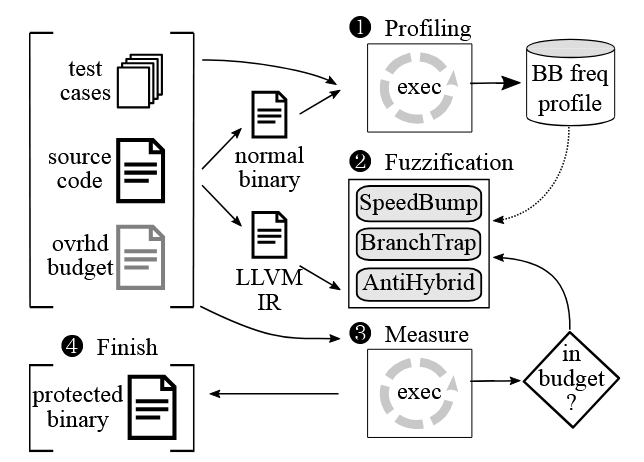
۲.۳ نمای کلی طراحی (Design Overview)
ما سه تکنیک فازیسازی (FUZZIFICATION) شامل SpeedBump، BranchTrap و AntiHybrid را پیشنهاد میکنیم تا هر یک از تکنیکهای فازینگ مطرحشده در بخش 2.1 را هدف قرار دهند. ابتدا، SpeedBump با تزریق مکانیزمهای تأخیرِ ریزدانه (fine‑grained delay primitives) در مسیرهای سرد (cold paths) – مسیرهایی که اجرای فازینگ بهطور مکرر به آنها میرسد اما اجرای عادی برنامه بهندرت از آنها استفاده میکند – باعث کند شدن اجرای فازینگ میشود (بخش 3).
در مرحله دوم، BranchTrap تعداد زیادی شاخهی وابسته به ورودی (input‑sensitive branches) ایجاد میکند تا فازرهای مبتنی بر پوشش مسیر (coverage‑based fuzzers) را وادار کند منابع خود را روی مسیرهای بیثمر مصرف کنند (بخش 4). همچنین با ایجاد برخوردهای مکرر در ساختار ذخیرهسازی پوشش کد، عمداً فضای پوشش را اشباع میکند تا فازر نتواند ورودیهای واقعاً مهمی را که مسیرهای جدید ایجاد میکنند تشخیص دهد.
در مرحله سوم، AntiHybrid جریانهای دادهی صریح (explicit data‑flows) را به جریانهای ضمنی (implicit) تبدیل میکند تا رهگیری داده از طریق تحلیل آلودگی (taint analysis) یا تحلیل آلودگی داده دشوار شود، و علاوه بر آن تعداد زیادی نماد جعلی وارد برنامه میکند تا در اجرای نمادین (symbolic execution) پدیدهی انفجار مسیر (path explosion) رخ دهد (بخش 5).
شکل ۳ نمای کلی سیستم فازیسازی (FUZZIFICATION) ما را نشان میدهد. این سیستم سه ورودی میگیرد:
- کد منبع برنامه (program source code)
- مجموعهای از تستهای رایج (commonly used test cases)
- بودجهٔ سربار مجاز (overhead budget)
و در خروجی، یک باینری محافظت شده با تکنیکهای فازیسازی تولید میکند. توجه داشته باشید که تعیین بودجهٔ سربار به عهدهٔ توسعه دهندگان است تا توازن مناسبی بین عملکرد و امنیت برنامه برقرار شود. ابتدا، برنامه را کامپایل میکنیم تا یک باینری عادی ایجاد شود و آن را با موارد تست عادی داده شده اجرا میکنیم تا تعداد فراوانی بلوکهای پایه جمعآوری شود. این اطلاعات نشان میدهد که کدام بلوکهای پایه بهندرت در اجرای عادی استفاده میشوند. سپس، بر اساس این پروفایل، سه تکنیک فازیسازی را روی برنامه اعمال کرده و یک باینری موقت محافظت شده تولید میکنیم.
سپس سربار باینری موقت را با همان موارد تست عادی دوباره اندازهگیری میکنیم. اگر سربار بیشتر از بودجه باشد، به مرحلهٔ قبل بازمیگردیم تا کُندی برنامه کاهش یابد، مثلاً با استفاده از تأخیر کوتاهتر یا اعمال ابزارگذاری کمتر. اگر سربار خیلی کمتر از بودجه باشد، میزان آن را مطابق بودجه افزایش میدهیم. در غیر این صورت، باینری محافظت شده نهایی تولید میشود.
3. SpeedBump: افزایش تأخیر در فازینگ
ما تکنیکی به نام SpeedBump را پیشنهاد میکنیم تا اجرای فازینگ را کُند نماید و در عین حال تأثیر کمی بر اجرای عادی برنامه داشته باشد. مشاهده ما این است که اجرای فازینگ اغلب به مسیرهایی میافتد که اجرای عادی بهندرت آنها را طی میکند، مانند مسیرهای مدیریت خطا (مثلاً بایتهای MAGIC نادرست). ما این مسیرها را مسیرهای سرد (cold paths) یا مسیر های کم اجرا شده مینامیم. تزریق تأخیر در مسیرهای کماستفاده باعث کُند شدن اجرای فازینگ میشود اما اجرای عادی را چندان تحت تأثیر قرار نمیدهد. ابتدا مسیرهای سرد را با اجرای برنامه روی تستهای داده شده شناسایی میکنیم و سپس تأخیرهای طراحیشده را به مسیرهای کد کمپیمایش تزریق میکنیم. ابزار ما بهصورت خودکار تعداد مسیرهایی که باید تأخیر به آنها اضافه شود و طول هر تأخیر را تعیین میکند، بهطوری که سربار باینری محافظت شده در اجرای عادی، زیر بودجهٔ تعیین شده توسط کاربر باقی بماند.
پروفایلگیری فرکانس بلاکهای پایه. فازیسازی (FUZZIFICATION) یک پروفایل فرکانس بلاکهای پایه ایجاد میکند تا مسیرهای سرد (cold paths) را شناسایی کند. فرایند پروفایلگیری شامل سه مرحله است. ابتدا، برنامههای هدف ابزارگذاری (instrument) میشوند تا تعداد بلاکهای پایهای که در طول اجرا بازدید میشوند شمارش شود و یک باینری برای پروفایلگیری تولید گردد. سپس، با استفاده از تستهای ارائه شده توسط کاربر، این باینری اجرا میشود و بلاکهای پایه بازدیدشده توسط هر ورودی جمعآوری میشوند. در مرحله سوم، فازیسازی اطلاعات جمعآوریشده را تحلیل میکند تا بلاکهای پایهای که بهندرت یا هرگز توسط ورودیهای معتبر اجرا نمیشوند شناسایی شوند. این بلاکها در تزریق تأخیر بهعنوان مسیرهای کماستفاده در نظر گرفته میشوند.
پروفایلگیری ما نیازی ندارد که تستهای ارائه شده توسط کاربر ۱۰۰٪ مسیرهای معتبر برنامه را پوشش دهند؛ بلکه کافی است که عملکردهای معمول برنامه را فعال کنند. ما معتقدیم این یک فرض عملی است، زیرا توسعهدهندگان با تجربه معمولاً مجموعهای از تستها دارند که بیشتر عملکردهای برنامه را پوشش میدهند (مانند مجموعه آزمونهای رگرسیون). بهصورت اختیاری، اگر توسعهدهندگان بتوانند تستهایی ارائه دهند که ویژگیهای غیرمعمول برنامه را فعال کنند، نتایج پروفایلگیری دقیقتر خواهد شد. بهعنوان مثال، برای برنامههایی که فرمتهای فایل شناختهشده را پردازش میکنند (مانند readelf که فایلهای ELF را میخواند)، جمعآوری مجموعه دادههای معتبر و نامعتبر کار نسبتاً سادهای است.
تزریق تأخیر قابل تنظیم (Configurable delay injection). ما دو مرحله زیر را به صورت مکرر انجام میدهیم تا مجموعه بلاکهای کدی که تأخیر در آنها تزریق میشود و طول هر تأخیر مشخص شود:
- ابتدا، تأخیر ۳۰ میلیثانیهای به ۳٪ بلاکهای پایهای که کمترین اجرا را داشتهاند در اجرای تستها تزریق میکنیم. مشاهده میکنیم که این تنظیم نزدیک به نتیجهٔ نهایی ارزیابی است.
- سپس سربار باینری تولیدشده اندازهگیری میشود. اگر سربار از بودجهٔ تعیینشده توسط کاربر تجاوز نکرد، به مرحلهٔ قبل بازمیگردیم و تأخیر بیشتری به بلاکهای بیشتر تزریق میکنیم. در غیر این صورت، تأخیر مرحلهٔ قبلی بهعنوان نتیجهٔ نهایی استفاده میشود.
تکنیک SpeedBump ما بهویژه برای توسعهدهندگانی مفید است که درک خوبی از برنامه و نیازمندیهای فازیسازی دارند. ما پنج گزینه ارائه میکنیم تا توسعهدهندگان بتوانند اثربخشی SpeedBump را بهطور دقیق تنظیم کنند.
- MAX_OVERHEAD بودجهٔ سربار را مشخص میکند. توسعهدهندگان میتوانند هر مقداری تعیین کنند تا زمانی که با سطح سربار راحت باشند.
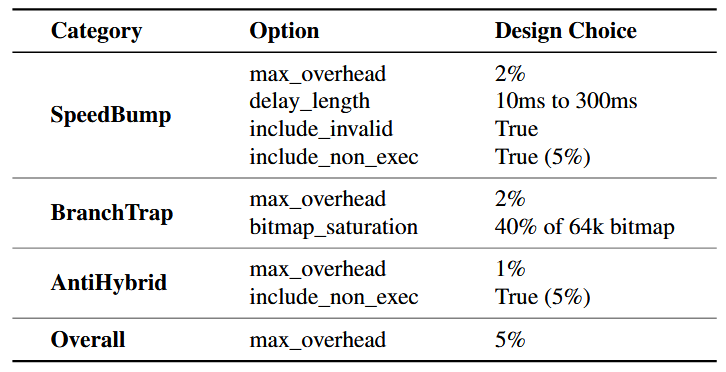
- DELAY_LENGTH محدودهٔ طول تأخیرها را تعیین میکند. در ارزیابی ما از ۱۰ میلیثانیه تا ۳۰۰ میلیثانیه استفاده شده است.
- INCLUDE_INCORRECT مشخص میکند که آیا تأخیرها به بلاکهای مدیریت خطا (یعنی مکانهایی که تنها توسط ورودیهای نامعتبر اجرا میشوند) تزریق شوند یا نه؛ این گزینه بهصورت پیشفرض فعال است.
- INCLUDE_NON_EXECو NON_EXEC_RATIO تعیین میکنند که آیا تأخیر به تعداد مشخصی از بلاکهایی که در اجرای تست هرگز اجرا نمیشوند تزریق شود یا خیر. این گزینه زمانی مفید است که توسعهدهندگان مجموعهٔ بزرگی از تستها ندارند.
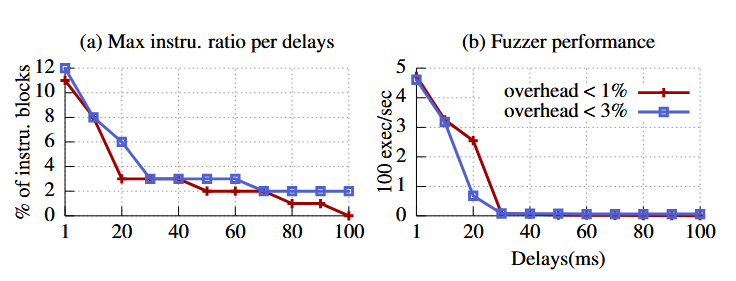
شکل ۴ تأثیر گزینههای مختلف بر حفاظت از باینری readelf با SpeedBump را نشان میدهد. ما برای این آزمایش، ۱,۹۴۸ فایل ELF در سیستم Debian بهعنوان تستهای معتبر و ۶۰۰ فایل متنی و تصویری بهعنوان ورودیهای نامعتبر جمعآوری کردیم.
- شکل ۴ (a) حداکثر نسبت بلاکهای پایهای که میتوان تأخیر در آنها تزریق کرد را نشان میدهد، به شرطی که سربار کمتر از ۱٪ و ۳٪ باشد.
- برای تأخیر ۱ میلیثانیه، میتوان ۱۱٪ از بلاکهای کماستفاده را برای بودجهٔ سربار ۱٪ و ۱۲٪ را برای ۳٪ ابزارگذاری کرد.
- برای تأخیر ۱۲۰ میلیثانیه، نمیتوان هیچ بلاکی را برای بودجهٔ ۱٪ تزریق کرد و تنها ۲٪ از مسیرهای سرد را برای بودجهٔ ۳٪ تزریق کرد.
- شکل ۴ (b) عملکرد واقعی AFL-QEMU را هنگام فازینگ باینریهای محافظت شده با SpeedBump نشان میدهد. نسبت بلاکهای تزریقشده مطابق با شکل ۴ (a) تعیین شده است.
نتیجه نشان میدهد که SpeedBump با تأخیر ۳۰ میلیثانیه فازر را بیش از ۵۰ برابر کند میکند. بنابراین، ما ۳۰ میلیثانیه و ۳٪ ابزارگذاری مربوطه را بهعنوان نقطهٔ شروع استفاده میکنیم.
۳.۱ ساختار اولیه تأخیر مقاوم در برابر تحلیل (Analysis-resistant Delay Primitives)
از آنجا که مهاجمان ممکن است با تحلیل برنامه بتوانند تأخیرهای ساده (مانند فراخوانی sleep) را شناسایی و حذف کنند، ما تأخیرهای مقاوم و پیچیدهای طراحی کردهایم که شامل عملیات حسابی هستند و با کد اصلی برنامه در ارتباط میباشند.
تأخیرهای ما بر پایه CSmith [66] ساخته شدهاند که قادر است قطعات کد تصادفی و بدون باگ با گزینههای قابل تنظیم تولید کند. بهعنوان مثال، CSmith میتواند تابعی تولید کند که پارامتر میگیرد، عملیات حسابی انجام میدهد و یک نوع داده مشخص برمیگرداند. ما CSmith را تغییر دادیم تا کدی تولید کند که وابستگیهای دادهای و وابستگی به کد اصلی داشته باشد. به طور مشخص:
- یک متغیر از کد اصلی به کد تولیدشده بهعنوان آرگومان منتقل میشود.
- کد تولید شده به کد اصلی ارجاع (reference) دارد.
- مقدار برگشتی کد تولید شده برای اصلاح یک متغیر سراسری (global variable) در کد اصلی استفاده میشود.

شکل ۵ نمونهای از تأخیرهای مقاوم ما را نشان میدهد. در این مثال، یک متغیر محلی PASS_VAR اعلام شده و متغیرهای سراسری GLOBAL_VAR1 و GLOBAL_VAR2 تغییر داده میشوند. به این ترتیب، وابستگی جریان داده (data-flow dependency) بین کد اصلی و کد تزریقشده ایجاد میشود (خطوط ۶، ۹ و ۱۲) و حالت برنامه تغییر میکند بدون اینکه روی عملکرد اصلی برنامه تأثیر بگذارد.
اگرچه کد بهصورت تصادفی تولید شده است، اما از طریق وابستگیهای جریان داده و کنترل (data-flow و control-flow) با کد اصلی بهطور محکم مرتبط است. بنابراین، برای تکنیکهای معمول تحلیل باینری، مانند حذف کد مرده (dead-code elimination)، تمایز آن از کد اصلی غیرساده و دشوار است. ما CSmith تغییر یافته را بهصورت مکرر اجرا میکنیم تا قطعات کدی مناسب پیدا کنیم که برای تزریق تأخیر، زمان مشخصی (مثلاً ۱۰ میلیثانیه) نیاز داشته باشند.
ایمنی تأخیرهای تزریق شده (Safety of delay primitives). ما از چکهای ایمنی CSmith و فازیسازی استفاده میکنیم تا اطمینان حاصل کنیم که کد تولیدشده بدون باگ است. ابتدا، از چکهای ایمنی پیشفرض CSmith استفاده میکنیم، که مجموعهای از تستها را در کد جاسازی میکند، شامل: صحیح بودن اعداد صحیح، نوع دادهها، اشارهگرها، اثرات جانبی، آرایهها، مقداردهی اولیه و متغیرهای سراسری. بهعنوان مثال:
- CSmith تحلیل اشارهگر انجام میدهد تا دسترسی به متغیرهای خارج از محدودهی پشته یا dereference اشارهگر null را شناسایی کند.
- از مقداردهی اولیه صریح برای جلوگیری از استفاده از متغیرهای مقداردهینشده استفاده میکند.
- از math wrapper برای جلوگیری از overflow غیرمنتظرهی اعداد صحیح استفاده میشود.
- qualifierها تحلیل میشوند تا از هرگونه عدم تطابق جلوگیری شود.
در مرحله دوم، فازیسازی یک فرآیند جداگانه برای شناسایی اثرات جانبی منفی (مثل کرش) در تأخیرها دارد. بهطور مشخص، کد ۱۰ بار با آرگومانهای ثابت اجرا میشود و اگر اجرای آن هرگونه خطایی نشان دهد، رد میشود.
در نهایت، فازیسازی تأخیرهای تولیدشده را با همان آرگومان ثابت جاسازی میکند تا از بروز خطا جلوگیری شود.
فازرهای آگاه به بلاکهای مدیریت خطا (Fuzzers aware of error-handling blocks). در برخی پیشنهادهای اخیر فازینگ، مانند VUzzer [52] و T-Fuzz [48]، بلاکهای پایهی مربوط به مدیریت خطا از طریق پروفایلگیری شناسایی میشوند و از محاسبه پوشش کد حذف میشوند تا از اجرای تکراری جلوگیری شود. این موضوع ممکن است اثربخشی تکنیک SpeedBump ما را تحت تأثیر قرار دهد، زیرا SpeedBump نیز از مرحلهای مشابه برای شناسایی مسیرهای سرد یا کم اجرا شده (cold paths) استفاده میکند.
خوشبختانه، مسیرهای سرد در SpeedBump فقط شامل بلاکهای مدیریت خطا نیستند، بلکه بلاکهای عملکردی که بهندرت اجرا میشوند را نیز در بر میگیرند. علاوه بر این، ما از روشهای مشابه برای شناسایی بلاکهای مدیریت خطا در بین مسیرهای کماستفاده استفاده میکنیم و گزینهای در اختیار توسعهدهندگان قرار میدهیم تا این بلاکها را ابزارگذاری نکنند. بدین ترتیب، فازیسازی ما روی ابزارگذاری بلاکهای عملکردی کماستفاده تمرکز میکند تا حداکثر اثربخشی را داشته باشد.
4. BranchTrap: مسدود کردن بازخورد پوشش کد (Blocking Coverage Feedback)
اطلاعات پوشش کد (code coverage) بهطور گسترده توسط فازرها برای یافتن و اولویتبندی ورودیهای جالب استفاده میشود [72, 37, 23]. ما میتوانیم این فازرها را درگیر مسیرهای بیفایده کنیم اگر تعداد زیادی شاخه شرطی (conditional branch) وارد کنیم که شرایط آنها نسبت به تغییرات جزئی ورودی حساس باشد. زمانی که فرآیند فازینگ به این تلههای شاخهای (branch traps) بیفتد، فازرهای مبتنی بر پوشش کد منابع خود را صرف کاوش مسیرهای بیفایده میکنند. بنابراین، ما تکنیک BranchTrap را پیشنهاد میکنیم تا فازرهای مبتنی بر پوشش کد را فریب داده یا بازخورد پوشش آنها را مسدود کنیم.
۴.۱ ساخت مسیرهای جعلی بر اساس ورودی کاربر
روش اول BranchTrap، ایجاد تعداد زیادی شاخه شرطی و پرش غیرمستقیم (indirect jump) و تزریق آنها در برنامهٔ اصلی است. هر شاخهٔ شرطی ساخته شده به تعدادی از بایتهای ورودی وابسته است تا تصمیم بگیرد شاخه گرفته شود یا خیر، در حالی که پرشهای غیرمستقیم مقصد خود را بر اساس ورودی کاربر محاسبه میکنند. بنابراین، حتی با تغییرات جزئی در ورودی، برنامه مسیرهای اجرایی متفاوتی را طی میکند. وقتی اجرای فازینگ یک شاخهٔ جعلی را فعال کند، فازر اولویت بالاتری برای جهش آن ورودی در نظر میگیرد و در نتیجه مسیرهای جعلی بیشتری شناسایی میشوند. بدین ترتیب، فازر همچنان منابع خود (CPU و حافظه) را برای بررسی مسیرهای بیفایده اما بدون باگ هدر میدهد.
برای فریب مؤثر فازرها و تمرکز آنها روی شاخههای جعلی، ما چهار جنبهٔ طراحی را در نظر میگیریم:
اول، BranchTrap باید تعداد کافی مسیر جعلی ایجاد کند تا سیاست فازینگ را تحت تأثیر قرار دهد. از آنجایی که فازر از یک ورودی جالب چندین نسخه (variant) تولید میکند، مسیرهای جعلی باید پوشش متفاوت ارائه دهند و مستقیماً تحت تأثیر ورودی باشند تا فازر مرتبا تله را کشف کند.
دوم، مسیرهای جدید تزریقشده باید سربار کمی روی اجرای عادی برنامه داشته باشند.
سوم، مسیرهای BranchTrap باید تعیینشده (deterministic) نسبت به ورودی کاربر باشند، به این معنی که همان ورودی باید از همان مسیر عبور کند. دلیل آن این است که برخی فازرها میتوانند مسیرهای غیرتعیینشده را شناسایی و نادیده بگیرند (مثلاً AFL یک ورودی را نادیده میگیرد اگر دو اجرای آن ورودی مسیرهای متفاوتی طی کنند).
چهارم، BranchTrap به سادگی توسط مهاجمان شناسایی یا حذف نشود.
یک پیادهسازی ساده از BranchTrap میتواند شامل تزریق جدول پرش (jump table) باشد و از برخی بایتهای ورودی بهعنوان ایندکس جدول استفاده شود (یعنی مقادیر متفاوت ورودی منجر به مقصدهای پرش متفاوت میشوند). با این حال، این روش میتواند بهسادگی توسط تحلیلهای سادهٔ مهاجمان خنثی شود. ما یک BranchTrap مقاوم طراحی و پیادهسازی کردهایم که از تکنیکهای بازیابی کد (code-reuse) استفاده میکند، مشابه مفهوم شناختهشدهٔ برنامهنویسی مبتنی بر بازگشت (return-oriented programming, ROP) [55].
۴.۱.۱ BranchTrap با تحریف گراف کنترل جریان (CFG Distortion)
برای تقویت BranchTrap، ما آدرسهای بازگشت (return addresses) هر شاخه تزریق شده را بر اساس ورودی کاربر متنوعسازی میکنیم. ایده ما از ROP (Return-Oriented Programming) الهام گرفته شده است، که در آن کد موجود برای حملات مخرب با زنجیر کردن قطعات کوچک کد دوباره استفاده میشود. روش ما میتواند جریان کنترل برنامه را بهطور قابل توجهی تحریف کند و خنثیسازی BranchTrap توسط مهاجمان را دشوارتر سازد.

پیادهسازی شامل سه مرحله است:
- BranchTrap بخشهای پایانی (epilogue) تابع از اسمبلی برنامه را جمعآوری میکند (که در زمان کامپایل برنامه تولید شدهاند).
- بخشهای پایانی (epilogue) که دارای توالی دستوری یکسان هستند، در یک جدول پرش (jump table) گروهبندی میشوند.
- اسمبلی بازنویسی میشود تا تابع یکی از بخشهای پایانی (epilogue) معادل را از جدول پرش مربوطه بازیابی کند و بازگشت تابع اصلی را با استفاده از برخی بایتهای ورودی به عنوان ایندکس جدول پرش شبیهسازی نماید.
با جایگزینی بخشهای پایانی (epilogue) تابع با معادل عملکردی (functional equivalent)، عملیات کاملاً مشابه برنامهٔ اصلی تضمین میشود.
شکل ۶ نمای داخلی پیادهسازی BranchTrap را در زمان اجرا نشان میدهد. برای یک تابع:
- BranchTrapمقدار XOR تمام آرگومانها را محاسبه میکند. این مقدار برای ایندکس کردن جدول پرش استفاده میشود (یعنی انتخابهای ممکن برای آدرس بخشهای پایانی).
- BranchTrap این مقدار را بهعنوان ایندکس جدول پرش استفاده میکند و آدرس واقعی epilogue را بهدست میآورد. برای جلوگیری از دسترسی خارج از محدوده آرایه، BranchTrap مقدار XOR شده را بر طول جدول پرش تقسیم میکند و باقیمانده را بهعنوان ایندکس میگیرد.
- پس از تعیین آدرس پرش هدف، جریان کنترل به gadget منتقل میشود (مثلاً همان pop rbp; pop r15; ret gadget).
- در نهایت، اجرا به آدرس بازگشت اصلی برمیگردد.
BranchTrap مبتنی بر ROP سه مزیت دارد:
- اثربخشی (Effective): جریان کنترل برنامه بهصورت مداوم و حساس نسبت به جهشهای ورودی تولیدشده توسط کاربر تغییر میکند؛ بنابراین، فرآیند فازیسازی (Fuzzification) میتواند تعداد قابلتوجهی مسیر اجرایی غیرمولد ایجاد کند و در نتیجه کارایی بازخورد پوشش (coverage feedback) را کاهش دهد. علاوه بر این، BranchTrap تضمین میکند که برای یک ورودی مشخص، همواره جریان کنترل یکسانی طی شود (یعنی مسیر اجرایی قطعی یا deterministic)، بهگونهای که فازر نتواند این مسیرهای جعلی را نادیده بگیرد.
- سربار کم (Low Overhead): BranchTrap به دلیل استفاده از عملیاتهای سبکوزن (شامل ذخیرهسازی آرگومان، انجام عملیات XOR، تعیین آدرس پرش، و انتقال کنترل به gadget) سربار بسیار کمی به اجرای عادی برنامه تحمیل میکند (برای مثال کمتر از ۱٪ سربار).
- استحکام (Robust): طراحی مبتنی بر ROP (Return Oriented Programming) پیچیدگی تحلیل را بهطور چشمگیری افزایش میدهد و شناسایی یا اعمال وصله (patch) روی باینری را برای مهاجم دشوارتر میکند. ما میزان استحکام BranchTrap در برابر تحلیلهای خصمانه را در بخش 6.4 ارزیابی کردهایم.
۴.۲ اشباعسازی حالت فازینگ
روش دوم BranchTrap مبتنی بر اشباعسازی وضعیت فازینگ است؛ رویکردی که مانع از یادگیری پیشرفت پوشش کد (code coverage) توسط فازرها میشود. برخلاف روش اول که باعث میشد فازرها روی ورودیهای بیفایده تمرکز کنند، هدف در اینجا جلوگیری از شناسایی ورودیهای واقعاً جالب و مؤثر توسط فازر است.
BranchTrap برای دستیابی به این هدف، تعداد زیادی شاخه را به برنامه اضافه میکند و از سازوکار نمایش پوشش (coverage representation mechanism) هر فازر برای پوشاندن و پنهان کردن یافتههای جدید سوءاستفاده میکند.
BranchTrap قادر است تعداد زیادی (مثلاً 10 هزار تا 100 هزار) شاخه قطعی را به برخی از بلوکهای پایه که به ندرت اجرا میشوند، معرفی کند. به محض اینکه فازر به این بلوکهای پایه میرسد، جدول پوشش (coverage table) آن به سرعت پر میشود. در نتیجه، اغلب مسیرهای جدیدی که در اجراهای بعدی کشف میشوند، بهاشتباه به عنوان مسیرهای قبلاً دیدهشده در نظر گرفته خواهند شد؛ بنابراین فازر ورودیهایی را که در واقع مسیرهای جالب و جدیدی را کاوش میکنند، کنار میگذارد.
بهعنوان نمونه، فازر AFL از یک bitmap با اندازهٔ ثابت (۶۴ کیلوبایت) برای ردیابی پوشش یالها (edge coverage) استفاده میکند. با افزودن تعداد زیادی شاخهٔ متمایز، احتمال برخورد (collision) در bitmap بهطور قابلتوجهی افزایش مییابد و در نتیجه دقت اندازهگیری پوشش کاهش پیدا میکند.
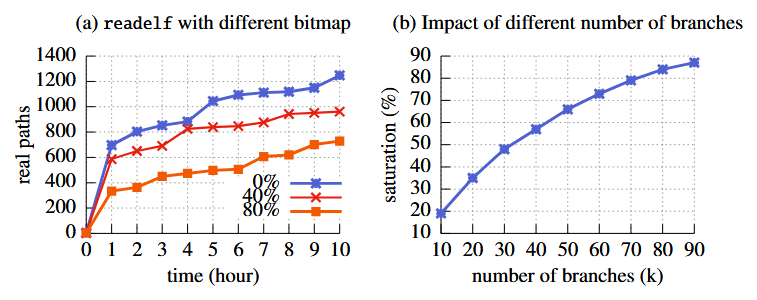
شکل 7 (a) تأثیر اشباع bitmap را بر فرآیند فازینگ ابزار readelf نشان میدهد. همانطور که مشاهده میشود، هرچه میزان اشباع bitmap بیشتر باشد، تعداد مسیرهای کشفشده کمتر خواهد بود. زمانی که bitmap در ابتدا خالی است، فازر AFL پس از ۱۰ ساعت فازینگ بیش از ۱۲۰۰ مسیر اجرایی را شناسایی میکند. در نرخ اشباع ۴۰٪، این مقدار به حدود ۹۵۰ مسیر کاهش مییابد. همچنین اگر bitmap اولیه بهشدت پر باشد (برای مثال با اشباع ۸۰٪ )، AFL با همان میزان تلاش فازینگ تنها حدود ۷۰۰ مسیر را شناسایی میکند.
فازرهای دارای مکانیزم کاهش تصادم یا برخورد (Collision Mitigation). فازرهای جدیدی مانند CollAFL [19] برای کاهش مشکل تصادم (collision) در دادههای پوشش، رویکرد اختصاص یک شناسهٔ یکتا به هر مسیر پوشش را پیشنهاد میکنند (برای مثال، در CollAFL هر branch دارای شناسهٔ منحصربهفرد است). با این حال، ما استدلال میکنیم که این تکنیکها نمیتوانند بهطور مؤثری قدرت روش BranchTrap را در اشباعسازی فضای ذخیرهسازی پوشش تضعیف کنند؛ آن هم به دو دلیل اصلی:
اول، روشهای فعلی کاهش برخورد نیازمند دسترسی به کد منبع برنامه هستند تا بتوانند در مرحلهٔ بهینهسازی زمان لینک (Link-Time Optimization) شناسههای یکتا را تخصیص دهند [19]. در مدل تهدید ما، مهاجمان به کد منبع برنامه یا باینری اصلی دسترسی ندارند و تنها یک نسخه از باینری محافظت شده را در اختیار دارند؛ بنابراین اعمال الگوریتمهای مشابه تخصیص شناسه بهمراتب دشوارتر خواهد بود.
دوم، این فازرها همچنان به استفاده از فضای ذخیرهسازی پوشش با اندازهٔ ثابت (fixed-size coverage storage) وابسته هستند، زیرا استفاده از حافظههای بزرگتر سربار اجرایی قابلتوجهی ایجاد میکند. در نتیجه، اگر بتوانیم حدود ۹۰٪ از این فضای ذخیرهسازی را اشباع کنیم، CollAFL تنها قادر خواهد بود از ۱۰٪ باقیمانده برای تخصیص شناسهها استفاده کند؛ بنابراین عملکرد فازینگ بهشدت تحت تأثیر قرار خواهد گرفت.
۴.۳ عوامل طراحی BranchTrap
ما یک رابط پیکربندی در اختیار توسعهدهندگان قرار میدهیم تا بتوانند BranchTrap مبتنی بر ROP و همچنین مکانیزم اشباع پوشش (coverage saturation) را برای دستیابی به سطح بهینهای از حفاظت تنظیم کنند.
نخست، تعداد مسیرهای جعلی (fake paths) تولیدشده توسط BranchTrap مبتنی بر ROP قابل تنظیم است. BranchTrap برای ایجاد جریان کنترل تحریف شده (distorted control-flow) به تعداد توابع موجود در برنامه وابسته است. بنابراین، تزریق BranchTrap زمانی بیشترین اثربخشی را دارد که برنامهٔ اصلی شامل تعداد زیادی تابع باشد. برای باینریهایی که تعداد توابع کمتری دارند، گزینهای فراهم شده است که به توسعهدهندگان اجازه میدهد بلوکهای پایهای (basic blocks) موجود را به چندین بخش کوچکتر تقسیم کنند و آنها را از طریق شاخههای شرطی به یکدیگر متصل نمایند.
دوم، اندازه و تعداد شاخههای تزریق شده با هدف اشباعسازی پوشش نیز قابل کنترل است. شکل 7(b) نشان میدهد که چگونه با افزایش تعداد شاخهها میتوان bitmap مورد استفاده در AFL را اشباع کرد. همانطور که مشاهده میشود، افزایش تعداد شاخهها باعث پر شدن تعداد بیشتری از ورودیهای bitmap میشود. برای مثال، تزریق ۱۰۰ هزار شاخه میتواند بیش از ۹۰٪ از bitmap را پر کند.
بدیهی است که تزریق تعداد بسیار زیادی شاخه موجب افزایش اندازهٔ باینری خروجی میشود. در آزمایش ما، با تزریق ۱۰۰ هزار شاخه، اندازهٔ باینری محافظت شده حدود ۴٫۶ مگابایت بزرگتر از باینری اصلی شد. برای جلوگیری از افزایش بیشازحد اندازهٔ کد، ما تعداد زیادی شاخه را تنها در یک یا دو بلوک پایهای که به ندرت اجرا میشوند تزریق میکنیم. بهمحض اینکه یکی از اجراهای فازینگ به این شاخهها برسد، فضای ذخیرهسازی پوشش پر شده و در ادامهٔ فرآیند فازینگ، ورودیهای جالب کمتری شناسایی خواهند شد.
5. AntiHybrid: خنثیسازی و مقابله با فازرهای هیبریدی (Thwarting Hybrid Fuzzers)
روشهای فازینگ هیبریدی (Hybrid Fuzzing) برای افزایش کارایی فازینگ از اجرای نمادین (Symbolic Execution) یا تحلیل آلودگی پویا (Dynamic Taint Analysis — DTA) استفاده میکنند.
اجرای کانکولیک (یا Concolic Execution) در حل شرایط شاخهای پیچیده (مانند بررسی magic number یا محاسباتchecksum ) بسیار مؤثر است؛ بنابراین میتواند به فازرها کمک کند تا از موانعی که با جهشهای معمول ورودی به سختی قابل عبور هستند، عبور کنند.
از سوی دیگر، تحلیل آلودگی پویا (DTA) به شناسایی بایتهای ورودیای کمک میکند که بر شرایط شاخهها تأثیرگذار هستند. این اطلاعات به فازر اجازه میدهد جهشهای ورودی را بهصورت هدفمندتر انجام دهد.
در سالهای اخیر، چندین روش فازینگ هیبریدی معرفی شدهاند که موفق به کشف آسیبپذیریهای مهم امنیتی شدهاند. برای نمونه:
- Driller [57] با بهکارگیری اجرای نمادین انتخابی (Selective Symbolic Execution)، کارایی خود را در در طول چالش بزرگ سایبری DARPA (CGC) اثبات کرد.
- VUzzer [52] از تحلیل آلودگی پویا برای شناسایی بایتهای ورودی حیاتی در مسیر اجرا استفاده کرد تا جهش ورودیها مؤثرتر انجام شود.
- QSym [67] یک تکنیک اجرای کانکولیک سریع ارائه داد که قابلیت مقیاسپذیری روی برنامههای واقعی را دارد.
با این حال، روشهای هیبریدی دارای ضعفهای شناختهشدهای هستند. اول، هم اجرای نمادین و هم تحلیل آلودگی پویا منابع زیادی مانند CPU و حافظه مصرف میکنند و این آنها را محدود به تحلیل برنامههای ساده میکند. دوم، اجرای نمادین با مشکل انفجار مسیرها (path explosion) محدود شده است. اگر پردازش نمادها نیازمند عملیات پیچیده باشد، موتور اجرای نمادین مجبور است تمام حالتهای اجرای ممکن را بهصورت فراگیر بررسی و ارزیابی کند؛ در نتیجه، بیشتر موتورهای اجرای نمادین نمیتوانند مسیر اجرای برنامه را تا انتها اجرا کنند. سوم، تحلیل DTA در ردیابی وابستگیهای داده ضمنی مشکل دارد، مانند کانالهای پنهان (covert channels)، کانالهای کنترلی (control channels) یا کانالهای مبتنی بر زمان (timing-based channels). برای مثال، برای پوشش وابستگی داده از طریق یک کانال کنترلی، موتور DTA باید ویژگی taint (آلودگی) را بهصورت گسترده به هر متغیری که بعد از یک شاخه شرطی ایجاد میگردد یا تغییر داده میشود منتقل کند، که باعث میشود تحلیل گرانقیمتتر و نتیجه کمتر دقیق باشد.
معرفی وابستگیهای جریان داده ضمنی (implicit data-flow dependencies). ما جریانهای داده صریح (explicit data-flows) موجود در برنامهٔ اصلی را به جریانهای داده ضمنی تبدیل میکنیم تا تحلیل آلودگی پویا (taint analysis) را دشوار کنیم.
در این فرآیند، فازیسازی (FUZZIFICATION) ابتدا شرایط شاخهها (branch conditions) و نقاط حساس اطلاعاتی (interesting information sinks) مانند تابع strcmp را شناسایی میکند و سپس کد تبدیل جریان داده را براساس نوع متغیرها تزریق میکند.
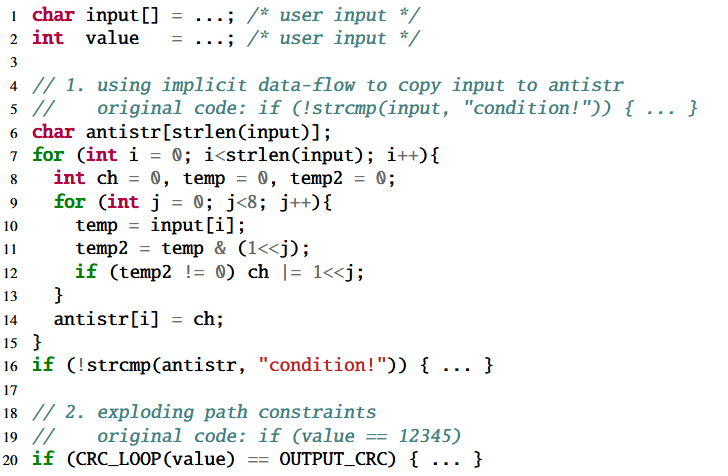
شکل 8 یک مثال از کاربرد AntiHybrid را نشان میدهد، جایی که ورودی به صورت آرایه برای تصمیمگیری در شرط شاخه استفاده میشود و strcmp یک تابع حساس است.
بنابراین، فازیسازی با استفاده از جریانهای داده ضمنی، آرایه را کپی میکند (خطوط 6 تا 15) و متغیر اصلی را با متغیر جدید جایگزین میکند (خط 16). به دلیل این تبدیل جریان داده به حالت ضمنی، تکنیک DTA نمیتواند بایتهای ورودی درست که بر شرط شاخه در خط 16 تأثیر میگذارند را شناسایی کند.
جریان دادهٔ ضمنی (implicit data-flow) مانع از تحلیل جریان داده میشود که فقط انتقال مستقیم دادهها را دنبال میکند. با این حال، این روش نمیتواند مانع استنتاج وابستگی دادهها از طریق تحلیل تفاضلی (differential analysis) شود. برای مثال، در کار اخیر RedQueen [2]، رابطهٔ احتمالی بین ورودی و شرایط شاخه از طریق pattern matching استنتاج میشود و در نتیجه میتواند از تبدیل جریان دادهٔ ضمنی عبور کند. با این وجود، RedQueen نیاز دارد که مقدار شرط شاخه به صورت صریح در ورودی نمایان باشد، چیزی که میتوان به راحتی با تغییر ساده دادهها فریب داد (مثلاً افزودن یک مقدار ثابت یکسان به هر دو عملوند مقایسه).
انفجار محدودیتهای مسیر (Exploding Path Constraints). برای جلوگیری از موفقیت فازرهای هیبریدی که از اجرای نمادین استفاده میکنند، فازیسازی (FUZZIFICATION) چندین قطعه کد (code chunk) تزریق میکند تا عمداً باعث انفجار مسیرها (path explosion) شود.
به طور مشخص، هر دستور مقایسه در برنامه با مقایسه مقادیر هش شدهٔ عملوندهای اصلی جایگزین میشود. دلیل استفاده از تابع هش این است که اجرای نمادین نمیتواند بهراحتی مقدار اصلی عملوند را از روی مقدار هش شده تعیین کند.
چون استفاده از توابع هش معمولاً سربار قابل توجهی را روی اجرای برنامه ایجاد میکند، فازیسازی از حلقههای بررسی افزونگی چرخهای سبک (CRC یا cyclic redundancy checking) با تکرار حلقهای برای تبدیل شرط شاخه استفاده میکند تا سربار عملکرد کاهش یابد. اگرچه از نظر تئوری CRC به اندازه قدرت هش نیست تا جلوی اجرای نمادین را بگیرد، اما همچنان باعث کندی قابل توجهی میشود.
شکل 8 یک مثال از تزریق کد برای انفجار مسیرها را نشان میدهد. بهطور مشخص، FUZZIFICATION شرط اصلی value == 12345 را به CRC_LOOP(value) == OUTPUT_CRC (خط 20) تغییر میدهد.
چنانچه اجرای نمادین تلاش کند این محدودیت CRC را حل کند، معمولاً به دلیل پیچیدگی ریاضیاتی آن با خطای timeout مواجه میشود.
برای مثال، QSym، یک موتور اجرای نمادین سریع و پیشرفته، مجهز به چندین روش اکتشافی است تا روی برنامههای واقعی مقیاسپذیر باشد. وقتی QSym اولین بار سعی میکند محدودیت پیچیدهای که ما تزریق کردهایم را حل کند، به دلیل timeout یا انفجار مسیرها شکست میخورد.
پس از آن که کدهای تزریق شده توسط فازر چندین بار اجرا شوند، QSym بلوکهای پایهای تکراری (مانند تابع هش تزریقشده) را شناسایی کرده و basic block pruning انجام میدهد. این بداین معناست که موتور دیگر برای آن بلوکها محدودیت جدیدی تولید نمیکند و منابع را برای محدودیتهای جدید اختصاص میدهد.
در نتیجه، QSym دیگر شرط با تابع هش تزریق شده را بررسی نمیکند و بنابراین کد داخل آن شاخه به ندرت توسط فازر کاوش میشود.
6. ارزیابی
ما تکنیکهای فازیسازی (FUZZIFICATION) خود را ارزیابی میکنیم تا اثربخشی آنها در موارد زیر مشخص شود:
- جلوگیری از کاوش مسیرهای برنامه توسط فازرها (بخش 6.1)
- کشف باگها (بخش 6.2)
- قابلیت عملی برای محافظت از برنامههای بزرگ واقعی (بخش 6.3)
- استحکام در برابر تکنیکهای تحلیل خصمانه (بخش 6.4)
پیادهسازی. چارچوب فازیسازی (FUZZIFICATION) ما شامل ۶،۵۵۹ خط کد پایتون (Python) و ۷۵۸ خط کد ++C است.
- تکنیک SpeedBump بهصورت یک LLVM pass پیادهسازی شده و از آن برای تزریق تأخیر در بلوکهای cold در زمان کامپایل استفاده میکنیم.
- برای BranchTrap، کد اسمبلی برنامه را تحلیل کرده و بهصورت مستقیم تغییر میدهیم.
- برای تکنیک AntiHybrid، یک LLVM pass به منظور ایجاد انفجار مسیرها (path explosion) استفاده شده و یک اسکریپت پایتون برای تزریق خودکار جریان دادههای ضمنی (implicit data-flows) به کار گرفته شده است.
در حال حاضر، سیستم ما از هر سه تکنیک فازیسازی روی برنامههای ۶۴ بیتی پشتیبانی میکند و قادر است برنامههای ۳۲ بیتی را نیز محافظت کند، به جز BranchTrap مبتنی بر ROP.
تنظیمات آزمایش. ما تکنیکهای فازیسازی را در برابر چهار فازر پیشرفته که روی باینریها کار میکنند ارزیابی میکنیم، به طور مشخص:
- AFL در حالت QEMU
- HonggFuzz در حالت Intel-PT
- VUzzer 321
- QSym همراه با AFL-QEMU
ارزیابیها روی دو دستگاه انجام شد:
- دستگاه اول با Intel Xeon CPU E7-8890 v4@2.20GHz، دارای ۱۹۲ هسته پردازشی و ۵۰۴ گیگابایت RAM
- دستگاه دوم با Intel Xeon CPU E7-4820@2.00GHz، دارای ۳۲ هسته پردازشی و ۱۲۸ گیگابایت RAM
برای بهدست آوردن نتایج تکرارپذیر، تلاش کردیم عوامل غیرقطعی فازرها را حذف کنیم. ASLR (یا Address Space Layout Randomization) روی ماشین آزمایش غیرفعال و حالت قطعی برای AFL فعال شد. با این حال، HonggFuzz و VUzzer به دلیل عدم پشتیبانی از فازینگ قطعی، مجبور شدیم تصادفی بودن آنها را حفظ کنیم. سپس از مجموعهٔ یکسانی از تستکیسها برای پروفایلگیری بلوکهای پایه در فازیسازی استفاده شد و ورودیهای اولیه یکسان به فازرهای مختلف داده شد. هنگام اجرای تزریق کد (code instrumentation) و بازنویسی باینری، از تکنیکها و پیکربندیهای یکسان فازیسازی برای هر برنامه هدف استفاده شد. واحدهای پایهای (primitives) فازیسازی از قبل تولید شدند (مثلاً کدهای SpeedBump با تأخیر ۱۰ تا ۳۰۰ میلیثانیه و کدهای BranchTrap با شاخههای قطعی) و همان واحدهای پایهای برای همه محافظتها به کار رفت.
توجه: توسعهدهندگان باید هنگام انتشار باینری واقعی، از واحدهای پایهای متفاوت استفاده کنند تا از تحلیلهای مبتنی بر مطابقت الگوی کد جلوگیری شود.
برنامههای هدف. ما دادههای LAVA-M [17] و 9 برنامهٔ دنیای واقعی را به عنوان اهداف فازینگ انتخاب کردیم، که معمولاً برای ارزیابی کارایی فازرها به کار میروند [11, 19, 64, 52]. 9 برنامهٔ واقعی شامل موارد زیر است:
- چهار برنامه از Google fuzzer test-suite [24]
- چهار برنامه از binutils [20] (جدول 2)
- برنامه PDF خوان MuPDF (PDF reader MuPDF)
ما دو مجموعه آزمایش روی این باینریها انجام دادیم که در جدول 3 خلاصه شده است. ابتدا، 9 برنامهٔ واقعی را با سه فازر (به جز VUzzer2) فاز کردیم تا تأثیر فازیسازی بر کشف مسیرهای کد را بسنجیم. بهطور مشخص، 8 برنامهٔ واقعی (به جز MuPDF) را با پنج پیکربندی مختلف کامپایل کردیم: نسخه اصلی (بدون محافظت)، SpeedBump، BranchTrap، AntiHybrid و ترکیب سه تکنیک (محافظت کامل). برای سادهتر شدن، MuPDF با دو پیکربندی کامپایل شد: بدون محافظت و محافظت کامل.
دوم، از سه فازر برای فازینگ چهار برنامهٔ binutils و از چهار فازر برای فازینگ برنامههای LAVA-M استفاده شد تا تأثیر فازیسازی بر کشف باگهای منحصربهفرد بررسی شود. همه برنامههای فاز شده در این مرحله در دو نسخه کامپایل شدند: بدون محافظت و با محافظت کامل. برنامههای LAVA-M به نسخهٔ ۳۲ بیتی کامپایل شدند تا با تحقیقات پیشین قابل مقایسه باشند. جدول 4 پیکربندی هر تکنیک استفاده شده در کامپایل را نشان میدهد. همچنین، timeout فازرها در صورتی که باینریها با timeout پیشفرض اجرا نمیشدند (مثلاً ۱۰۰۰ میلیثانیه برای AFL-QEMU)، تغییر داده شد.
معیار ارزیابی. ما از دو معیار برای اندازهگیری اثربخشی فازیسازی استفاده میکنیم: پوشش کد (code coverage) بر اساس مسیرهای واقعی کشف شده و کرشهای منحصربهفرد (unique crashes).
مسیر واقعی (real path) به مسیر اجرای نشان داده شده در برنامهٔ اصلی گفته میشود و مسیرهای جعلی تزریق شده توسط BranchTrap را شامل نمیشود. همچنین مسیرهای واقعیای که توسط ورودیهای اولیه (seed inputs) ایجاد شدهاند، حذف شدند تا بتوانیم بر مسیرهایی که توسط فازرها کشف شدهاند تمرکز کنیم.
کرش منحصربهفرد به ورودیای گفته میشود که میتواند برنامه را با مسیر واقعی متفاوت کرش دهد. کرشهای تکراری مطابق تعریف AFL [71] فیلتر شده و این روش به طور گسترده توسط فازرهای دیگر نیز استفاده میشود [11, 36].
6.1 کاهش پوشش کد
6.1.1 تأثیر بر فازرهای معمولی
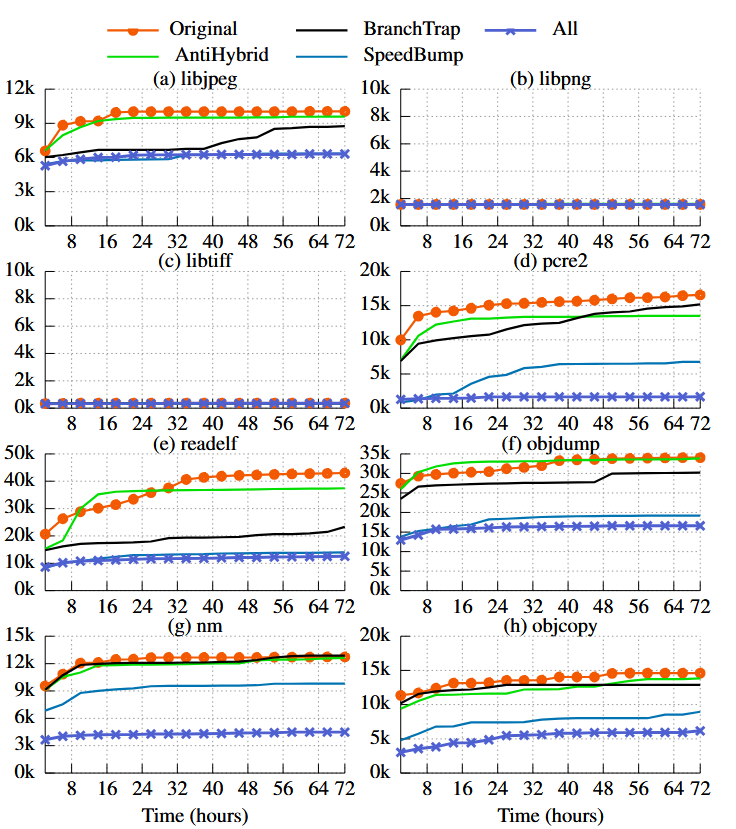
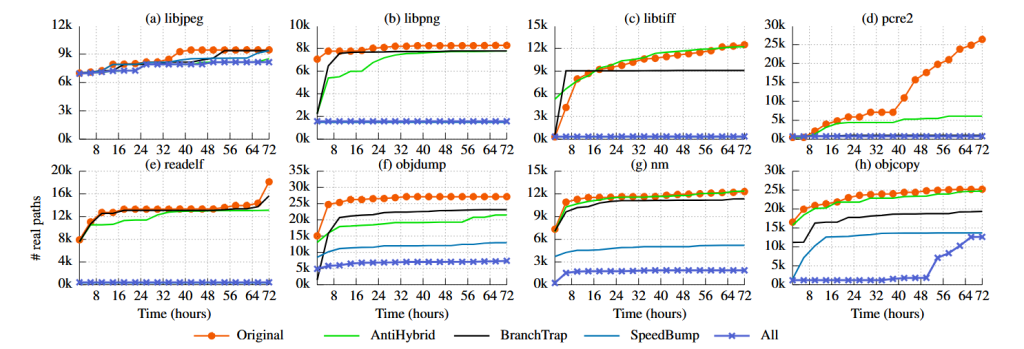
ما تأثیر فازیسازی (FUZZIFICATION) بر کاهش تعداد مسیرهای واقعی را در برابر AFL-QEMU و HonggFuzz-Intel-PT اندازهگیری میکنیم. شکل 9 نتایج فازینگ ۷۲ ساعته AFL-QEMU روی برنامههای مختلف با پنج پیکربندی محافظت را نشان میدهد. نتیجه حاصل از HonggFuzz-Intel-PT مشابه است و در ضمیمهٔ A آورده شده است.
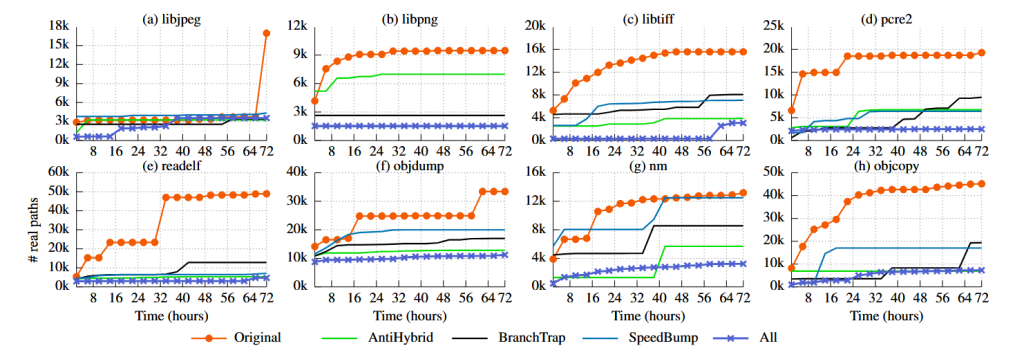
به طور خلاصه، با استفاده از هر سه تکنیک، فازیسازی (FUZZIFICATION) به طور متوسط تعداد مسیرهای واقعی کشف شده را برای AFL تا ۷۶٪ و برایHonggFuzz تا ۶۷٪ کاهش میدهد. برای AFL، نرخ کاهش بین ۱۴٪ تا ۹۷٪ متغیر است و فازیسازی بیش از ۹۰٪ کشف مسیرها را برای libtiff، pcre2 و readelf کاهش میدهد. برای HonggFuzz، نرخ کاهش بین ۳۸٪ تا ۹۰٪ است و فازیسازی تنها برای pcre2 بیش از ۹۰٪ مسیرها را کاهش میدهد. از آنجا که فازیسازی به صورت خودکار جزئیات هر محافظت را برای رعایت بودجهٔ سربار (overhead budget) تعیین میکند، تأثیر آن در برنامههای مختلف متفاوت است.
جدول ۵ تأثیر هر تکنیک را در جلوگیری از کشف مسیرها نشان میدهد. در میان آنها، SpeedBump بهترین محافظت را در برابر فازرهای معمولی ارائه میدهد، و پس از آن BranchTrap و AntiHybrid قرار دارند. جالب اینکه، با وجود آن که AntiHybrid برای مقابله با فازینگ هیبریدی توسعه یافته است، در کاهش مسیرهای کشف شده توسط فازرهای معمولی نیز مؤثر است. ما معتقدیم این موضوع عمدتاً ناشی از کُندی اجرای برنامههای فاز شده است.
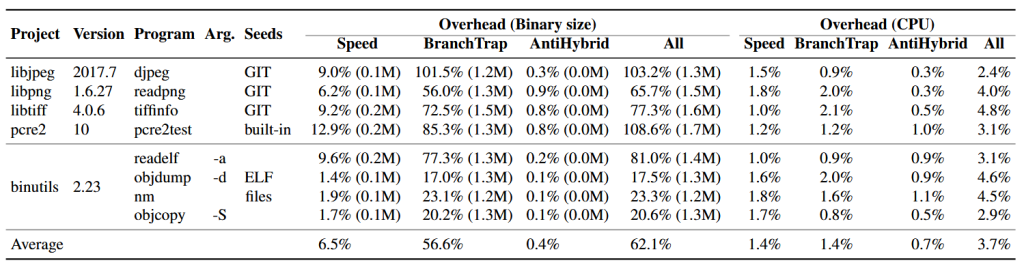
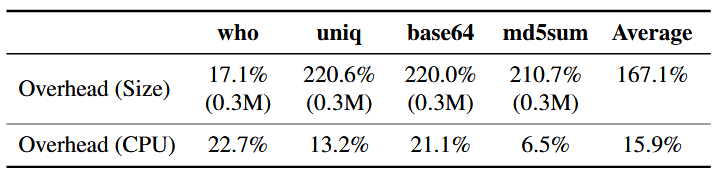
ما سربار ایجاد شده توسط تکنیکهای مختلف فازیسازی را بر اندازهٔ برنامه و سرعت اجرای آن اندازهگیری کردیم. نتایج در جدول ۲ ارائه شده است. به طور خلاصه، فازیسازی بودجهٔ سربار مشخص شده توسط کاربر را رعایت میکند، اما دارای سربار فضایی نسبتاً بالایی است. به طور متوسط، باینریهایی که با فازیسازی تجهیز شدهاند، ۶۲٫۱٪ بزرگتر از باینریهای اصلی هستند. کد اضافه عمدتاً از تکنیک BranchTrap ناشی میشود، که برای اشباع bitmap تعداد زیادی شاخه اضافه میکند. توجه داشته باشید که اندازهٔ کد اضافه تقریباً در برنامههای مختلف یکسان است. بنابراین، برای برنامههای کوچک، سربار اندازه بالا است، اما برای برنامههای بزرگ قابل چشمپوشی است. به عنوان مثال، همانطور که در جدول ۷ نشان داده شده، سربار اندازه برای برنامههای LibreOffice کمتر از ۱٪ است.
علاوه بر این، BranchTrap قابل پیکربندی است و توسعهدهندگان میتوانند برای برنامههای کوچک تعداد کمتری شاخه جعلی تزریق کنند تا از افزایش بیشازحد اندازه جلوگیری شود.
تحلیل نتایج کماثر. فازیسازی در محافظت از برنامه libjpeg اثر کمتری نشان میدهد. به طور مشخص، تعداد مسیرهای واقعی در libjpeg توسط فازیسازی تنها ۱۳٪ برای AFL و ۳۷٪ برای HonggFuzz کاهش یافته است، در حالی که میانگین کاهش بهترتیب ۷۶٪ و ۶۷٪ است.
ما فازیسازی روی libjpeg را تحلیل کردیم و دریافتیم که SpeedBump و BranchTrap نمیتوانند libjpeg را بهطور مؤثر محافظت کنند. به طور مشخص، این دو تکنیک تنها ۹ بلوک پایهای در بودجهٔ سربار مشخص شده توسط کاربر (۲٪ برای SpeedBump و ۲٪ برای BranchTrap) تزریق میکنند، که کمتر از ۰٫۱٪ کل بلوکهای پایهای است.
برای رفع این مشکل، توسعهدهندگان میتوانند بودجهٔ سربار را افزایش دهند تا فازیسازی بتواند موانع بیشتری برای محافظت از برنامه ایجاد کند.
۶.۱.۲ تأثیر بر فازرهای هیبریدی
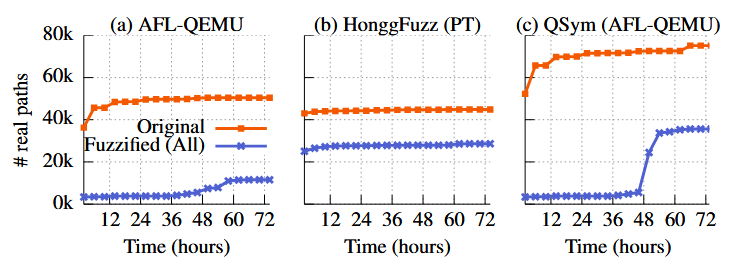
ما همچنین تأثیر فازیسازی (FUZZIFICATION) بر پوشش کد (code coverage) را در برابر QSym، یک فازر هیبریدی (hybrid fuzzer) که از اجرای نمادین (symbolic execution) برای کمک به فازینگ استفاده میکند، ارزیابی کردیم. شکل ۱۰ تعداد مسیرهای واقعی کشف شده توسط QSym از باینریهای اصلی و محافظت شده را نشان میدهد.
بهطور کلی، فازیسازی با استفاده از هر سه تکنیک، به طور متوسط پوشش مسیرها را برای QSym تا ۸۰٪ کاهش میدهد و روی تمام برنامههای آزمایش شده اثربخشی بالا و پایداری نشان میدهد. به طور مشخص، نرخ کاهش بین ۶۶٪ (objdump) تا ۹۰٪ (readelf) متغیر است.
نتیجهٔ libjpeg یک الگوی جالب نشان میدهد: QSym در ۸ ساعت آخر تعداد زیادی مسیر واقعی از باینری اصلی پیدا میکند، اما هیچ یک از باینریهای محافظتشده چنین نتیجهای ندارند.
جدول ۵ نشان میدهد که AntiHybrid بهترین اثر را در برابر فازرهای هیبریدی دارد (کاهش ۶۷٪ مسیر)، پس از آن SpeedBump با ۵۹٪ و BranchTrap با ۵۸٪ قرار دارند.
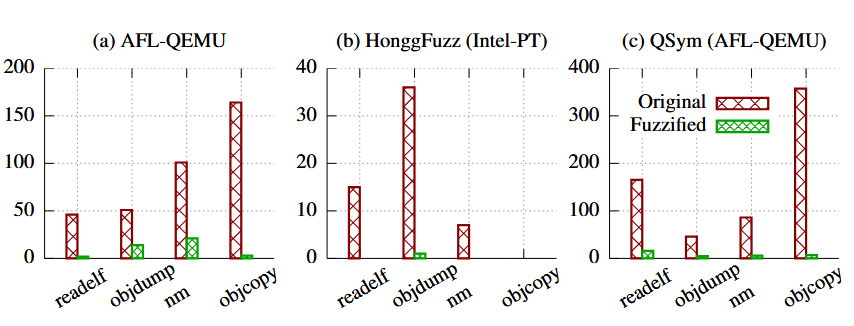
مقایسه با نتایج فازینگ معمولی. QSym با استفاده از اجرای نمادین کارآمد قادر است مسیرهای جدیدی در فازینگ کشف کند و بنابراین از باینریهای اصلی ۴۴٪ مسیر واقعی بیشتر از AFL پیدا میکند. همانطور که انتظار میرفت، AntiHybrid بیشترین تأثیر را بر QSym دارد (کاهش ۶۷٪) و تأثیر کمتری بر AFL (۱۸٪) و HonggFuzz (۷٪) دارد. با استفاده از تکنیکهای فازیسازی ما، مزیت QSym نسبت به فازرهای معمولی کاهش یافته و از ۴۴٪ به ۱۲٪رسیده است.
۶.۲ ممانعت از کشف باگها (Hindering Bug Finding)
ما تعداد کرشهای منحصربهفرد که فازرها از باینریهای اصلی و محافظت شده پیدا میکنند، اندازهگیری میکنیم. در ارزیابی ما، ابتدا چهار برنامه از binutils و برنامههای LAVA-M با سه فازر (به جز VUzzer) فاز شدند. سپس برنامههای LAVA-M با VUzzer فاز شدند، که در این مرحله آنها به نسخههای ۳۲ بیتی کامپایل شدند و محافظت BranchTrap مبتنی بر ROP که هنوز برای برنامههای ۳۲ بیتی پیادهسازی نشده است، اعمال نگردید.
۶.۲.۱ تأثیر بر برنامههای واقعی
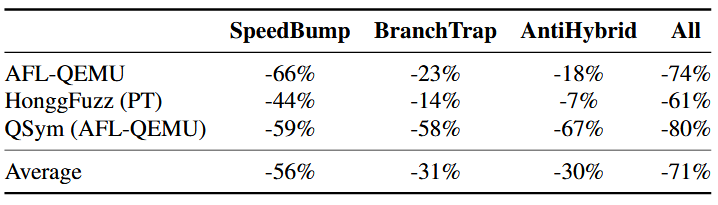
شکل ۱۱ تعداد کل کرشهای منحصربهفرد کشف شده توسط سه فازر در مدت ۷۲ ساعت را نشان میدهد. به طور کلی، فازیسازی تعداد کرشهای کشف شده را تا ۹۳٪ کاهش میدهد؛ به طور مشخص، ۸۸٪ برای AFL، ۹۸٪ برای HonggFuzz و ۹۴٪ برای QSym.
اگر فرض کنیم نرخ کشف کرش در طول فرآیند فازینگ ثابت است، فازرها باید ۴۰ برابر تلاش بیشتر انجام دهند تا همان تعداد کرش را از باینریهای محافظت شده شناسایی کنند. از آنجا که نرخ کشف کرش معمولاً در فازینگ واقعی با گذر زمان کاهش مییابد، فازرها مجبور خواهند بود تلاش بسیار بیشتری انجام دهند. بنابراین، فازیسازی میتواند به طور مؤثر فازرها را محدود کند و باعث شود آنها زمان بسیار بیشتری صرف کشف همان تعداد ورودیهای ایجادکننده کرش نمایند.
۶.۲.۲ تأثیر بر مجموعه دادهٔ LAVA-M
در مقایسه با سایر باینریهای آزمایش شده، برنامههای LAVA-M کوچکتر و سادهتر هستند. اگر ما یک تأخیر ۱ میلیثانیهای روی ۱٪ از بلوکهای پایهای به ندرت اجرا شده روی کل باینری اعمال کنیم، برنامه بیش از ۴۰ برابر کند خواهد شد.
برای اعمال فازیسازی روی مجموعه دادهٔ LAVA-M، بودجهٔ سربار بالاتری مجاز شد و FUZZIFICATION بهصورت ریزدانهتر (fine-grained) اعمال گردید. به طور مشخص:
- از واحدهای تأخیر بسیار کوچک (۱۰ تا ۱۰۰ میکروثانیه) استفاده شد.
- نسبت تزریق بلوکهای پایهای از ۱٪ به ۰٫۱٪ کاهش یافت.
- تعداد مؤلفههای AntiHybrid کاهش یافت.
- شاخههای قطعی کوچکتری تزریق شد تا سربار اندازهٔ کد کاهش یابد.
جدول ۶ سربار زمان اجرا و حافظهٔ برنامههای LAVA-M تولید شده با تکنیکهای فازیسازی را نشان میدهد.
پس از فازینگ باینریهای محافظت شده به مدت ۱۰ ساعت:
- AFL-QEMU دچار هیچگونه کرشی نشد.
- HonggFuzz سه کرش از باینری اصلیuniq شناسایی کرد و هیچ کرشی از باینریهای محافظت شده نیافت.
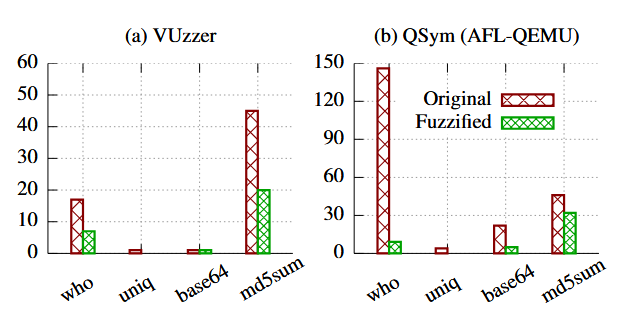
شکل ۱۲ نتایج فازینگ VUzzer و QSym را نشان میدهد. به طور کلی، فازیسازی تعداد باگهای کشف شده را ۵۶٪ برای VUzzer و ۷۸٪ برای QSym کاهش میدهد.
توجه داشته باشید که نتایج فازینگ روی باینریهای اصلی با مقادیر گزارش شده در مقالات اصلی [67, 52] متفاوت است، که دلایل آن عبارتاند از:
- VUzzer و QSym نمیتوانند مراحل غیرقطعی در طول فازینگ را حذف کنند.
- ما بخش AFL هر ابزار را در حالت QEMU اجرا کردیم.
- مجموعه دادهٔ LAVA-M با چندین اصلاح باگ بهروزرسانی شده است.
۶.۳ مقابله با فازینگ در برنامههای واقعی
برای بررسی قابلیت عملی فازیسازی (FUZZIFICATION) روی برنامههای بزرگ و واقعی، 6 برنامه انتخاب کردیم که رابط کاربری گرافیکی (GUI) دارند و به دهها کتابخانه وابسته میباشند. از آنجا که فازینگ برنامههای بزرگ و دارای GUI یک مسئلهٔ شناخته شده و چالشبرانگیز است، ارزیابی ما در این بخش بر اندازهگیری سربار تکنیکهای FUZZIFICATION و عملکرد برنامههای محافظت شده متمرکز است.
هنگام اعمال تکنیک SpeedBump، به دلیل عدم پشتیبانی از رابط خط فرمان (CLI)، نمیتوانیم مرحلهٔ پروفایلگیری بلوکهای پایه را انجام دهیم (مثلاً readelf فایل ELF را پارس میکند و نتایج را در خط فرمان نمایش میدهد)؛ بنابراین، تنها واحدهای کُند کننده را در روتینهای مدیریت خطا تزریق کردیم.
برای تکنیک BranchTrap، تصمیم گرفتیم تعداد زیادی شاخه جعلی را در بلوکهای پایهای نزدیک به نقطهٔ ورود برنامه تزریق کنیم. به این ترتیب، اجرای برنامه همیشه از کامپوننت تزریقشده عبور میکند تا بتوانیم سربار زمان اجرا را بهدرستی اندازهگیری کنیم. تکنیک AntiHybrid را نیز بهصورت مستقیم اعمال کردیم.
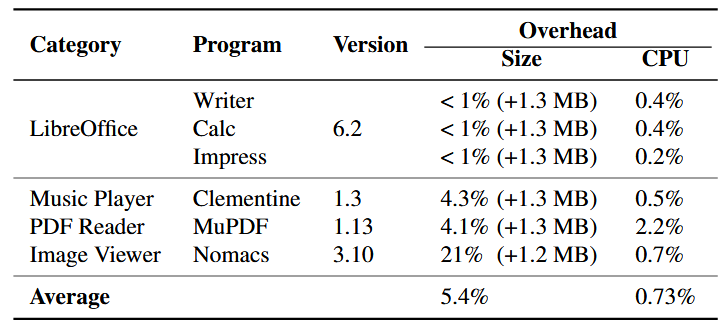
برای هر برنامهٔ محافظت شده، ابتدا آن را به صورت دستی با چندین ورودی، از جمله تستکیسهای داده شده، اجرا کردیم و تأیید کردیم که عملکرد اصلی برنامه را تغییر نمیدهد. به عنوان مثال، MuPDF تمامی فایلهای PDF تست شده را با موفقیت نمایش، ویرایش، ذخیره و چاپ میکند.
سپس سربار اندازهٔ کد و زمان اجرا باینریهای محافظت شده را برای تستکیسهای داده شده اندازهگیری کردیم. همانطور که در جدول ۷ نشان داده شده، به طور متوسط فازیسازی ۵٫۴٪ سربار اندازهٔ کد و ۰٫۷۳٪ سربار زمان اجرا ایجاد میکند. توجه داشته باشید که سربار اندازهٔ کد در اینجا به مراتب کمتر از برنامههای قبلی است (۶۲٫۱٪ برای هشت برنامه نسبتاً کوچک در جدول ۲ و بیش از ۱۰۰٪ برای برنامههای سادهٔ LAVA-M در جدول ۶).
مقابله با فازینگ در MuPDF. ما همچنین اثربخشی فازیسازی در محافظت از MuPDF در برابر سه فازر AFL، HonggFuzz و QSym را ارزیابی کردیم، زیرا MuPDF از طریق ابزاری به نام mutool از رابط خط فرمان (CLI) پشتیبانی میکند. باینری را با همان پارامترهای نشان دادهشده در جدول ۴ کامپایل کردیم و پروفایلگیری بلوکهای پایهای را با استفاده از رابط CLI انجام دادیم. پس از ۷۲ ساعت فازینگ، هیچ یک از فازرها هیچ باگی از MuPDF پیدا نکردند.
بنابراین، به جای آن، تعداد مسیرهای واقعی بین باینری اصلی و محافظت شده را مقایسه کردیم. همانطور که در شکل ۱۳ نشان داده شده، فازیسازی به طور متوسط ۵۵٪ مسیرها را کاهش میدهد؛ به طور مشخص، ۷۷٪ برای AFL، ۳۶٪ برای HonggFuzz و ۵۲٪ برای QSym. بنابراین، ما معتقدیم که کشف باگها توسط فازرهای واقعی از برنامههای محافظتشده چالشبرانگیزتر است.

۶.۴ ارزیابی اقدامات متقابل بهترین تلاش
ما استحکام تکنیکهای فازیسازی (FUZZIFICATION) را در برابر تکنیکهای تحلیل برنامه آماده که ممکن است توسط مهاجمان برای معکوس کردن محافظتها استفاده شود، ارزیابی کردیم. با این حال، نتایج آزمایش به طور خاص نشان نمیدهد که فازیسازی در برابر مهاجمان قدرتمند با منابع محاسباتی نامحدود مقاوم است.
جدول ۸ تحلیلهای انجام شده را نشان میدهد و نتیجهٔ ارزیابی را خلاصه میکند. ابتدا، مهاجمان ممکن است به دنبال الگوهای خاص کد در باینری محافظت شده باشند تا کد تزریق شدهٔ محافظتی را شناسایی کنند. برای آزمایش مقابله با فازینگ مبتنی بر تطابق الگو، تعدادی قطعه کد را که به صورت مکرر در باینریهای محافظت شده استفاده شدهاند، بررسی کردیم.
یافتهها نشان داد که کد تزریق شده توسط AntiHybrid چندین الگوی قابل مشاهده ایجاد میکند، مانند الگوریتمهای هش یا کد بازسازی جریان داده، و بنابراین میتواند توسط مهاجمان شناسایی شود. راه حل ممکن برای این مشکل، استفاده از تکنیکهای تنوع موجود برای حذف الگوهای مشترک است [35].
ما تأیید کردیم که هیچ الگوی مشخصی در SpeedBump و BranchTrap یافت نمیشود، زیرا ما از CSmith [66] برای تولید تصادفی قطعه کد جدید در هر فرآیند FUZZIFICATION استفاده میکنیم.
دوم، تحلیل جریان کنترل (control-flow analysis) میتواند بهصورت خودکار کدهای استفاده نشده در یک باینری مشخص را شناسایی کرده و آنها را حذف کند (یعنی dead code elimination). با این حال، این تکنیک نمیتواند تکنیکهای فازیسازی ما را حذف کند، زیرا تمام کدهای تزریق شده با کد اصلی cross-reference شدهاند.
سوم، تحلیل جریان داده (data-flow analysis) قادر است وابستگیهای دادهای را شناسایی کند. ما باینریهای محافظت شده را در ابزار دیباگینگ GDB اجرا کردیم تا وابستگیهای دادهای بین کد تزریق شده و کد اصلی را بررسی کنیم. تأیید کردیم که وابستگیهای دادهای همیشه از طریق متغیرهای سراسری، آرگومانها و مقادیر بازگشتی توابع تزریق شده وجود دارد.
در نهایت، ما مهاجمی را در نظر گرفتیم که قادر به انجام تحلیل دستی برای شناسایی کد ضد فازینگ با آگاهی از تکنیکهای ما است. شایان ذکر است که ما مهاجمان قدرتمند که قادر به تحلیل منطق برنامه برای کشف آسیبپذیری هستند را در اینجا در نظر نگرفتهایم.
از آنجا که کدهای تزریق شده توسط فازیسازی مکمل توابع اصلی هستند، نتیجه میگیریم که تحلیل دستی در نهایت میتواند تکنیکهای ما را با ارزیابی عملکرد واقعی کد شناسایی و خنثی کند. با این حال، از آنجا که کد تزریق شده عملکردی مشابه عملیات حسابی معمولی دارد و دارای وابستگیهای کنترل و داده به کد اصلی است، ما معتقدیم که تحلیل دستی زمانبر و پرخطا خواهد بود و بنابراین میتواند زمان لازم برای کشف باگهای واقعی را افزایش دهد.
۷. بحث و کارهای آینده
در این بخش، محدودیتهای فازیسازی را بررسی کرده و راهکارهای موقت برای مقابله با آنها پیشنهاد میکنیم.
تکمیلکنندهٔ سیستمهای کاهش حمله. هدف از ضد فازینگ (anti–fuzzing) این نیست که تمامی آسیبپذیریها را بهطور کامل از مهاجمان مخفی کند. بلکه هدف آن، ایجاد هزینهٔ بالای تلاش برای مهاجمان هنگام فازینگ برنامه برای یافتن باگها است، بهطوری که توسعهدهندگان قادر باشند ابتدا باگها را شناسایی و به موقع رفع کنند.
بنابراین، ما معتقدیم که تکنیک anti-fuzzing ما تکمیلکنندهٔ مهمی برای اکوسیستم فعلی کاهش حمله است. تلاشهای کاهش آسیب موجود، یا به دنبال جلوگیری از باگهای برنامه هستند (مثلاً از طریق زبانهای نوع ایمن [32, 44]) یا به دنبال جلوگیری از موفقیت اکسپلویت (exploit)ها هستند، با این فرض که مهاجمان به هر حال باگها را پیدا خواهند کرد (مثلاً از طریق یکپارچگی جریان کنترل – control-flow integrity [1, 16, 30]).
چون هیچ یک از این دفاعها نمیتوانند حفاظت ۱۰۰٪ ارائه دهند، تکنیکهای فازیسازی یک سطح دفاعی اضافی فراهم میکنند که امنیت برنامه را افزایش میدهد. با این حال، ما تأکید میکنیم که فازیسازی به تنهایی نمیتواند بهترین امنیت را فراهم کند. بلکه باید روی تمام جنبههای امنیت سیستم کار ادامه یابد تا یک سیستم کامپیوتری کاملاً امن ایجاد شود، شامل اما نه محدود به:
- فرآیند توسعهٔ امن
- کشف مؤثر باگها
- دفاع کارآمد در زمان اجرا
محافظت بهترین تلاش در برابر تحلیلهای خصمانه: اگرچه ما تحلیلهای عمومی موجود را بررسی کردهایم و معتقدیم که آنها نمیتوانند تکنیکهای فازیسازی ما را به طور کامل خنثی کنند، این روشهای دفاعی تنها محافظت در سطح بهترین تلاش ارائه میدهند.
اولاً، اگر مهاجمان دارای منابع تقریباً نامحدود باشند، مانند زمانی که حملات APT (Advanced Persistent Threat) را اجرا میکنند، هیچ مکانیزم دفاعی نمیتواند در برابر تحلیل خصمانهٔ قدرتمند دوام بیاورد. به عنوان مثال، با استفاده از تحلیل جریان کنترل و تحلیل جریان داده در سطح باینری بسیار قدرتمند، مهاجمان ممکن است در نهایت شاخههای تزریقشده توسط BranchTrap را شناسایی کرده و آنها را برای دستیابی به باینری بدون محافظت بازگردانند. با این حال، سنجش میزان منابع لازم برای رسیدن به این هدف دشوار است و در همین حال، توسعهدهندگان میتوانند از منطق شاخهای پیچیدهتر برای کاهش احتمال معکوسسازی استفاده کنند.
ثانیاً، ما تنها تکنیکهای موجود فعلی را بررسی کردهایم و نمیتوانیم تمام تحلیلهای ممکن را پوشش دهیم. ممکن است مهاجمانی که جزئیات تکنیکهای فازیسازی ما را میدانند، روش خاصی برای دور زدن مؤثر محافظت ارائه دهند، مانند سوءاستفاده از اشکالات پیادهسازی ما. اما در این حالت، تکنیک ضد فازینگ نیز به سرعت بهروزرسانی میشود تا حملهٔ مشخص را مسدود کند، به محض اینکه روش معکوسسازی شناسایی شود.
بنابراین، ما معتقدیم که تکنیک ضد فازینگ بهطور مداوم همراه با چرخهٔ حمله و دفاع بهبود خواهد یافت.
تعادل عملکرد برای امنیت. فازیسازی امنیت نرمافزار را با هزینه سربار کمی، از جمله افزایش اندازه کد و کاهش سرعت اجرا، بهبود میبخشد. یک تعادل مشابه در بسیاری از مکانیسمهای دفاعی نشان داده شده است و بر استقرار مکانیسمهای دفاعی تأثیر میگذارد. به عنوان مثال، تصادفیسازی طرح فضای آدرس (ASLR) به دلیل سربار کم، به طور گسترده توسط سیستمهای عامل مدرن پذیرفته شده است، در حالی که راهحلهای ایمنی حافظه هنوز راه درازی برای عملی شدن دارند. خوشبختانه، محافظت توسط فازیسازی کاملاً انعطافپذیر است، جایی که ما گزینههای پیکربندی مختلفی را برای توسعهدهندگان فراهم میکنیم تا در مورد تعادل بهینه بین امنیت و عملکرد تصمیم بگیرند و ابزار ما به طور خودکار حداکثر محافظت را تحت بودجه سربار تعیین میکند.
واحدهای تأخیر در محیطهای سختافزاری مختلف (Delay primitive on different H/W environments). ما از کدهای تولید شده توسط CSmith به عنوان واحدهای تأخیر استفاده میکنیم و تأخیر آنها را روی یک ماشین مشخص (ماشین توسعه دهنده) اندازهگیری میکنیم. این پیکربندی بدان معناست که این تأخیرهای تزریق شده ممکن است نتوانند کُندی مورد انتظار را در اجرای فاز شده روی سختافزار قدرتمندتر ایجاد کنند.
از سوی دیگر، این واحدهای تأخیر ممکن است برای کاربران عادی با دستگاههای کمتوان سربار بیشتری از حد انتظار ایجاد کنند. برای مدیریت این موضوع، ما برنامه داریم یک نسخهٔ متغیر اضافی توسعه دهیم که بتواند واحدهای تأخیر را بهصورت پویا در زمان اجرا تنظیم کند. به طور مشخص، ما عملکرد CPU را با پایش چند دستورالعمل اندازهگیری میکنیم و بهطور خودکار شمارندهٔ حلقه در واحدهای تأخیر را تنظیم میکنیم تا تأخیر دقیق در محیطهای سختافزاری مختلف اعمال شود.
با این حال، کد ممکن است الگوهای ایستا مانند سیستم کال اندازهگیری زمان یا دستورالعمل ویژهای مثل rdtsc را آشکار کند؛ بنابراین، ما توجه داریم که این نسخه دارای تعاملی اجتناب ناپذیر بین سازگاری و استحکام است.
8. کارهای مرتبط
فازینگ (Fuzzing). از زمان پیشنهاد اولیهٔ بارتون میلر در سال ۱۹۹۰ [40]، فازینگ به یک روش استاندارد برای تست خودکار برنامهها و کشف باگها تبدیل شده است. تکنیکها و ابزارهای متنوعی برای فازینگ ارائه شده [57, 52, 29, 21, 34]، توسعه یافته [72, 37, 25, 23, 18, 9] و برای کشف تعداد زیادی از باگهای برنامه استفاده شدهاند [51, 72, 59, 26, 10]. تلاشهای مستمری برای افزایش کارایی فازینگ انجام شده است، مانند توسعهٔ حلقه بازخورد مؤثرتر [6]، پیشنهاد پرایمیتیوهای جدید سیستمعامل [64] و استفاده از خوشهها برای فازینگ در مقیاس بزرگ [22, 24, 39].
اخیراً، پژوهشگران از فازینگ به عنوان یک روش عمومی برای کاوش مسیرهای برنامه با ویژگیهای خاص استفاده میکنند، مانند حداکثرسازی استفاده از CPU [49]، دستیابی به مکان خاصی در کد [5] و اعتبارسنجی نتایج یادگیری عمیق بهصورت تجربی [47]. تمام این کارها به بهبود قابل توجه امنیت و اطمینان نرمافزار منجر شدهاند.
در این مقاله، ما بر سمت دیگر شمشیر دو لبه تمرکز کردهایم، جایی که مهاجمان از تکنیکهای فازینگ برای یافتن آسیبپذیریهای صفر روزه و اجرای حملات سایبری پیچیده سوءاستفاده میکنند. ما روشهای مؤثری برای ممانعت از کشف باگ توسط مهاجمان با استفاده از فازیسازی ارائه میکنیم، که میتواند زمان لازم برای توسعهدهندگان و پژوهشگران مورد اعتماد را برای مقابله با تلاشهای فازینگ خصمانه فراهم کند.
تکنیکهای ضد فازینگ. چند مطالعه بهطور مختصر مفهوم ضد فازینگ را بررسی کردهاند [63, 27, 41, 31]. در میان آنها، Göransson و همکاران دو تکنیک ساده را ارزیابی کردند، یعنی ماسک کردن کرشها (crash masking) برای جلوگیری از شناسایی کرش توسط فازرها و شناسایی فازر برای مخفی کردن عملکرد هنگام فاز شدن [27].
با این حال، مهاجمان میتوانند به راحتی این روشها را شناسایی کرده و برای فازینگ مؤثر از آنها عبور کنند. سیستم ما یک روش کنترلشونده و ریزدانه (finegrained) ارائه میدهد تا اجرای فاز شده را کُند کند و همچنین راهکارهای مؤثری برای دستکاری حلقهٔ بازخورد به منظور فریب فازرها معرفی میکند. علاوه بر این، ما مکانیزمهای دفاعی را نیز مدنظر قرار دادهایم تا مهاجمان نتوانند تکنیکهای ضد فازینگ ما را حذف کنند.
Hu و همکاران پیشنهاد کردند که برای مانع شدن در برابر حملات، باگهای اثبات شده (اما بهطور واضح غیرقابل سوءاستفاده) را در برنامه تزریق کنند که به آنها“Chaff Bugs” گفته میشود [31]. این باگها ابزارهای تحلیل باگ را گیج میکنند و تلاش مهاجمان برای تولید اکسپلویت (exploit) را هدر میدهند.
هم Chaff Bugs و هم تکنیکهای فازیسازی روی برنامههای کد بسته (closed-source) کار میکنند. با این تفاوت که تکنیکهای ما بهطور ابتدایی جلوی کشف باگ را میگیرند و فرصت تحلیل باگ یا ساخت اکسپلویت (exploit) را از مهاجم سلب میکنند.
علاوه بر این، هر دو روش ممکن است بر استفادهٔ نادر اما قانونی برنامه تأثیر بگذارند. با این حال، روشهای ما حداکثر منجر به کُند شدن اجرای برنامه میشوند، در حالی که Chaff Bugs نامناسب میتوانند باعث کرش شوند و بنابراین قابلیت استفاده برنامه را کاهش دهند.
تکنیکهای ضد تحلیل. ضد اجرای نمادین (anti-symbolic-execution) و ضد تحلیل آلودگی داده (anti-taint-analysis) از موضوعات شناخته شده هستند. Sharif و همکاران [56] یک ابهامسازی شرطی کد طراحی کردند که شاخههای شرطی را با عملیات رمزنگاری رمزگذاری میکند. Wang و همکاران [62] روشی برای سختکردن باینری در برابر اجرای نمادین پیشنهاد دادند که به جای توابع رمزنگاری، از عملیات خطی استفاده میکند. با این حال، هیچکدام سربار عملکرد را به عنوان یک معیار ارزیابی در نظر نگرفتهاند.
SymPro [7]، پروفایلینگ نمادین (symbolic profiling) را ارائه کرد، روشی برای شناسایی و تشخیص گلوگاههای برنامه تحت اجرای نمادین. Cavallaro و همکاران [8] مجموعهای جامع از تکنیکهای فرار از تحلیل آلودگی داده دینامیک را نشان دادند.
ابهامسازی و تنوع نرمافزار. ابهامسازی نرمافزار، کد برنامه را به فرمتهای پیچیدهای تبدیل میکند که تحلیل آن دشوار باشد تا از مهندسی معکوس غیرمنتظره جلوگیری شود [12, 13]. ابزارهای متنوعی برای ابهامسازی باینریها توسعه یافتهاند [15, 60, 33, 46]. با این حال، ابهامسازی برای جلوگیری از فازینگ غیرمنتظره مؤثر نیست، زیرا تمرکز آن بر فرار از تحلیل استاتیک است و منطق اصلی برنامه همچنان در زمان اجرا آشکار میشود.
در مقابل، تنوع نرمافزار نسخههای مختلفی از همان برنامه را برای محیطهای اجرایی مختلف ارائه میدهد، با هدف یا محدود کردن حمله به یک نسخهٔ خاص (معمولاً مجموعهای کوچک از تمام توزیعها) یا افزایش چشمگیر تلاش لازم برای ساخت exploit عمومی [35, 3, 53, 50].
فازینگ یکی از نسخههای متنوع شده ممکن است کمتر مؤثر باشد اگر باگی که شناسایی شده به یک نسخه خاص محدود باشد (که معمولاً ناشی از اشتباه در پیادهسازی مکانیزم تنوع است). با این حال، برای باگهایی که از اشتباه برنامهنویسی ناشی میشوند، تنوع نمیتواند جلوی کشف آنها توسط مهاجمان را بگیرد.
۹. نتیجهگیری
ما یک سیستم جدید کاهش حمله به نام فازیسازی (FUZZIFICATION) پیشنهاد میکنیم تا توسعهدهندگان بتوانند فازینگ خصمانه را مهار کنند. در این سیستم سه روش اصولی برای ممانعت از فازینگ ارائه شده است: تزریق تأخیر برای ک،ند کردن اجرای فاز شده، درج شاخههای جعلی برای گیج کردن بازخورد پوشش کد و تبدیل جریانهای داده برای جلوگیری از تحلیل آلودگی داده همراه با استفاده از محدودیتهای پیچیده برای مختل کردن اجرای نمادین. ما همچنین واحدهای ضد فازینگ مقاوم طراحی کردهایم تا مهاجمان نتوانند فرآیند فازیسازی را دور بزنند. ارزیابی ما نشان میدهد که فازیسازی میتواند کاوش مسیرها را تا ۷۰.۳٪ کاهش دهد و کشف باگها را برای باینریهای واقعی تا ۹۳٪ و برای مجموعه داده LAVA-M تا ۶۷.۵٪ کاهش دهد.
10. منابع
[1] Martín Abadi, Mihai Budiu, Úlfar Erlingsson, and Jay Ligatti. Control-flow Integrity. In Proceedings of the 12th ACM Conference on Computer and Communications Security, 2005.
[2] Cornelius Aschermann, Sergej Schumilo, Tim Blazytko, Robert Gawlik, and Thorsten Holz. REDQUEEN: Fuzzing with Input-to-State Correspondence. In Proceedings of the 2019 Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, February 2019.
[3] Algirdas Avizienis and Liming Chen. On the Implementation of N-version Programming for Software Fault Tolerance during Execution. Proceedings of the IEEE COMPSAC, pages 149–155, 1977.
[4] Fabrice Bellard. QEMU, a Fast and Portable Dynamic Translator. In Proceedings of the 2005 USENIX Annual Technical Conference (ATC), Anaheim, CA, April 2005.
[5] Marcel Böhme, Van-Thuan Pham, Manh-Dung Nguyen, and Abhik Roychoudhury. Directed Greybox Fuzzing. In Proceedings of the 24th ACM Conference on Computer and Communications Security (CCS), Dallas, TX, October–November 2017.
[6] Marcel Böhme, Van-Thuan Pham, and Abhik Roychoudhury. Coveragebased Greybox Fuzzing as Markov Chain. In Proceedings of the 23rd ACM Conference on Computer and Communications Security (CCS), Vienna, Austria, October 2016.
[7] James Bornholt and Emina Torlak. Finding Code that Explodes under Symbolic Evaluation. Proceedings of the ACM on Programming Languages, 2(OOPSLA), 2018.
[8] Lorenzo Cavallaro, Prateek Saxena, and R Sekar. Anti-taint-analysis: Practical Evasion Techniques against Information Flow based Malware Defense. Technical report, Stony Brook University, 2007.
[9] CENSUS. Choronzon - An Evolutionary Knowledge-based Fuzzer,2015. ZeroNights Conference.
[10] Oliver Chang, Abhishek Arya, and Josh Armour. OSS-Fuzz: Five Months Later, and Rewarding Projects, 2018. https://security.googleblog.com/2017/05/oss-fuzz-five-months-later-and.html.
[11] Peng Chen and Hao Chen. Angora: Efficient Fuzzing by Principled Search. In Proceedings of the 39th IEEE Symposium on Security and Privacy (Oakland), San Jose, CA, May 2018.
[12] Christian Collberg, Clark Thomborson, and Douglas Low. A Taxonomy of Obfuscating Transformations. Technical report, Department of Computer Science, University of Auckland, New Zealand, 1997.
[13] Christian Collberg, Clark Thomborson, and Douglas Low. Manufacturing Cheap, Resilient, and Stealthy Opaque Constructs. In Proceedings of the 25th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, 1998.
[14] Timothy Garnett Derek Bruening, Vladimir Kiriansky. Dynamic Instrumentation Tool Platform. http://www.dynamorio.org/, 2009.
[15] Theo Detristan, Tyll Ulenspiegel, Mynheer Superbus Von Underduk, and Yann Malcom. Polymorphic Shellcode Engine using Spectrum Analysis, 2003. http://phrack.org/issues/61/9.html.
[16] Ren Ding, Chenxiong Qian, Chengyu Song, Bill Harris, Taesoo Kim, and Wenke Lee. Efficient Protection of Path-Sensitive Control Security. In Proceedings of the 26th USENIX Security Symposium (Security), Vancouver, BC, Canada, August 2017.
[17] Brendan Dolan-Gavitt, Patrick Hulin, Engin Kirda, Tim Leek, Andrea Mambretti, Wil Robertson, Frederick Ulrich, and Ryan Whelan. LAVA: Large-scale Automated Vulnerability Addition. In Proceedings of the 37th IEEE Symposium on Security and Privacy (Oakland), San Jose, CA, May 2016.
[18] Michael Eddington. Peach Fuzzing Platform. Peach Fuzzer, page 34, 2011.
[19] Shuitao Gan, Chao Zhang, Xiaojun Qin, Xuwen Tu, Kang Li, Zhongyu Pei, and Zuoning Chen. CollAFL: Path Sensitive Fuzzing. In Proceedings of the 39th IEEE Symposium on Security and Privacy (Oakland), San Jose, CA, May 2018.
[20] GNU Project. GNU Binutils Collection. https://www.gnu.org/software/binutils, 1996.
[21] Patrice Godefroid, Michael Y. Levin, and David Molnar. Automated Whitebox Fuzz Testing. In Proceedings of the 15th Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, February 2008.
[22] Google. Fuzzing for Security, 2012. https://blog.chromium.org/2012/04/fuzzing-for-security.html.
[23] Google. Honggfuzz, 2016. https://google.github.io/honggfuzz/.
[24] Google. OSS-Fuzz - Continuous Fuzzing for Open Source Software, 2016. https://github.com/google/oss-fuzz.
[25] Google. Syzkaller - Linux Syscall Fuzzer, 2016. https://github.com/google/syzkaller.
[26] Google. Honggfuzz Found Bugs, 2018. https://github.com/google/honggfuzz#trophies.
[27] David Göransson and Emil Edholm. Escaping the Fuzz. Master’s thesis, Chalmers University of Technology, Gothenburg, Sweden, 2016.
[28] Munawar Hafiz and Ming Fang. Game of Detections: How Are Security Vulnerabilities Discovered in the Wild? Empirical Software Engineering, 21(5):1920–1959, October 2016.
[29] Christian Holler, Kim Herzig, and Andreas Zeller. Fuzzing with Code Fragments. In Proceedings of the 21st USENIX Security Symposium (Security), Bellevue, WA, August 2012.
[30] Hong Hu, Chenxiong Qian, Carter Yagemann, Simon Pak Ho Chung, William R. Harris, Taesoo Kim, and Wenke Lee. Enforcing Unique Code Target Property for Control-Flow Integrity. In Proceedings of the 25th ACM Conference on Computer and Communications Security (CCS), Toronto, Canada, October 2018.
[31] Zhenghao Hu, Yu Hu, and Brendan Dolan-Gavitt. Chaff Bugs: Deterring Attackers by Making Software Buggier. CoRR, abs/1808.00659, 2018.
[32] Trevor Jim, J. Greg Morrisett, Dan Grossman, Michael W. Hicks, James Cheney, and Yanling Wang. Cyclone: A Safe Dialect of C. In Proceedings of the USENIX Annual Technical Conference, 2002.
[33] Pascal Junod, Julien Rinaldini, Johan Wehrli, and Julie Michielin. Obfuscator-LLVM – Software Protection for the Masses. In Brecht Wyseur, editor, Proceedings of the IEEE/ACM 1st International Workshop on Software Protection. IEEE, 2015.
[34] Su Yong Kim, Sangho Lee, Insu Yun, Wen Xu, Byoungyoung Lee, Youngtae Yun, and Taesoo Kim. CAB-Fuzz: Practical Concolic Testing Techniques for COTS Operating Systems. In Proceedings of the 2017 USENIX Annual Technical Conference (ATC), Santa Clara, CA, July 2017.
[35] Per Larsen, Andrei Homescu, Stefan Brunthaler, and Michael Franz. SoK: Automated Software Diversity. In Proceedings of the 35th IEEE Symposium on Security and Privacy (Oakland), San Jose, CA, May 2014.
[36] Yuekang Li, Bihuan Chen, Mahinthan Chandramohan, Shang-Wei Lin, Yang Liu, and Alwen Tiu. Steelix: Program-state Based Binary Fuzzing. In Proceedings of the 11th Joint Meeting on Foundations of Software Engineering, 2017.
[37] LLVM. LibFuzzer - A Library for Coverage-guided Fuzz Testing, 2017. http://llvm.org/docs/LibFuzzer.html.
[38] Chi-Keung Luk, Robert Cohn, Robert Muth, Harish Patil, Artur Klauser, Geoff Lowney, Steven Wallace, Vijay Janapa Reddi, and Kim Hazelwood. Pin: Building Customized Program Analysis Tools with Dynamic Instrumentation. In Proceedings of the 2005 ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), Chicago, IL, June 2005.
[39] Microsoft. Microsoft Previews Project Springfield, a Cloud-based Bug Detector, 2016. https://blogs.microsoft.com/next/2016/09/26/microsoft-previews-project-springfield-cloud-based-bug-detector.
[40] Barton P. Miller, Louis Fredriksen, and Bryan So. An Empirical Study of the Reliability of UNIX Utilities. Commun. ACM, 33(12):32–44, December 1990.
[41] Charlie Miller. Anti-Fuzzing. https://www.scribd.com/document/316851783/anti-fuzzing-pdf, 2010.
[42] WinAFL Crashes with Testing Code. https://github.com/ivanfratric/winafl/issues/62, 2017.
[43] Unexplained Crashes in WinAFL. https://github.com/DynamoRIO/dynamorio/issues/2904, 2018.
[44] George C. Necula, Scott McPeak, and Westley Weimer. CCured: Type-safe Retrofitting of Legacy Code. In Proceedings of the 29th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, 2002.
[45] CSO online. Seven of the Biggest Recent Hacks on Crypto Exchanges, 2018. https://www.ccn.com/japans-16-licensed-cryptocurrency-exchanges-launch-self-regulatory-body/.
[46] Oreans Technologies. Themida, 2017. https://www.oreans.com/themida.php.
[47] Kexin Pei, Yinzhi Cao, Junfeng Yang, and Suman Jana. DeepXplore: Automated Whitebox Testing of Deep Learning Systems. In Proceedings of the 26th ACM Symposium on Operating Systems Principles (SOSP), Shanghai, China, October 2017.
[48] Hui Peng, Yan Shoshitaishvili, and Mathias Payer. T-Fuzz: Fuzzing by Program Transformation. In Proceedings of the 39th IEEE Symposium on Security and Privacy (Oakland), San Jose, CA, May 2018.
[49] Theofilos Petsios, Jason Zhao, Angelos D. Keromytis, and Suman Jana. SlowFuzz: Automated Domain-Independent Detection of Algorithmic Complexity Vulnerabilities. In Proceedings of the 24th ACM Conference on Computer and Communications Security (CCS), Dallas, TX, October–November 2017.
[50] Brian Randell. System Structure for Software Fault Tolerance. IEEE Transactions on Software Engineering, (2):220–232, 1975.
[51] Michael Rash. A Collection of Vulnerabilities Discovered by the AFL Fuzzer, 2017. https://github.com/mrash/afl-cve.
[52] Sanjay Rawat, Vivek Jain, Ashish Kumar, Lucian Cojocar, Cristiano Giuffrida, and Herbert Bos. VUzzer: Application-aware Evolutionary Fuzzing. In Proceedings of the 2017 Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, February–March 2017.
[53] Ina Schaefer, Rick Rabiser, Dave Clarke, Lorenzo Bettini, David Benavides, Goetz Botterweck, Animesh Pathak, Salvador Trujillo, and Karina Villela. Software Diversity: State of the Art and Perspectives. International Journal on Software Tools for Technology Transfer (STTT), 14(5):477–495, October 2012.
[54] Sergej Schumilo, Cornelius Aschermann, Robert Gawlik, Sebastian Schinzel, and Thorsten Holz. kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels. In Proceedings of the 26th USENIX Security Symposium (Security), Vancouver, BC, Canada, August 2017.
[55] Hovav Shacham. The Geometry of Innocent Flesh on the Bone: Returninto-libc Without Function Calls (on the x86). In Proceedings of the 14th ACM Conference on Computer and Communications Security (CCS), Alexandria, VA, October–November 2007.
[56] Monirul I Sharif, Andrea Lanzi, Jonathon T Giffin, and Wenke Lee. Impeding Malware Analysis Using Conditional Code Obfuscation. In Proceedings of the 15th Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, February 2008.
[57] Nick Stephens, John Grosen, Christopher Salls, Andrew Dutcher,Ruoyu Wang, Jacopo Corbetta, Yan Shoshitaishvili, Christopher Kruegel, and Giovanni Vigna. Driller: Augmenting Fuzzing through Selective Symbolic Execution. In Proceedings of the 2016 Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, February 2016.
[58] Synopsys. Where the Zero-days are, 2017. https://www.synopsys.com/content/dam/synopsys/sig-assets/reports/state-of-fuzzing-2017.pdf.
[59] Syzkaller. Syzkaller Found Bugs - Linux Kernel, 2018. https://github.com/google/syzkaller/blob/master/docs/linux/found_bugs.md.
[60] UPX Team. The Ultimate Packer for eXecutables, 2017. https://upx.github.io.
[61] Daniel Votipka, Rock Stevens, Elissa M. Redmiles, Jeremy Hu, and Michelle L. Mazurek. Hackers vs. Testers A Comparison of Software Vulnerability Discovery Processes. In Proceedings of the 39th IEEE Symposium on Security and Privacy (Oakland), San Jose, CA, May 2018.
[62] Zhi Wang, Jiang Ming, Chunfu Jia, and Debin Gao. Linear Obfuscation to Combat Symbolic Execution. In Proceedings of the 16th European Symposium on Research in Computer Security (ESORICS), Leuven, Belgium, September 2011.
[63] Ollie Whitehouse. Introduction to Anti-Fuzzing: A Defence in Depth Aid. https://www.nccgroup.trust/uk/about-us/newsroomand-events/blogs/2014/january/introduction-to-antifuzzing-a-defence-in-depth-aid/, 2014.
[64] Wen Xu, Sanidhya Kashyap, Changwoo Min, and Taesoo Kim. Designing New Operating Primitives to Improve Fuzzing Performance. In Proceedings of the 24th ACM Conference on Computer and Communications Security (CCS), Dallas, TX, October–November 2017.
[65] Zhou Xu. PTfuzzer, 2018. https://github.com/hunter-ht-2018/ptfuzzer.
[66] Xuejun Yang, Yang Chen, Eric Eide, and John Regehr. Finding and Understanding Bugs in C Compilers. In ACM SIGPLAN Notices, volume 46, pages 283–294. ACM, 2011.
[67] Insu Yun, Sangho Lee, Meng Xu, Yeongjin Jang, and Taesoo Kim. QSYM: A Practical Concolic Execution Engine Tailored for Hybrid Fuzzing. In Proceedings of the 27th USENIX Security Symposium (Security), Baltimore, MD, August 2018.
[68] Michal Zalewski. Fuzzing Random Programs without execve(),2014. https://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html.
[69] Michal Zalewski. New in AFL: Persistent Mode, 2015.https://lcamtuf.blogspot.com/2015/06/new-in-afl-persistent-mode.html.
[70] Michal Zalewski. High-performance Binary-only Instrumentation for AFL-fuzz, 2016. https://github.com/mirrorer/afl/tree/master/qemu_mode.
[71] Michal Zalewski. Technical Whitepaper for AFL-fuzz, 2017. https://github.com/mirrorer/afl/blob/master/docs/technical_details.txt.
[72] Michal Zalewski. American Fuzzy Lop (2.52b), 2018. http://lcamtuf.coredump.cx/afl/.
11. ضمایم
A. نتایج HonggFuzz در حالت Intel-PT